










すべてのデータアーキテクトは、同じ重要な瞬間を迎える。最初はクリーンで正規化されたスキーマから始める。データベースは数千件のレコードを容易に処理できる。クエリはミリ秒単位で返答される。エンティティ関係図(ERD)は洗練された見た目をしている。しかし、ビジネスが拡大する。ユーザーの採用が急増する。データ量が爆発的に増加する。突然、システムの速度が低下する。結合処理に数秒かかる。ロックがトランザクションをブロックする。元のERD設計が負担となる。
本書では、小規模なデータベースから高負荷の本番環境への移行について詳述する。パフォーマンスを維持しつつデータ整合性を損なわないために必要な構造的変更を検討する。焦点は論理設計、インデックス戦略、パーティショニング技術に置かれる。ここでは特定のベンダー製ソフトウェアは名指しされていない。これらの原則は、あらゆるリレーショナルストレージエンジンに適用可能である。
🏗️ 基準:成長を想定した設計
アプリケーションが開始される段階では、開発スピードが最優先事項である。ERDはビジネスドメインを正確に反映している。正規化度は高い。第三正規形(3NF)がしばしば目標となる。これにより冗長性が最小限に抑えられる。データの一貫性が保証される。しかし、このアプローチは特定のワークロードパターンを前提としている。クエリが単純であることを前提としている。データセットがメモリに快適に収まるという前提である。
データセットが拡大するにつれて、これらの前提は成り立たなくなる。結合処理のコストは対数的に増加する。クエリプロセッサがスキャンするデータ量は線形に増加する。ディスクI/Oがボトルネックとなる。アーキテクチャは論理的な純粋性から物理的なパフォーマンスへと移行する必要がある。
破綻のポイントを特定する
リファクタリングを行う前に、システムがどこで失敗しているかを理解する必要がある。数千件から数百万件への移行は、データ取得の物理法則を変える。以下の兆候を確認せよ:
- クエリ遅延:5msで処理されていたクエリが、500msにまで遅延する。
- ロック競合:トランザクションがロックの解放を待つ。
- 書き込みスループット:インデックスのメンテナンスのため、挿入処理が遅くなる。
- メモリ圧力:バッファプールが頻繁にアクセスされるテーブルをキャッシュできない。
- ネットワーク飽和:大きな結果セットが帯域幅を消費する。
これらの症状が現れた時点で、ERDは進化しなければならない。単にハードウェアを追加するだけでは不十分である。構造を最適化しなければならない。
🔍 第1フェーズ:スキーマの再構築
スケーリングの第一歩は、エンティティ関係図(ERD)の監査である。現在の構造がスケーリングに必要なクエリパターンをサポートしているかどうかを確認する必要がある。
正規化 vs. 非正規化
正規化はデータの重複を減らす。更新を簡素化する。しかし、結合を強制する。スケーリング時には結合は高コストとなる。非正規化は冗長性を導入する。結合を減らす。読み取りを高速化する。これは慎重に管理しなければならないトレードオフである。
n
以下の戦略を検討せよ:
- 読み込み中心のワークロード:頻繁にアクセスされる属性を非正規化する。結合を避けるために、主テーブルに直接格納する。
- 書き込み中心のワークロード:正規化を維持する。複数のテーブルにわたる連鎖的な更新を避ける。
- ハイブリッドアプローチ: コアスキーマは正規化された状態を保ってください。レポート用に物化ビューまたは要約テーブルを作成してください。
当該ケーススタディでは、元の設計では単一のユーザー情報を取得するために10のテーブルを結合していました。これによりディスクI/Oが過剰になりました。最も一般的なユーザー属性をメインプロファイルテーブルに非正規化することで、結合数を10から1に削減しました。
大容量テキストフィールドの取り扱い
メインテーブルに大容量の文字列(CLOB)を格納すると、ページ読み取りが遅くなることがあります。データベースエンジンはプライマリキーを確認するために、行全体を読み込む必要があります。行が大きすぎると、ディスクにスプールされる可能性があります。
推奨される実践には以下が含まれます:
- 大容量のテキストフィールドを別テーブルに分離する。
- 明示的に要求された場合にのみ、テキストフィールドを取得する。
- メインインデックスにコンテンツの代わりに参照(ID)を格納する。
📈 フェーズ2:インデックス戦略
インデックスはクエリパフォーマンスの原動力です。適切に設計されたERDは、データを迅速に検索するためにインデックスに依存しています。レコードが増えるにつれて、インデックスのサイズも増大します。インデックスの維持には書き込みリソースが消費されます。
複合インデックス
単一カラムインデックスはしばしば不十分です。複合インデックスにより、エンジンは複数の基準を同時にフィルタリングできます。インデックス内のカラムの順序は重要です。最も選択性の高いカラムを最初に配置するべきです。
たとえば、以下でフィルタリングする場合にステータス および 日付、しかし ステータス には選択性が低く(例:3つの値しか存在しない)、日付 を最初に配置してください。これにより、検索範囲をより速く絞り込めます。
カバーインデックス
カバーインデックスは、クエリで必要なすべてのカラムを含みます。データベースはインデックスのみを使ってクエリを満たすことができます。テーブルデータ(ヒープ)にアクセスする必要がありません。これは大きなパフォーマンス向上です。
- すべての
SELECTカラムを含める。 - すべての
WHERE句のカラムを含める。 - すべての
ORDER BY列。
インデックスのメンテナンス
インデックスは静的ではありません。時間とともに断片化します。データに応じて大きくなります。定期的なメンテナンスが必要です。
- 再構築: インデックス構造を断片化から解放します。
- 再整理: 完全な再構築なしにリーフページを再順序付けします。
- モニタリング: 使用されていないインデックスを追跡します。書き込みスペースを節約するために削除してください。
🗄️ フェーズ3:パーティショニングとシャーディング
単一のテーブルが単一のディスクまたはメモリプールの容量を超えると、パーティショニングが必須になります。これにより論理テーブルがより小さな物理セグメントに分割されます。
範囲パーティショニング
この方法は範囲値に基づいてデータを分割します。日付や連続するIDによく使用されます。たとえば、年ごとにデータを分割する場合です。
- 利点: パーティショニングキーでフィルタリングされたクエリは、1つのセグメントのみをスキャンします。
- 欠点: パーティショニングキーなしのクエリはすべてのセグメントをスキャンします(フルテーブルスキャン)。
ハッシュパーティショニング
キー列に対してハッシュ関数を使用して、データをセグメント間で均等に分散します。ホットスポットを防ぎます。
- 利点: データの均等な分散。
- 欠点: 範囲クエリが高コストになります。
水平シャーディング対垂直シャーディング
シャーディングは、データを複数のデータベースインスタンスに分散させることで、パーティショニングをさらに進めたものです。
| 戦略 | 説明 | 最適な使用ケース |
|---|---|---|
| 水平シャーディング | キーに基づいて行をデータベース間で分割する。 | 高い書き込み量、大規模なデータセット。 |
| 垂直シャーディング | 使用状況に基づいて列をデータベース間で分割する。 | 大容量の列、異なる読み取りパターン。 |
| ディレクトリシャーディング | 照会をルーティングするために照会テーブルを使用する。 | 複雑なルーティング論理、動的スケーリング。 |
ケーススタディでは、ユーザーIDに基づいて水平シャーディングを実装しました。これにより、5つのノードに負荷を分散できました。各ノードは約20%のトラフィックを処理しました。これにより、単一のストレージエンジンへの負荷が軽減されました。
🚀 フェーズ4:クエリ最適化
完璧なスキーマであっても、悪いクエリはパフォーマンスを殺す。オプティマイザは実行計画を選択する。あなたがそれを導く必要がある。
フルテーブルスキャンの回避
常にクエリがインデックスを使用することを確認する。テーブル全体をスキャンすると、スケーリング時にタイムアウトする。実行計画を確認する。「テーブルスキャン」ではなく「インデックススキャン」または「インデックスシーク」を確認する。
結果セットの制限
すべてのレコードを取得してはならない。ページネーションを使用する。1回のリクエストで返される行数を制限する。
- オフセットリミット:標準的なページネーション。深いオフセットでは遅くなることがある。
- キーセットページネーション:最後に確認したIDを使って次のページを取得する。はるかに高速。
バッチ処理
単一のトランザクションで数百万回の更新を行わない。バッチに分割する。
- 1,000件ごとにコミットする。
- これによりログファイルの成長を抑える。
- これにより長時間のロックを防ぐ。
⚠️ 避けるべき一般的な落とし穴
スケーリングは新たなリスクをもたらす。これらの一般的なミスに注意する。
- 過剰なインデックス化:インデックスが多すぎると書き込みが遅くなる。書き込みパフォーマンスを監視する。
- データ型の無視:使用する
VARCHAR固定長のIDではスペースが無駄になります。代わりにINTまたはBIGINT. - N+1クエリ:ループ内で関連データを取得する。イージーローディングまたはバッチ結合を使用する。
- ソフトデリート:レコードを削除済みとしてマークすると、それらはテーブルに永遠に残る。古いデータはアーカイブする。
- スキーマのロック:システムが稼働中にテーブル構造を変更する。オンラインスキーマ変更を使用する。
📊 監視すべきパフォーマンスメトリクス
測定しないものは改善できない。ベースラインを確立する。これらのメトリクスを継続的に監視する。
- 1秒あたりの行数:データの書き込み速度はどれほど速いですか?
- 1秒あたりのクエリ数:読み取りトラフィックはどれほどありますか?
- キャッシュヒット率:読み取りはメモリにヒットしていますか、ディスクにヒットしていますか?
- ロック待機時間:トランザクションはリソースの待機中ですか?
- ディスクI/O:ストレージは飽和していますか?
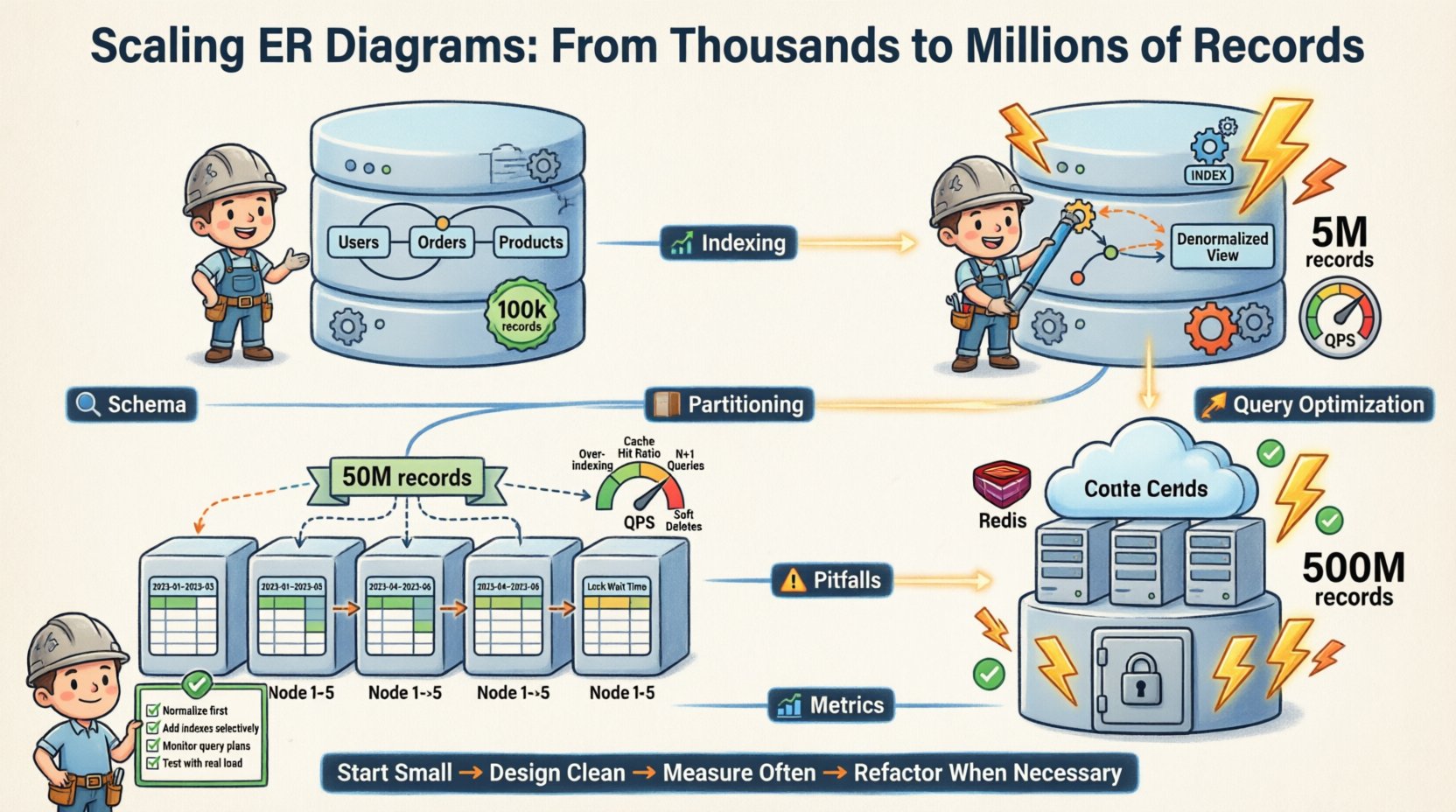
🔄 ERDの進化
エンティティ関係図は静的な文書ではありません。生きている設計図です。システムがスケーリングするにつれて、ERDも変化します。
以下が私たちのスキーマ進化のプロセスです:
- フェーズ1(開始):完全正規化。3NF。単一のデータベースインスタンス。10万件のレコード。
- フェーズ2(成長): 読み込みが重いテーブルの非正規化。インデックスを追加。単一インスタンス。500万件のレコード。
- フェーズ3(スケーリング): 水平パーティショニング。ユーザーIDでシャーディング。複数インスタンス。5000万件のレコード。
- フェーズ4(成熟): 古いデータのアーカイブ。キャッシュレイヤーの統合。読み取りレプリカ。5億件のレコード。
各フェーズでは論理モデルに特定の変更が必要だった。コアとなる関係性は安定したままだった。物理的な実装は適応した。
🛠️ スケーリングのチェックリスト
高負荷環境へのデプロイの前に、このチェックリストを使用してください。
- ☐ すべての外部キーにサポートインデックスが存在することを確認する。
- ☐
SELECT *アプリケーションコードに含まれていないか確認する。 - ☐ パーティショニングキーが均等に分散されていることを確認する。
- ☐ データベースノードのフェイルオーバーシナリオをテストする。
- ☐ コネクションプールの設定を見直す。
- ☐ データのアーカイブとクリーンアップの計画を立てる。
- ☐ 遅いクエリに対するモニタリングアラートを実装する。
- ☐ スキーマ変更手順を文書化する。
💡 可靠性に関する最終的な考察
ER図のスケーリングはスピードだけの話ではない。信頼性が重要である。負荷に耐えられずクラッシュする高速なシステムは無意味である。遅いが安定したシステムは管理可能である。
目標は成長を見越した構造を設計することである。ストレージコストと計算コストのバランスを取らなければならない。一貫性と可用性のバランスも取らなければならない。これらが分散システムの基本的なトレードオフである。
これらの原則に従うことで、データアーキテクチャが堅牢を保てる。数千から数百万への移行も破綻せずに処理できる。鍵となるのは準備である。鍵となるのはテストである。鍵となるのはストレージエンジンの下地となるメカニズムを理解することである。
小さな規模から始める。クリーンな設計を行う。頻繁に測定する。必要に応じてリファクタリングする。これが持続可能なスケーリングへの道である。

