











Cuando una arquitectura de base de datos diseñada en papel funciona perfectamente en un entorno de pruebas pero colapsa bajo tráfico del mundo real, la desconexión a menudo reside entre el modelo visual y la realidad en tiempo de ejecución. Un diagrama de entidades y relaciones (ERD) es un plano, no un motor vivo. Sin embargo, cuando los desarrolladores hablan de un ‘ERD que falla bajo carga’, generalmente se refieren a un diseño de esquema derivado de ese diagrama que no puede soportar las demandas de producción. Esta guía aborda los cuellos de botella estructurales, lógicos y de rendimiento que hacen que los modelos relacionales tengan dificultades cuando aumenta el volumen de datos y la concurrencia.
Diagnosticar estos problemas requiere una comprensión profunda de cómo las relaciones de datos se traducen en operaciones de E/S, contención de bloqueos y uso de memoria. Exploraremos los puntos de fricción donde las decisiones de diseño chocan con las limitaciones del hardware y los patrones de tráfico. Al identificar los síntomas específicos de un fallo estructural, podrá refactorizar su modelo de datos para soportar escalabilidad sin comprometer la integridad de los datos.
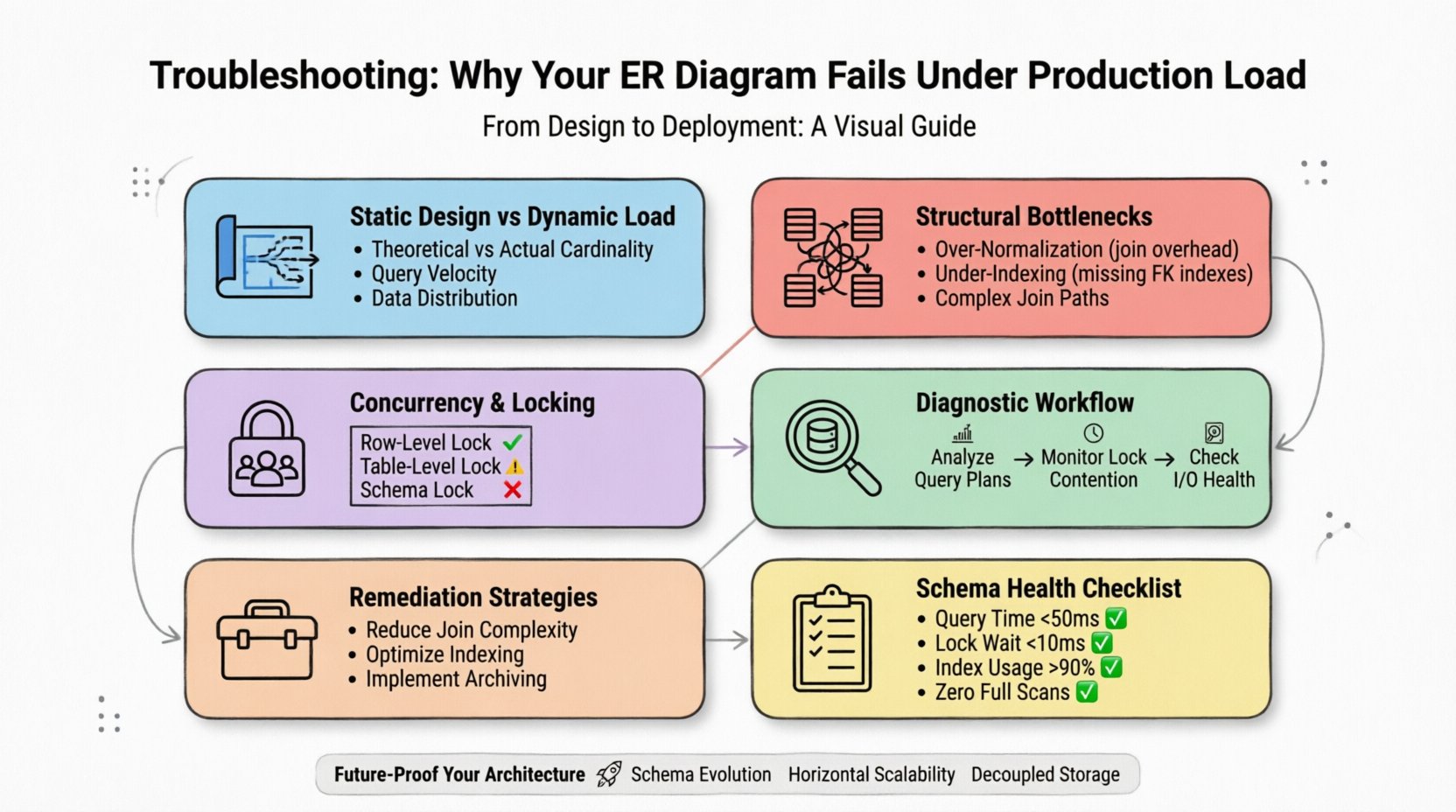
1. La brecha entre el diseño estático y la carga dinámica ⚡
Un diagrama ER representa relaciones potenciales y tipos de datos. No tiene en cuenta la velocidad de escritura, la distribución de lecturas ni las restricciones de almacenamiento físico del motor subyacente. Un modelo que parece equilibrado en una pizarra a menudo oculta ineficiencias que solo se manifiestan cuando se consultan millones de filas simultáneamente.
- Cardinalidad teórica frente a cardinalidad real:Los diagramas asumen relaciones uno a uno o uno a muchos. En producción, estas a menudo se convierten en muchas a muchas con rutas de unión complejas que agotan los recursos de la CPU.
- Velocidad de consulta:Un esquema podría manejar unos pocos miles de lecturas por segundo, pero se atasca con miles por milisegundo debido a la granularidad de los bloqueos.
- Distribución de datos:Los puntos calientes ocurren cuando los datos no se distribuyen de forma uniforme entre los nodos de almacenamiento, lo que provoca un equilibrio de carga desigual.
Para diagnosticar de forma efectiva, debe dejar de tratar el esquema como un artefacto estático. Es un recurso dinámico que debe monitorearse tan de cerca como el propio servidor.
2. Cuellos de botella estructurales comunes 📉
La causa más frecuente de degradación del rendimiento es la propia estructura de las relaciones. Cómo se conectan las tablas determina cómo el motor recorre los datos. Las uniones complejas son el principal culpable de los tiempos lentos de ejecución de consultas.
2.1 Riesgos de sobre-normalización
Si bien la normalización reduce la redundancia, una normalización excesiva aumenta el número de uniones necesarias para recuperar un conjunto de datos único. En escenarios de alta carga, cada unión es un punto potencial de fallo.
- Sobrecarga de unión:Cada operación de unión requiere que la base de datos coincida filas de dos tablas. Si estas tablas son grandes y carecen de un índice adecuado, el motor realiza una escaneo completo de la tabla.
- Profundidad de la transacción:Los esquemas profundamente normalizados a menudo requieren transacciones de larga duración para recuperar datos relacionados, manteniendo bloqueos durante períodos prolongados.
- Eficiencia de la caché:Los datos normalizados están fragmentados en múltiples páginas, lo que reduce la eficacia de la caché del grupo de búferes.
2.2 Sub-indexación y rutas de acceso
Un ERD bien estructurado implica patrones de acceso. Si el diagrama no se alinea con la carga real de consultas, el motor de base de datos no puede encontrar el camino más rápido hacia los datos.
- Índices de claves foráneas:Las claves foráneas a menudo carecen de índices, lo que provoca caídas de rendimiento al eliminar o actualizar registros padres.
- Orden de claves compuestas:El orden de las columnas en un índice compuesto importa. Si las consultas filtran primero por la segunda columna, el índice podría ser ignorado.
- Índices selectivos faltantes:Sin índices en columnas de alta cardinalidad, el motor escanea tablas enteras para encontrar valores específicos.
3. Concurrencia y mecanismos de bloqueo 🔒
Cuando aumenta la carga, la concurrencia se convierte en la principal restricción. Varios usuarios que intentan modificar los mismos datos generan contención. Si el diseño del esquema no tiene en cuenta el grado de granularidad de los bloqueos, el sistema entra en un estado de interbloqueo o expira.
| Tipo de bloqueo | Impacto en la carga | Síntoma típico |
|---|---|---|
| Bloqueo a nivel de fila | Impacto mínimo, alta concurrencia | Baja latencia, alto rendimiento |
| Bloqueo a nivel de tabla | Alto impacto, bloquea a otros usuarios | Errores de tiempo de espera, consultas colgadas |
| Bloqueo de esquema | Bloquea todo el acceso durante las operaciones DDL | Interrupción general del sistema durante el mantenimiento |
3.1 Interbloqueos y condiciones de carrera
Los interbloqueos ocurren cuando dos transacciones esperan mutuamente a que se liberen los recursos. Esto suele deberse a órdenes de bloqueo inconsistentes en la lógica de la aplicación que interactúa con el esquema.
- Niveles de aislamiento de transacciones:Los niveles de aislamiento más altos (como Serializable) ofrecen seguridad, pero reducen significativamente la concurrencia.
- Escalada de bloqueos:Si una transacción bloquea demasiadas filas, el motor puede escalonar hasta un bloqueo de tabla, bloqueando todas las demás operaciones.
- Transacciones largas:Operaciones que mantienen bloqueos durante segundos en lugar de milisegundos generan cuellos de botella para toda la cola.
4. Volumen de datos y estrategias de particionamiento 📊
A medida que los datos crecen, las limitaciones físicas de la capa de almacenamiento se vuelven evidentes. Un esquema que funciona para 10.000 filas puede fallar catastróficamente con 100 millones de filas. El particionamiento es el método utilizado para dividir tablas grandes en piezas más pequeñas y manejables.
- Particionamiento vertical:Mover las columnas poco accesadas a una tabla separada reduce el tamaño de la tabla principal, mejorando las tasas de acierto en caché para los datos de uso frecuente.
- Particionamiento horizontal:Dividir las filas entre múltiples segmentos físicos (sharding) distribuye la carga entre múltiples nodos de almacenamiento.
- Particionamiento basado en el tiempo:Para datos transaccionales, el particionamiento por fecha permite al motor eliminar las particiones antiguas de inmediato sin bloquear toda la tabla.
5. Flujo de diagnóstico para fallas en producción 🔍
Cuando el sistema se ralentiza, necesitas un enfoque sistemático para identificar la causa raíz. La optimización aleatoria a menudo desperdicia recursos. Sigue este flujo de trabajo para localizar el problema.
5.1 Analizar planes de ejecución de consultas
El plan de ejecución revela cómo el motor de base de datos pretende recuperar los datos. Busca indicadores específicos de ineficiencia.
- Escaneos completos de tabla:Indica una indexación faltante o una consulta que solicita demasiados datos.
- Búsquedas de claves:Sugiere que el motor debe saltar repetidamente entre el índice y los datos de la tabla, aumentando la entrada/salida.
- Operaciones de ordenación:Ordenar conjuntos de resultados grandes consume memoria y CPU significativos.
5.2 Monitorear la contención de bloqueos
Utiliza herramientas del sistema para monitorear eventos de espera. Tiempos de espera elevados en bloqueos indican que el esquema no puede soportar el nivel actual de concurrencia.
- Métricas de tiempo de espera:Registra la duración durante la cual las transacciones esperan recursos.
- Gráficos de interbloqueos:Revisa datos históricos para ver qué consultas causaron conflictos.
- Cola de espera de bloqueos:Monitorea el número de transacciones que esperan el mismo recurso.
5.3 Verificar la salud del subsistema de E/S
Incluso con un esquema perfecto, un almacenamiento lento causará fallas. Asegúrate de que la infraestructura subyacente coincida con los patrones de acceso a datos.
- Límites de rendimiento:Verifica si el dispositivo de almacenamiento está saturado con operaciones de lectura/escritura.
- Picos de latencia:Tiempo de respuesta inconsistente desde la capa de almacenamiento suele indicar degradación del hardware.
- Eficiencia del grupo de búferes:Si la base de datos pasa más tiempo leyendo desde el disco que desde la memoria, el esquema o el volumen de datos es demasiado grande para la caché.
6. Estrategias de remediación para la optimización de esquemas 🛠️
Una vez identificado el cuello de botella, aplica cambios dirigidos. Refactorizar un esquema de producción requiere precaución para evitar pérdida de datos o tiempo de inactividad.
6.1 Reducir la complejidad de las uniones
Simplifica las relaciones que causan la mayor fricción. Esto a menudo implica desnormalizar áreas específicas del modelo.
- Vistas materializadas: Pre-calcule joins complejos y almacene el resultado en una tabla separada para una recuperación rápida.
- Columnas calculadas: Almacene datos derivados directamente en la tabla para evitar cálculos en el momento de la consulta.
- Enrutamiento de réplicas de lectura: Envíe consultas intensivas de lectura a una réplica que almacene una copia desnormalizada de los datos.
6.2 Optimización de la estrategia de índices
Los índices son la herramienta más efectiva para acelerar las búsquedas, pero tienen un costo en las operaciones de escritura.
- Índices filtrados: Cree índices solo en subconjuntos de datos que se consulten con frecuencia.
- Índices cubiertos: Incluya todas las columnas necesarias para una consulta en el índice para evitar acceder a la tabla principal.
- Mantenimiento de índices: Reconstruya o reorganice los índices con regularidad para evitar la fragmentación causada por actualizaciones frecuentes.
6.3 Implementación de eliminaciones suaves y archivado
Los datos activos son más rápidos de consultar que los datos históricos. Mover los datos antiguos fuera de la tabla principal mejora el rendimiento.
- Tablas de archivado: Mueva los registros antiguos que superen un umbral determinado a una capa de almacenamiento separada y más fría.
- Eliminaciones suaves: Marque los registros como eliminados sin eliminarlos, manteniendo la estructura de la tabla estable mientras oculta lógicamente los datos.
- Políticas de retención de datos: Automatice la eliminación de datos innecesarios para evitar un crecimiento descontrolado.
7. Lista de verificación de evaluación para la salud del esquema ✅
Antes de implementar cambios, verifique su modelo frente a estos criterios para asegurarse de que pueda soportar la carga de producción.
| Criterios | Condición de aprobación | Condición de rechazo |
|---|---|---|
| Tiempo promedio de consulta | < 50 ms | > 500 ms |
| Tiempo de espera de bloqueo | < 10 ms | > 100 ms |
| Uso de índices | > 90% | < 50% |
| Escaneos completos de tabla | Cero | Frecuente |
Auditar regularmente tu modelo de datos frente a estas métricas garantiza que el diseño evolucione junto a las necesidades de tu negocio. Un esquema estático terminará convirtiéndose en una carga. La supervisión continua y los ajustes incrementales son la única forma de mantener la confiabilidad.
8. Comprender los patrones de consulta y las cargas de trabajo 📈
El rendimiento no se trata solo del esquema; se trata de cómo se utiliza ese esquema. Comprender el perfil de carga de trabajo es esencial para ajustar el modelo.
- OLTP frente a OLAP:El procesamiento en línea de transacciones (OLTP) requiere escrituras rápidas y pequeñas. El procesamiento analítico en línea (OLAP) requiere lecturas rápidas y grandes. Un esquema optimizado para uno suele tener dificultades con el otro.
- Patrones de escritura intensiva: Si tu aplicación escribe con frecuencia, prioriza la eficiencia de los índices y minimiza el bloqueo durante las escrituras.
- Patrones de lectura intensiva: Si tu aplicación lee con frecuencia, prioriza las estrategias de caché y réplicas de lectura.
9. El papel de la lógica de la aplicación en el rendimiento de la base de datos 💻
A menudo, el problema no está en la base de datos, sino en cómo la aplicación interactúa con ella. Los problemas de consultas N+1 son un ejemplo clásico de ineficiencia a nivel de aplicación que se manifiesta como fallo de la base de datos.
- Operaciones por lotes: Enviar miles de declaraciones de inserción individuales es más lento que una sola operación por lotes.
- Carga diferida: Recuperar datos en pequeños trozos puede generar un número excesivo de idas y vueltas a la base de datos.
- Aprovechamiento de conexiones: Una gestión ineficiente de las conexiones de base de datos puede agotar los recursos disponibles durante las cargas máximas.
Optimizar la capa de aplicación reduce la presión sobre el esquema, permitiendo que la base de datos funcione dentro de sus parámetros diseñados.
10. Proteger tu arquitectura de datos para el futuro 🚀
Diseñar para el futuro requiere anticipar el crecimiento. Aunque no puedes predecir números exactos de tráfico, puedes diseñar para la elasticidad.
- Evolución del esquema:Utilice estrategias de migración que permitan cambios no disruptivos en el modelo de datos.
- Escalabilidad horizontal:Diseñe las tablas para que soporten el particionamiento desde el principio.
- Almacenamiento desacoplado:Separe la capa de almacenamiento de la capa de computación para escalarlas de forma independiente.
Al adherirse a estos principios, construye una base que resiste las presiones de producción. El objetivo no es solo solucionar problemas actuales, sino crear un sistema resistente capaz de adaptarse a desafíos futuros.
11. Resumen de los pasos clave de diagnóstico 📝
Para recapitular, diagnosticar fallas de carga en producción implica un enfoque de múltiples capas.
- Revise el diagrama ER:Verifique relaciones excesivamente complejas y índices faltantes.
- Analice las consultas:Busque escaneos completos de tablas y rutas de unión ineficientes.
- Monitoree los bloqueos:Identifique puntos de contención que causan tiempos de espera.
- Verifique el hardware:Asegúrese de que el almacenamiento y la memoria no sean cuellos de botella.
- Optimice el esquema:Aplicar estrategias de particionamiento e indexación.
- Reestructure la aplicación:Reduzca el número de llamadas a la base de datos y optimice el manejo de transacciones.
Seguir este enfoque estructurado garantiza que aborde la causa raíz en lugar de los síntomas. La optimización de rendimiento es un proceso iterativo que requiere paciencia y precisión.
12. Reflexiones finales sobre la resiliencia del esquema 🧠
Un modelo de datos robusto es la columna vertebral de cualquier aplicación de alto rendimiento. Requiere atención constante y una disposición para adaptarse a medida que cambian los patrones de tráfico. Al comprender los matices de las relaciones, el indexado y la concurrencia, puede prevenir los problemas comunes que conducen a fallas en producción.
Recuerde que el diagrama es una herramienta, no el sistema. La verdadera prueba de su diseño ocurre en el entorno en vivo. Mantenga su monitoreo ajustado, sus índices limpios y sus transacciones cortas. Con estas prácticas establecidas, su arquitectura de datos servirá como una base confiable para el crecimiento de su negocio.
Permanezca alerta. Monitoree sus métricas. Refactore cuando sea necesario. Su sistema le lo agradecerá.

