










每位数据架构师都会面临同一个关键时刻。你从一个清晰、规范化的模式开始。数据库轻松处理数千条记录。查询在毫秒级返回。实体关系图(ERD)看起来非常优雅。然后,业务增长了。用户采纳率飙升。数据量急剧膨胀。突然间,系统变慢了。连接操作需要数秒。锁阻塞了事务。原始的ERD设计反而成了负担。
本指南详细介绍了从小型数据库过渡到高吞吐量生产环境的过程。我们探讨了在不牺牲数据完整性的前提下,维持性能所需的结构变更。重点仍在于逻辑设计、索引策略和分区技术。此处未提及任何特定厂商的软件;这些原则适用于任何关系型存储引擎。
🏗️ 基线:面向增长的设计
当应用程序刚启动时,首要任务是开发速度。ERD能准确反映业务领域。规范化程度很高。第三范式(3NF)通常是目标。这能最大限度减少冗余,确保数据一致性。然而,这种方法假设了特定的工作负载模式,假设查询简单,假设数据集能舒适地容纳在内存中。
随着数据集的扩大,这些假设就会失效。连接操作的成本呈对数增长。查询处理器扫描的数据量呈线性增长。磁盘I/O成为瓶颈。架构必须从逻辑纯粹性转向物理性能。
识别性能瓶颈
在重构之前,你必须了解系统在何处失效。从数千条记录过渡到数百万条记录,会改变数据检索的物理规律。请关注以下指标:
- 查询延迟:原本只需5毫秒的查询,现在需要500毫秒。
- 锁争用:事务在等待锁释放。
- 写入吞吐量:由于索引维护,插入操作变慢。
- 内存压力:缓冲池无法缓存频繁访问的表。
- 网络饱和:大型结果集消耗带宽。
当这些症状出现时,ERD必须随之演进。你不能简单地增加硬件。必须优化结构。
🔍 第一阶段:模式重构
扩展的第一步是审查实体关系图。你需要确认当前结构是否支持大规模下的查询模式。
规范化 vs. 反规范化
规范化减少了数据冗余,简化了更新操作。然而,它强制使用连接操作。在大规模下,连接操作成本高昂。反规范化引入了冗余,减少了连接操作,提升了读取速度。这是一个必须谨慎权衡的取舍。
n
考虑以下策略:
- 读取密集型工作负载:对频繁访问的属性进行反规范化。将其直接存储在主表中,以避免连接操作。
- 写入密集型工作负载:保持规范化。避免在多个表之间进行级联更新。
- 混合方法: 保持核心模式的规范化。为报告创建物化视图或汇总表。
在我们的案例研究中,原始设计需要连接十个表来检索单个用户资料,这导致了过度的磁盘I/O。通过将最常见的用户属性去规范化到主资料表中,我们将连接数量从十个减少到一个。
处理大文本字段
在主表中存储大字符串(CLOB)会减慢页面读取速度。数据库引擎必须加载整个行以检查主键。如果行太大,可能会溢出到磁盘。
最佳实践包括:
- 将大文本字段分离到一个关联表中。
- 仅在明确请求时才获取文本字段。
- 在主索引中存储引用(ID)而不是内容。
📈 第二阶段:索引策略
索引是查询性能的引擎。一个设计良好的ERD依赖索引来快速定位数据。随着记录的增长,索引大小也随之增加。维护索引会消耗写入资源。
复合索引
单列索引通常不够用。复合索引允许引擎同时根据多个条件进行过滤。索引中列的顺序很重要。最具有选择性的列应放在首位。
例如,如果你按状态和日期,但如果状态的选择性较低(例如,只有三个值),应将日期放在首位。这能更快地缩小搜索范围。
覆盖索引
覆盖索引包含查询所需的所有列。数据库仅使用索引即可满足查询,无需访问表数据(堆)。这能显著提升性能。
- 包含所有
SELECT列。 - 包含所有
WHERE子句中的列。 - 包含所有
按...排序列。
索引维护
索引并非静态的。它们会随时间碎片化,随着数据增长而变大。需要定期维护。
- 重建: 重组索引结构,消除碎片。
- 重组: 在不完全重建的情况下重新排序叶页。
- 监控: 跟踪未使用的索引。将其删除以节省写入空间。
🗄️ 阶段3:分区与分片
当单个表超过单个磁盘或内存池的容量时,分区就变得必要了。这会将一个逻辑表拆分为更小的物理段。
范围分区
该方法根据范围值来划分数据。常用于日期或连续ID。例如,按年份划分数据。
- 优点: 按分区键过滤的查询只需扫描一个段。
- 缺点: 不带分区键的查询需要扫描所有段(全表扫描)。
哈希分区
通过在键列上使用哈希函数,将数据均匀分布到各个段中。可防止热点问题。
- 优点: 数据分布均匀。
- 缺点: 范围查询变得昂贵。
水平分片与垂直分片
分片通过将数据分布在多个数据库实例上来进一步实现分区。
| 策略 | 描述 | 最佳使用场景 |
|---|---|---|
| 水平分片 | 根据键将行拆分到多个数据库中。 | 高写入量,大规模数据集。 |
| 垂直分片 | 根据使用情况将列拆分到多个数据库中。 | 大列,不同的读取模式。 |
| 目录分片 | 使用查找表来路由查询。 | 复杂的路由逻辑,动态扩展。 |
在我们的案例研究中,我们基于用户ID实现了水平分片。这使我们能够将负载分布在五个节点上。每个节点处理大约20%的流量。这降低了对任何单一存储引擎的负载。
🚀 第四阶段:查询优化
即使模式完美,糟糕的查询也会导致性能下降。优化器选择执行计划,你必须引导它。
避免全表扫描
始终确保查询使用了索引。如果扫描了整张表,在大规模情况下会导致超时。检查执行计划,寻找“索引扫描”或“索引查找”,而不是“表扫描”。
限制结果集
永远不要获取所有记录。使用分页。限制每次请求返回的行数。
- 偏移量限制: 标准分页。在深层偏移时可能较慢。
- 键集分页: 使用最后看到的ID来获取下一页。快得多。
批量操作
不要在单个事务中执行数百万次更新。应将其拆分为多个批次。
- 每处理1000条记录后提交。
- 这减少了日志文件的增长。
- 这可以防止长时间运行的锁。
⚠️ 需要避免的常见陷阱
扩展会引入新的风险。请注意这些常见错误。
- 过度创建索引: 索引过多会减慢写入速度。需监控写入性能。
- 忽略数据类型: 使用
VARCHAR用于固定长度的ID会浪费空间。使用INT或BIGINT. - N+1 查询: 在循环中获取相关数据。使用预加载或批量连接。
- 软删除: 标记记录为已删除会使其永远保留在表中。归档旧数据。
- 锁定模式: 在系统运行时更改表结构。使用在线模式变更。
📊 需要跟踪的性能指标
你无法改进自己无法衡量的东西。建立基线。持续监控这些指标。
- 每秒行数: 数据写入的速度有多快?
- 每秒查询数: 读取流量有多大?
- 缓存命中率: 读取操作是命中内存还是磁盘?
- 锁等待时间: 事务是否在等待资源?
- 磁盘I/O: 存储是否已饱和?
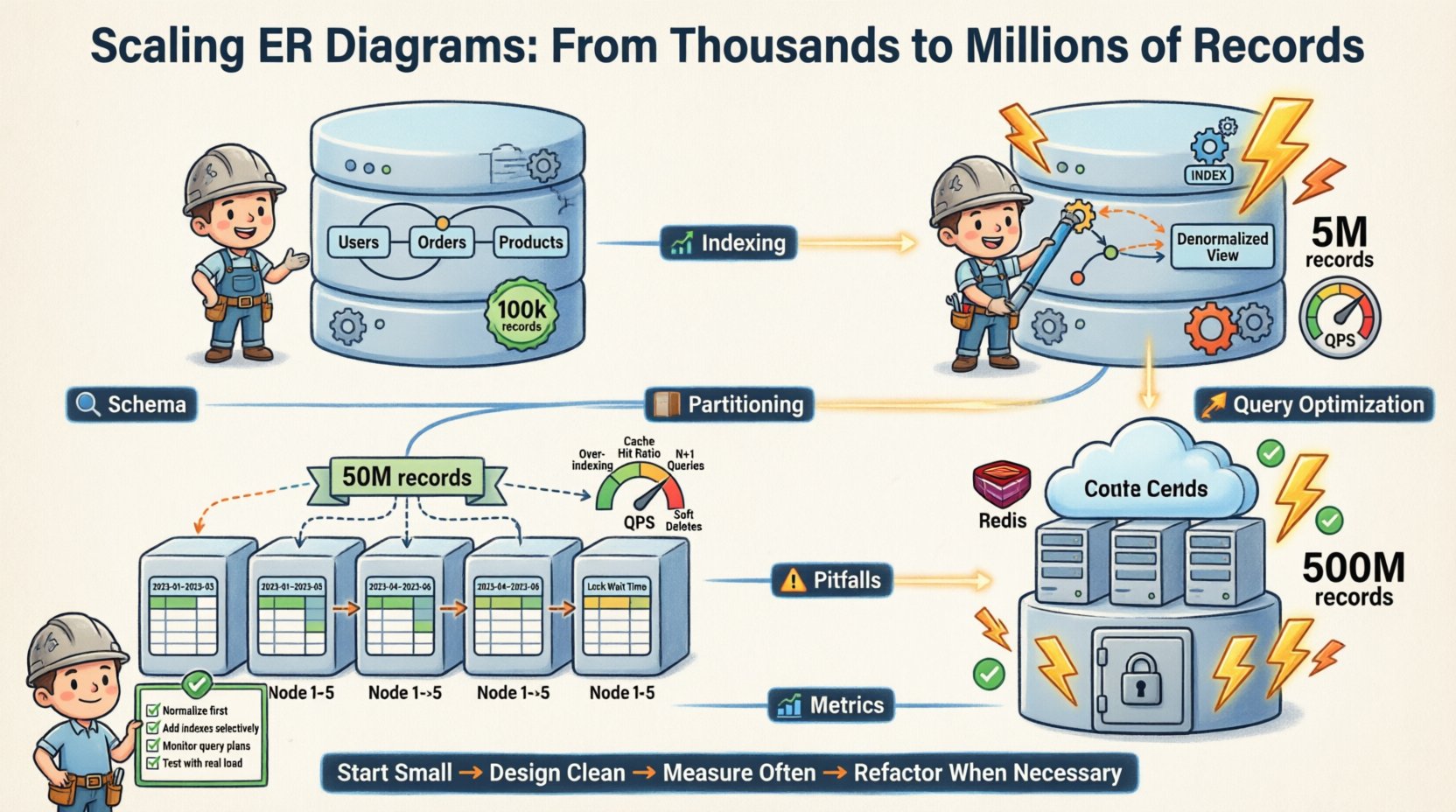
🔄 ERD的演变
实体关系图不是一份静态文档。它是一个动态的蓝图。随着系统规模的扩大,ERD也会随之变化。
以下是我们的模式演进过程:
- 阶段1(开始): 完全规范化。3NF。单个数据库实例。10万条记录。
- 阶段2(增长): 读取密集型表的反规范化。添加了索引。单实例。500万条记录。
- 第三阶段(扩展): 水平分区。按用户ID分片。多实例。5000万条记录。
- 第四阶段(成熟): 归档旧数据。集成缓存层。读取副本。5亿条记录。
每个阶段都需要对逻辑模型进行特定调整。核心关系保持稳定。物理实现随之适应。
🛠️ 扩展检查清单
在部署到高流量环境之前使用此检查清单。
- ☐ 验证所有外键都有支持索引。
- ☐ 检查是否存在
SELECT *在应用程序代码中。 - ☐ 确保分区键分布均匀。
- ☐ 测试数据库节点的故障转移场景。
- ☐ 审查连接池设置。
- ☐ 规划数据归档和清理。
- ☐ 为慢查询实现监控告警。
- ☐ 记录模式变更流程。
💡 关于可靠性的最终思考
扩展ER图不仅仅是关于速度,更关乎可靠性。一个在负载下会崩溃的快速系统毫无用处;一个虽然缓慢但稳定的系统则可以管理。
目标是设计一个能够预见增长的结构。你必须在存储成本与计算成本之间取得平衡。你必须在一致性与可用性之间取得平衡。这是分布式系统的基本权衡。
遵循这些原则,你可以确保数据架构保持稳健。你可以顺利实现从数千到数百万的过渡而不会崩溃。关键在于准备,关键在于测试,关键在于理解存储引擎的底层机制。
从小开始。设计简洁。经常度量。必要时重构。这是实现可持续扩展的道路。

