











Когда архитектура базы данных, разработанная на бумаге, безупречно работает в песочнице, но рушится под реальной нагрузкой, разрыв часто заключается между визуальной моделью и реальностью выполнения. Диаграмма сущность-связь (ERD) — это эскиз, а не работающий двигатель. Однако, когда разработчики говорят о «сбое ERD под нагрузкой», они обычно имеют в виду проектирование схемы, основанное на этой диаграмме, которое не может выдерживать производственные требования. Данное руководство рассматривает структурные, логические и производительностные узкие места, из-за которых реляционные модели испытывают трудности при резком росте объема данных и уровня параллелизма.
Диагностика этих проблем требует глубокого понимания того, как отношения между данными трансформируются в операции ввода-вывода, конфликты блокировок и использование памяти. Мы исследуем точки соприкосновения, где решения по проектированию сталкиваются с ограничениями оборудования и паттернами трафика. Определив конкретные симптомы структурных сбоев, вы сможете перестроить свою модель данных для масштабирования без ущерба целостности данных.
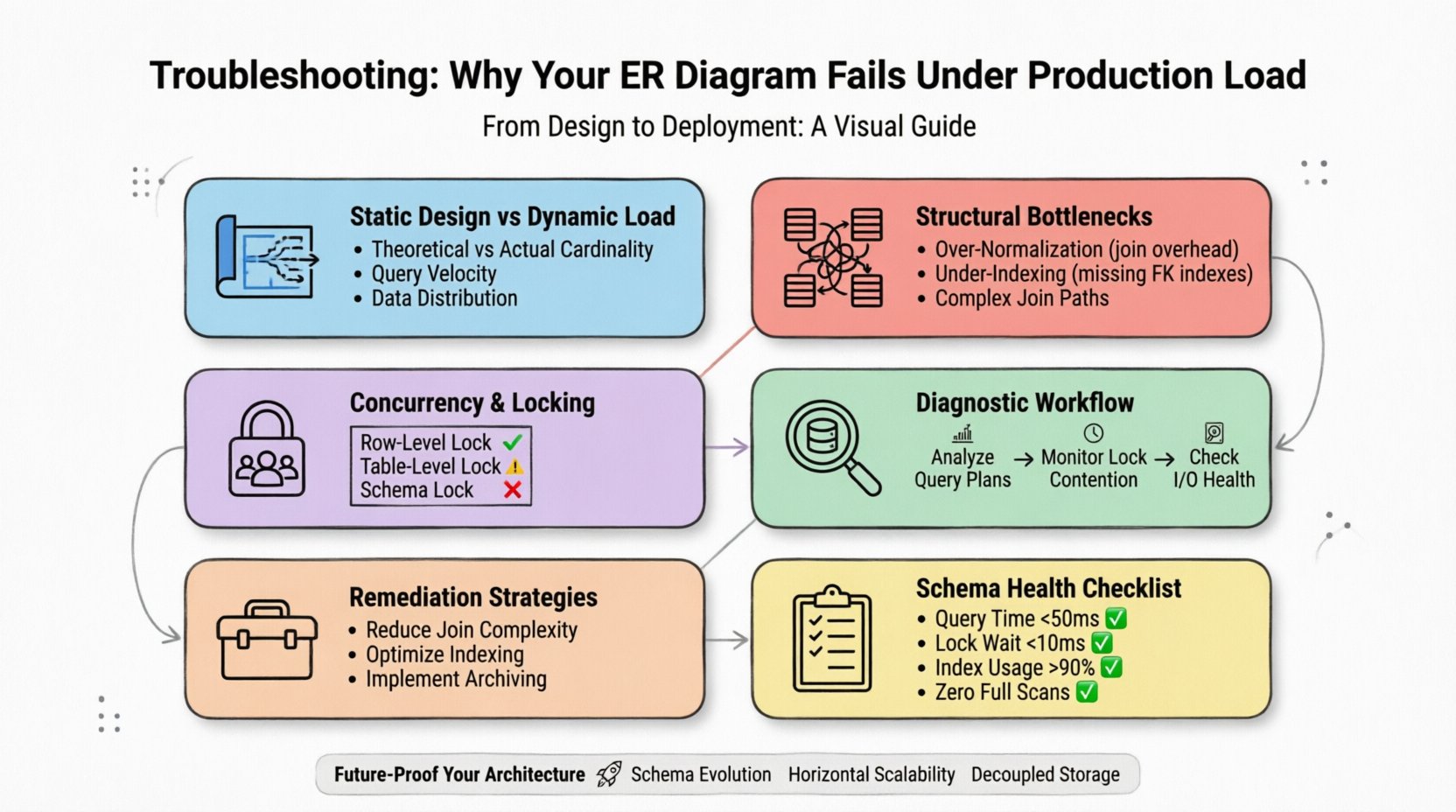
1. Разрыв между статическим проектированием и динамической нагрузкой ⚡
Диаграмма сущность-связь отображает потенциальные отношения и типы данных. Она не учитывает скорость записи, распределение чтения или физические ограничения хранения базовой системы. Модель, которая кажется сбалансированной на доске, часто скрывает неэффективности, проявляющиеся только при одновременном запросе миллионов строк.
- Теоретическая vs. Реальная кардинальность:На диаграммах предполагаются отношения один к одному или один ко многим. В производственной среде они часто превращаются в многие к многим с сложными путями соединения, исчерпывающими ресурсы ЦП.
- Скорость запросов:Схема может обрабатывать несколько тысяч чтений в секунду, но захлебываться при тысячах запросов в миллисекунду из-за мелкого масштаба блокировок.
- Распределение данных:Пиковые нагрузки возникают, когда данные не равномерно распределены по узлам хранения, что приводит к неравномерному распределению нагрузки.
Чтобы эффективно диагностировать, необходимо перестать рассматривать схему как статический объект. Это динамический ресурс, который необходимо мониторить так же тщательно, как и сам сервер.
2. Распространённые структурные узкие места 📉
Наиболее частая причина снижения производительности — сама структура отношений. То, как таблицы связаны между собой, определяет, как движок обходит данные. Сложные соединения являются основной причиной медленного выполнения запросов.
2.1 Риски чрезмерной нормализации
Хотя нормализация уменьшает избыточность, чрезмерная нормализация увеличивает количество соединений, необходимых для получения одного набора данных. В условиях высокой нагрузки каждое соединение может стать потенциальной точкой отказа.
- Накладные расходы на соединение:Каждая операция соединения требует от базы данных сопоставления строк из двух таблиц. Если эти таблицы большие и не имеют правильного индексирования, движок выполняет полное сканирование таблицы.
- Глубина транзакции:Глубоко нормализованные схемы часто требуют длительных транзакций для получения связанных данных, удерживая блокировки в течение длительного времени.
- Эффективность кэширования:Нормализованные данные фрагментированы по нескольким страницам, что снижает эффективность кэширования в буферном пуле.
2.2 Недостаточное индексирование и пути доступа
Хорошо структурированная ERD предполагает паттерны доступа. Если диаграмма не соответствует фактической нагрузке запросов, движок базы данных не сможет найти самый быстрый путь к данным.
- Индексы внешних ключей:Внешние ключи часто не имеют индексов, что приводит к падению производительности при удалении или обновлении родительских записей.
- Порядок столбцов в составном ключе:Порядок столбцов в составном индексе имеет значение. Если запросы фильтруют по второму столбцу первым, индекс может быть проигнорирован.
- Отсутствующие выборочные индексы:Без индексов на столбцах с высокой кардинальностью движок сканирует всю таблицу, чтобы найти конкретные значения.
3. Параллелизм и механизмы блокировки 🔒
Когда нагрузка возрастает, параллелизм становится основным ограничением. Несколько пользователей, пытающихся изменить одни и те же данные, вызывают конфликты. Если при проектировании схемы не учитывается степень детализации блокировок, система может заблокироваться или превысить время ожидания.
| Тип блокировки | Влияние на нагрузку | Типичный симптом |
|---|---|---|
| Блокировка на уровне строки | Минимальное влияние, высокая параллельность | Низкая задержка, высокая пропускная способность |
| Блокировка на уровне таблицы | Высокое влияние, блокирует других пользователей | Ошибки превышения времени ожидания, зависшие запросы |
| Блокировка схемы | Блокирует весь доступ во время DDL | Системный сбой во время обслуживания |
3.1 Взаимоблокировки и гонки
Взаимоблокировки возникают, когда две транзакции ждут друг друга освобождения ресурсов. Это часто вызвано несогласованностью порядка блокировок в логике приложения, взаимодействующей со схемой.
- Уровни изоляции транзакций: Более высокие уровни изоляции (например, Serializable) обеспечивают безопасность, но значительно снижают параллелизм.
- Повышение уровня блокировки: Если транзакция блокирует слишком много строк, движок может повысить уровень блокировки до таблицы, блокируя все остальные операции.
- Долгие транзакции: Операции, удерживающие блокировки секунды вместо миллисекунд, создают узкие места для всей очереди.
4. Объём данных и стратегии партиционирования 📊
По мере роста данных физические ограничения слоя хранения становятся очевидными. Схема, работающая для 10 000 строк, может катастрофически сбоить при 100 миллионах строк. Партиционирование — это метод, используемый для разделения больших таблиц на более мелкие и управляемые части.
- Вертикальное партиционирование: Перемещение редко используемых столбцов в отдельную таблицу уменьшает размер основной таблицы, повышая коэффициент попадания в кэш для горячих данных.
- Горизонтальное партиционирование: Разделение строк по нескольким физическим сегментам (шардинг) распределяет нагрузку между несколькими узлами хранения.
- Партиционирование по времени: Для транзакционных данных партиционирование по дате позволяет движку мгновенно удалять старые партиции, не блокируя всю таблицу.
5. Диагностический рабочий процесс для сбоев в производстве 🔍
Когда система замедляется, вам нужен системный подход для выявления корневой причины. Случайная оптимизация часто приводит к потере ресурсов. Следуйте этому рабочему процессу, чтобы точно определить проблему.
5.1 Проанализируйте планы выполнения запросов
План выполнения показывает, каким образом движок базы данных намерен извлечь данные. Обратите внимание на конкретные признаки неэффективности.
- Полные сканирования таблиц:Указывает на отсутствие индекса или на запрос, который запрашивает слишком много данных.
- Поиск по ключу:Свидетельствует о том, что движку приходится многократно перескакивать между индексом и данными таблицы, что увеличивает объем ввода-вывода.
- Операции сортировки:Сортировка больших наборов результатов потребляет значительное количество памяти и процессорного времени.
5.2 Мониторинг конкуренции за блокировки
Используйте системные инструменты для мониторинга событий ожидания. Долгое время ожидания блокировок указывает на то, что схема не может поддерживать текущий уровень параллелизма.
- Метрики времени ожидания:Отслеживайте продолжительность времени, в течение которого транзакции ожидают ресурсов.
- Графы взаимоблокировок:Проанализируйте исторические данные, чтобы определить, какие запросы вызвали конфликты.
- Очередь ожидания блокировок:Мониторьте количество транзакций, ожидающих одного и того же ресурса.
5.3 Проверка состояния подсистемы ввода-вывода
Даже при идеальной схеме медленное хранилище приведет к сбоям. Убедитесь, что базовая инфраструктура соответствует паттернам доступа к данным.
- Ограничения пропускной способности:Проверьте, не перегружен ли накопитель операциями чтения и записи.
- Всплески задержек:Несогласованное время отклика со стороны слоя хранения часто указывает на износ оборудования.
- Эффективность буферного пула:Если база данных тратит больше времени на чтение с диска, чем из памяти, схема или объем данных слишком велик для кэша.
6. Стратегии устранения проблем для оптимизации схемы 🛠️
Как только узкое место будет выявлено, применяйте целенаправленные изменения. Рефакторинг схемы в рабочей среде требует осторожности, чтобы избежать потери данных или простоев.
6.1 Снижение сложности соединений
Упростите отношения, вызывающие наибольшее напряжение. Часто это требует денормализации конкретных участков модели.
- Материализованные представления: Предварительно вычислите сложные соединения и сохраните результат в отдельной таблице для быстрого извлечения.
- Вычисляемые столбцы: Храните производные данные непосредственно в таблице, чтобы избежать вычислений во время выполнения запроса.
- Маршрутизация к репликам для чтения: Отправляйте запросы с высокой нагрузкой на чтение на реплику, которая хранит денормализованную копию данных.
6.2 Оптимизация стратегии индексации
Индексы — наиболее эффективный инструмент для ускорения поиска, но они имеют стоимость при операциях записи.
- Фильтрованные индексы: Создавайте индексы только на подмножествах данных, которые часто запрашиваются.
- Покрывающие индексы: Включайте все столбцы, необходимые для запроса, в индекс, чтобы избежать обращения к основной таблице.
- Обслуживание индексов: Регулярно перестраивайте или перестраивайте индексы, чтобы предотвратить фрагментацию, вызванную частыми обновлениями.
6.3 Реализация мягкого удаления и архивирования
Активные данные быстрее извлекаются, чем исторические. Перемещение старых данных из основной таблицы улучшает производительность.
- Таблицы архива: Перемещайте записи, старше определённого порога, в отдельный, более холодный слой хранения.
- Мягкое удаление: Отмечайте записи как удалённые, не удаляя их, сохраняя структуру таблицы стабильной, при этом логически скрывая данные.
- Политики хранения данных: Автоматизируйте очистку ненужных данных, чтобы предотвратить неограниченный рост.
7. Чек-лист оценки состояния схемы ✅
Перед развертыванием изменений проверьте свою модель по этим критериям, чтобы убедиться, что она сможет выдержать нагрузку в продакшене.
| Критерии | Условие прохождения | Условие неудачи |
|---|---|---|
| Среднее время выполнения запроса | < 50 мс | > 500 мс |
| Время ожидания блокировки | < 10 мс | > 100 мс |
| Использование индексов | > 90% | < 50% |
| Полные сканирования таблиц | Ноль | Часто |
Регулярная проверка вашей модели данных по этим метрикам гарантирует, что архитектура будет развиваться вместе с потребностями вашего бизнеса. Статическая схема в конечном итоге станет активом, который будет мешать. Непрерывный мониторинг и постепенные корректировки — единственный способ поддерживать надежность.
8. Понимание паттернов запросов и рабочих нагрузок 📈
Производительность — это не только схема; это то, как используется схема. Понимание профиля рабочей нагрузки необходимо для настройки модели.
- OLTP против OLAP:Обработка онлайн-транзакций (OLTP) требует быстрых, небольших записей. Обработка онлайн-аналитики (OLAP) требует быстрых, больших чтений. Схема, оптимизированная под одну задачу, часто испытывает трудности с другой.
- Паттерны с интенсивной записью: Если ваше приложение часто записывает данные, уделяйте приоритет эффективности индексов и минимизируйте блокировки при записи.
- Паттерны с интенсивным чтением: Если ваше приложение часто читает данные, уделяйте приоритет стратегиям кэширования и репликам для чтения.
9. Роль логики приложения в производительности базы данных 💻
Часто проблема не в базе данных, а в том, как приложение взаимодействует с ней. Проблемы с запросами N+1 — классический пример неэффективности на уровне приложения, проявляющейся как сбой базы данных.
- Массовые операции: Отправка тысяч отдельных операторов вставки медленнее, чем одна пакетная операция.
- Ленивая загрузка: Получение данных небольшими порциями может вызвать чрезмерное количество往返 к базе данных.
- Пул соединений: Неэффективное управление соединениями с базой данных может исчерпать доступные ресурсы в пиковые нагрузки.
Оптимизация уровня приложения снижает нагрузку на схему, позволяя базе данных работать в рамках заданных параметров.
10. Защита вашей архитектуры данных от будущих изменений 🚀
Проектирование будущего требует прогнозирования роста. Хотя вы не можете точно предсказать объем трафика, вы можете проектировать систему с учетом масштабируемости.
- Эволюция схемы: Используйте стратегии миграции, которые позволяют вносить ненарушающие работу изменения в модель данных.
- Горизонтальное масштабирование: Проектируйте таблицы с учетом шардинга с самого начала.
- Отдельное хранение: Разделите слой хранения данных и слой вычислений, чтобы масштабировать их независимо.
Следуя этим принципам, вы создаете основу, способную выдерживать нагрузки в производственной среде. Цель заключается не просто в устранении текущих проблем, а в создании устойчивой системы, способной адаптироваться к будущим вызовам.
11. Краткое резюме ключевых диагностических шагов 📝
Для повторения: диагностика сбоев нагрузки в производственной среде требует многоуровневого подхода.
- Просмотрите ERD: Проверьте наличие чрезмерно сложных связей и отсутствующих индексов.
- Анализ запросов: Ищите полные сканирования таблиц и неэффективные пути соединений.
- Мониторинг блокировок: Определите точки конкуренции, вызывающие тайм-ауты.
- Проверка оборудования: Убедитесь, что хранилище и память не являются узкими местами.
- Оптимизация схемы: Примените стратегии партиционирования и индексирования.
- Рефакторинг приложения: Сократите количество вызовов к базе данных и оптимизируйте обработку транзакций.
Следуя этому структурированному подходу, вы обеспечиваете решение коренной причины, а не симптомов. Оптимизация производительности — это итеративный процесс, требующий терпения и точности.
12. Заключительные мысли о устойчивости схемы 🧠
Надежная модель данных — это основа любого высокопроизводительного приложения. Она требует постоянного внимания и готовности адаптироваться к изменению паттернов трафика. Понимая нюансы связей, индексирования и параллелизма, вы можете избежать распространенных ошибок, приводящих к сбоям в производственной среде.
Помните, что диаграмма — это инструмент, а не сама система. Подлинное испытание вашего дизайна происходит в живой среде. Держите мониторинг под контролем, индексы — чистыми, а транзакции — короткими. При соблюдении этих практик ваша архитектура данных станет надежной основой для роста вашего бизнеса.
Будьте бдительны. Мониторьте свои метрики. Рефакторьте при необходимости. Ваша система скажет вам спасибо.

