










डेटा किसी भी आधुनिक सूचना प्रणाली की रीढ़ है। हालांकि, संरचना के बिना डेटा सिर्फ शोर है। कच्ची सूचना को क्रियान्वयन योग्य बुद्धिमत्ता में बदलने के लिए, हम संरचित डेटा मॉडल पर निर्भर हैं। एंटिटी-रिलेशनशिप डायग्राम (ERD) इन संरचनाओं के लिए वास्तुकला नक्शा के रूप में कार्य करता है। यह अमूर्त व्यापार आवश्यकताओं और ठोस तकनीकी कार्यान्वयन के बीच के अंतर को पार करता है। यह मार्गदर्शिका डेटा मॉडलिंग के तकनीकी पहलुओं का अध्ययन करती है, जिसमें संचालन तर्क को स्कीमा परिभाषाओं में सटीक रूप से अनुवाद करने के तरीकों पर ध्यान केंद्रित किया गया है।
🏗️ मूल घटकों को समझना
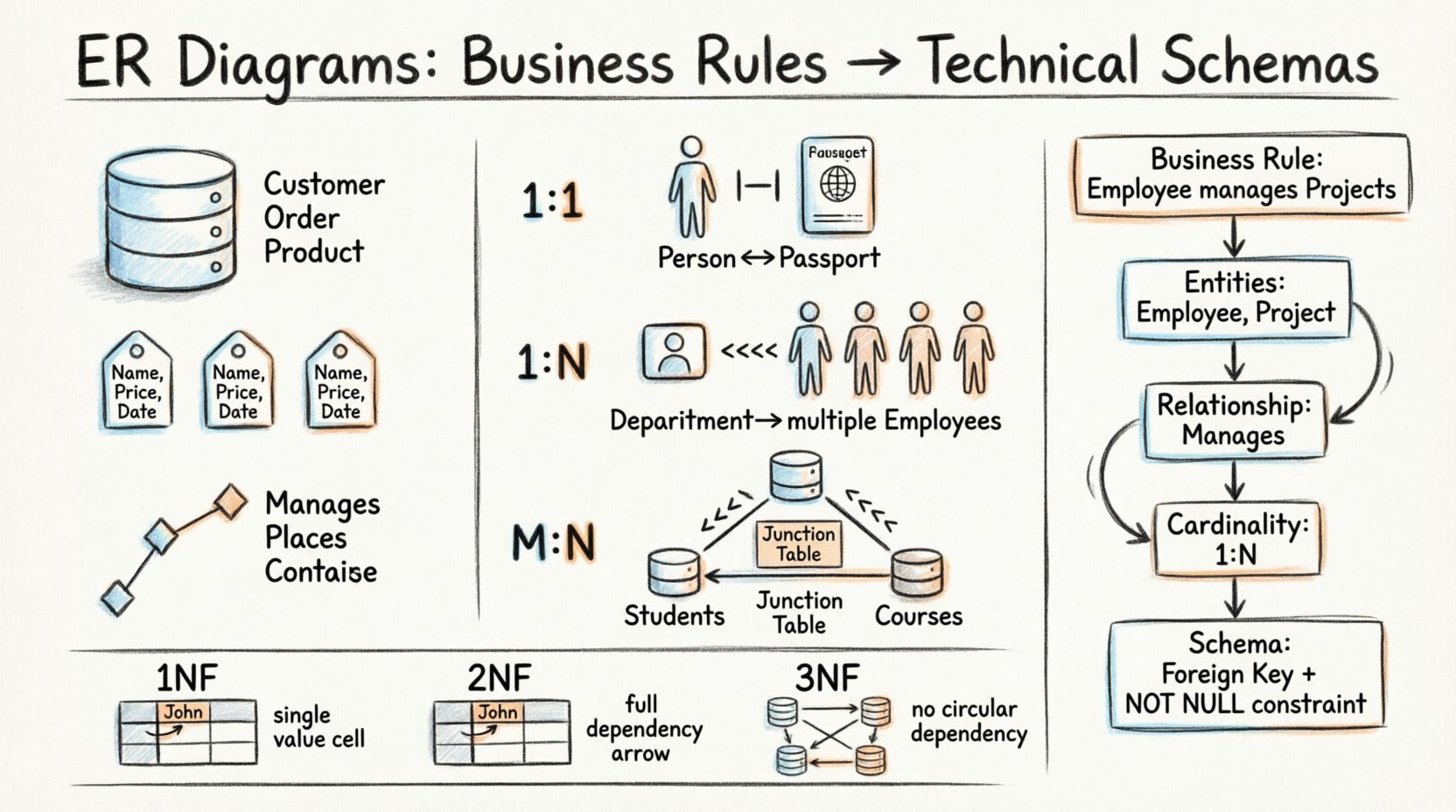
एक ER डायग्राम में तीन मूल निर्माण ब्लॉक होते हैं। प्रत्येक ब्लॉक डेटा के संग्रह और संबंधों के एक विशिष्ट पहलू का प्रतिनिधित्व करता है। इन घटकों को समझने से संगठन की आवश्यकताओं के अनुरूप दृढ़ डेटाबेस के निर्माण की संभावना बनती है।
- एंटिटीज: ये उन वस्तुओं या अवधारणाओं का प्रतिनिधित्व करते हैं जिनके बारे में डेटा एकत्र किया जाता है। व्यापार के संदर्भ में, इन्हें अक्सर नामवाचक शब्दों के रूप में देखा जाता है जैसेग्राहक, आदेश, याउत्पाद। स्कीमा में, एंटिटीज टेबल बन जाती हैं।
- गुणधर्म: ये एंटिटी के गुणों का वर्णन करते हैं। उदाहरण के लिएनाम, मूल्य, यातारीख। गुणधर्म संबंधित टेबलों के कॉलम बन जाते हैं।
- संबंध: ये एंटिटीज के बीच संबंधों को परिभाषित करते हैं। एक संबंध यह बताता है कि एक एंटिटी के उदाहरण दूसरी एंटिटी के उदाहरणों से कैसे जुड़ते हैं। डेटाबेस में, संबंध अक्सर कीज़ के माध्यम से बलपूर्वक लागू किए जाते हैं।
🔄 व्यापार नियमों को स्कीमा तत्वों में अनुवाद करना
डेटा मॉडलिंग में सबसे महत्वपूर्ण चरण अनुवाद चरण है। व्यापार स्टेकहोल्डर प्रक्रियाओं और नीतियों के शब्दों में बोलते हैं। इंजीनियर टेबलों और सीमाओं के शब्दों में बोलते हैं। मॉडलर को इन दो भाषाओं के बीच अनुवादक के रूप में कार्य करना चाहिए।
एक व्यापार नियम पर विचार करें:“एक एकल कर्मचारी कई प्रोजेक्ट को प्रबंधित कर सकता है, लेकिन एक प्रोजेक्ट के कम से कम एक प्रबंधक होना चाहिए।” इसे स्कीमा कैसे बनाया जाता है?
- एंटिटीज की पहचान करें: कर्मचारी औरप्रोजेक्ट.
- संबंध की पहचान करें: प्रबंधित करता है.
- कार्डिनैलिटी को परिभाषित करें: एक कर्मचारी से बहुत सारे प्रोजेक्ट (1:N)। एक प्रोजेक्ट कम से कम एक कर्मचारी से (1:1 या 1:N अर्थात व्याख्या के आधार पर)।
- वैकल्पिकता को लागू करें: प्रोजेक्ट कोई भी नहीं एक प्रबंधक के साथ होना चाहिए। यह विदेशी कुंजी पर एक NOT NULL सीमा बन जाती है।
इस प्रक्रिया में व्यावसायिक उपयोगकर्ताओं द्वारा प्रदान किए गए प्राकृतिक भाषा के ध्यान से विश्लेषण की आवश्यकता होती है। अस्पष्टता डेटा अखंडता की दुश्मन है। यदि कोई नियम कहता है “एक ग्राहक आदेश दे सकता है”, क्या यह इस बात का अर्थ है कि वे कर सकते हैं शून्य आदेश दे सकते हैं, या कम से कम एक आदेश देना होगा? यह अंतर विदेशी कुंजी के कार्यान्वयन को बदल देता है।
📏 कार्डिनैलिटी और वैकल्पिकता
कार्डिनैलिटी एक एकता के उन उदाहरणों की संख्या को परिभाषित करती है जो दूसरी एकता के प्रत्येक उदाहरण के साथ जुड़ सकते हैं या जुड़ने चाहिए। यह संबंध का गणितीय आधार है।
एक से एक (1:1)
यह संबंध तब होता है जब एक तालिका में एक एकल रिकॉर्ड दूसरी तालिका में ठीक एक रिकॉर्ड से संबंधित होता है। यह सुरक्षा या प्रदर्शन के कारण तालिकाओं को विभाजित करने के लिए आम है, हालांकि यह सामान्य व्यावसायिक तर्क में कम होता है।
- उदाहरण: एक व्यक्ति के पास एक पासपोर्ट होता है। एक पासपोर्ट एक व्यक्ति के साथ संबंधित होता है।
- कार्यान्वयन: एक तालिका में विदेशी कुंजी जो दूसरी तालिका की प्राथमिक कुंजी को संदर्भित करती है।
एक से बहुत (1:N)
यह संबंधित डेटाबेस में सबसे आम संबंध प्रकार है। तालिका A में एक रिकॉर्ड तालिका B में बहुत सारे रिकॉर्ड से संबंधित होता है। तालिका B विदेशी कुंजी को रखती है।
- उदाहरण: एक विभाग में बहुत सारे कर्मचारी होते हैं। एक कर्मचारी एक विभाग से संबंधित होता है।
- कार्यान्वयन: द कर्मचारी तालिका में एक हैविभागआईडी कॉलम।
बहु-से-बहु (M:N)
तालिका A में दो रिकॉर्ड तालिका B में कई रिकॉर्ड से संबंधित हो सकते हैं, और इसके विपरीत भी। इसका सीधा कार्यान्वयन मानक संबंधात्मक स्कीमा में एक मध्यवर्ती चरण के बिना संभव नहीं है।
- उदाहरण: छात्र कोर्स में नामांकन करते हैं। एक छात्र कई कोर्स लेता है। एक कोर्स में कई छात्र होते हैं।
- कार्यान्वयन: एक जंक्शन तालिका (सहसंबंधित एकता) बनाएं जिसमें दोनों मूल तालिकाओं से विदेशी कुंजियां हों।
| संबंध प्रकार | दृश्य प्रतीक (अवधारणा) | स्कीमा कार्यान्वयन | सामान्य उपयोग केस |
|---|---|---|---|
| एक-से-एक (1:1) | |—| | किसी भी तालिका में विदेशी कुंजी | व्यक्ति ↔ पासपोर्ट |
| एक-से-बहु (1:N) | |—<<< | ‘बहु’ तालिका में विदेशी कुंजी | विभाग ↔ कर्मचारी |
| बहु-से-बहु (M:N) | <<<—<<< | दो विदेशी कुंजियों वाली जंक्शन तालिका | छात्र ↔ कोर्स |
🧩 सामान्यीकरण सिद्धांत
जब एकताओं और संबंधों को परिभाषित कर लिया जाता है, तो स्कीमा को सामान्यीकृत किया जाना चाहिए। सामान्यीकरण डेटा को कम अतिरिक्तता और डेटा अखंडता में सुधार करने के लिए डेटा को व्यवस्थित करने की एक व्यवस्थित प्रक्रिया है। इसमें तालिकाओं को छोटे, अच्छी तरह से संरचित घटकों में विभाजित करना शामिल है।
पहला सामान्य रूप (1NF)
प्रत्येक कॉलम में परमाणु मान होने चाहिए। एक ही सेल में दोहराए जाने वाले समूह या ऐरे नहीं होने चाहिए। प्रत्येक पंक्ति अद्वितीय होनी चाहिए।
- उल्लंघन: एक compétences कॉलम में समाविष्ट “SQL, Python, Java” एक सेल में।
- सुधार: कौशल को एक संबंध द्वारा जुड़े अलग तालिका में विभाजित करें।
दूसरा सामान्य रूप (2NF)
तालिका को 1NF में होना चाहिए, और सभी गैर-कुंजी विशेषताओं को मुख्य कुंजी पर पूर्ण रूप से निर्भर होना चाहिए। इससे आंशिक निर्भरता को दूर किया जाता है।
- परिदृश्य: एक तालिका जो संयोजित करती है आदेश और आदेश आइटम जहां उत्पाद नाम केवल इस पर निर्भर करता है आइटम आईडी, नहीं आदेश आईडी.
- सुधार: स्थानांतरित करें उत्पाद नाम एक आइटम तालिका में।
तृतीय सामान्य रूप (3NF)
तालिका को 2NF में होना चाहिए, और इसमें कोई अनुक्रमिक निर्भरता नहीं होनी चाहिए। गैर-कुंजी विशेषताओं को अन्य गैर-कुंजी विशेषताओं पर निर्भर नहीं होना चाहिए।
- परिदृश्य: एक ग्राहक तालिका जिसमें शामिल है शहर और देश, जहां देश निर्धारित होता है शहर.
- सुधार: एक बनाएं स्थान तालिका शहर और देश के डेटा को संग्रहीत करने के लिए।
🛡️ प्रतिबंधों और अखंडता का प्रबंधन
एक स्कीमा केवल उन नियमों के बराबर ही अच्छा होता है जो इसकी रक्षा करते हैं। प्रतिबंध सुनिश्चित करते हैं कि डेटा समय के साथ सटीक और संगत बना रहे।
प्राथमिक कुंजी
प्रत्येक तालिका में एक अद्वितीय पहचानकर्ता होना चाहिए। इससे सुनिश्चित होता है कि कोई भी दो पंक्तियाँ समान नहीं होंगी और सटीक पुनर्प्राप्ति की अनुमति मिलती है। अधिकांश प्रणालियों में, यह एक स्वतः बढ़ता हुआ पूर्णांक होता है। कुछ में, यह एक UUID या प्राकृतिक कुंजी हो सकती है।
विदेशी कुंजी
विदेशी कुंजियाँ संदर्भात्मक अखंडता बनाए रखती हैं। वे सुनिश्चित करती हैं कि बच्चे की तालिका में कोई रिकॉर्ड माता-पिता तालिका में संगत रिकॉर्ड के बिना नहीं हो सकता है। इससे अनाथ डेटा को रोका जाता है।
- हटाने पर कैस्केड: यदि माता-पिता को हटाया जाता है, तो बच्चे को स्वतः ही हटा दिया जाता है।
- हटाने पर प्रतिबंध: बच्चे मौजूद होने पर माता-पिता के हटाने को रोकता है।
- हटाने पर नॉल सेट करें: माता-पिता को हटा देता है लेकिन बच्चे के रिकॉर्ड को एक नॉल विदेशी कुंजी के साथ छोड़ देता है।
चेक सीमाएँ
ये विशिष्ट व्यापार तर्क को डेटाबेस के भीतर सीधे लागू करते हैं। उदाहरणों में एक के लिए सुनिश्चित करना शामिल हैमूल्य शून्य से अधिक है या एकप्रारंभ तिथि एक के पहले हैसमाप्ति तिथि.
⚠️ डेटा मॉडलिंग में सामान्य त्रुटियाँ
यहाँ अनुभवी वास्तुकार भी महत्वपूर्ण विवरणों को नजरअंदाज कर सकते हैं। सामान्य गलतियों के बारे में जागरूक रहने से अधिक लचीले प्रणाली के डिज़ाइन में मदद मिलती है।
- अत्यधिक सामान्यीकरण: ताबलों को बहुत अधिक विभाजित करने से जटिल जॉइन्स की स्थिति बनती है जो प्रश्न प्रदर्शन को खराब करती है। कभी-कभी, पठन-भारी कार्यभार के लिए असामान्यीकरण स्वीकार्य हो सकता है।
- मृदु डिलीट को नजरअंदाज करना: व्यापार नियम अक्सर ऐतिहासिक डेटा को बनाए रखने की आवश्यकता महसूस कराते हैं। एक रिकॉर्ड को स्थायी रूप से हटाने से लेखा-जोखा का अनुसरण खत्म हो जाता है। एकIsDeleted झंडा अक्सर आवश्यक होता है।
- अद्वितीयता की मान्यता करना: केवल इसलिए कि एक व्यापार नियम अद्वितीयता की ओर इशारा करता है (उदाहरण के लिए,ईमेल) का मतलब यह नहीं है कि डेटाबेस इसे लागू करता है। एक अद्वितीय सीमा को स्पष्ट रूप से परिभाषित किया जाना चाहिए।
- समय को नजरअंदाज करना: अधिकांश व्यापार डेटा में समयांतरिक घटक होता है। रिकॉर्ड के बनाए जाने या अद्यतन किए जाने के समय को रिकॉर्ड करना लेखा-जोखा और त्रुटि निवारण के लिए आवश्यक है।जबएक रिकॉर्ड के बनाए जाने या अद्यतन किए जाने के समय को रिकॉर्ड करना लेखा-जोखा और त्रुटि निवारण के लिए आवश्यक है।
- मानों को कोड में स्थिर रूप से लिखना: लुकअप ताबलों के संदर्भ के बजाय SQL प्रश्नों में विशिष्ट मानों का उपयोग करने से प्रणाली कठोर और रखरखाव में कठिन हो जाती है।
🔄 आवर्ती डिज़ाइन प्रक्रिया
डेटा मॉडलिंग अक्सर रेखीय प्रक्रिया नहीं होती है। यह आवर्ती है। प्रारंभिक आरेख एक परिकल्पना है जिसे वास्तविक उपयोग पैटर्न और प्रतिक्रिया के खिलाफ परीक्षण करना होता है।
- अवधारणात्मक डिज़ाइन: उच्च स्तरीय एकाइयों और संबंधों पर ध्यान केंद्रित करें। डेटा प्रकार जैसी तकनीकी विवरणों को नजरअंदाज करें।
- तार्किक डिज़ाइन: विशेषताएं जोड़ें, डेटा प्रकार निर्धारित करें, और कुंजियां स्थापित करें। संरचना को सामान्यीकृत करें।
- भौतिक डिज़ाइन: विशिष्ट डेटाबेस इंजन के लिए अनुकूलित करें। इंडेक्सिंग रणनीतियों, विभाजन और भंडारण पर विचार करें।
- समीक्षा: स्टेकहोल्डर्स के साथ मॉडल की पुष्टि करें। सुनिश्चित करें कि यह भविष्य के व्यवसाय विकास का समर्थन करता है।
समीक्षा चरण के दौरान, यह सामान्य है कि एक संबंध को गलत समझा गया हो। उदाहरण के लिए, एकबहु-से-बहुसंबंध वास्तव में एक विवरण या एक श्रृंखला हो सकता हैएक-से-बहु गहन प्रश्न पूछे जाने के बाद। डिज़ाइन चरण में लचीलापन अनुप्रयोग चरण में महत्वपूर्ण प्रयास बचाता है।
📈 स्केलिंग और विकास
स्कीमा विकसित होते हैं। आवश्यकताएं बदलती हैं। आज फिट होने वाला कल फिट नहीं हो सकता है। एक अच्छी तरह से डिज़ाइन किया गया ईआर आरेख वृद्धि की भविष्यवाणी करता है।
- विस्तार्यता: स्कीमा में विशिष्ट विशेषताओं को कोड करने से बचें। बहुत गतिशील आवश्यकताओं के लिए उपयुक्त स्थितियों में सामान्य तालिकाओं या विशेषता पैटर्न (जैसे ईएवी) का उपयोग करें।
- संस्करण निर्धारण: स्कीमा परिवर्तनों का ट्रैक रखें। माइग्रेशन स्क्रिप्ट को एप्लिकेशन कोड के साथ संस्करण नियंत्रण में रखा जाना चाहिए।
- दस्तावेज़ीकरण: आरेख ही दस्तावेज़ीकरण है। यदि आरेख डेटाबेस से मेल नहीं खाता है, तो डेटाबेस पर भरोसा करें, लेकिन आरेख को तुरंत अपडेट करें।
🔍 संरचनात्मक अखंडता पर निष्कर्ष
डेटाबेस स्कीमा की गुणवत्ता सीधे उन एप्लिकेशनों की विश्वसनीयता पर प्रभाव डालती है जो इस पर निर्भर करती हैं। ईआर आरेख एक चित्र से अधिक है; यह व्यापार तर्क और तकनीकी ढांचे के बीच एक संविदा है। व्यापार नियमों को तकनीकी स्कीमा में ठीक से मैप करके, उचित सामान्यीकरण सुनिश्चित करके और कठोर अखंडता प्रतिबंधों को बनाए रखकर, हम ऐसे प्रणालियां बनाते हैं जो लचीली और कुशल होती हैं।
अपने आरेखों में स्पष्टता पर ध्यान केंद्रित करें। किसी भी इंजीनियर के डिज़ाइन को पढ़ने में सक्षम होने के लिए मानक नोटेशन का उपयोग करें। छोटे समय के प्रदर्शन लाभ की तुलना में डेटा अखंडता को प्राथमिकता दें, क्योंकि बाद में अखंडता समस्याओं को ठीक करना प्रारंभिक रूप से प्रश्नों को अनुकूलित करने से बहुत अधिक लागत वाला होता है। लक्ष्य एक स्कीमा है जो व्यापार का वर्तमान में समर्थन करती है और भविष्य में इसके अनुकूल हो सकती है।

