










Mỗi kiến trúc viên dữ liệu đều phải đối mặt với khoảnh khắc then chốt như nhau. Bạn bắt đầu với một lược đồ sạch, được chuẩn hóa. Cơ sở dữ liệu xử lý hàng nghìn bản ghi một cách dễ dàng. Các truy vấn trả về trong vài mili giây. Sơ đồ quan hệ thực thể (ERD) trông tinh tế. Rồi doanh nghiệp phát triển. Người dùng tăng nhanh. Dữ liệu bùng nổ. Bỗng nhiên, hệ thống chậm lại. Các thao tác nối (join) mất vài giây. Các khóa (lock) chặn các giao dịch. Thiết kế ERD ban đầu trở thành gánh nặng.
Hướng dẫn này chi tiết quá trình chuyển đổi từ cơ sở dữ liệu quy mô nhỏ sang môi trường sản xuất khối lượng lớn. Chúng tôi khám phá những thay đổi cấu trúc cần thiết để duy trì hiệu suất mà không hy sinh tính toàn vẹn dữ liệu. Trọng tâm vẫn nằm ở thiết kế logic, chiến lược chỉ mục và kỹ thuật phân vùng. Không có phần mềm nhà cung cấp cụ thể nào được nhắc đến ở đây; các nguyên tắc này áp dụng cho bất kỳ bộ lưu trữ quan hệ nào.
🏗️ Cơ sở ban đầu: Thiết kế để phát triển
Khi một ứng dụng bắt đầu, ưu tiên là tốc độ phát triển. ERD phản ánh chính xác lĩnh vực kinh doanh. Chuẩn hóa ở mức cao. Dạng chuẩn hóa thứ ba (3NF) thường là mục tiêu. Điều này giảm thiểu sự trùng lặp. Đảm bảo tính nhất quán dữ liệu. Tuy nhiên, cách tiếp cận này giả định một mô hình công việc cụ thể. Nó giả định các truy vấn đơn giản. Nó giả định dữ liệu có thể vừa vặn trong bộ nhớ.
Khi tập dữ liệu mở rộng, các giả định ban đầu thất bại. Chi phí của các thao tác nối tăng theo cấp số logarit. Khối lượng dữ liệu được bộ xử lý truy vấn quét tăng theo tuyến tính. I/O đĩa trở thành điểm nghẽn. Kiến trúc cần thay đổi từ sự thuần khiết về mặt logic sang hiệu suất vật lý.
Xác định điểm giới hạn
Trước khi tái cấu trúc, bạn phải hiểu rõ hệ thống đang thất bại ở đâu. Sự chuyển đổi từ hàng nghìn đến hàng triệu bản ghi thay đổi bản chất của việc truy xuất dữ liệu. Hãy tìm những dấu hiệu sau:
- Độ trễ truy vấn: Các truy vấn từng mất 5ms nay mất 500ms.
- Cạnh tranh khóa: Các giao dịch phải chờ khóa được giải phóng.
- Tốc độ ghi: Các thao tác chèn chậm lại do duy trì chỉ mục.
- Áp lực bộ nhớ: Bộ đệm không thể lưu trữ tạm các bảng thường xuyên truy cập.
- Bão hòa mạng: Các tập kết quả lớn tiêu tốn băng thông.
Khi những triệu chứng này xuất hiện, ERD phải tiến hóa. Bạn không thể đơn giản thêm phần cứng. Bạn phải tối ưu cấu trúc.
🔍 Giai đoạn 1: Tái cấu trúc lược đồ
Bước đầu tiên trong việc mở rộng là kiểm tra sơ đồ quan hệ thực thể. Bạn cần xác minh xem cấu trúc hiện tại có hỗ trợ các mẫu truy vấn cần thiết ở quy mô lớn hay không.
Chuẩn hóa so với phi chuẩn hóa
Chuẩn hóa giảm thiểu sự trùng lặp dữ liệu. Nó đơn giản hóa việc cập nhật. Tuy nhiên, nó buộc phải thực hiện các thao tác nối. Các thao tác nối tốn kém ở quy mô lớn. Phi chuẩn hóa tạo ra sự trùng lặp. Nó giảm số thao tác nối. Nó tăng tốc độ đọc. Đây là một sự đánh đổi cần được quản lý cẩn trọng.
n
Hãy cân nhắc các chiến lược sau:
- Công việc chủ yếu đọc:Phi chuẩn hóa các thuộc tính thường xuyên truy cập. Lưu trữ chúng trực tiếp trong bảng chính để tránh các thao tác nối.
- Công việc chủ yếu ghi:Duy trì chuẩn hóa. Tránh cập nhật lan truyền qua nhiều bảng.
- Phương pháp kết hợp: Giữ cho lược đồ chính được chuẩn hóa. Tạo các view được vật chất hóa hoặc các bảng tóm tắt để báo cáo.
Trong nghiên cứu trường hợp của chúng tôi, thiết kế ban đầu có mười bảng được nối để truy xuất hồ sơ người dùng duy nhất. Điều này gây ra I/O đĩa quá mức. Bằng cách loại bỏ chuẩn hóa các thuộc tính người dùng phổ biến nhất vào bảng hồ sơ chính, chúng tôi đã giảm số lượng nối từ mười xuống còn một.
Xử lý các trường văn bản lớn
Lưu trữ các chuỗi lớn (CLOBs) trong bảng chính có thể làm chậm việc đọc trang. Bộ động cơ cơ sở dữ liệu phải tải toàn bộ hàng để kiểm tra khóa chính. Nếu hàng quá lớn, nó có thể bị tràn ra đĩa.
Các thực hành tốt nhất bao gồm:
- Tách các trường văn bản lớn thành một bảng liên kết.
- Chỉ lấy trường văn bản khi được yêu cầu rõ ràng.
- Lưu trữ tham chiếu (ID) thay vì nội dung trong chỉ mục chính.
📈 Giai đoạn 2: Chiến lược chỉ mục
Các chỉ mục là động cơ của hiệu suất truy vấn. Một sơ đồ ERD được thiết kế tốt phụ thuộc vào các chỉ mục để tìm kiếm dữ liệu nhanh chóng. Khi số lượng bản ghi tăng, kích thước chỉ mục cũng tăng lên. Việc duy trì các chỉ mục tiêu tốn tài nguyên ghi.
Chỉ mục kết hợp
Các chỉ mục cột đơn thường không đủ. Chỉ mục kết hợp cho phép bộ xử lý lọc theo nhiều tiêu chí cùng lúc. Thứ tự các cột trong chỉ mục là quan trọng. Cột có tính chọn lọc cao nhất nên được đặt đầu tiên.
Ví dụ, nếu bạn lọc theo trạng thái và ngày, nhưng trạng thái có tính chọn lọc thấp (ví dụ, chỉ có ba giá trị), hãy đặt ngày đầu tiên. Điều này thu hẹp không gian tìm kiếm nhanh hơn.
Chỉ mục bao phủ
Chỉ mục bao phủ bao gồm tất cả các cột cần thiết cho truy vấn. Cơ sở dữ liệu có thể đáp ứng truy vấn chỉ bằng cách sử dụng chỉ mục. Nó không cần phải truy cập dữ liệu bảng (heap). Đây là một lợi thế hiệu suất đáng kể.
- Bao gồm tất cả các
SELECTcột. - Bao gồm tất cả các
WHEREcột điều kiện. - Bao gồm tất cả các
SẮP XẾP THEOcột.
Bảo trì chỉ mục
Các chỉ mục không phải là tĩnh. Chúng bị phân mảnh theo thời gian. Chúng tăng dần theo dữ liệu. Cần bảo trì định kỳ.
- Tái tạo lại:Phân mảnh lại cấu trúc chỉ mục.
- Tái tổ chức:Sắp xếp lại các trang lá mà không cần tái tạo toàn bộ.
- Theo dõi:Theo dõi các chỉ mục không được sử dụng. Loại bỏ chúng để tiết kiệm không gian ghi.
🗄️ Giai đoạn 3: Chia tách và Phân mảnh
Khi một bảng duy nhất vượt quá dung lượng của một ổ đĩa hoặc bộ nhớ đơn lẻ, việc chia tách trở nên cần thiết. Điều này chia một bảng logic thành các đoạn vật lý nhỏ hơn.
Chia tách theo khoảng giá trị
Phương pháp này chia dữ liệu dựa trên giá trị khoảng. Thường được dùng cho ngày tháng hoặc ID tuần tự. Ví dụ: chia dữ liệu theo năm.
- Lợi ích:Các truy vấn lọc theo khóa chia tách chỉ quét một đoạn.
- Nhược điểm:Các truy vấn không có khóa chia tách sẽ quét tất cả các đoạn (quét toàn bộ bảng).
Chia tách theo hàm băm
Phương pháp này phân bố dữ liệu đều trên các đoạn bằng cách sử dụng hàm băm trên một cột khóa. Điều này ngăn ngừa hiện tượng điểm nóng.
- Lợi ích:Phân bố dữ liệu đều.
- Nhược điểm:Các truy vấn theo khoảng trở nên tốn kém.
Phân mảnh ngang so với Phân mảnh dọc
Phân mảnh tiến xa hơn so với chia tách bằng cách phân bố dữ liệu trên nhiều phiên bản cơ sở dữ liệu.
| Chiến lược | Mô tả | Trường hợp sử dụng tốt nhất |
|---|---|---|
| Phân mảnh ngang | Chia các hàng thành nhiều cơ sở dữ liệu dựa trên một khóa. | Lưu lượng ghi cao, dữ liệu lớn. |
| Chia theo chiều dọc | Chia các cột thành nhiều cơ sở dữ liệu dựa trên mức độ sử dụng. | Các cột lớn, các mẫu đọc khác nhau. |
| Chia theo thư mục | Sử dụng bảng tra cứu để định tuyến các truy vấn. | Logic định tuyến phức tạp, mở rộng động. |
Trong nghiên cứu trường hợp của chúng tôi, chúng tôi đã triển khai chia theo chiều ngang dựa trên ID người dùng. Điều này cho phép chúng tôi phân phối tải trên năm nút. Mỗi nút xử lý khoảng 20% lưu lượng truy cập. Điều này đã giảm tải cho bất kỳ bộ động cơ lưu trữ nào.
🚀 Giai đoạn 4: Tối ưu hóa truy vấn
Ngay cả với lược đồ hoàn hảo, các truy vấn kém vẫn làm giảm hiệu suất. Bộ tối ưu sẽ chọn phương án thực thi. Bạn cần hướng dẫn nó.
Tránh quét toàn bộ bảng
Luôn đảm bảo truy vấn sử dụng chỉ mục. Nếu nó quét toàn bộ bảng, sẽ bị hết thời gian khi mở rộng quy mô. Kiểm tra kế hoạch thực thi. Tìm kiếm “Index Scan” hoặc “Index Seek” thay vì “Table Scan”.
Hạn chế tập kết quả
Không bao giờ lấy tất cả các bản ghi. Sử dụng phân trang. Giới hạn số lượng hàng trả về cho mỗi yêu cầu.
- Giới hạn offset:Phân trang tiêu chuẩn. Có thể chậm khi offset sâu.
- Phân trang theo khóa:Sử dụng ID cuối cùng đã thấy để lấy trang tiếp theo. Nhanh hơn nhiều.
Gom các thao tác
Không thực hiện hàng triệu cập nhật trong một giao dịch duy nhất. Chia chúng thành các lô nhỏ.
- Ghi lại sau mỗi 1.000 bản ghi.
- Điều này làm giảm sự gia tăng kích thước tệp nhật ký.
- Điều này ngăn chặn các khóa kéo dài.
⚠️ Những sai lầm phổ biến cần tránh
Mở rộng quy mô mang lại những rủi ro mới. Hãy cảnh giác với những sai lầm phổ biến này.
- Tạo chỉ mục quá nhiều:Quá nhiều chỉ mục làm chậm thao tác ghi. Theo dõi hiệu suất ghi.
- Bỏ qua kiểu dữ liệu: Sử dụng
VARCHARcho ID có độ dài cố định sẽ tốn không gian. Sử dụngINThoặcBIGINT. - Câu truy vấn N+1: Lấy dữ liệu liên quan trong vòng lặp. Sử dụng tải trước hoặc nối nhóm batch.
- Xóa mềm: Đánh dấu bản ghi là đã xóa sẽ giữ chúng trong bảng mãi mãi. Lưu trữ dữ liệu cũ.
- Khóa lược đồ: Thay đổi cấu trúc bảng khi hệ thống đang hoạt động. Sử dụng thay đổi lược đồ trực tuyến.
📊 Các chỉ số hiệu suất cần theo dõi
Bạn không thể cải thiện điều gì mà bạn không đo lường. Xác lập nền tảng ban đầu. Theo dõi các chỉ số này liên tục.
- Số hàng mỗi giây: Dữ liệu đang được ghi nhanh đến mức nào?
- Số truy vấn mỗi giây: Có bao nhiêu lưu lượng đọc tồn tại?
- Tỷ lệ hit bộ nhớ đệm: Các thao tác đọc đang truy cập vào bộ nhớ hay ổ đĩa?
- Thời gian chờ khóa: Các giao dịch có đang chờ tài nguyên không?
- I/O ổ đĩa: Bộ nhớ có đang bão hòa không?
🔄 Sự phát triển của sơ đồ ERD
Sơ đồ quan hệ thực thể không phải là tài liệu tĩnh. Đó là bản vẽ sống động. Khi hệ thống mở rộng, sơ đồ ERD cũng thay đổi.
Dưới đây là tiến trình phát triển lược đồ của chúng ta:
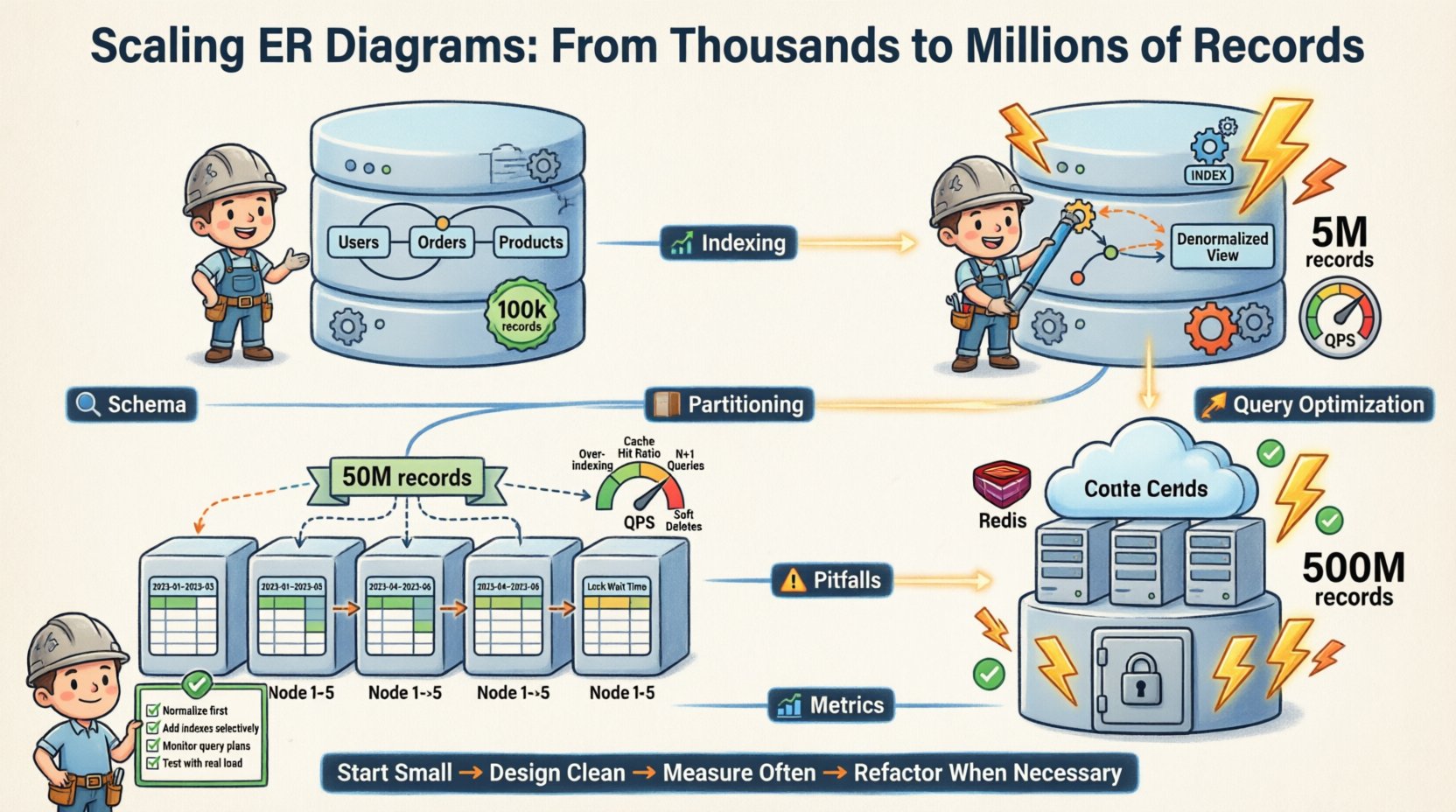
- Giai đoạn 1 (Bắt đầu): Hoàn toàn chuẩn hóa. 3NF. Một phiên bản cơ sở dữ liệu duy nhất. 100.000 bản ghi.
- Giai đoạn 2 (Phát triển): Chuẩn hóa lại các bảng đọc nhiều. Thêm chỉ mục. Đơn vị duy nhất. 5 triệu bản ghi.
- Giai đoạn 3 (Mở rộng):Chia theo chiều ngang. Chia theo ID người dùng. Nhiều đơn vị. 50 triệu bản ghi.
- Giai đoạn 4 (Chín muồi):Lưu trữ dữ liệu cũ. Tích hợp lớp bộ nhớ đệm. Bản sao đọc. 500 triệu bản ghi.
Mỗi giai đoạn đều yêu cầu những thay đổi cụ thể đối với mô hình logic. Các mối quan hệ cốt lõi vẫn ổn định. Việc triển khai vật lý đã điều chỉnh theo.
🛠️ Danh sách kiểm tra cho việc mở rộng
Sử dụng danh sách kiểm tra này trước khi triển khai vào môi trường có khối lượng cao.
- ☐ Xác minh tất cả các khóa ngoại đều có chỉ mục hỗ trợ.
- ☐ Kiểm tra xem có
SELECT *trong mã ứng dụng. - ☐ Đảm bảo các khóa phân vùng được phân bố đều.
- ☐ Kiểm thử các tình huống chuyển đổi khẩn cấp cho các nút cơ sở dữ liệu.
- ☐ Xem xét lại cài đặt nhóm kết nối.
- ☐ Lên kế hoạch cho việc lưu trữ dữ liệu cũ và dọn dẹp.
- ☐ Triển khai cảnh báo giám sát cho các truy vấn chậm.
- ☐ Tài liệu hóa các quy trình thay đổi lược đồ.
💡 Những suy nghĩ cuối cùng về độ tin cậy
Mở rộng một sơ đồ quan hệ thực thể không chỉ là về tốc độ. Đó là về độ tin cậy. Một hệ thống nhanh nhưng sập khi chịu tải là vô dụng. Một hệ thống chậm nhưng ổn định thì có thể kiểm soát được.
Mục tiêu là thiết kế một cấu trúc có thể dự đoán sự phát triển. Bạn phải cân bằng chi phí lưu trữ với chi phí tính toán. Bạn phải cân bằng tính nhất quán với khả năng sẵn sàng. Đây là những thỏa hiệp cốt lõi của các hệ thống phân tán.
Bằng cách tuân theo những nguyên tắc này, bạn có thể đảm bảo kiến trúc dữ liệu của mình vẫn vững chắc. Bạn có thể xử lý việc chuyển đổi từ hàng ngàn lên hàng triệu bản ghi mà không bị sập. Chìa khóa nằm ở sự chuẩn bị. Chìa khóa nằm ở kiểm thử. Chìa khóa nằm ở việc hiểu rõ cơ chế hoạt động nền tảng của bộ động lưu trữ của bạn.
Bắt đầu nhỏ. Thiết kế sạch sẽ. Đo lường thường xuyên. Tái cấu trúc khi cần thiết. Đây là con đường dẫn đến sự mở rộng bền vững.

