










Daten bilden die Grundlage jedes modernen Informationssystems. Doch Daten ohne Struktur sind lediglich Rauschen. Um rohe Informationen in handlungsleitende Intelligenz zu verwandeln, setzen wir auf strukturierte Datenmodelle. Das Entity-Relationship-Diagramm (ERD) dient als architektonisches Bauplan für diese Strukturen. Es schließt die Lücke zwischen abstrakten Geschäftsanforderungen und konkreter technischer Umsetzung. Dieser Leitfaden untersucht die Mechanik der Datenmodellierung und legt den Fokus darauf, wie man betriebliche Logik präzise in Schema-Definitionen übersetzen kann.
🏗️ Verständnis der Kernkomponenten
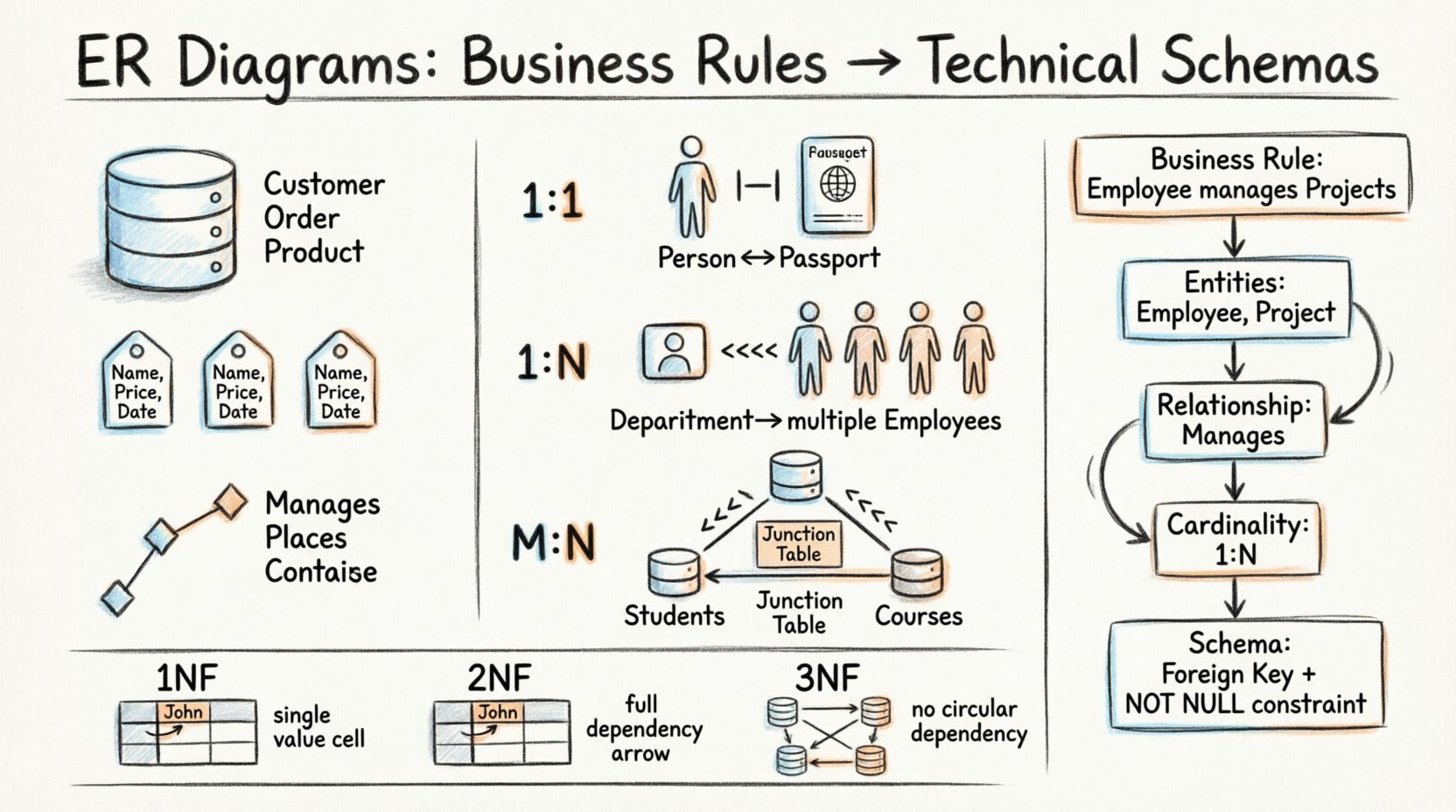
Ein ER-Diagramm besteht aus drei grundlegenden Bausteinen. Jeder Baustein repräsentiert einen spezifischen Aspekt der Datenspeicherung und -verknüpfung. Die Beherrschung dieser Komponenten ermöglicht die Erstellung robuster Datenbanken, die den Anforderungen der Organisation entsprechen.
- Entitäten: Diese stellen die Objekte oder Konzepte dar, über die Daten gesammelt werden. Im geschäftlichen Kontext sind dies oft Substantive wieKunde, Bestellung, oderProdukt. Im Schema werden Entitäten zu Tabellen.
- Attribute: Diese beschreiben die Eigenschaften einer Entität. Beispiele sindName, Preis, oderDatum. Attribute werden zu Spalten innerhalb der entsprechenden Tabellen.
- Beziehungen: Diese definieren die Verbindungen zwischen Entitäten. Eine Beziehung zeigt an, wie Instanzen einer Entität mit Instanzen einer anderen Entität verknüpft sind. In der Datenbank werden Beziehungen oft über Schlüssel durchgesetzt.
🔄 Übersetzung von Geschäftsregeln in Schema-Elemente
Der kritischste Schritt bei der Datenmodellierung ist die Übersetzungsphase. Geschäftsinteressenten sprechen in Begriffen von Prozessen und Richtlinien. Ingenieure sprechen in Begriffen von Tabellen und Einschränkungen. Der Modellierer muss als Übersetzer zwischen diesen beiden Sprachen agieren.
Betrachten Sie eine Geschäftsregel:„Ein einzelner Mitarbeiter kann mehrere Projekte verwalten, aber ein Projekt muss mindestens einen Leiter haben.“Wie wird daraus ein Schema?
- Identifizieren Sie die Entitäten: Mitarbeiter undProjekt.
- Beziehung identifizieren: Verwaltet.
- Kardinalität definieren: Ein Mitarbeiter zu vielen Projekten (1:N). Ein Projekt zu mindestens einem Mitarbeiter (1:1 oder 1:N, abhängig von der Interpretation).
- Optionality durchsetzen: Das Projekt musseinen Leiter haben. Dies wird eine NICHT NULLBeschränkung für den Fremdschlüssel.
Dieser Prozess erfordert eine sorgfältige Analyse der natürlichen Sprache, die von den Geschäftsanwendern bereitgestellt wird. Mehrdeutigkeit ist der Feind der Datenintegrität. Wenn eine Regel besagt „Ein Kunde kann Bestellungen aufgeben“, bedeutet das, dass sie könnennull Bestellungen aufgeben, oder müssen sie mindestens eine aufgeben? Diese Unterscheidung verändert die Implementierung von Fremdschlüsseln.
📏 Kardinalität und Optionality
Die Kardinalität definiert die Anzahl der Instanzen einer Entität, die mit jeder Instanz einer anderen Entität assoziiert sein können oder müssen. Sie ist die mathematische Grundlage der Beziehung.
Ein-zu-Eins (1:1)
Diese Beziehung tritt auf, wenn ein einzelner Datensatz in einer Tabelle genau einem Datensatz in einer anderen Tabelle zugeordnet ist. Dies ist üblich, wenn Tabellen aus Sicherheits- oder Leistungsgründen aufgeteilt werden, ist jedoch im allgemeinen Geschäftslogik weniger häufig.
- Beispiel: Eine Person hat einen Reisepass. Ein Reisepass gehört einer Person.
- Implementierung: Ein Fremdschlüssel in einer der Tabellen, der auf den Primärschlüssel der anderen verweist.
Ein-zu-Viele (1:N)
Dies ist der häufigste Beziehungstyp in relationalen Datenbanken. Ein Datensatz in Tabelle A steht in Beziehung zu mehreren Datensätzen in Tabelle B. Tabelle B enthält den Fremdschlüssel.
- Beispiel: Eine Abteilung hat viele Mitarbeiter. Ein Mitarbeiter gehört einer Abteilung an.
- Implementierung: Die Mitarbeiter Tabelle enthält eine AbteilungsID Spalte.
Viele-zu-Viele (M:N)
Zwei Datensätze in Tabelle A können mit mehreren Datensätzen in Tabelle B verknüpft sein und umgekehrt. Eine direkte Implementierung dieses Zusammenhangs ist in standardmäßigen relationalen Schemata ohne einen Zwischenschritt nicht möglich.
- Beispiel: Studierende melden sich in Kursen an. Ein Studierender besucht viele Kurse. Ein Kurs hat viele Studierende.
- Implementierung: Erstellen Sie eine Verbindungstabelle (assoziatives Entität), die Fremdschlüssel aus beiden Eltern-Tabellen enthält.
| Beziehungstyp | Visuelle Notation (Konzept) | Schema-Implementierung | Häufiges Anwendungsbeispiel |
|---|---|---|---|
| Eins-zu-Eins (1:1) | |—| | Fremdschlüssel in einer der Tabellen | Person ↔ Reisepass |
| Eins-zu-Viele (1:N) | |—<<< | Fremdschlüssel in der Tabelle „Viele“ | Abteilung ↔ Mitarbeiter |
| Viele-zu-Viele (M:N) | <<<—<<< | Verbindungstabelle mit zwei Fremdschlüsseln | Studierende ↔ Kurse |
🧩 Normalisierungsprinzipien
Sobald die Entitäten und Beziehungen definiert sind, muss das Schema normalisiert werden. Die Normalisierung ist ein systematischer Prozess zur Organisation von Daten, um Redundanz zu reduzieren und die Datenintegrität zu verbessern. Dabei werden Tabellen in kleinere, gut strukturierte Komponenten zerlegt.
Erste Normalform (1NF)
Jede Spalte muss atomare Werte enthalten. Es sollten keine wiederholten Gruppen oder Arrays innerhalb einer einzelnen Zelle vorhanden sein. Jede Zeile muss eindeutig sein.
- Verletzung: A Fähigkeiten Spalte, die enthält „SQL, Python, Java“ in einer Zelle.
- Korrektur: Teilen Sie Fähigkeiten in eine separate Tabelle auf, die über eine Beziehung verknüpft ist.
Zweite Normalform (2NF)
Die Tabelle muss in 1NF sein, und alle nicht-schlüsselbasierten Attribute müssen vollständig vom Primärschlüssel abhängen. Dies beseitigt partielle Abhängigkeiten.
- Szenario: Eine Tabelle, die Bestellung und Bestellposition bei der Produktname hängt nur vom Artikel-ID, nicht von der Bestell-ID.
- Korrektur: Verschieben Sie Produktname in eine Artikel Tabelle.
Dritte Normalform (3NF)
Die Tabelle muss in 2NF sein, und es dürfen keine transitiven Abhängigkeiten bestehen. Nicht-Schlüsselattribute dürfen nicht von anderen Nicht-Schlüsselattributen abhängen.
- Szenario: Eine Kunde Tabelle, die enthält Stadt und Land, wobei Land wird bestimmt durch Stadt.
- Korrektur: Erstellen Sie eine Standort Tabelle, um Stadt- und Länderdaten zu speichern.
🛡️ Behandlung von Einschränkungen und Integrität
Ein Schema ist nur so gut wie die Regeln, die es schützen. Einschränkungen stellen sicher, dass die Daten im Laufe der Zeit genau und konsistent bleiben.
Primärschlüssel
Jede Tabelle muss einen eindeutigen Bezeichner haben. Dies stellt sicher, dass keine zwei Zeilen identisch sind, und ermöglicht eine präzise Abfrage. In vielen Systemen ist dies eine automatisch hochzählende Ganzzahl. In anderen kann es eine UUID oder ein natürlicher Schlüssel sein.
Fremdschlüssel
Fremdschlüssel gewährleisten die Referenzintegrität. Sie stellen sicher, dass ein Datensatz in der Kindtabelle nicht existieren kann, ohne einen entsprechenden Datensatz in der Elterntabelle zu haben. Dies verhindert verwaiste Daten.
- Bei Löschen Kaskade: Wenn das übergeordnete Element gelöscht wird, wird das untergeordnete Element automatisch gelöscht.
- Bei Löschen Beschränken: Verhindert die Löschung des übergeordneten Elements, wenn untergeordnete Elemente existieren.
- Bei Löschen auf NULL setzen: Löscht das übergeordnete Element, lässt aber die untergeordnete Aufzeichnung mit einem NULL-Fremdschlüssel zurück.
Prüfbeschränkungen
Diese erzwingen spezifische Geschäftslogik direkt innerhalb der Datenbank. Beispiele hierfür sind die Sicherstellung, dass eine Preis größer als null ist oder eine Startdatum vor einem Enddatum.
⚠️ Häufige Fallen im Datenmodellieren
Selbst erfahrene Architekten können kritische Details übersehen. Die Aufmerksamkeit auf häufige Fehler hilft dabei, widerstandsfähigere Systeme zu gestalten.
- Über-Normalisierung:Das zu aggressive Aufteilen von Tabellen kann zu komplexen Verknüpfungen führen, die die Abfrageleistung beeinträchtigen. Manchmal ist eine De-Normalisierung für arbeitslastige Leseanwendungen akzeptabel.
- Ignorieren von Weichen Löschungen: Geschäftsregeln erfordern oft die Beibehaltung historischer Daten. Das dauerhafte Löschen eines Datensatzes entfernt die Prüfungs- und Nachverfolgungsspur. Ein IstGelöschtFlag ist oft notwendig.
- Annahme von Eindeutigkeit: Nur weil eine Geschäftsregel Eindeutigkeit impliziert (z. B. E-Mail) bedeutet nicht, dass die Datenbank dies erzwingt. Eine eindeutige Beschränkung muss explizit definiert werden.
- Ignorieren der Zeit: Der Großteil der Geschäftsdaten hat eine zeitliche Komponente. Die Aufzeichnung von Wannein Datensatz erstellt oder aktualisiert wurde, ist für die Prüfung und Fehlersuche unerlässlich.
- Harte Kodierung von Werten:Das Verwenden spezifischer Werte in SQL-Abfragen anstelle der Verwendung von Abfrage-Tabellen macht das System starr und schwer zu pflegen.
🔄 Der iterative Gestaltungsprozess
Datenmodellierung ist selten ein linearer Prozess. Sie ist iterativ. Das ursprüngliche Diagramm ist eine Hypothese, die anhand tatsächlicher Nutzungsmuster und Rückmeldungen getestet werden muss.
- Konzeptuelles Design:Konzentrieren Sie sich auf hochwertige Entitäten und Beziehungen. Ignorieren Sie technische Details wie Datentypen.
- Logischer Entwurf: Fügen Sie Attribute hinzu, definieren Sie Datentypen und legen Sie Schlüssel fest. Normalisieren Sie die Struktur.
- Physischer Entwurf: Optimieren Sie für die spezifische Datenbank-Engine. Berücksichtigen Sie Indexstrategien, Partitionierung und Speicherung.
- Überprüfung: Validieren Sie das Modell mit den Stakeholdern. Stellen Sie sicher, dass es zukünftiges Geschäftswachstum unterstützt.
Während der Überprüfungsphase ist es üblich, dass eine Beziehung missverstanden wurde. Zum Beispiel könnte eine Viele-zu-VieleBeziehung eigentlich eine Hierarchie oder eine Kette von Eins-zu-VieleBeziehungen sein, wenn tiefere Fragen gestellt werden. Flexibilität im Entwurfsphase spart erheblichen Aufwand während der Implementierungsphase.
📈 Skalierung und Evolution
Schemata entwickeln sich weiter. Anforderungen ändern sich. Was heute passt, passt möglicherweise morgen nicht mehr. Ein gut gestaltetes ER-Diagramm antizipiert Wachstum.
- Erweiterbarkeit: Vermeiden Sie das Festcodieren spezifischer Funktionen in das Schema. Verwenden Sie generische Tabellen oder Attributmuster (wie EAV), wo appropriate für hochdynamische Anforderungen.
- Versionsverwaltung: Verfolgen Sie Änderungen am Schema. Migrations-Skripte sollten zusammen mit dem Anwendungscode versioniert werden.
- Dokumentation: Das Diagramm ist die Dokumentation. Wenn das Diagramm nicht mit der Datenbank übereinstimmt, vertrauen Sie der Datenbank, aktualisieren Sie das Diagramm aber sofort.
🔍 Schlussfolgerung zur strukturellen Integrität
Die Qualität eines Datenbankschemas wirkt sich direkt auf die Zuverlässigkeit der darauf basierenden Anwendungen aus. Ein ER-Diagramm ist mehr als eine Zeichnung; es ist ein Vertrag zwischen der Geschäftslogik und der technischen Infrastruktur. Indem wir Geschäftsregeln rigoros in technische Schemata übertragen, eine ordnungsgemäße Normalisierung sicherstellen und strenge Integritätsbeschränkungen aufrechterhalten, bauen wir Systeme, die widerstandsfähig und effizient sind.
Konzentrieren Sie sich auf Klarheit in Ihren Diagrammen. Verwenden Sie Standardnotationen, um sicherzustellen, dass jeder Ingenieur das Design lesen kann. Priorisieren Sie die Datenintegrität gegenüber kurzfristigen Leistungsverbesserungen, da die Behebung von Integritätsproblemen später viel kostspieliger ist als die frühzeitige Optimierung von Abfragen. Ziel ist ein Schema, das das Geschäft heute unterstützt und sich in Zukunft anpassen kann.

