











紙上設計されたデータベースアーキテクチャがサンドボックス環境では完璧に動作するものの、実際のトラフィック下で崩壊する場合、その原因はしばしば視覚的なモデルと実行時の現実との間に存在するギャップにある。エンティティ関係図(ERD)は設計図であり、動くエンジンではない。しかし、開発者が「負荷下でERDが失敗する」と言うとき、それはその図から導かれたスキーマ設計が本番環境の要求を維持できず、問題を引き起こしていることを意味している。本ガイドでは、データ量と同時アクセス数が急増する際にリレーショナルモデルが苦戦する原因となる構造的・論理的・パフォーマンス上のボトルネックについて解説する。
これらの問題を診断するには、データ関係がI/O操作、ロック競合、メモリ使用量にどのように変換されるかを深く理解する必要がある。設計選択とハードウェアの限界、トラフィックパターンとの衝突点を検証する。構造的失敗の具体的な兆候を特定することで、データ整合性を損なうことなくスケーラビリティを支えるようにデータモデルを再設計できる。
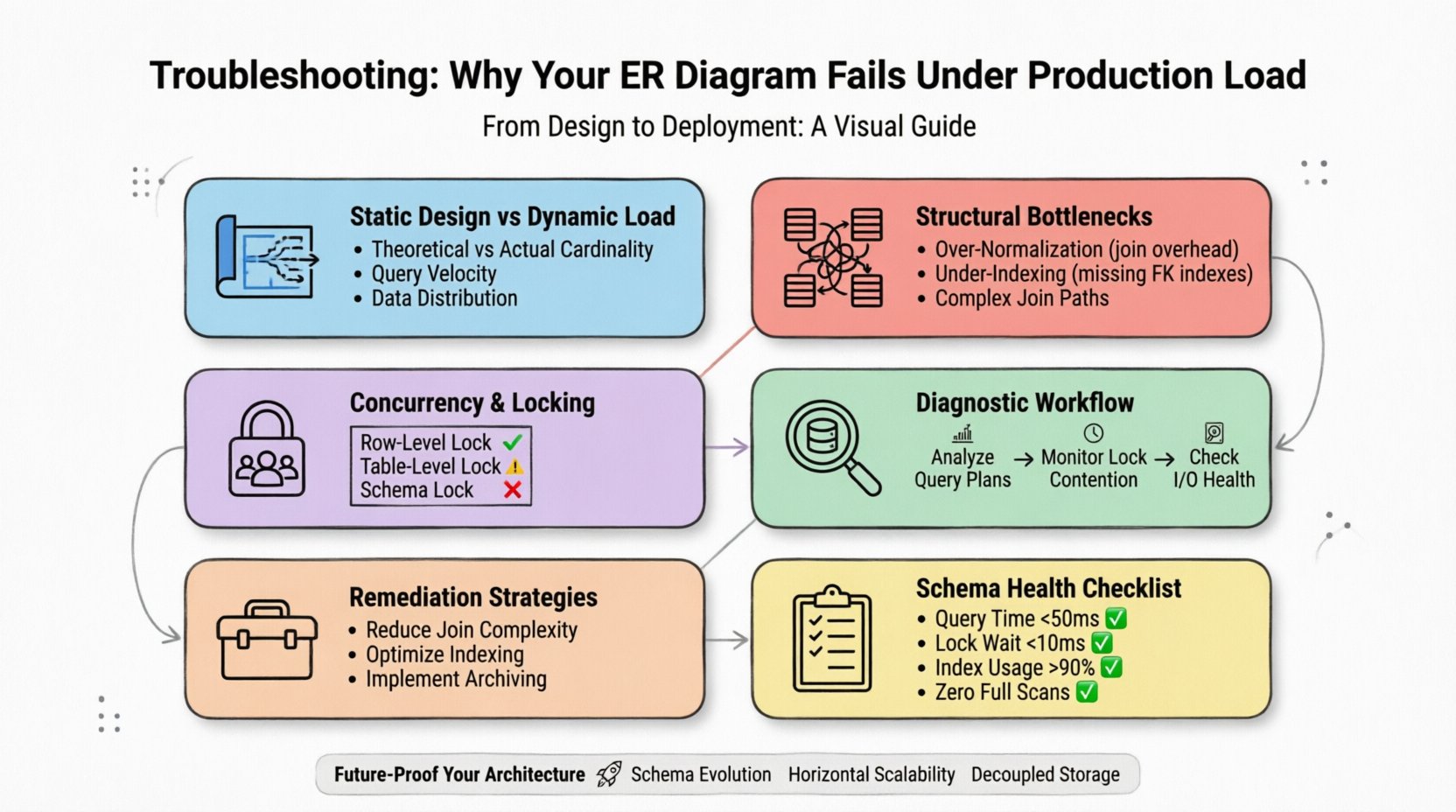
1. 静的設計と動的負荷の間のギャップ ⚡
ER図は潜在的な関係性とデータ型を表す。書き込みの速度、読み取りの分布、基盤エンジンの物理的ストレージ制約は考慮されない。ホワイトボード上でバランスが取れているように見えるモデルでも、数百万行のレコードを同時にクエリする状況でしか顕在化しない非効率性が隠れていることがある。
- 理論的 vs. 実際の基数:図は1対1または1対多の関係を前提としている。本番環境では、これらが多くの場合、複雑な結合経路を持つ多対多の関係に変化し、CPUリソースを枯渇させる。
- クエリ速度:スキーマは1秒間に数千件の読み取りを処理できるが、ロックの粒度が粗いため、1ミリ秒あたり数千件の処理で停止してしまう。
- データ分布:データがストレージノード間で均等に分散されない場合、ホットスポットが発生し、負荷分散が不均一になる。
効果的に診断するには、スキーマを静的な資産と見なすのをやめなければならない。それはサーバーと同様に、厳密に監視されるべき動的なリソースである。
2. 一般的な構造的ボトルネック 📉
パフォーマンス低下の最も一般的な原因は、関係構造そのものである。テーブルの接続方法がエンジンによるデータ走査の仕方を決定する。複雑な結合は、クエリ実行時間が遅くなる主な原因である。
2.1 過剰正規化のリスク
正規化は冗長性を減らすが、過剰な正規化は単一のデータセットを取得するために必要な結合の数を増加させる。高負荷環境では、1つの結合も潜在的な障害点となる。
- 結合のオーバーヘッド:各結合操作では、データベースが2つのテーブルの行を照合する必要がある。これらのテーブルが大きく、適切なインデックスがなければ、エンジンはフルテーブルスキャンを実行する。
- トランザクションの深さ:深く正規化されたスキーマは、関連データを取得するために長時間実行されるトランザクションを必要とすることが多く、ロックを長期間保持する。
- キャッシュ効率:正規化されたデータは複数のページに分散されるため、バッファプールキャッシュの効果が低下する。
2.2 インデックス不足とアクセス経路
適切に構造化されたERDはアクセスパターンを示唆する。図が実際のクエリワークロードと一致しない場合、データベースエンジンはデータへの最速経路を見つけることができない。
- 外部キーインデックス:外部キーはしばしばインデックスがなく、親レコードの削除や更新時にパフォーマンス低下を引き起こす。
- 複合キーの順序:複合インデックスのカラムの順序は重要である。クエリが2番目のカラムからフィルタリングする場合、インデックスが無視される可能性がある。
- 選択的インデックスの欠如:高基数カラムにインデックスがなければ、エンジンは特定の値を見つけるためにテーブル全体をスキャンする。
3. 同時実行とロックメカニズム 🔒
負荷が増加すると、同時実行性が主な制約要因になります。複数のユーザーが同じデータを変更しようとする場合、競合が生じます。スキーマ設計でロックの粒度を考慮していないと、システムがデッドロックまたはタイムアウトします。
| ロックの種類 | 負荷への影響 | 典型的な症状 |
|---|---|---|
| 行単位のロック | 影響が最小限、同時実行性が高い | 低遅延、高スループット |
| テーブル単位のロック | 大きな影響、他のユーザーをブロック | タイムアウトエラー、処理が停止するクエリ |
| スキーマロック | DDL実行中はすべてのアクセスをブロック | メンテナンス中にシステム全体が停止 |
3.1 デッドロックとレースコンディション
デッドロックは、2つのトランザクションが互いにリソースの解放を待つ場合に発生します。これは、スキーマとやり取りするアプリケーションロジックにおけるロック順序の不整合が原因であることがよくあります。
- トランザクションの分離レベル:より高い分離レベル(例:可視化)は安全を提供しますが、同時実行性を著しく低下させます。
- ロックの昇格:トランザクションが多すぎる行をロックすると、エンジンがテーブルロックに昇格し、他のすべての操作をブロックする可能性があります。
- 長時間トランザクション:ミリ秒ではなく秒単位でロックを保持する操作は、全体のキューにボトルネックを生じさせます。
4. データ量とパーティショニング戦略 📊
データが増加すると、ストレージレイヤーの物理的限界が顕在化します。1万行で動作するスキーマが1億行で深刻な障害を起こすことがあります。パーティショニングは、大きなテーブルを小さな管理可能な部分に分割する手法です。
- 垂直パーティショニング:アクセス頻度の低い列を別テーブルに移動することで、主テーブルのサイズを小さくし、ホットデータのキャッシュヒット率を向上させます。
- 水平パーティショニング:行を複数の物理セグメント(シャーディング)に分割することで、複数のストレージノードに負荷を分散します。
- 時系列ベースのパーティショニング:取引データの場合、日付単位でパーティショニングすることで、エンジンが古いパーティションを即座に削除でき、テーブル全体をロックせずに済みます。
5. 本番環境での障害に対する診断ワークフロー 🔍
システムの動作が遅くなった場合、根本原因を特定するために体系的なアプローチが必要です。ランダムな最適化はしばしばリソースを無駄にします。このワークフローに従って、問題の原因を特定してください。
5.1 クエリ実行計画の分析
実行計画は、データベースエンジンがデータを取得しようとしている方法を明らかにします。非効率さの具体的な兆候を探してください。
- フルテーブルスキャン:インデックスが欠落しているか、要求するデータ量が多すぎるクエリを示しています。
- キー照合:エンジンがインデックスとテーブルデータの間を繰り返し移動しなければならないことを示しており、I/Oが増加します。
- ソート操作:大きな結果セットの並べ替えは、大きなメモリとCPUを消費します。
5.2 ロック競合の監視
システムツールを使用して待機イベントを監視してください。ロックでの待機時間が長い場合、スキーマが現在の並行処理レベルをサポートできていないことを示しています。
- 待機時間メトリクス:トランザクションがリソースを待機する時間の長さを追跡してください。
- デッドロックグラフ:過去のデータを確認して、どのクエリが衝突を引き起こしたかを把握してください。
- ロック待機キュー:同じリソースを待機しているトランザクションの数を監視してください。
5.3 I/Oサブシステムの健全性の確認
完璧なスキーマであっても、遅いストレージは障害を引き起こします。下位のインフラがデータアクセスパターンと一致していることを確認してください。
- スループットの限界:ストレージデバイスが読み取り/書き込み操作で飽和していないか確認してください。
- レイテンシの急上昇:ストレージ層からの応答時間が不安定な場合、ハードウェアの劣化を示していることが多いです。
- バッファプールの効率:データベースがディスクからの読み取りにメモリより多くの時間を費やしている場合、スキーマまたはデータ量がキャッシュに適さないほど大きくなっています。
6. スキーマ最適化のための是正戦略 🛠️
ボトルネックが特定されたら、的確な変更を適用してください。本番環境のスキーマを再構築するには、データ損失やダウンタイムを避けるために注意が必要です。
6.1 Joinの複雑さの低減
最も摩擦を生じる関係を簡素化してください。これは、モデルの特定の領域を非正規化することに多くなります。
- マテリアライズドビュー:複雑な結合を事前に計算し、結果を別テーブルに格納して高速な取得を可能にする。
- 計算列:クエリ実行時に計算を避けるため、導出データをテーブルに直接格納する。
- 読み取りレプリカルーティング:読み取り負荷の高いクエリを、正規化されていないデータのコピーを保持するレプリカに送信する。
6.2 インデックス戦略の最適化
インデックスは検索を高速化する最も効果的なツールだが、書き込み操作にはコストがかかる。
- フィルタリングインデックス:頻繁にクエリされるデータのサブセットのみにインデックスを作成する。
- カバーインデックス:クエリに必要なすべての列をインデックスに含め、メインテーブルへのアクセスを回避する。
- インデックスのメンテナンス:頻繁な更新によって生じる断片化を防ぐため、定期的にインデックスを再構築または再編成する。
6.3 ソフトデリートとアーカイブの実装
アクティブデータは歴史的データよりもクエリが速い。古いデータをプライマリテーブルから移動させることでパフォーマンスが向上する。
- アーカイブテーブル:一定期間を超えるレコードを別々の、低温なストレージ層に移動する。
- ソフトデリート:レコードを削除せずに削除済みとしてマークすることで、テーブル構造を安定させつつ論理的にデータを非表示にする。
- データ保持ポリシー:不要なデータの削除を自動化して、無制限な成長を防ぐ。
7. スキーマの健全性を評価するチェックリスト ✅
変更をデプロイする前に、これらの基準に基づいてモデルを検証し、本番環境での負荷を処理できることを確認する。
| 基準 | 合格条件 | 不合格条件 |
|---|---|---|
| 平均クエリ時間 | < 50ms | > 500ms |
| ロック待機時間 | < 10ms | > 100ms |
| インデックス使用率 | > 90% | < 50% |
| フルテーブルスキャン | ゼロ | 頻繁 |
これらの指標に基づいてデータモデルを定期的に監査することで、設計がビジネスニーズに合わせて進化することを保証します。静的なスキーマはやがて負担になります。信頼性を維持する唯一の方法は、継続的なモニタリングと段階的な調整です。
8. クエリパターンとワークロードの理解 📈
パフォーマンスはスキーマそのものだけの問題ではない。そのスキーマの使い方こそが重要である。ワークロードの特性を理解することは、モデルのチューニングに不可欠である。
- OLTP と OLAP の違い:オンライントランザクション処理(OLTP)は、高速で小規模な書き込みを必要とする。オンライン分析処理(OLAP)は、高速で大規模な読み込みを必要とする。一方の用途に最適化されたスキーマは、他方の用途ではしばしば問題を引き起こす。
- 書き込みが重いパターン:アプリケーションが頻繁に書き込む場合は、インデックスの効率性を最優先し、書き込み時のロックを最小限に抑えること。
- 読み込みが重いパターン:アプリケーションが頻繁に読み込む場合は、キャッシュ戦略と読み取りレプリカを最優先すること。
9. アプリケーションロジックがデータベースパフォーマンスに与える役割 💻
多くの場合、問題の原因はデータベースそのものにあるのではなく、アプリケーションがデータベースとどのようにやり取りしているかにある。N+1クエリ問題は、アプリケーションレベルの非効率がデータベースの障害として現れる典型的な例である。
- バッチ処理:数千件の個別INSERT文を送信するよりも、1つのバッチ処理の方が高速である。
- 遅延読み込み:データを小さなチャンクで取得すると、データベースへの過剰な往復通信が発生する可能性がある。
- コネクションプーリング:データベース接続の非効率な管理は、ピーク負荷時に利用可能なリソースを枯渇させる可能性がある。
アプリケーション層の最適化により、スキーマへの負荷が軽減され、データベースが設計されたパラメータ内で動作できるようになる。
10. データアーキテクチャの将来対応 🚀
将来を見据えた設計には、成長を予測することが求められる。正確なトラフィック数を予測することはできないが、スケーラビリティを考慮した設計は可能である。
- スキーマの進化: データモデルへの非中断的な変更を可能にするマイグレーション戦略を使用する。
- 水平スケーラビリティ: 最初からシャーディングをサポートできるようにテーブルを設計する。
- ストレージの分離: ストレージ層とコンピューティング層を分離して、それぞれを独立してスケーリングできるようにする。
これらの原則に従うことで、本番環境のプレッシャーに耐えうる基盤を構築できます。目標は現在の問題を修正することではなく、将来の課題に適応できる耐障害性の高いシステムを構築することです。
11. 主な診断ステップの要約 📝
要するに、本番負荷障害を診断するには、複数の層にわたるアプローチが必要です。
- ERDの確認: 過度に複雑な関係性や欠落しているインデックスがないか確認する。
- クエリの分析: フルテーブルスキャンや非効率な結合パスがないか確認する。
- ロックの監視: タイムアウトを引き起こす競合ポイントを特定する。
- ハードウェアの確認: ストレージとメモリがボトルネックになっていないか確認する。
- スキーマの最適化: パーティショニングとインデックス戦略を適用する。
- アプリケーションの再構築: データベース呼び出しの回数を減らし、トランザクション処理を最適化する。
この構造化されたアプローチに従うことで、症状ではなく根本原因に取り組むことができます。パフォーマンスチューニングは、忍耐と正確さを要する反復的なプロセスです。
12. スキーマの耐障害性についての最終的な考察 🧠
堅牢なデータモデルは、いかなる高性能アプリケーションの基盤です。トラフィックパターンの変化に応じて常に注意を払い、適応する意欲が必要です。関係性、インデックス、並行処理の微細な点を理解することで、本番環境での障害を引き起こす一般的な落とし穴を回避できます。
図はシステムそのものではなく、あくまでツールであることを思い出してください。設計の真の試練はライブ環境で行われます。モニタリングは厳密に、インデックスは清潔に、トランザクションは短く保ちましょう。これらの実践を徹底すれば、データアーキテクチャはビジネス成長の信頼できる基盤となります。
常に警戒を怠らないでください。メトリクスを監視し、必要に応じて再構築してください。あなたのシステムが感謝するでしょう。

