



エンティティ関係図(ERD)は、データベース設計の基盤となる設計図です。複雑なビジネス要件を、データストアの構築をガイドする構造的な視覚モデルに変換します。データモデリングにおいて見られるさまざまな関係タイプの中で、多対多関係はしばしば最大の課題をもたらします。これらの接続をどのように表現し、実装するかを理解することは、データの整合性を維持し、クエリのパフォーマンスを確保するために不可欠です。
このガイドでは、概念的および論理的モデリングの文脈の中で、多対多関係のメカニズムを検討します。標準的なリレーショナル構造が直接的なM:N接続に対処できない理由、関連エンティティを使用してそれらを解決する方法、そしてクリーンなスキーマを維持するためのベストプラクティスについても説明します。
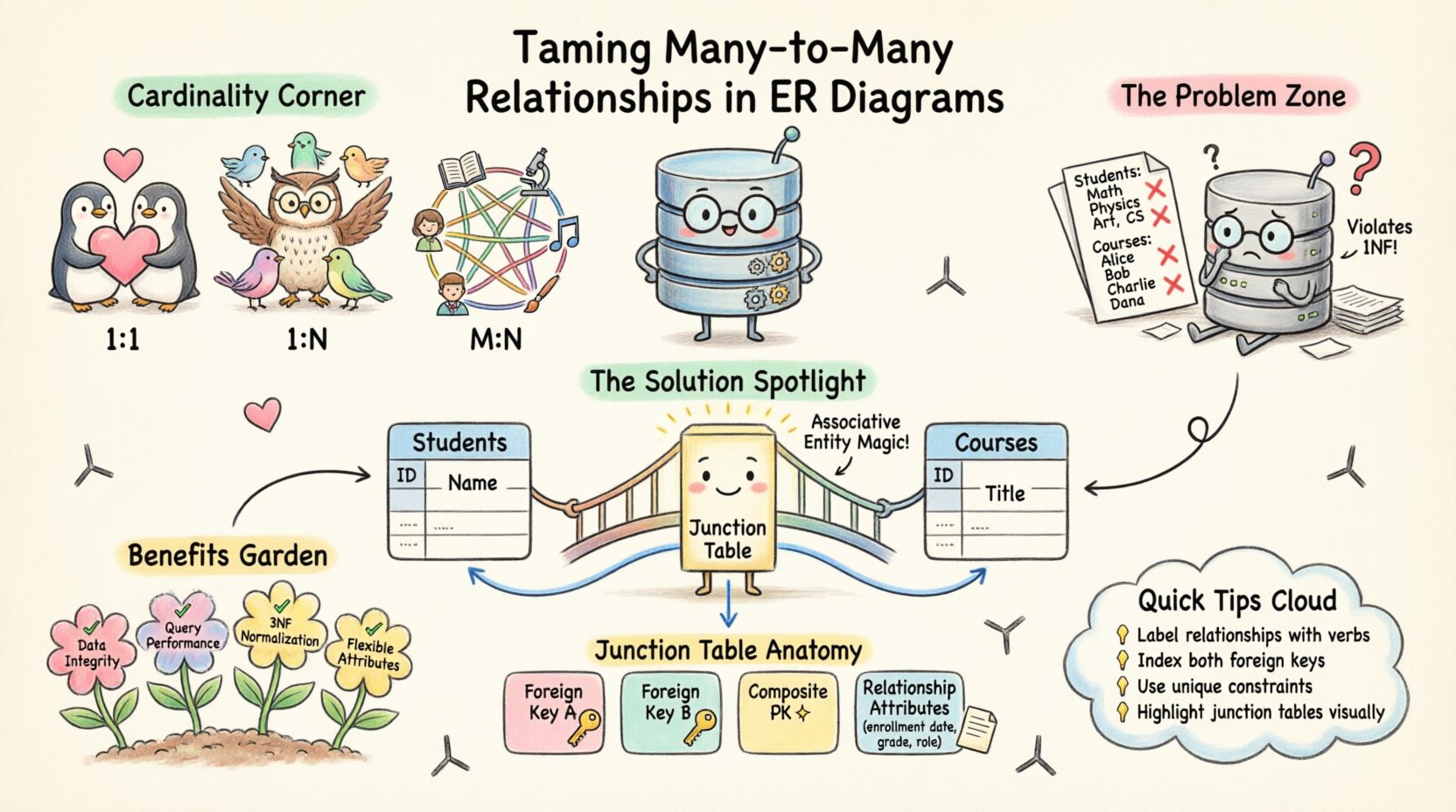
基数と関係タイプの理解 🔗
複雑なシナリオに取り組む前に、データエンティティがどのように相互作用するかを定義する基本的な基数を確認することが不可欠です。基数は、2つの接続されたテーブルのレコード間の数的関係を指定します。
- 1対1(1:1):Table Aの1つのレコードが、Table Bの正確に1つのレコードと関連しています。ユーザーのプロフィールが1つの決済方法とリンクされているような状況でよく見られます。
- 1対多(1:N):Table Aの1つのレコードが、Table Bの複数のレコードと関連しています。たとえば、1人の著者が多くの本を執筆しますが、各本には1人の主要な著者がいます。
- 多対多(M:N):Table Aの複数のレコードが、Table Bの複数のレコードと関連しています。代表的な例として、学生と授業があります。1人の学生が複数の授業に登録し、1つの授業には複数の学生がいます。
1:1および1:N関係は、リレーショナルデータベースシステムにおいて直接外部キーにマッピングできますが、M:N関係はより洗練されたアプローチを必要とします。リレーショナル理論では、関係自体が独立したエンティティであり、独自の属性と制約を持つと規定しています。
多対多の核心的な課題 🧩
純粋なリレーショナルモデルでは、冗長性を生じたり正規化ルールに違反したりせずに、1つのテーブルに外部キーを配置して、別のテーブルの複数の行を参照することはできません。たとえば、学生テーブルにコースIDのリスト(例:カンマ区切りの文字列)を格納しようとすると、第1正規形(1NF)に違反します。これにより、コース名を更新する際に複数の行を変更する必要が生じ、特定のコースに登録された学生を検索する際の効率が低下します。
したがって、標準的な解決策は、M:N関係を2つの1:N関係に分割することです。このプロセスにより、抽象的な接続がデータベースエンジンが効率的に処理できる物理的な構造に変換されます。
戦略1:関連エンティティパターン 🔗
多対多関係を解決する最も効果的な方法は、関連エンティティ(しばしば接続テーブル、ブリッジテーブル、または交差テーブルとして知られる)を作成することです。このテーブルは、2つの親エンティティを結びつけるためにのみ存在します。
関連エンティティを導入すると、元のM:N関係が分解されます。Entity Aと接続テーブルの間の関係は1対多になります。同様に、Entity Bと接続テーブルの間の関係も1対多になります。
関連エンティティの構造
関連エンティティは通常、以下の要素を含みます:
- 外部キーA:Entity Aの主キーを参照します。
- 外部キーB:Entity Bの主キーを参照します。
- 複合主キー:多くの場合、外部キーAと外部キーBの組み合わせが、接続レコードの固有識別子になります。
- 関係属性:関係自体に特有のデータ(例:登録日、成績、役割、数量)はここに属し、親テーブルには含まれません。
学生と授業のシナリオを考えてみましょう。直接的なリンクは、学生が異なる成績で同じ授業に複数回登録可能であることを意味します。接続テーブル「Student_Course_Enrollment、各生徒ごとの各コースの成績を記録します。
ER図における視覚的表現
図面上では、親エンティティから結合エンティティへ向かって2本の線が引かれます。クロウズフット表記(または同等の基数記号)では、親側に単一の線、結合側にクロウズフットが両方の関係に対して表示されます。
戦略2:関係に属性を扱う方法 📝
関連エンティティを使用する主な理由の一つは、関係自体を記述する属性を格納することです。関係に属性がない場合、代替のモデリング手法を検討するかもしれませんが、実際には、ほぼすべての現実世界のM:N関係には特定のデータが含まれています。
- 登録日時:生徒はいつコースに登録しましたか?
- 役割:この文脈では、ユーザーは講師、補助者、または生徒ですか?
- 価格:ベンダーと製品の間のこの特定の取引に関連する費用はいくらでしたか?
これらの属性を親テーブル(生徒またはコース)に配置すると、データの重複が生じます。生徒が5つのコースを受講する場合、誤って重複させると最初のコースの登録日が5回保存されることになり、重複させない場合、保存が不可能になります。結合テーブルを使用することで、このデータを明確に分離できます。
実装のメカニズムと制約 ⚙️
論理モデルから物理スキーマに移行する際、特定の技術的考慮事項がデータ整合性を保証します。無効なデータがシステムに入ることを防ぐために、制約を定義する必要があります。
外部キー制約
結合テーブル内の親エンティティを参照するすべての列は、外部キーとして定義される必要があります。これにより参照整合性が確保されます。
- 生徒レコードが削除された場合、対応する結合レコードを適切に処理する必要があります。オプションとして、連鎖削除(すべてのリンクを削除)または削除制限(リンクが存在する場合は生徒を削除しない)があります。
- 同様に、コースが削除された場合、そのコースへのリンクはビジネスルールに従って管理されるべきです。
一意制約
関係内の重複エントリを防ぐために、2つの外部キーの組み合わせに一意制約が適用されます。これにより、システムが複数回の登録を明示的に許可しない限り、生徒が同じコースに2回以上登録されることを防ぎます(例:再履修)。その場合、追加キーとして「登録ID」が追加されます。
インデックス戦略
結合テーブルのクエリにおいてパフォーマンスは非常に重要です。これらのテーブルは結合操作のボトルネックになりがちなので、適切なインデックスは必須です。
- 両方の外部キー列それぞれにインデックスを作成することで、どちらの親側からの検索も高速化できます。
- 2つの外部キーに複合インデックスを設定することは、一意制約の維持と結合クエリの最適化に不可欠です。
M:Nモデリングにおける一般的な落とし穴 🚧
経験豊富なデザイナーでも、これらのパターンを実装する際に問題に直面することがあります。一般的なミスに気づくことで、より強靭なシステムの構築が可能になります。
1. 自己参照の多対多
場合によっては、エンティティが自分自身と多対多の関係を持つことがあります。代表的な例が、従業員とそのマネージャーです。従業員は1人のマネージャーを持つ一方、マネージャーは複数の従業員を管理します。しかし、一部の組織構造では、複数のマネージャーが責任を共有する場合や、従業員がプロジェクトで同僚として協力する場合があります。プロジェクトに複数の従業員が共同で参加する場合、従業員-プロジェクトの結合が必要です。関係が厳密に階層的である場合は1:Nですが、同僚間の協働である場合はM:Nです。
自己参照型のM:N関係をモデル化する際、結合テーブルは同じエンティティテーブルを2回参照する。
2. 冗長な外部キー
親テーブルに結合テーブルを指す外部キーを追加しないでください。これにより循環依存が発生し、正規化の原則に違反します。結合テーブルは子であり、親は独立したままです。
3. 複数の結合テーブルによる過度な複雑化
時折、設計者は同じ関係に対して異なる種類のデータを処理するために複数の結合テーブルを作成する。これにより論理が分散する。データ型が根本的に互換性がない場合を除き、条件付き属性やNULL許容カラムを備えた1つの包括的な結合テーブルを持つ方が、関係を複数のテーブルに分割するよりも良い。
正規化とデータ整合性 🛡️
M:N関係を適切に扱うことは、データベースの正規化を直接支援する。関係の属性を別テーブルに移動することで、第三正規形(3NF)を達成できる。
- 1NF:繰り返しグループがない。結合テーブルにより、カンマ区切りのリストの必要性がなくなる。
- 2NF:部分的依存がない。結合テーブルの属性は、複合キーの一部ではなく全体に依存する。
- 3NF:推移的依存がない。属性はエンティティ自体ではなく、関係を記述する。
これらの形式に違反すると、更新異常が発生する。たとえば、コースタイトルを学生テーブルに保存すると、その学生がコースを受講したすべての行でタイトルを更新しなければならない。結合テーブルを使用すれば、コースタイトルはCourseテーブルにあり、結合テーブルはリンクのみを保持する。
多対多関係のクエリ 📉
スキーマが確立されると、データを取得するには3つのテーブル(親A、結合、親B)を結合する必要がある。これは標準的なSQL操作だが、カルテシアン積を避けるために注意深く構築する必要がある。
クエリ構造の例
特定のコースに登録されたすべての学生を取得するには:
- StudentテーブルをStudent IDで結合テーブルに結合する。
- 結合テーブルをCourse IDでCourseテーブルに結合する。
- 特定のCourse IDでフィルタリングする。
明示的なJOIN構文(INNER JOINまたはLEFT JOIN)を使用することが、明確性とパフォーマンスの観点から、暗黙的結合(FROM句内のカンマ区切りテーブル)よりも推奨される。
パフォーマンス上の考慮事項
データ量が増えるにつれて、結合テーブルは大きくなる可能性がある。学生のすべてのコースを頻繁にリストアップする必要がある場合は、結合テーブル内のStudent IDに対するインデックスが最適化されていることを確認する。コースのすべての学生をリストアップする必要がある場合は、Course IDに対するインデックスを最適化する必要がある。高トラフィックシステムでは、レポートテーブルに対して正規化を緩和する可能性があるが、トランザクションのコアは正規化されたままにするべきである。
ERDの視覚的ベストプラクティス 🎨
ドキュメントの明確さは、コードそのものと同じくらい重要である。ER図を描く際は、ステークホルダーがモデルを理解できるようにするため、以下のガイドラインに従う。
- 関係を明確にラベル付けする:関係を説明するために動詞を使用する(例:「受講する」、「管理する」、「含む」)。
- 一貫した表記を使用する:文書全体で、クロウズフット記法やチェン記法などの1つの標準に従う。
- 結合テーブルを強調する:関連するエンティティを視覚的に区別する。このテーブルがコアビジネスエンティティではなくリンクであることを示すために、異なる形状や色を使用するかもしれない。
- 属性を文書化する:関係に特有の属性(例:「入会日」)が結合テーブル上に表示されるようにし、隠さないようにする。
実装アプローチの比較 📊
以下は、異なる関係タイプが物理スキーマ内でどのように扱われるかの比較である。
| 関係の種類 | スキーマの実装 | 主キーの位置 | 外部キーの使用 |
|---|---|---|---|
| 1対1 | 1つのテーブルに外部キー | どちらのテーブルでもよい | オプションまたは必須 |
| 1対多 | 「多」側のテーブルに外部キー | 主テーブル | 子テーブルで必須 |
| 多対多 | 専用の結合テーブル | 複合(FK1 + FK2) | 両方の側で結合テーブルで必須 |
表が示すように、多対多関係は専用の構造を必要とする点で他と異なります。この構造的な分離が、データの重複なしにデータベースエンジンが複雑さを管理できる理由です。
高度な考慮事項:弱いエンティティ 🌱
場合によっては、関連するエンティティは弱いエンティティと見なされることがある。これは、結合テーブルが親エンティティなしでは存在できない場合に発生する。結合テーブルは技術的には外部キーに依存しているが、存在の観点では通常、強いエンティティとして扱われる。ただし、結合テーブルに存在を示唆する重要なビジネスロジック(例:注文明細)が含まれている場合は、主要エンティティと同様の厳密さで扱うべきである。
関係がオプションの場合(例:学生がまだコースを選択していない場合)、結合テーブルの外部キーはNULL値を許容すべきであるが、アクティブなリンクではこれは稀である。通常、結合テーブルに行が存在することにより、関係が有効であるとみなされる。
再帰的関係の処理 🔁
再帰的関係とは、エンティティが自分自身と関係を持つ特殊なケースである。部門が複数のサブ部門を持つ階層をモデル化する場合、サブ部門も複数のサブ部門を持つことができる。これは再帰的な1:Nである。一方、誰もが誰とでも友達になれる友人ネットワークをモデル化する場合、これは再帰的なM:Nである。
実装は標準的なM:Nと同様だが、結合テーブル内の外部キーは両方とも同じ親テーブルを指す。これにより、役割を区別するための注意深い命名規則が必要となる(例:友人_ID_1 と Friend_ID_2).
データアーキテクチャの前進 🚀
多数対多数の関係を設計することは、データアーキテクチャにおける基本的なスキルです。静的なリストを考えるのではなく、動的な接続を考えるという意識の転換が必要です。関連エンティティパターンに従うことで、データベースがスケーラブルでメンテナンスしやすく、 poorly normalized design に伴う異常から解放されることを保証できます。
図はコミュニケーションのためのツールであることを思い出してください。明確なERDは、開発者、アナリスト、ステークホルダー間の誤解を防ぎます。多数対多数の状況に直面したときは、一時停止して次のように尋ねてください:「この接続に固有のデータはありますか?」答えが「はい」なら、ジョインテーブルは必須です。答えが「いいえ」なら、単純なリンクで十分です。
これらの高度な戦略を適用することで、複雑なクエリや柔軟なビジネスルールをサポートする基盤を構築できます。設計段階でこれらの関係を正しくモデル化するための努力は、アプリケーションのライフサイクル全体にわたり、パフォーマンスと安定性という恩恵をもたらします。
要件が進化するにつれて、継続的にスキーマを見直してください。関係は変化し、モデルは完全な見直しが必要ない程度に柔軟で、新しい接続を扱えるようにするべきです。この適応性こそが、成熟したデータ設計の特徴です。

