











Lorsqu’une architecture de base de données conçue sur papier fonctionne parfaitement dans un environnement de test mais s’effondre sous le trafic du monde réel, le décalage réside souvent entre le modèle visuel et la réalité d’exécution. Un schéma Entité-Relation (ERD) est un plan, pas un moteur vivant. Toutefois, lorsque les développeurs parlent d’un « ERD qui échoue sous charge », ils décrivent généralement une conception de schéma dérivée de ce diagramme, incapable de supporter les exigences de production. Ce guide aborde les goulets d’étranglement structurels, logiques et de performance qui font que les modèles relationnels peinent lorsque le volume de données et la concurrence augmentent brusquement.
Diagnostiquer ces problèmes exige une compréhension approfondie de la manière dont les relations entre les données se traduisent en opérations d’E/S, en contention de verrous et en utilisation de la mémoire. Nous explorerons les points de friction où les choix de conception entrent en conflit avec les limites matérielles et les modèles de trafic. En identifiant les symptômes spécifiques d’une défaillance structurelle, vous pouvez restructurer votre modèle de données pour assurer la montée en charge sans compromettre l’intégrité des données.
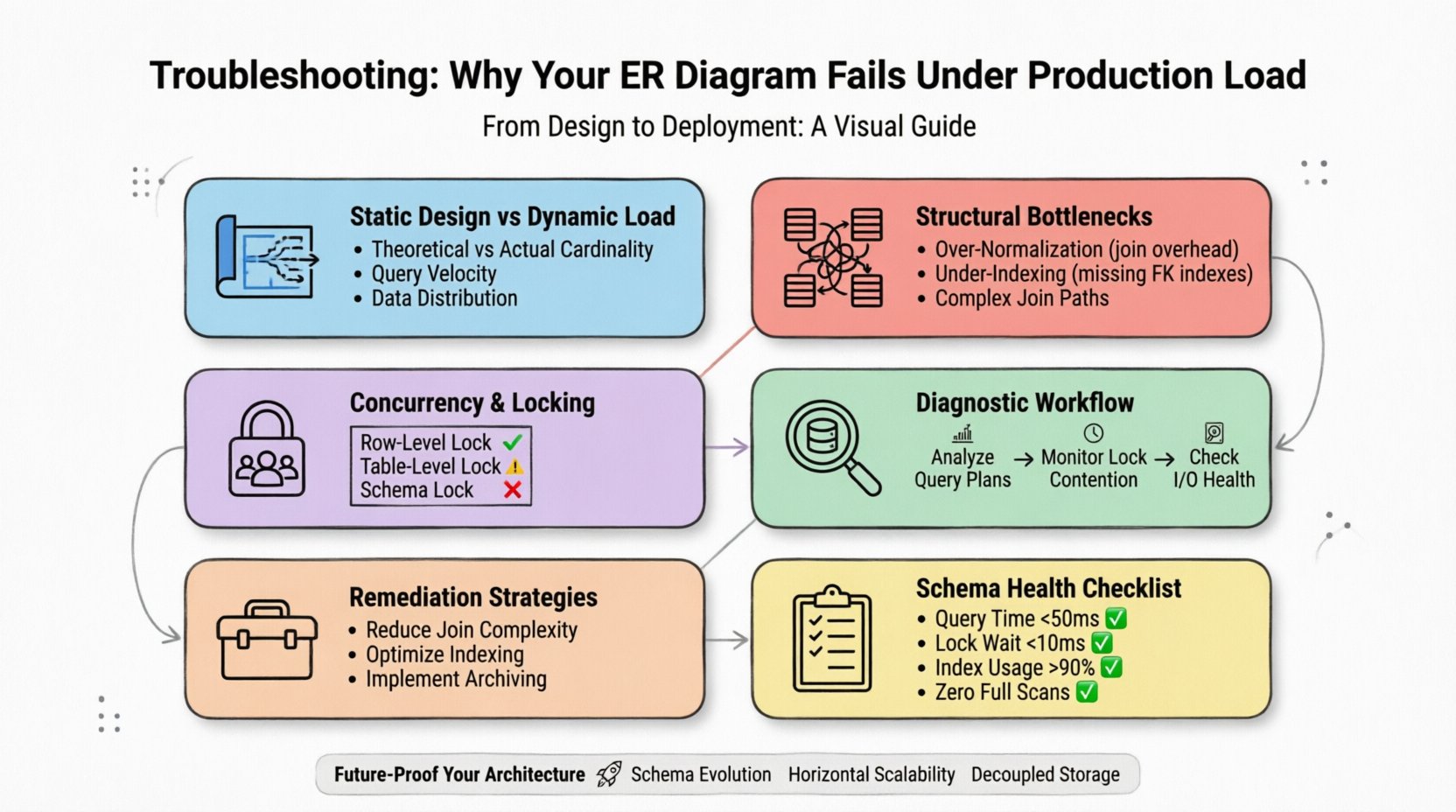
1. L’écart entre la conception statique et la charge dynamique ⚡
Un schéma ER représente des relations potentielles et des types de données. Il ne tient pas compte de la vitesse des écritures, de la répartition des lectures ou des contraintes de stockage physique du moteur sous-jacent. Un modèle qui semble équilibré sur un tableau blanc cache souvent des inefficacités qui ne se manifestent qu’au moment où des millions de lignes sont interrogées simultanément.
- Cardinalité théorique vs. réelle : Les diagrammes supposent des relations un-à-un ou un-à-plusieurs. En production, ces relations deviennent souvent plusieurs-à-plusieurs avec des chemins de jointure complexes qui épuisent les ressources CPU.
- Vitesse des requêtes : Un schéma peut gérer quelques milliers de lectures par seconde, mais s’arrêter net à des milliers par milliseconde en raison de la granularité des verrous.
- Répartition des données : Les points chauds apparaissent lorsque les données ne sont pas réparties uniformément sur les nœuds de stockage, entraînant un équilibrage de charge inégal.
Pour diagnostiquer efficacement, vous devez cesser de traiter le schéma comme un artefact statique. Il s’agit d’une ressource dynamique qui doit être surveillée aussi attentivement que le serveur lui-même.
2. Goulets d’étranglement structurels courants 📉
La cause la plus fréquente de dégradation des performances réside dans la structure des relations elle-même. La manière dont les tables sont connectées détermine la façon dont le moteur parcourt les données. Les jointures complexes sont la principale cause des temps d’exécution lents des requêtes.
2.1 Risques liés à la sur-normalisation
Bien que la normalisation réduise la redondance, une normalisation excessive augmente le nombre de jointures nécessaires pour récupérer un ensemble de données unique. Dans les scénarios à forte charge, chaque jointure est un point potentiel de défaillance.
- Surcharge des jointures : Chaque opération de jointure exige que la base de données corresponde les lignes de deux tables. Si ces tables sont grandes et manquent d’index appropriés, le moteur effectue un balayage complet de la table.
- Profondeur des transactions : Les schémas fortement normalisés nécessitent souvent des transactions longues pour récupérer des données associées, conservant les verrous pendant de longues périodes.
- Efficacité du cache : Les données normalisées sont fragmentées sur plusieurs pages, ce qui réduit l’efficacité du cache du pool de tampons.
2.2 Sous-indexation et chemins d’accès
Un ERD bien structuré implique des modèles d’accès. Si le diagramme ne correspond pas au volume réel de requêtes, le moteur de base de données ne peut pas trouver le chemin le plus rapide vers les données.
- Index des clés étrangères : Les clés étrangères manquent souvent d’index, ce qui entraîne une baisse des performances lors de la suppression ou de la mise à jour des enregistrements parents.
- Ordre des clés composées : L’ordre des colonnes dans un index composé est important. Si les requêtes filtrent sur la deuxième colonne en premier, l’index peut être ignoré.
- Index sélectifs manquants : Sans index sur les colonnes à haute cardinalité, le moteur effectue un balayage complet des tables pour trouver des valeurs spécifiques.
3. Concurrence et mécanismes de verrouillage 🔒
Lorsque la charge augmente, la concurrence devient la contrainte principale. Plusieurs utilisateurs tentant de modifier les mêmes données créent une contention. Si la conception du schéma ne tient pas compte de la granularité des verrous, le système peut entrer en blocage ou expirer.
| Type de verrou | Impact sur la charge | Symptôme typique |
|---|---|---|
| Verrou au niveau des lignes | Impact minimal, haute concurrence | Faible latence, haut débit |
| Verrou au niveau des tables | Impact élevé, bloque les autres utilisateurs | Erreurs de délai d’attente, requêtes bloquées |
| Verrou de schéma | Bloque tout accès pendant les opérations DDL | Panne systémique pendant la maintenance |
3.1 Blocages et conditions de course
Les blocages se produisent lorsque deux transactions attendent l’une l’autre pour libérer des ressources. Cela est souvent dû à des ordres de verrouillage incohérents dans la logique d’application interagissant avec le schéma.
- Niveaux d’isolement des transactions : Les niveaux d’isolement plus élevés (comme Serializable) assurent une sécurité mais réduisent considérablement la concurrence.
- Montée en verrouillage : Si une transaction verrouille trop de lignes, le moteur peut passer à un verrou de table, bloquant toutes les autres opérations.
- Transactions longues : Les opérations qui détiennent des verrous pendant des secondes au lieu de millisecondes créent des goulets d’étranglement pour toute la file d’attente.
4. Volume des données et stratégies de partitionnement 📊
À mesure que les données augmentent, les limites physiques de la couche de stockage deviennent évidentes. Un schéma fonctionnant pour 10 000 lignes peut échouer catastrophiquement avec 100 millions de lignes. Le partitionnement est la méthode utilisée pour diviser les grandes tables en morceaux plus petits et gérables.
- Partitionnement vertical : Déplacer les colonnes peu fréquemment accessibles vers une table séparée réduit la taille de la table principale, améliorant les taux de réussite du cache pour les données chaudes.
- Partitionnement horizontal : Répartir les lignes sur plusieurs segments physiques (sharding) répartit la charge sur plusieurs nœuds de stockage.
- Partitionnement basé sur le temps : Pour les données transactionnelles, le partitionnement par date permet au moteur de supprimer instantanément les anciennes partitions sans verrouiller toute la table.
5. Flux de diagnostic des pannes de production 🔍
Lorsque le système ralentit, vous avez besoin d’une approche systématique pour identifier la cause racine. L’optimisation aléatoire gaspille souvent des ressources. Suivez ce flux de travail pour localiser le problème.
5.1 Analyser les plans d’exécution des requêtes
Le plan d’exécution révèle la manière dont le moteur de base de données entend récupérer les données. Recherchez des indicateurs spécifiques d’inefficacité.
- Analyse complète des tables :Indique un index manquant ou une requête qui demande trop de données.
- Recherches par clé :Suggère que le moteur doit passer plusieurs fois entre l’index et les données de la table, ce qui augmente l’E/S.
- Opérations de tri :Le tri de grands jeux de résultats consomme une mémoire et une puissance CPU importantes.
5.2 Surveiller la contention sur les verrous
Utilisez des outils système pour surveiller les événements d’attente. Des temps d’attente élevés sur les verrous indiquent que le schéma ne peut pas supporter le niveau de concurrence actuel.
- Métriques de temps d’attente :Suivez la durée pendant laquelle les transactions attendent des ressources.
- Graphiques de blocages :Examinez les données historiques pour voir quelles requêtes ont causé des conflits.
- File d’attente d’attente des verrous :Surveillez le nombre de transactions en attente de la même ressource.
5.3 Vérifier l’état du sous-système E/S
Même avec un schéma parfait, un stockage lent entraînera des pannes. Assurez-vous que l’infrastructure sous-jacente correspond aux modèles d’accès aux données.
- Limites de débit :Vérifiez si le périphérique de stockage est saturé par des opérations de lecture/écriture.
- Pic de latence :Des temps de réponse inconstants provenant du niveau de stockage indiquent souvent une dégradation matérielle.
- Efficacité du pool de tampons :Si la base de données passe plus de temps à lire sur le disque que dans la mémoire, le schéma ou le volume de données est trop important pour le cache.
6. Stratégies de remédiation pour l’optimisation du schéma 🛠️
Une fois le goulot d’étranglement identifié, appliquez des modifications ciblées. Le restructuration d’un schéma de production exige une prudence pour éviter la perte de données ou une interruption.
6.1 Réduction de la complexité des jointures
Simplifiez les relations qui causent le plus de friction. Cela implique souvent la dénormalisation de zones spécifiques du modèle.
- Vues matérialisées : Pré-calculer les jointures complexes et stocker le résultat dans une table séparée pour une récupération rapide.
- Colonnes calculées : Stocker les données dérivées directement dans la table pour éviter le calcul au moment de la requête.
- Acheminement vers les répliques de lecture : Envoyer les requêtes intensives en lecture vers une réplique qui contient une copie dénormalisée des données.
6.2 Optimisation de la stratégie d’indexation
Les index sont l’outil le plus efficace pour accélérer les recherches, mais ils ont un coût sur les opérations d’écriture.
- Index filtrés : Créer des index uniquement sur des sous-ensembles de données fréquemment interrogés.
- Index couvrants : Inclure toutes les colonnes nécessaires à une requête dans l’index pour éviter d’accéder à la table principale.
- Maintenance des index : Reconstituer ou réorganiser régulièrement les index pour éviter la fragmentation causée par des mises à jour fréquentes.
6.3 Mise en œuvre des suppressions douces et de l’archivage
Les données actives sont plus rapides à interroger que les données historiques. Déplacer les anciennes données hors de la table principale améliore les performances.
- Tables d’archivage : Déplacer les enregistrements plus anciens qu’un certain seuil vers une couche de stockage séparée, plus froide.
- Suppressions douces : Marquer les enregistrements comme supprimés sans les supprimer, en maintenant la structure de la table stable tout en masquant logiquement les données.
- Politiques de rétention des données : Automatiser l’élimination des données inutiles pour éviter une croissance incontrôlée.
7. Liste de contrôle d’évaluation de la santé du schéma ✅
Avant de déployer des modifications, vérifiez votre modèle selon ces critères pour vous assurer qu’il peut supporter la charge de production.
| Critères | Condition de réussite | Condition d’échec |
|---|---|---|
| Temps moyen de requête | < 50 ms | > 500 ms |
| Temps d’attente du verrouillage | < 10 ms | > 100 ms |
| Utilisation des index | > 90% | < 50% |
| Balayages complets de table | Zéro | Fréquent |
Effectuer régulièrement des audits de votre modèle de données par rapport à ces métriques garantit que la conception évolue en parallèle avec vos besoins commerciaux. Un schéma statique finira par devenir une charge. Le suivi continu et les ajustements progressifs sont les seules façons de maintenir la fiabilité.
8. Comprendre les modèles de requêtes et les charges de travail 📈
La performance ne dépend pas uniquement du schéma ; elle dépend de la manière dont ce schéma est utilisé. Comprendre le profil de charge de travail est essentiel pour optimiser le modèle.
- OLTP par rapport à OLAP :Le traitement en ligne des transactions (OLTP) nécessite des écritures rapides et petites. Le traitement analytique en ligne (OLAP) nécessite des lectures rapides et importantes. Un schéma optimisé pour l’un peine souvent avec l’autre.
- Modèles à écriture intense : Si votre application écrit fréquemment, privilégiez l’efficacité des index et minimisez le verrouillage lors des écritures.
- Modèles à lecture intense : Si votre application lit fréquemment, privilégiez les stratégies de mise en cache et les réplicas de lecture.
9. Le rôle de la logique d’application dans les performances de la base de données 💻
Souvent, le problème ne réside pas dans la base de données, mais dans la manière dont l’application interagit avec elle. Les problèmes de requêtes N+1 sont un exemple classique d’inefficacité au niveau de l’application qui se traduit par une défaillance de la base de données.
- Opérations en bloc : Envoyer des milliers d’instructions d’insertion individuelles est plus lent qu’une seule opération par lot.
- Chargement paresseux : Récupérer les données par petits morceaux peut entraîner un nombre excessif de voyages vers la base de données.
- Pool de connexions : Une gestion inefficace des connexions à la base de données peut épuiser les ressources disponibles pendant les pics de charge.
Optimiser la couche d’application réduit la pression sur le schéma, permettant à la base de données de fonctionner dans ses paramètres conçus.
10. Rendre votre architecture de données résistante aux évolutions futures 🚀
Concevoir pour l’avenir exige de prévoir la croissance. Bien que vous ne puissiez pas prédire les chiffres exacts de trafic, vous pouvez concevoir pour l’élasticité.
- Évolution du schéma : Utilisez des stratégies de migration qui permettent des modifications non disruptives du modèle de données.
- Évolutivité horizontale : Concevez les tables pour qu’elles supportent le fractionnement dès le départ.
- Stockage déconnecté : Séparez la couche de stockage de la couche de calcul afin de les faire évoluer indépendamment.
En suivant ces principes, vous construisez une fondation capable de résister aux pressions du production. L’objectif n’est pas seulement de résoudre les problèmes actuels, mais de créer un système résilient capable d’adapter aux défis futurs.
11. Résumé des étapes clés de diagnostic 📝
Pour résumer, diagnostiquer les échecs de charge en production implique une approche multicouche.
- Examinez le MCD : Vérifiez les relations trop complexes et les index manquants.
- Analysez les requêtes : Recherchez les analyses de table entières et les chemins de jointure inefficaces.
- Surveillez les verrous : Identifiez les points de contention qui provoquent des timeouts.
- Vérifiez le matériel : Assurez-vous que le stockage et la mémoire ne sont pas des goulets d’étranglement.
- Optimisez le schéma : Appliquez des stratégies de partitionnement et d’indexation.
- Refactorisez l’application : Réduisez le nombre d’appels à la base de données et optimisez la gestion des transactions.
En suivant cette approche structurée, vous vous assurez de traiter la cause racine plutôt que les symptômes. L’optimisation des performances est un processus itératif qui exige de la patience et de la précision.
12. Réflexions finales sur la résilience du schéma 🧠
Un modèle de données robuste est le pilier de toute application à haute performance. Il exige une attention constante et une volonté d’adaptation au fur et à mesure que les schémas de trafic évoluent. En comprenant les subtilités des relations, de l’indexation et de la concurrence, vous pouvez éviter les pièges courants qui entraînent des échecs en production.
Souvenez-vous que le diagramme est un outil, pas le système lui-même. Le véritable test de votre conception a lieu dans l’environnement en production. Gardez votre surveillance serrée, vos index propres et vos transactions courtes. Avec ces pratiques en place, votre architecture de données servira de fondation fiable à la croissance de votre entreprise.
Restez vigilant. Surveillez vos métriques. Refactorisez lorsque nécessaire. Votre système vous remerciera.

