










Todo arquiteto de dados enfrenta o mesmo momento decisivo. Você começa com um esquema limpo e normalizado. O banco de dados manipula milhares de registros sem esforço. As consultas retornam em milissegundos. O Diagrama de Relacionamento de Entidades (ERD) parece elegante. Depois, o negócio cresce. A adoção pelos usuários aumenta drasticamente. O volume de dados explode. De repente, o sistema começa a lentidão. As junções levam segundos. Os bloqueios impedem transações. O projeto original do ERD torna-se um fardo.
Este guia detalha a transição de um banco de dados de pequena escala para um ambiente de produção de alto volume. Exploramos as mudanças estruturais necessárias para manter o desempenho sem comprometer a integridade dos dados. O foco permanece no design lógico, estratégias de indexação e técnicas de particionamento. Nenhum software específico do fornecedor é mencionado aqui; os princípios se aplicam a qualquer motor de armazenamento relacional.
🏗️ O Ponto de Partida: Projetando para o Crescimento
Quando um aplicativo começa, a prioridade é a velocidade de desenvolvimento. O ERD reflete com precisão o domínio do negócio. A normalização é alta. A Terceira Forma Normal (3NF) é frequentemente o objetivo. Isso minimiza a redundância. Garante a consistência dos dados. No entanto, essa abordagem assume um padrão de carga de trabalho específico. Assume que as consultas são simples. Assume que o conjunto de dados cabe confortavelmente na memória.
À medida que o conjunto de dados cresce, as suposições falham. O custo das junções aumenta logaritmicamente. O volume de dados escaneados pelo processador de consultas cresce linearmente. A E/S de disco torna-se o gargalo. A arquitetura exige uma mudança da pureza lógica para o desempenho físico.
Identificando o Ponto de Quebra
Antes de refatorar, você precisa entender onde o sistema falha. A transição de milhares para milhões de registros muda a física da recuperação de dados. Procure esses indicadores:
- Latência de Consulta:Consultas que levavam 5ms agora levam 500ms.
- Contenção de Bloqueios:Transações aguardam o desbloqueio dos bloqueios.
- Taxa de Escrita:Inserções ficam mais lentas devido à manutenção de índices.
- Pressão de Memória:A pool de buffer não consegue armazenar em cache tabelas frequentemente acessadas.
- Saturação da Rede:Grandes conjuntos de resultados consomem largura de banda.
Quando esses sintomas aparecem, o ERD deve evoluir. Você não pode simplesmente adicionar mais hardware. Deve otimizar a estrutura.
🔍 Fase 1: Refatoração do Esquema
O primeiro passo para escalar é auditando o Diagrama de Relacionamento de Entidades. Você precisa verificar se a estrutura atual suporta os padrões de consulta necessários em grande escala.
Normalização versus Denormalização
A normalização reduz a duplicação de dados. Simplifica as atualizações. No entanto, força junções. Junções são caras em grande escala. A denormalização introduz redundância. Reduz junções. Acelera leituras. Esse é um trade-off que deve ser gerenciado com cuidado.
n
Considere as seguintes estratégias:
- Cargas de Trabalho com Leituras Intensivas:Denormalize atributos frequentemente acessados. Armazene-os diretamente na tabela principal para evitar junções.
- Cargas de Trabalho com Escritas Intensivas:Mantenha a normalização. Evite atualizações em cascata em múltiplas tabelas.
- Abordagem Híbrida: Mantenha o esquema principal normalizado. Crie visualizações materializadas ou tabelas de resumo para relatórios.
No nosso estudo de caso, o design original tinha dez tabelas unidas para recuperar um único perfil de usuário. Isso causou I/O excessivo no disco. Ao desnormalizar os atributos de usuário mais comuns na tabela principal de perfis, reduzimos o número de junções de dez para uma.
Tratamento de Campos de Texto Grandes
Armazenar strings grandes (CLOBs) na tabela principal pode retardar leituras de página. O motor do banco de dados precisa carregar toda a linha para verificar a chave primária. Se a linha for muito grande, ela pode ser transferida para o disco.
Boas práticas incluem:
- Separe campos de texto grandes em uma tabela vinculada.
- Busque apenas o campo de texto quando solicitado explicitamente.
- Armazene referências (IDs) em vez de conteúdo no índice principal.
📈 Fase 2: Estratégias de Indexação
Índices são o motor do desempenho de consultas. Um ERD bem projetado depende de índices para localizar dados rapidamente. À medida que os registros crescem, o tamanho do índice também aumenta. Manter índices consome recursos de gravação.
Índices Compostos
Índices de uma única coluna são frequentemente insuficientes. Índices compostos permitem que o motor filtre em múltios critérios simultaneamente. A ordem das colunas no índice importa. A coluna mais seletiva deve vir em primeiro lugar.
Por exemplo, se você filtrar por status e data, mas status tem baixa seletividade (por exemplo, apenas três valores), coloque data primeiro. Isso reduz o espaço de busca mais rapidamente.
Índices Cobertores
Um índice cobertor inclui todas as colunas necessárias pela consulta. O banco de dados pode atender à consulta usando apenas o índice. Não precisa acessar os dados da tabela (heap). Isso representa uma melhoria significativa de desempenho.
- Inclua todas as
SELECTcolunas. - Inclua todas as
WHEREcolunas da cláusula WHERE. - Inclua todas as
ORDENAR PORcolunas.
Manutenção de Índices
Índices não são estáticos. Eles fragmentam ao longo do tempo. Crescem com os dados. É necessária manutenção regular.
- Reconstrução:Desfragmenta a estrutura do índice.
- Reorganização:Reorganiza as páginas folha sem reconstrução completa.
- Monitoramento: Monitore índices não utilizados. Remova-os para economizar espaço de gravação.
🗄️ Fase 3: Particionamento e Sharding
Quando uma única tabela ultrapassa a capacidade de uma única unidade de disco ou pool de memória, o particionamento torna-se necessário. Isso divide uma tabela lógica em segmentos físicos menores.
Particionamento por Faixa
Este método divide os dados com base em um valor de faixa. Comumente usado para datas ou IDs sequenciais. Por exemplo, dividir os dados por ano.
- Benefício:Consultas filtradas pela chave de partição analisam apenas um segmento.
- Desvantagem:Consultas sem a chave de partição analisam todos os segmentos (varredura completa da tabela).
Particionamento por Hash
Este método distribui os dados de forma uniforme entre os segmentos usando uma função de hash em uma coluna-chave. Isso evita pontos quentes.
- Benefício:Distribuição uniforme dos dados.
- Desvantagem:Consultas por faixa tornam-se caras.
Sharding Horizontal vs. Vertical
O sharding leva o particionamento além, distribuindo dados entre várias instâncias de banco de dados.
| Estratégia | Descrição | Melhor Caso de Uso |
|---|---|---|
| Sharding Horizontal | Divida as linhas entre bancos de dados com base em uma chave. | Alto volume de escrita, grandes conjuntos de dados. |
| Sharding vertical | Divida as colunas entre bancos de dados com base no uso. | Colunas grandes, padrões de leitura distintos. |
| Sharding de diretório | Use uma tabela de pesquisa para rotear consultas. | Lógica de roteamento complexa, escalabilidade dinâmica. |
No nosso estudo de caso, implementamos o sharding horizontal com base no ID do usuário. Isso nos permitiu distribuir a carga entre cinco nós. Cada nó lidou com aproximadamente 20% do tráfego. Isso reduziu a carga em qualquer motor de armazenamento individual.
🚀 Fase 4: Otimização de Consultas
Mesmo com um esquema perfeito, consultas ruins matam o desempenho. O otimizador escolhe o plano de execução. Você precisa guiá-lo.
Evitando varreduras completas de tabela
Sempre certifique-se de que uma consulta use um índice. Se ela varrer toda a tabela, irá expirar em grande escala. Verifique o plano de execução. Procure por “Varredura de Índice” ou “Busca de Índice” em vez de “Varredura de Tabela”.
Limitando conjuntos de resultados
Nunca busque todos os registros. Use paginação. Limite o número de linhas retornadas por solicitação.
- Limite de deslocamento: Paginação padrão. Pode ser lenta em deslocamentos profundos.
- Paginação por conjunto de chaves: Use o último ID visto para buscar a próxima página. Muito mais rápido.
Agrupamento de operações
Não realize milhões de atualizações em uma única transação. Divida-as em lotes.
- Confirme após cada 1.000 registros.
- Isso reduz o crescimento do arquivo de log.
- Isso evita bloqueios de longa duração.
⚠️ Armadilhas comuns a evitar
Escalonar introduz novos riscos. Esteja ciente desses erros comuns.
- Sobrecarga de índices:Muitos índices tornam as escritas mais lentas. Monitore o desempenho de escrita.
- Ignorar tipos de dados: Usando
VARCHARpara IDs de comprimento fixo desperdiça espaço. UseINTouBIGINT. - Consultas N+1: Buscar dados relacionados em um loop. Use carregamento preguiçoso ou junções em lote.
- Exclusão suave:Marcar registros como excluídos mantém-os na tabela para sempre. Arquive dados antigos.
- Esquemas de bloqueio:Alterar a estrutura da tabela enquanto o sistema está ativo. Use alterações online no esquema.
📊 Métricas de Desempenho para Monitorar
Você não pode melhorar o que não mede. Estabeleça uma base. Monitore essas métricas continuamente.
- Linhas por segundo: Quão rápido os dados estão sendo gravados?
- Consultas por segundo: Quanta tráfego de leitura existe?
- Taxa de acerto no cache: As leituras estão atingindo a memória ou o disco?
- Tempo de espera por bloqueio: As transações estão esperando por recursos?
- E/S de disco: O armazenamento está saturado?
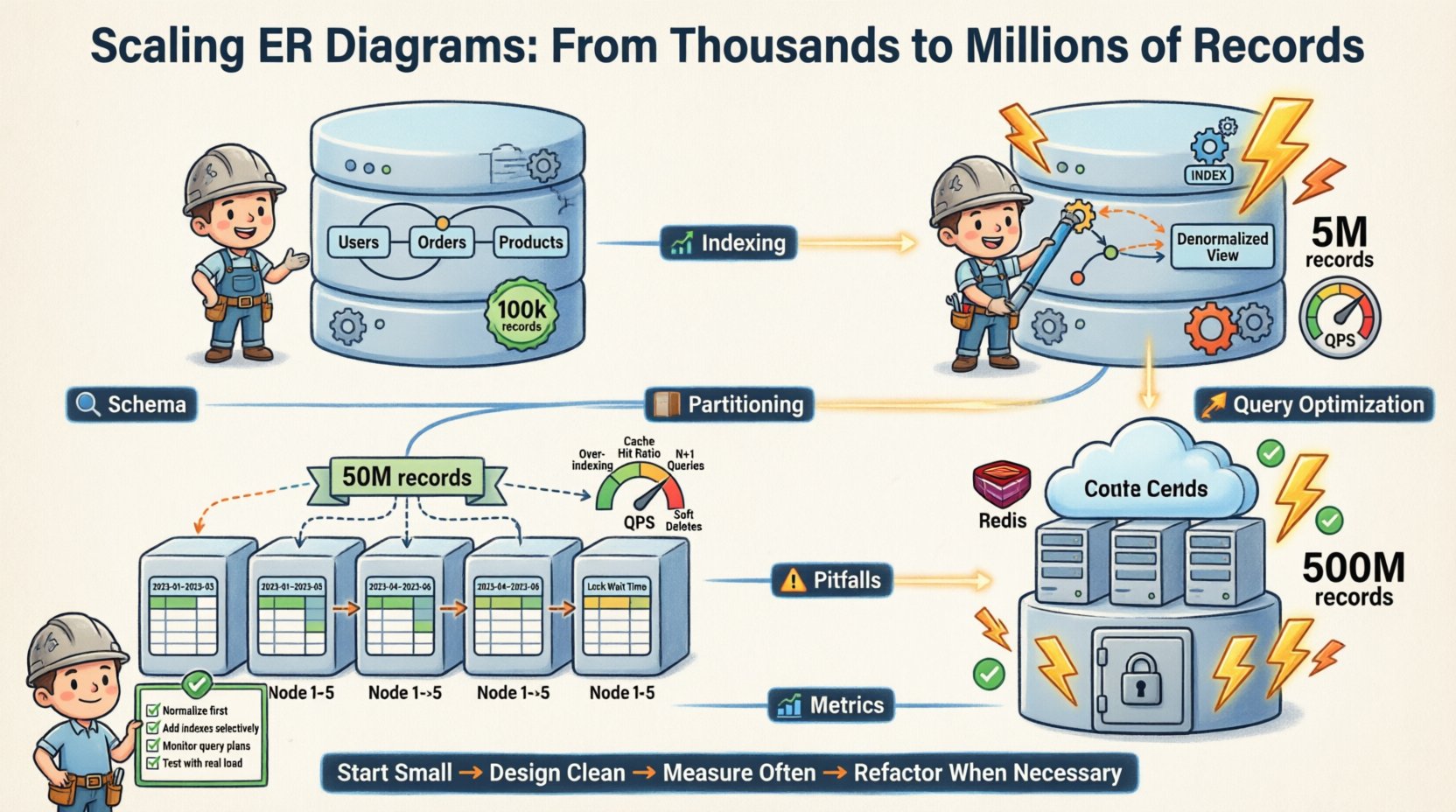
🔄 A Evolução do ERD
O Diagrama de Relacionamento de Entidades não é um documento estático. É um plano vivo. À medida que o sistema escala, o ERD muda.
Aqui está a evolução da nossa evolução de esquema:
- Fase 1 (Início): Totalmente normalizado. 3FN. Instância única de banco de dados. 100k registros.
- Fase 2 (Crescimento): Denormalização de tabelas com alta carga de leitura. Índices adicionados. Instância única. 5 milhões de registros.
- Fase 3 (Escalonamento):Particionamento horizontal. Fragmentado por ID de usuário. Múltiplas instâncias. 50 milhões de registros.
- Fase 4 (Maturidade):Arquivamento de dados antigos. Integração com camada de cache. Réplicas de leitura. 500 milhões de registros.
Cada fase exigiu mudanças específicas no modelo lógico. As relações principais permaneceram estáveis. A implementação física foi adaptada.
🛠️ Lista de verificação para escalonamento
Use esta lista de verificação antes de implantar em um ambiente de alta volume.
- ☐ Verifique se todas as chaves estrangeiras têm índices de apoio.
- ☐ Verifique se há
SELECT *no código da aplicação. - ☐ Certifique-se de que as chaves de particionamento sejam distribuídas uniformemente.
- ☐ Teste cenários de failover para nós do banco de dados.
- ☐ Revise as configurações da pool de conexões.
- ☐ Planeje o arquivamento e a limpeza de dados.
- ☐ Implemente alertas de monitoramento para consultas lentas.
- ☐ Documente os procedimentos de alteração de esquema.
💡 Pensamentos finais sobre confiabilidade
Escalonar um diagrama ER não é apenas sobre velocidade. É sobre confiabilidade. Um sistema rápido, mas que falha sob carga, é inútil. Um sistema lento, mas estável, é gerenciável.
O objetivo é projetar uma estrutura que antecipe o crescimento. Você deve equilibrar o custo de armazenamento contra o custo de computação. Você deve equilibrar consistência contra disponibilidade. Essas são as trocas fundamentais dos sistemas distribuídos.
Ao seguir esses princípios, você pode garantir que sua arquitetura de dados permaneça robusta. Você pode lidar com a transição de milhares para milhões sem falhar. A chave está na preparação. A chave está nos testes. A chave está em entender os mecanismos subjacentes do seu motor de armazenamento.
Comece pequeno. Projete com clareza. Meça com frequência. Refatore quando necessário. Este é o caminho para um escalonamento sustentável.

