










Cada arquitecto de datos enfrenta el mismo momento crucial. Comienzas con un esquema limpio y normalizado. La base de datos maneja miles de registros sin esfuerzo. Las consultas devuelven resultados en milisegundos. El diagrama de relaciones de entidades (ERD) parece elegante. Luego, el negocio crece. La adopción por parte de los usuarios aumenta bruscamente. El volumen de datos explota. De repente, el sistema se ralentiza. Las uniones tardan segundos. Los bloqueos detienen las transacciones. El diseño original del ERD se convierte en una carga.
Esta guía detalla la transición desde una base de datos de pequeña escala hasta un entorno de producción de alto volumen. Exploramos los cambios estructurales necesarios para mantener el rendimiento sin sacrificar la integridad de los datos. El enfoque se mantiene en el diseño lógico, las estrategias de indexación y las técnicas de partición. No se nombra ningún software específico del proveedor aquí; los principios se aplican a cualquier motor de almacenamiento relacional.
🏗️ El punto de partida: Diseñando para el crecimiento
Cuando una aplicación comienza, la prioridad es la velocidad de desarrollo. El ERD refleja con precisión el dominio del negocio. La normalización es alta. La Tercera Forma Normal (3NF) suele ser el objetivo. Esto minimiza la redundancia. Garantiza la consistencia de los datos. Sin embargo, este enfoque asume un patrón de trabajo específico. Supone que las consultas son simples. Supone que el conjunto de datos cabe cómodamente en la memoria.
A medida que el conjunto de datos crece, las suposiciones fallan. El costo de las uniones aumenta de forma logarítmica. El volumen de datos escaneados por el procesador de consultas crece de forma lineal. La E/S de disco se convierte en el cuello de botella. La arquitectura requiere un cambio desde la pureza lógica hacia el rendimiento físico.
Identificar el punto de ruptura
Antes de refactorizar, debes entender dónde falla el sistema. La transición de miles a millones de registros cambia la física de la recuperación de datos. Busca estos indicadores:
- Latencia de consultas:Consultas que tardaban 5 ms ahora tardan 500 ms.
- Contención de bloqueos:Las transacciones esperan a que se liberen los bloqueos.
- Rendimiento de escritura:Las inserciones se ralentizan debido al mantenimiento de índices.
- Presión de memoria:La memoria caché no puede almacenar en caché las tablas más frecuentemente accedidas.
- Saturación de red:Los conjuntos de resultados grandes consumen ancho de banda.
Cuando aparecen estos síntomas, el ERD debe evolucionar. No puedes simplemente añadir más hardware. Debes optimizar la estructura.
🔍 Fase 1: Refactorización de esquema
El primer paso para escalar es auditar el diagrama de relaciones de entidades. Debes verificar si la estructura actual soporta los patrones de consulta necesarios a escala.
Normalización frente a denormalización
La normalización reduce la duplicación de datos. Simplifica las actualizaciones. Sin embargo, obliga a realizar uniones. Las uniones son costosas a escala. La denormalización introduce redundancia. Reduce las uniones. Acelera las lecturas. Esta es una compensación que debe gestionarse con cuidado.
n
Considera las siguientes estrategias:
- Cargas de trabajo con muchas lecturas:Denormaliza los atributos frecuentemente accedidos. Guárdalos directamente en la tabla principal para evitar uniones.
- Cargas de trabajo con muchas escrituras:Mantén la normalización. Evita actualizaciones en cascada entre múltiples tablas.
- Enfoque híbrido: Mantenga el esquema principal normalizado. Cree vistas materializadas o tablas de resumen para informes.
En nuestro estudio de caso, el diseño original tenía diez tablas unidas para recuperar un perfil de usuario único. Esto provocó un uso excesivo de E/S de disco. Al denormalizar los atributos de usuario más comunes en la tabla principal de perfiles, redujimos el número de uniones de diez a una.
Manejo de campos de texto grandes
Almacenar cadenas grandes (CLOBs) en la tabla principal puede ralentizar las lecturas de página. El motor de base de datos debe cargar toda la fila para verificar la clave primaria. Si la fila es demasiado grande, podría desbordarse al disco.
Las mejores prácticas incluyen:
- Separe los campos de texto grandes en una tabla vinculada.
- Solo recupere el campo de texto cuando se solicite explícitamente.
- Almacene referencias (IDs) en lugar de contenido en el índice principal.
📈 Fase 2: Estrategias de indexación
Los índices son el motor del rendimiento de las consultas. Un ERD bien diseñado depende de los índices para localizar los datos rápidamente. A medida que crecen los registros, el tamaño del índice también crece. El mantenimiento de los índices consume recursos de escritura.
Índices compuestos
Los índices de una sola columna a menudo son insuficientes. Los índices compuestos permiten al motor filtrar según múltiples criterios simultáneamente. El orden de las columnas en el índice importa. La columna más selectiva debe ir primero.
Por ejemplo, si filtra por estado y fecha, pero estado tiene baja selectividad (por ejemplo, solo tres valores), coloque fechaprimero. Esto reduce más rápidamente el espacio de búsqueda.
Índices cubiertos
Un índice cubierto incluye todas las columnas requeridas por la consulta. La base de datos puede satisfacer la consulta utilizando solo el índice. No necesita acceder a los datos de la tabla (heap). Esto representa una mejora significativa en el rendimiento.
- Incluya todas las
SELECTcolumnas. - Incluya todas las
WHEREcolumnas de la cláusula WHERE. - Incluya todas las
ORDENAR PORcolumnas.
Mantenimiento de índices
Los índices no son estáticos. Se fragmentan con el tiempo. Crecen con los datos. Se requiere mantenimiento regular.
- Reconstrucción:Desfragmenta la estructura del índice.
- Reorganización:Reordena las páginas hoja sin reconstrucción completa.
- Monitoreo:Monitorea los índices no utilizados. Elimínalos para ahorrar espacio de escritura.
🗄️ Fase 3: Particionamiento y fragmentación
Cuando una sola tabla supera la capacidad de un disco o grupo de memoria individual, el particionamiento se vuelve necesario. Esto divide una tabla lógica en segmentos físicos más pequeños.
Particionamiento por rango
Este método divide los datos según un valor de rango. Se utiliza comúnmente para fechas o identificadores secuenciales. Por ejemplo, dividir los datos por año.
- Ventaja:Las consultas que filtran por la clave de partición escanean solo un segmento.
- Desventaja:Las consultas sin la clave de partición escanean todos los segmentos (escaneo completo de la tabla).
Particionamiento por hash
Este método distribuye los datos de forma uniforme entre los segmentos utilizando una función hash en una columna clave. Evita los puntos calientes.
- Ventaja:Distribución uniforme de los datos.
- Desventaja:Las consultas de rango se vuelven costosas.
Fragmentación horizontal frente a vertical
La fragmentación lleva el particionamiento más lejos al distribuir los datos entre varias instancias de base de datos.
| Estrategia | Descripción | Mejor caso de uso |
|---|---|---|
| Fragmentación horizontal | Divida las filas entre bases de datos según una clave. | Alto volumen de escritura, grandes conjuntos de datos. |
| Fragmentación vertical | Divida las columnas entre bases de datos según su uso. | Columnas grandes, patrones de lectura distintos. |
| Fragmentación por directorio | Use una tabla de búsqueda para enrutar consultas. | Lógica de enrutamiento compleja, escalado dinámico. |
En nuestro estudio de caso, implementamos la fragmentación horizontal basada en el ID de usuario. Esto nos permitió distribuir la carga entre cinco nodos. Cada nodo manejó aproximadamente el 20 % del tráfico. Esto redujo la carga sobre cualquier motor de almacenamiento individual.
🚀 Fase 4: Optimización de consultas
Incluso con un esquema perfecto, las consultas malas matan el rendimiento. El optimizador elige el plan de ejecución. Debes guiarlo.
Evitar escaneos completos de tablas
Asegúrese siempre de que una consulta use un índice. Si escanea toda la tabla, se agotará a escala. Revise el plan de ejecución. Busque “Escaneo de índice” o “Búsqueda de índice” en lugar de “Escaneo de tabla”.
Limitar conjuntos de resultados
Nunca recupere todos los registros. Use la paginación. Limite el número de filas devueltas por solicitud.
- Límite de desplazamiento:Paginación estándar. Puede ser lenta en desplazamientos profundos.
- Paginación por conjunto de claves:Use el último ID visto para obtener la siguiente página. Mucho más rápido.
Agrupación de operaciones
No realice millones de actualizaciones en una sola transacción. Divídalas en lotes.
- Confirme después de cada 1.000 registros.
- Esto reduce el crecimiento del archivo de registro.
- Esto evita bloqueos prolongados.
⚠️ Peligros comunes que deben evitarse
La escalabilidad introduce nuevos riesgos. Esté atento a estos errores comunes.
- Sobrecarga de índices:Demasiados índices ralentizan las escrituras. Monitoree el rendimiento de escritura.
- Ignorar tipos de datos: Usando
VARCHARpara identificadores de longitud fija desperdicia espacio. UseINToBIGINT. - Consultas N+1: Recuperar datos relacionados en un bucle. Use carga anticipada o uniones por lotes.
- Eliminaciones suaves:Marcar registros como eliminados los mantiene en la tabla para siempre. Archive los datos antiguos.
- Bloqueo de esquemas: Cambiar la estructura de la tabla mientras el sistema está en funcionamiento. Use cambios en el esquema en línea.
📊 Métricas de rendimiento a monitorear
No puedes mejorar lo que no mides. Establece una base. Monitorea estas métricas continuamente.
- Filas por segundo: ¿Qué tan rápido se están escribiendo los datos?
- Consultas por segundo: ¿Cuánto tráfico de lectura existe?
- Ratio de aciertos en caché: ¿Las lecturas están alcanzando la memoria o el disco?
- Tiempo de espera de bloqueos: ¿Las transacciones están esperando recursos?
- Entrada/Salida del disco: ¿Está saturado el almacenamiento?
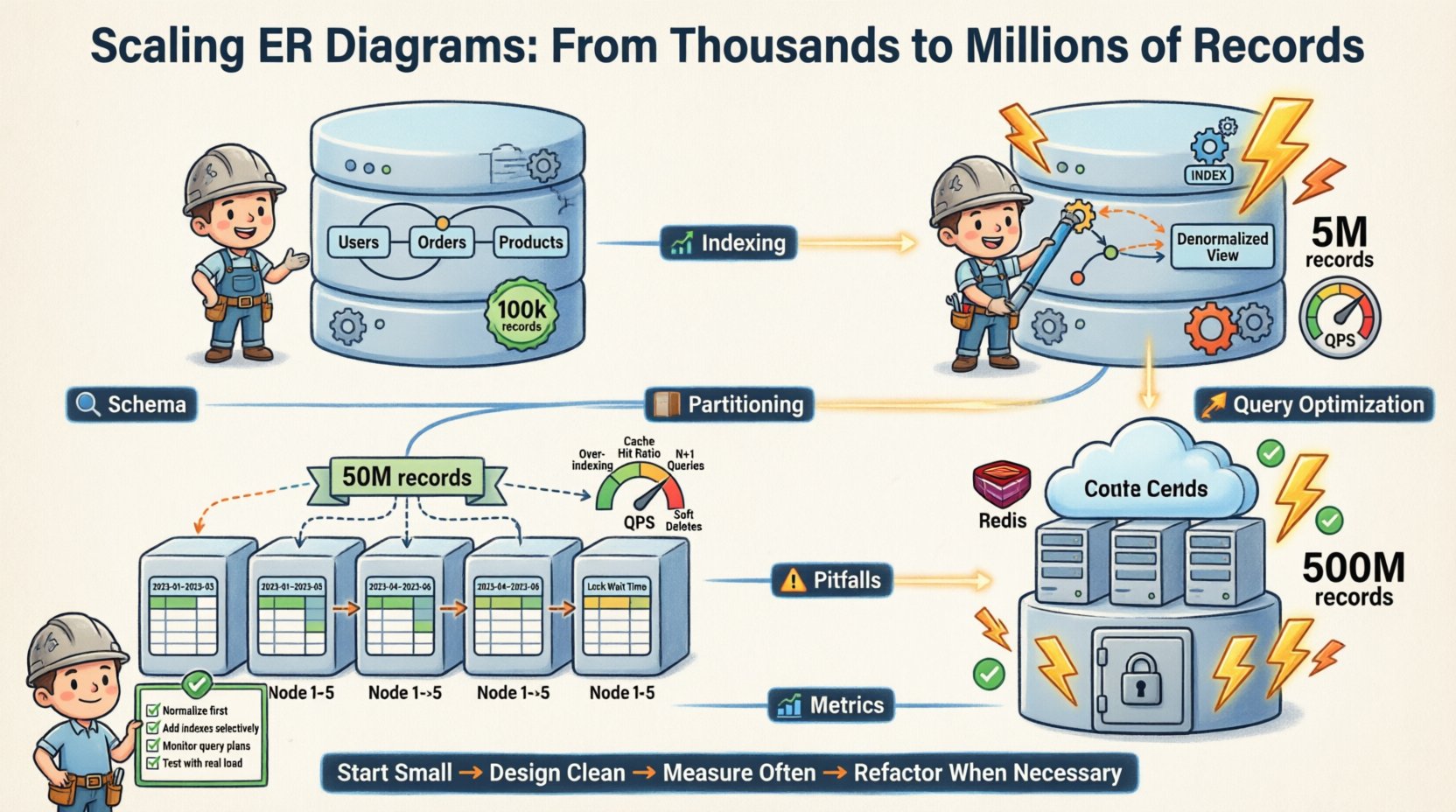
🔄 La evolución del diagrama ER
El diagrama de entidades y relaciones no es un documento estático. Es un plano vivo. A medida que el sistema crece, el diagrama ER cambia.
Aquí está la progresión de la evolución de nuestro esquema:
- Fase 1 (Inicio): Totalmente normalizado. 3FN. Instancia única de base de datos. 100k registros.
- Fase 2 (Crecimiento): Denormalización de tablas con alta carga de lectura. Se agregaron índices. Instancia única. 5 millones de registros.
- Fase 3 (Escalado):Particionamiento horizontal. Fragmentado por ID de usuario. Múltiples instancias. 50 millones de registros.
- Fase 4 (Madurez):Archivado de datos antiguos. Integración de capa de caché. Réplicas de lectura. 500 millones de registros.
Cada fase requirió cambios específicos en el modelo lógico. Las relaciones principales permanecieron estables. La implementación física se adaptó.
🛠️ Lista de verificación para escalado
Utilice esta lista de verificación antes de implementar en un entorno de alto volumen.
- ☐ Verifique que todas las claves foráneas tengan índices de soporte.
- ☐ Verifique si hay
SELECT *en el código de la aplicación. - ☐ Asegúrese de que las claves de particionamiento se distribuyan de forma uniforme.
- ☐ Pruebe escenarios de conmutación por error para los nodos de la base de datos.
- ☐ Revise la configuración de los grupos de conexiones.
- ☐ Planee el archivado y limpieza de datos.
- ☐ Implemente alertas de monitoreo para consultas lentas.
- ☐ Documente los procedimientos de cambio de esquema.
💡 Reflexiones finales sobre la confiabilidad
Escalado de un diagrama ER no se trata solo de velocidad. Se trata de confiabilidad. Un sistema rápido pero que falla bajo carga es inútil. Un sistema lento pero estable es manejable.
El objetivo es diseñar una estructura que anticipe el crecimiento. Debe equilibrar el costo del almacenamiento frente al costo de cómputo. Debe equilibrar la consistencia frente a la disponibilidad. Estas son las trade-offs fundamentales de los sistemas distribuidos.
Siguiendo estos principios, puede asegurarse de que su arquitectura de datos permanezca robusta. Puede manejar la transición de miles a millones sin romperse. La clave está en la preparación. La clave está en la prueba. La clave está en comprender los mecanismos subyacentes de su motor de almacenamiento.
Empiece pequeño. Diseñe limpio. Mida con frecuencia. Refactore cuando sea necesario. Este es el camino hacia una escala sostenible.

