










数据构成了任何现代信息系统的核心。然而,没有结构的数据只是噪音。为了将原始信息转化为可操作的智能,我们依赖于结构化的数据模型。实体-关系图(ERD)是这些结构的架构蓝图。它弥合了抽象业务需求与具体技术实现之间的差距。本指南探讨了数据建模的机制,重点在于如何准确地将操作逻辑转化为模式定义。
🏗️ 理解核心组件
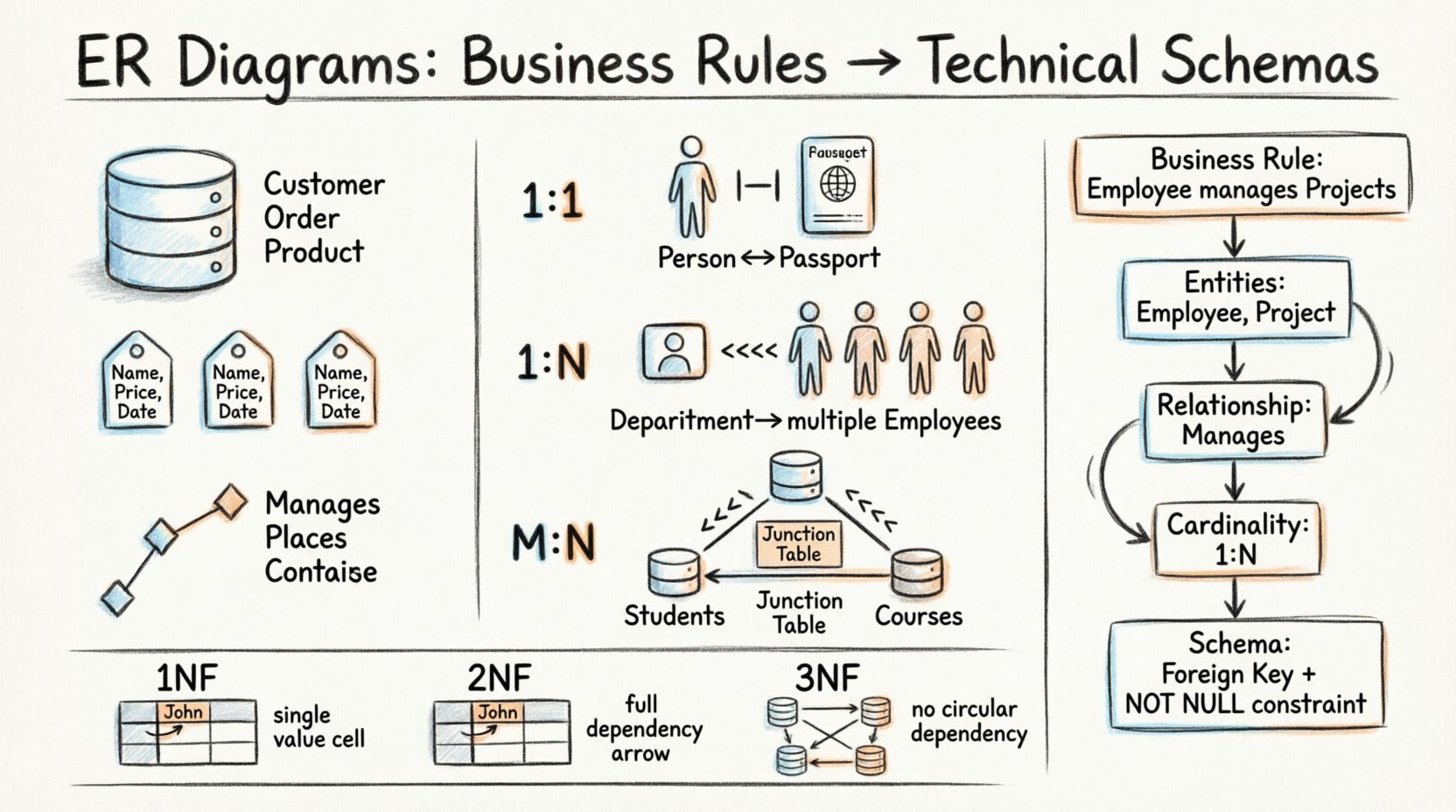
ER图由三个基本构建模块组成。每个模块代表数据存储和关联的特定方面。掌握这些组件,可以构建出与组织需求一致的稳健数据库。
- 实体: 它们代表了数据收集所涉及的对象或概念。在业务环境中,这些通常是名词,例如客户, 订单,或产品。在模式中,实体会变成表。
- 属性: 它们描述实体的属性。例如名称, 价格,或日期。属性会变成对应表中的列。
- 关系: 它们定义了实体之间的关联。关系表明一个实体的实例如何与另一个实体的实例相连接。在数据库中,关系通常通过键来强制执行。
🔄 将业务规则转化为模式元素
数据建模中最关键的步骤是转换阶段。业务利益相关者用流程和政策来表达,而工程师则用表和约束来表达。建模者必须充当这两种语言之间的翻译者。
考虑一个业务规则:“一个员工可以管理多个项目,但一个项目必须至少有一个负责人。”这如何转化为模式?
- 识别实体: 员工和项目.
- 识别关系: 管理.
- 定义基数: 一个员工对应多个项目(1:N)。一个项目至少对应一个员工(1:1 或 1:N,取决于解释)。
- 强制可选性: 项目 必须 有负责人。这会在外键上形成一个 非空 约束。
此过程需要对业务用户提供的自然语言进行仔细分析。模糊性是数据完整性的敌人。如果一条规则表述为“客户可以下订单”,这是否意味着他们可以 下零个订单,还是必须至少下一份订单?这种区别会影响外键的实现方式。
📏 基数与可选性
基数定义了一个实体的实例与另一个实体的每个实例之间可以或必须关联的数量。它是关系的数学基础。
一对一(1:1)
当一个表中的单条记录恰好与另一个表中的单条记录相关联时,就会出现这种关系。这通常在出于安全或性能原因拆分表时出现,但在一般业务逻辑中较少见。
- 示例: 一个人有一本护照。一本护照属于一个人。
- 实现方式: 任一表中的外键,引用另一个表的主键。
一对多(1:N)
这是关系型数据库中最常见的关系类型。表A中的一个记录与表B中的多个记录相关联。表B持有外键。
- 示例: 一个部门有多个员工。一名员工属于一个部门。
- 实现: 员工 表包含一个 部门ID 列。
多对多(M:N)
表A中的两条记录可以与表B中的多条记录相关联,反之亦然。在没有中间步骤的情况下,标准关系模式无法直接实现这种关系。
- 示例: 学生选修课程。一个学生选修多门课程,一门课程有多个学生。
- 实现: 创建一个连接表(关联实体),其中包含来自两个父表的外键。
| 关系类型 | 视觉表示(概念) | 模式实现 | 常见用例 |
|---|---|---|---|
| 一对一(1:1) | |—| | 任一表中的外键 | 人员 ↔ 护照 |
| 一对多(1:N) | |—<<< | “多”方表中的外键 | 部门 ↔ 员工 |
| 多对多(M:N) | <<<—<<< | 包含两个外键的连接表 | 学生 ↔ 课程 |
🧩 规范化原则
一旦实体和关系被定义,就必须对模式进行规范化。规范化是一种系统化的过程,通过组织数据来减少冗余并提高数据完整性。它涉及将表分解为更小、结构更合理的组件。
第一范式(1NF)
每一列必须包含原子值。单个单元格内不应存在重复组或数组。每一行必须是唯一的。
- 违反: 一个 技能 列包含 “SQL、Python、Java” 在一个单元格中。
- 修正: 将技能拆分到一个通过关系链接的独立表中。
第二范式(2NF)
该表必须处于1NF,所有非键属性必须完全依赖于主键。这消除了部分依赖。
- 场景: 一个结合了 订单 和 订单项 其中 产品名称 仅依赖于 项目ID,而不是 订单ID.
- 修正: 将 产品名称 移动到一个 项目 表中。
第三范式(3NF)
该表必须处于2NF,且不应存在传递依赖。非主键属性不应依赖于其他非主键属性。
- 场景: 一个 客户 表,包含 城市 和 国家,其中 国家 由 城市.
- 更正: 创建一个 位置 表来存储城市和国家数据。
🛡️ 处理约束与完整性
一个模式的价值取决于保护它的规则。约束确保数据在时间推移中保持准确和一致。
主键
每个表都必须有一个唯一标识符。这确保了没有两行是相同的,并允许精确检索。在许多系统中,这是一个自增整数。在其他系统中,它可能是一个UUID或自然键。
外键
外键维护引用完整性。它们确保子表中的记录不能在没有对应父表记录的情况下存在。这可以防止孤立数据。
- 删除级联: 如果删除父记录,子记录将自动被删除。
- 删除限制: 如果存在子记录,则禁止删除父记录。
- 删除置空: 删除父记录,但将子记录的外键设为null。
检查约束
这些约束在数据库内部直接强制执行特定的业务逻辑。例如,确保一个价格大于零,或者一个开始日期在结束日期.
⚠️ 数据建模中的常见陷阱
即使经验丰富的架构师也可能忽略关键细节。了解常见错误有助于设计出更可靠的系统。
- 过度规范化:过于激进地拆分表会导致复杂的连接操作,从而降低查询性能。在读取密集型工作负载中,有时允许一定程度的反规范化。
- 忽略软删除:业务规则通常要求保留历史数据。永久删除记录会破坏审计轨迹。通常需要一个IsDeleted标志位。
- 假设唯一性:仅仅因为业务规则暗示唯一性(例如,电子邮件)并不意味着数据库会强制执行。必须显式定义唯一性约束。
- 忽略时间:大多数业务数据都具有时间属性。记录记录的创建时间或更新时间对于审计和调试至关重要。
- 硬编码值:在SQL查询中使用具体值而不是引用查找表会使系统变得僵化且难以维护。
🔄 迭代式设计过程
数据建模很少是线性的过程。它是迭代的。初始的图表只是一个假设,必须通过实际使用模式和反馈来验证。
- 概念设计:关注高层次的实体和关系。忽略数据类型等技术细节。
- 逻辑设计: 添加属性,定义数据类型,并建立键。对结构进行规范化。
- 物理设计: 针对特定的数据库引擎进行优化。考虑索引策略、分区和存储。
- 审查: 与利益相关者共同验证模型。确保其能够支持未来的业务增长。
在审查阶段,常常会发现某个关系被误解了。例如,一个多对多关系实际上可能是一个层次结构,或一系列的一对多关系,一旦提出更深入的问题就会发现这一点。设计阶段的灵活性可以显著节省实施阶段的工作量。
📈 扩展与演进
模式会演进。需求会变化。今天适用的,明天可能不再适用。一个设计良好的ER图能够预见增长。
- 可扩展性: 避免将特定功能硬编码到模式中。对于高度动态的需求,适当使用通用表或属性模式(如EAV)。
- 版本控制: 跟踪模式的变化。迁移脚本应与应用程序代码一起进行版本控制。
- 文档: 图便是文档。如果图与数据库不符,请相信数据库,但立即更新图。
🔍 结构完整性总结
数据库模式的质量直接影响依赖它的应用程序的可靠性。ER图不仅仅是绘图;它是业务逻辑与技术基础设施之间的契约。通过严格地将业务规则映射到技术模式,确保适当的规范化,并维持严格的完整性约束,我们构建出具有韧性且高效的系统。
专注于图示的清晰性。使用标准符号,确保任何工程师都能读懂设计。应优先考虑数据完整性,而非短期性能提升,因为后期修复完整性问题的成本远高于早期优化查询。目标是构建一个既能满足当前业务需求,又能适应未来变化的模式。

