










Каждый архитектор данных сталкивается с одним и тем же решающим моментом. Вы начинаете с чистой, нормализованной схемы. База данных без труда справляется с тысячами записей. Запросы возвращаются за миллисекунды. Диаграмма сущность-связь (ERD) выглядит элегантно. Затем бизнес растёт. Уровень принятия пользователями резко возрастает. Объём данных взрывается. Внезапно система замедляется. Соединения занимают секунды. Блокировки блокируют транзакции. Первоначальный дизайн ERD становится бременем.
В этом руководстве описывается переход от базы данных небольшого масштаба к высоконагруженной производственной среде. Мы исследуем структурные изменения, необходимые для поддержания производительности без ущерба целостности данных. Основное внимание уделяется логическому проектированию, стратегиям индексации и методам партиционирования. Здесь не упоминается конкретное программное обеспечение производителя; принципы применимы к любой реляционной системе хранения.
🏗️ Основа: проектирование с учётом роста
Когда приложение начинается, приоритетом является скорость разработки. ERD точно отражает бизнес-область. Нормализация высока. Третья нормальная форма (3NF) часто является целью. Это минимизирует избыточность. Обеспечивает согласованность данных. Однако такой подход предполагает определённый паттерн нагрузки. Предполагает простые запросы. Предполагает, что набор данных помещается в память без проблем.
По мере роста объёма данных предположения перестают выполняться. Стоимость соединений растёт логарифмически. Объём данных, сканируемых процессором запросов, растёт линейно. Ввод-вывод на диске становится узким местом. Архитектура требует перехода от логической чистоты к физической производительности.
Определение точки разрушения
Прежде чем рефакторить, необходимо понять, где система начинает сбоить. Переход от тысяч до миллионов записей меняет физику извлечения данных. Обратите внимание на следующие признаки:
- Задержка запросов: Запросы, которые занимали 5 мс, теперь занимают 500 мс.
- Конкуренция блокировок: Транзакции ждут освобождения блокировок.
- Пропускная способность записи: Вставки замедляются из-за обслуживания индексов.
- Нагрузка на память: Буферный пул не может кэшировать часто используемые таблицы.
- Перегрузка сети: Большие наборы результатов потребляют пропускную способность.
Когда появляются эти симптомы, ERD должен эволюционировать. Просто добавить больше оборудования недостаточно. Необходимо оптимизировать структуру.
🔍 Этап 1: Рефакторинг схемы
Первый шаг при масштабировании — аудит диаграммы сущность-связь. Необходимо проверить, поддерживает ли текущая структура паттерны запросов, необходимые при масштабировании.
Нормализация против денормализации
Нормализация уменьшает дублирование данных. Упрощает обновления. Однако вынуждает использовать соединения. Соединения дорогостоящие при масштабировании. Денормализация вводит избыточность. Уменьшает количество соединений. Ускоряет чтение. Это компромисс, который необходимо тщательно управлять.
n
Рассмотрите следующие стратегии:
- Работа с высокой нагрузкой на чтение: Денормализуйте часто используемые атрибуты. Храните их непосредственно в основной таблице, чтобы избежать соединений.
- Работа с высокой нагрузкой на запись: Сохраняйте нормализацию. Избегайте каскадных обновлений в нескольких таблицах.
- Гибридный подход: Держите основную схему нормализованной. Создавайте материализованные представления или сводные таблицы для отчетности.
В нашем исследовании случаев исходный дизайн предусматривал соединение десяти таблиц для получения профиля одного пользователя. Это приводило к чрезмерной дисковой I/O. За счет денормализации наиболее часто используемых атрибутов пользователя в основную таблицу профиля мы сократили количество соединений с десяти до одного.
Обработка больших текстовых полей
Хранение больших строк (CLOB) в основной таблице может замедлить чтение страниц. Движку базы данных необходимо загрузить всю строку для проверки первичного ключа. Если строка слишком велика, она может быть вытеснена на диск.
Наилучшие практики включают:
- Разделяйте большие текстовые поля на связанную таблицу.
- Получайте текстовое поле только при явном запросе.
- Храните ссылки (идентификаторы), а не содержимое, в основном индексе.
📈 Этап 2: Стратегии индексации
Индексы — это движущая сила производительности запросов. Хорошо спроектированная ERD полагается на индексы для быстрого поиска данных. По мере роста количества записей размер индексов также увеличивается. Поддержание индексов потребляет ресурсы записи.
Составные индексы
Индексы по одному столбцу часто недостаточны. Составные индексы позволяют движку фильтровать по нескольким критериям одновременно. Порядок столбцов в индексе имеет значение. Самый выборочный столбец должен идти первым.
Например, если вы фильтруете по статус и дату, но статус имеет низкую выборочность (например, только три значения), поместите дату первым. Это быстрее сужает пространство поиска.
Покрывающие индексы
Покрывающий индекс включает все столбцы, необходимые для запроса. База данных может удовлетворить запрос, используя только индекс. Ей не нужно обращаться к данным таблицы (куче). Это значительный выигрыш по производительности.
- Включите все
SELECTстолбцы. - Включите все
WHEREстолбцы условия. - Включите все
ПО СОРТИРОВКЕстолбцов.
Обслуживание индексов
Индексы не являются статическими. Со временем они фрагментируются. Они растут вместе с данными. Требуется регулярное обслуживание.
- Перестройка:Фрагментирует структуру индекса.
- Организация:Переупорядочивает листовые страницы без полной перестройки.
- Мониторинг: Отслеживайте неиспользуемые индексы. Удаляйте их, чтобы сэкономить место для записи.
🗄️ Этап 3: Разделение и шардинг
Когда одна таблица превышает объем одного диска или пула памяти, становится необходимым разделение. Это разделяет логическую таблицу на более мелкие физические сегменты.
Разделение по диапазону
Этот метод делит данные на основе диапазонного значения. Часто используется для дат или последовательных идентификаторов. Например, разделение данных по годам.
- Преимущество: Запросы, фильтрующие по ключу разделения, сканируют только один сегмент.
- Недостаток: Запросы без ключа разделения сканируют все сегменты (полное сканирование таблицы).
Хэш-разделение
Этот метод равномерно распределяет данные по сегментам с использованием хэш-функции по столбцу ключа. Это предотвращает появление «горячих точек».
- Преимущество: Равномерное распределение данных.
- Недостаток: Запросы по диапазону становятся дорогостоящими.
Горизонтальное и вертикальное шардинг
Шардинг продолжает разделение, распределяя данные по нескольким экземплярам базы данных.
| Стратегия | Описание | Лучшее применение |
|---|---|---|
| Горизонтальное шардинг | Разделение строк по базам данных на основе ключа. | Высокий объем записей, большие наборы данных. |
| Вертикальное шардирование | Разделение столбцов по базам данных на основе использования. | Большие столбцы, различные паттерны чтения. |
| Шардирование по каталогу | Используйте таблицу поиска для маршрутизации запросов. | Сложная логика маршрутизации, динамическое масштабирование. |
В нашем исследовании мы реализовали горизонтальное шардирование на основе идентификатора пользователя. Это позволило нам распределить нагрузку между пятью узлами. Каждый узел обрабатывал примерно 20% трафика. Это снизило нагрузку на любой отдельный движок хранения.
🚀 Этап 4: Оптимизация запросов
Даже при идеальной схеме плохие запросы убивают производительность. Оптимизатор выбирает план выполнения. Вы должны его направлять.
Избегание полного сканирования таблицы
Всегда убедитесь, что запрос использует индекс. Если он сканирует всю таблицу, он будет превышать время ожидания при масштабировании. Проверьте план выполнения. Ищите «Сканирование индекса» или «Поиск по индексу», а не «Сканирование таблицы».
Ограничение наборов результатов
Никогда не получайте все записи. Используйте пагинацию. Ограничьте количество строк, возвращаемых за один запрос.
- Ограничение смещения: Стандартная пагинация. Может быть медленной при глубоких смещениях.
- Пагинация по ключу: Используйте последний просмотренный идентификатор для получения следующей страницы. Гораздо быстрее.
Пакетная обработка операций
Не выполняйте миллионы обновлений в одной транзакции. Разбейте их на пакеты.
- Фиксируйте после каждого 1000 записей.
- Это уменьшает рост файла журнала.
- Это предотвращает длительные блокировки.
⚠️ Распространённые ошибки, которые следует избегать
Масштабирование вводит новые риски. Будьте внимательны к этим распространённым ошибкам.
- Чрезмерное индексирование: Слишком много индексов замедляет запись. Контролируйте производительность записи.
- Пренебрежение типами данных: Использование
VARCHARдля идентификаторов фиксированной длины теряется место. ИспользуйтеINTилиBIGINT. - Запросы N+1: Получение связанных данных в цикле. Используйте жадную загрузку или пакетные соединения.
- Мягкое удаление: Отметка записей как удалённых оставляет их в таблице навсегда. Архивируйте старые данные.
- Блокировка схем: Изменение структуры таблицы во время работы системы. Используйте онлайн-изменения схемы.
📊 Показатели производительности для отслеживания
Вы не можете улучшить то, что не измеряете. Установите базовый уровень. Непрерывно отслеживайте эти показатели.
- Строк в секунду: Насколько быстро записываются данные?
- Запросов в секунду: Сколько трафика чтения существует?
- Коэффициент попадания в кэш: Происходит ли чтение из памяти или диска?
- Время ожидания блокировки: Ожидают ли транзакции ресурсов?
- Дисковый ввод-вывод: Насыщен ли накопитель?
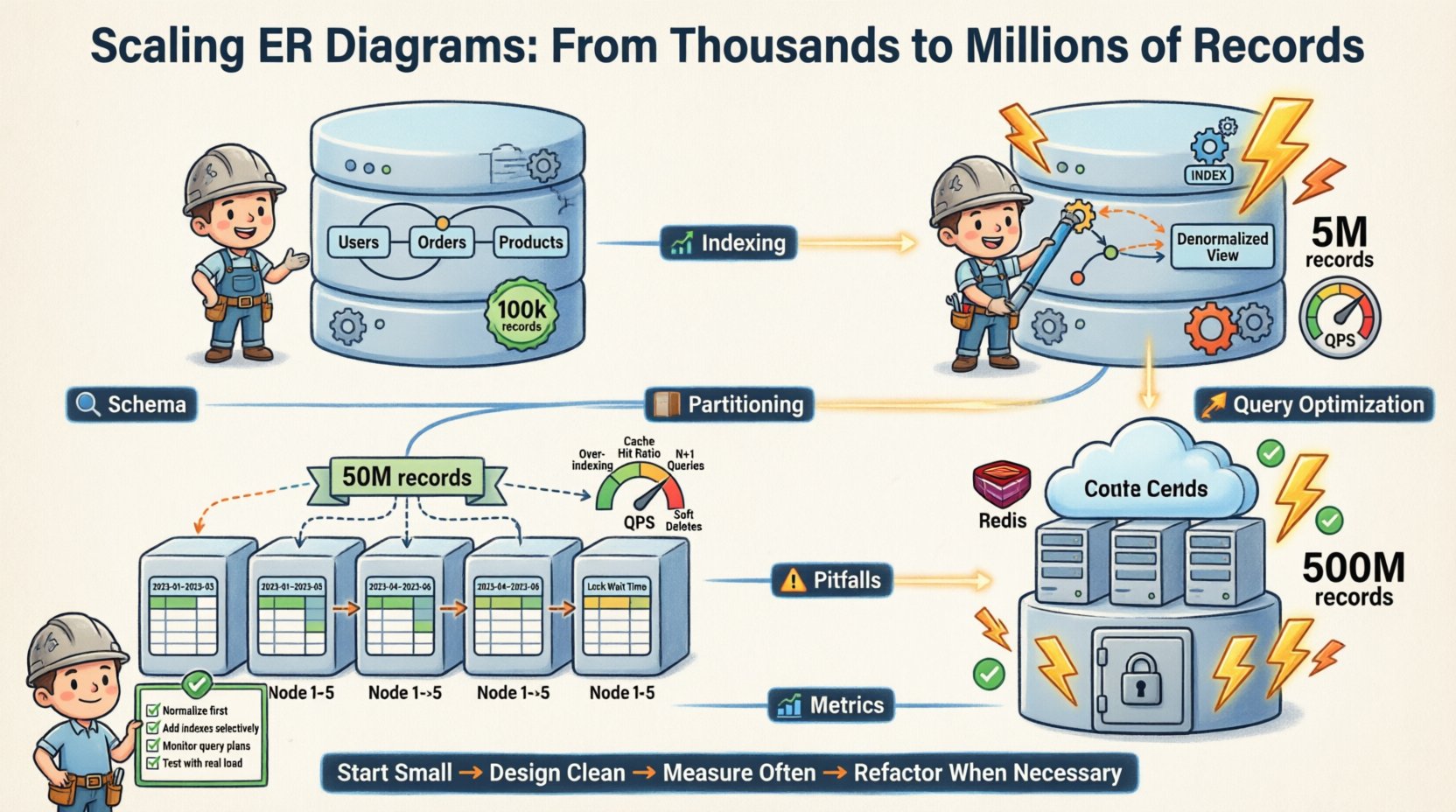
🔄 Эволюция ERD
Диаграмма сущность-связь не является статическим документом. Это живой чертёж. По мере масштабирования системы ERD меняется.
Вот последовательность эволюции нашей схемы:
- Фаза 1 (Начало): Полностью нормализовано. 3НФ. Один экземпляр базы данных. 100 тыс. записей.
- Фаза 2 (Рост): Денормализация таблиц с высокой нагрузкой на чтение. Добавлены индексы. Одиночный экземпляр. 5 млн записей.
- Этап 3 (Масштабирование): Горизонтальное партиционирование. Разделение по идентификатору пользователя. Многоэкземплярный режим. 50 млн записей.
- Этап 4 (Зрелость): Архивирование старых данных. Интеграция кэширующего слоя. Реплики для чтения. 500 млн записей.
Каждый этап требовал конкретных изменений в логической модели. Основные отношения оставались неизменными. Физическая реализация адаптировалась.
🛠️ Чек-лист по масштабированию
Используйте этот чек-лист перед развертыванием в среде с высокой нагрузкой.
- ☐ Проверьте, что все внешние ключи имеют соответствующие индексы.
- ☐ Проверьте наличие
SELECT *в коде приложения. - ☐ Убедитесь, что ключи партиционирования равномерно распределены.
- ☐ Протестируйте сценарии отказа для узлов базы данных.
- ☐ Проверьте настройки пула соединений.
- ☐ Планируйте архивирование и очистку данных.
- ☐ Реализуйте оповещения мониторинга по медленным запросам.
- ☐ Документируйте процедуры изменения схемы.
💡 Заключительные мысли о надежности
Масштабирование диаграммы сущность-связь — это не только скорость. Это надежность. Система, которая быстрая, но рушится под нагрузкой, бесполезна. Система, которая медленная, но стабильная, управляема.
Цель — спроектировать структуру, которая учитывает рост. Необходимо балансировать стоимость хранения данных и стоимость вычислений. Необходимо балансировать согласованность и доступность. Это фундаментальные компромиссы распределенных систем.
Следуя этим принципам, вы можете обеспечить устойчивость вашей архитектуры данных. Вы сможете перейти от тысяч к миллионам записей, не нарушая работу системы. Ключевыми факторами являются подготовка, тестирование и понимание внутренних механизмов вашей системы хранения данных.
Начинайте с малого. Проектируйте чисто. Часто измеряйте. Рефакторьте при необходимости. Это путь к устойчивому масштабированию.

