











Gdy architektura bazy danych zaprojektowana na papierze działa bez zarzutu w środowisku testowym, ale zawala się pod wpływem rzeczywistego ruchu, rozłączenie często tkwi między modelem wizualnym a rzeczywistością działania. Diagram relacji encji (ERD) to projekt, a nie działający silnik. Jednak gdy deweloperzy mówią o „awarii ERD pod obciążeniem”, zazwyczaj opisują projekt schematu pochodzący z tego diagramu, który nie jest w stanie wytrzymać wymagań środowisk produkcyjnych. Niniejszy przewodnik omawia przyczyny strukturalne, logiczne i wydajnościowe, które powodują, że modele relacyjne mają trudności, gdy objętość danych i stopień współbieżności rosną.
Diagnozowanie tych problemów wymaga głębokiego zrozumienia, jak relacje danych przekładają się na operacje wejścia/wyjścia, zawieszenie blokad i zużycie pamięci. Przeanalizujemy punkty zderzenia, w których wybory projektowe kolidują z ograniczeniami sprzętowymi i wzorcami ruchu. Identyfikując konkretne objawy awarii strukturalnej, możesz przepisać swój model danych, aby wspierał skalowanie bez naruszania integralności danych.
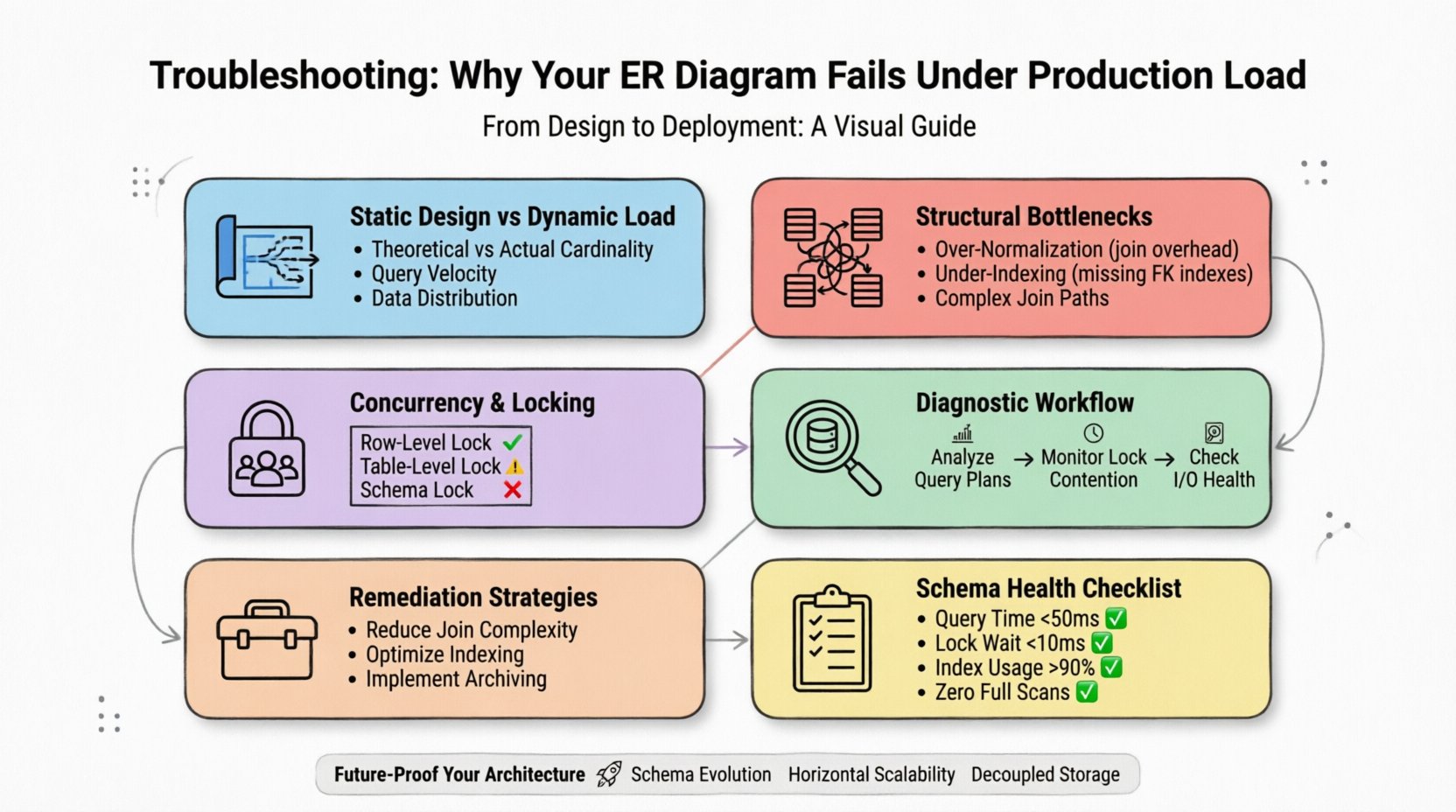
1. Przepaść między statycznym projektem a dynamicznym obciążeniem ⚡
Diagram ER przedstawia potencjalne relacje i typy danych. Nie uwzględnia prędkości zapisu, rozkładu odczytów ani ograniczeń fizycznych pamięci masowej silnika. Model, który wydaje się zrównoważony na tablicy, często ukrywa nieefektywności, które ujawniają się dopiero wtedy, gdy miliony wierszy są jednocześnie przeszukiwane.
- Teoretyczna vs. rzeczywista liczba elementów:Diagramy zakładają relacje jeden do jednego lub jeden do wielu. W środowisku produkcyjnym często stają się relacjami wiele do wielu z złożonymi ścieżkami łączenia, które wyczerpują zasoby procesora.
- Prędkość zapytań:Schemat może obsługiwać kilka tysięcy odczytów na sekundę, ale zawiesza się przy tysiącach na milisekundę z powodu szczegółowości blokad.
- Rozkład danych:Punkty przeciążenia pojawiają się, gdy dane nie są równomiernie rozłożone między węzłami przechowywania, co prowadzi do nierównomiernego rozkładu obciążenia.
Aby skutecznie diagnozować problemy, musisz przestać traktować schemat jako statyczny artefakt. To zasób dynamiczny, który należy monitorować tak dokładnie, jak sam serwer.
2. Powszechne przeszkody strukturalne 📉
Najczęstszą przyczyną degradacji wydajności jest struktura relacji samodzielnie. Sposób, w jaki tabele są ze sobą połączone, decyduje o tym, jak silnik przeszukuje dane. Złożone łączenia są główną przyczyną powolnego wykonania zapytań.
2.1 Ryzyko nadmiernego normalizowania
Choć normalizacja zmniejsza nadmiarowość, nadmierna normalizacja zwiększa liczbę łączeń wymaganych do pobrania pojedynczego zestawu danych. W warunkach wysokiego obciążenia każde łączenie może być potencjalnym punktem awarii.
- Nadmiar łączeń: Każda operacja łączenia wymaga od bazy danych dopasowania wierszy z dwóch tabel. Jeśli te tabele są duże i nie mają odpowiednich indeksów, silnik wykonuje pełne skanowanie tabeli.
- Głębokość transakcji:Głęboko znormalizowane schematy często wymagają długotrwałych transakcji do pobrania powiązanych danych, utrzymując blokady przez długie okresy.
- Efektywność pamięci podręcznej:Dane znormalizowane są rozdzielone na wielu stronach, co zmniejsza skuteczność buforowania w puli buforów.
2.2 Niedostateczne indeksowanie i ścieżki dostępu
Dobrze zbudowany diagram ERD sugeruje wzorce dostępu. Jeśli diagram nie odpowiada rzeczywistemu obciążeniu zapytań, silnik bazy danych nie może znaleźć najszybszej drogi do danych.
- Indeksy kluczy obcych:Klucze obce często nie mają indeksów, co powoduje spadki wydajności podczas usuwania lub aktualizacji rekordów nadrzędnych.
- Kolejność kluczy złożonych:Kolejność kolumn w indeksie złożonym ma znaczenie. Jeśli zapytania filtrowane są najpierw po drugiej kolumnie, indeks może zostać zignorowany.
- Brak wybiórczych indeksów:Bez indeksów na kolumnach o wysokiej liczbie unikalnych wartości silnik przeszukuje całe tabele, aby znaleźć konkretne wartości.
3. Współbieżność i mechanizmy blokowania 🔒
Gdy obciążenie rośnie, współbieżność staje się głównym ograniczeniem. Wiele użytkowników próbujących zmodyfikować te same dane powoduje zawieszenie. Jeśli projekt schematu nie uwzględnia szczegółowości blokowania, system może dojść do zakleszczenia lub przekroczenia czasu oczekiwania.
| Typ blokady | Wpływ na obciążenie | Typowy objaw |
|---|---|---|
| Blokada poziomu wiersza | Minimalny wpływ, wysoka współbieżność | Niskie opóźnienie, wysoka przepustowość |
| Blokada poziomu tabeli | Duży wpływ, blokuje innych użytkowników | Błędy przekroczenia czasu, zawieszone zapytania |
| Blokada schematu | Blokada dostępu dla wszystkich podczas DDL | Wycieczka całego systemu podczas konserwacji |
3.1 Zakleszczenia i warunki wyścigu
Zakleszczenia występują, gdy dwie transakcje czekają na zwolnienie zasobów przez siebie nawzajem. Zazwyczaj powoduje to niezgodność kolejności blokowania w logice aplikacji interagującej ze schematem.
- Poziomy izolacji transakcji: Wyższe poziomy izolacji (np. Serializable) zapewniają bezpieczeństwo, ale znacznie zmniejszają współbieżność.
- Zwiększanie poziomu blokady: Jeśli transakcja blokuje zbyt wiele wierszy, silnik może zwiększyć poziom blokady do tabeli, blokując wszystkie inne operacje.
- Długie transakcje: Operacje, które trzymają blokady przez sekundy zamiast milisekund, tworzą węzły zatyczki dla całej kolejki.
4. Objętość danych i strategie partycjonowania 📊
Wraz ze wzrostem danych, fizyczne ograniczenia warstwy przechowywania stają się widoczne. Schemat działający dla 10 000 wierszy może katastrofalnie zawieść przy 100 milionach wierszy. Partycjonowanie to metoda dzielenia dużych tabel na mniejsze, łatwiejsze w zarządzaniu fragmenty.
- Partycjonowanie pionowe: Przeniesienie rzadko używanych kolumn do osobnej tabeli zmniejsza rozmiar głównej tabeli, poprawiając współczynnik trafień w pamięci podręcznej dla danych ciepłych.
- Partycjonowanie poziome: Podział wierszy na wiele fizycznych segmentów (sharding) rozdziela obciążenie na wiele węzłów przechowywania.
- Partycjonowanie oparte na czasie: Dla danych transakcyjnych partycjonowanie według daty pozwala silnikowi natychmiastowo usunąć stare partycje bez blokowania całej tabeli.
5. Przepływ diagnostyczny dla awarii produkcyjnych 🔍
Gdy system spowalnia, potrzebujesz systematycznego podejścia do identyfikacji przyczyny głównej. Losowa optymalizacja często marnuje zasoby. Postępuj zgodnie z tym przepływem, aby dokładnie zlokalizować problem.
5.1 Analiza planów wykonania zapytań
Plan wykonania ujawnia, jak silnik bazy danych zamierza pobrać dane. Szukaj konkretnych wskazówek nieefektywności.
- Pełne skany tabeli:Wskazuje na brakujący indeks lub zapytanie, które żąda zbyt dużo danych.
- Wyszukiwania kluczy:Wskazuje, że silnik musi wielokrotnie przechodzić między indeksem a danymi tabeli, co zwiększa I/O.
- Operacje sortowania:Sortowanie dużych zestawów wyników zużywa znaczne zasoby pamięci i procesora.
5.2 Monitorowanie zawieszeń blokad
Użyj narzędzi systemowych do monitorowania zdarzeń oczekiwania. Długie czasy oczekiwania na blokady wskazują, że schemat nie może wspierać obecnego poziomu współbieżności.
- Metryki czasu oczekiwania:Śledź czas, przez który transakcje oczekują na zasoby.
- Wykresy zakleszczeń:Przejrzyj dane historyczne, aby zobaczyć, które zapytania spowodowały konflikty.
- Kolejka oczekiwania na blokadę:Monitoruj liczbę transakcji oczekujących na ten sam zasób.
5.3 Sprawdź stan podsystemu I/O
Nawet przy idealnym schemacie powolne magazynowanie spowoduje awarie. Upewnij się, że podstawowa infrastruktura odpowiada wzorców dostępu do danych.
- Ograniczenia przepustowości:Sprawdź, czy urządzenie magazynowania jest przeciążone operacjami odczytu/zapisu.
- Piky opóźnień:Niespójne czasy odpowiedzi z warstwy magazynowania często wskazują na degradację sprzętu.
- Efektywność puli buforów:Jeśli baza danych spędza więcej czasu na odczytywaniu z dysku niż z pamięci, schemat lub objętość danych jest zbyt duża dla pamięci podręcznej.
6. Strategie naprawcze dla optymalizacji schematu 🛠️
Gdy zlokalizowano wąski garb, wprowadź skierowane zmiany. Refaktoryzacja schematu produkcyjnego wymaga ostrożności, aby uniknąć utraty danych lub przestojów.
6.1 Zmniejszanie złożoności połączeń
Uprość relacje, które powodują największe trudności. Często oznacza to zredukowanie normalizacji w konkretnych obszarach modelu.
- Wykonywane widoki: Wstępnie oblicz złożone połączenia i zapisz wynik w oddzielnej tabeli dla szybkiego pobrania.
- Kolumny obliczane: Przechowuj dane pochodne bezpośrednio w tabeli, aby uniknąć obliczeń w czasie zapytania.
- Routing do replik odczytu: Przesyłaj zapytania odczytowe do repliki, która przechowuje skonwertowaną kopię danych.
6.2 Optymalizacja strategii indeksowania
Indeksy są najskuteczniejszym narzędziem przyspieszającym wyszukiwanie, ale mają koszt dla operacji zapisu.
- Indeksy filtrowane: Twórz indeksy tylko na podzbiorach danych, które są często zapytane.
- Indeksy pokrywające: Dołącz wszystkie kolumny potrzebne do zapytania do indeksu, aby uniknąć dostępu do głównej tabeli.
- Utrzymanie indeksów: Regularnie odbudowuj lub przekształcaj indeksy, aby zapobiec fragmentacji spowodowanej częstymi aktualizacjami.
6.3 Wdrażanie miękkich usuwań i archiwizacji
Dane aktywne są szybsze do zapytania niż dane historyczne. Przenoszenie starych danych poza główną tabelę poprawia wydajność.
- Tabele archiwalne: Przenieś rekordy starsze niż określony próg do osobnej, chłodniejszej warstwy przechowywania.
- Miękkie usuwanie: Oznacz rekordy jako usunięte bez ich usuwania, utrzymując stabilność struktury tabeli, jednocześnie logicznie ukrywając dane.
- Zasady przechowywania danych: Automatyzuj czyszczenie niepotrzebnych danych, aby zapobiec niekontrolowanemu wzrostowi.
7. Lista kontrolna oceny zdrowia schematu ✅
Zanim wdrożysz zmiany, sprawdź swój model pod kątem tych kryteriów, aby upewnić się, że wytrzyma obciążenie produkcyjne.
| Kryteria | Warunek sukcesu | Warunek porażki |
|---|---|---|
| Średni czas zapytania | < 50 ms | > 500 ms |
| Czas oczekiwania na blokadę | < 10ms | > 100ms |
| Wykorzystanie indeksów | > 90% | < 50% |
| Pełne skany tabeli | Zero | Częste |
Regularne audyty modelu danych pod kątem tych metryk zapewniają, że projekt ewoluuje wraz z potrzebami Twojej firmy. Statyczna struktura danych w końcu stanie się obciążeniem. Jedynym sposobem na utrzymanie niezawodności jest ciągła kontrola i stopniowe dostosowania.
8. Zrozumienie wzorców zapytań i obciążeń 📈
Wydajność nie dotyczy tylko schematu; dotyczy sposobu jego wykorzystania. Zrozumienie profilu obciążenia jest kluczowe do dopasowania modelu.
- OLTP vs. OLAP: Przetwarzanie transakcji online (OLTP) wymaga szybkich, małych zapisów. Przetwarzanie analityczne online (OLAP) wymaga szybkich, dużych odczytów. Schemat zoptymalizowany pod jedno często ma problemy z drugim.
- Wzorce z dużym obciążeniem zapisu: Jeśli Twoja aplikacja często zapisuje dane, skup się na wydajności indeksów i minimalizuj blokady podczas zapisu.
- Wzorce z dużym obciążeniem odczytu: Jeśli Twoja aplikacja często odczytuje dane, skup się na strategiach buforowania i replikach odczytowych.
9. Rola logiki aplikacji w wydajności bazy danych 💻
Często winą nie jest baza danych, lecz sposób, w jaki aplikacja z nią współpracuje. Problemy zapytań N+1 to klasyczny przykład nieefektywności na poziomie aplikacji, która objawia się awarią bazy danych.
- Operacje zbiorowe: Wysyłanie tysięcy pojedynczych zapytań INSERT jest wolniejsze niż jedna operacja zbiorowa.
- Ładowanie leniwe: Pobieranie danych małymi porcjami może powodować nadmiarowe przejścia do bazy danych.
- Pule połączeń: Nieefektywne zarządzanie połączeniami z bazą danych może wyczerpać dostępne zasoby podczas szczytowego obciążenia.
Optymalizacja warstwy aplikacji zmniejsza obciążenie schematu, pozwalając bazie danych działać w zdefiniowanych parametrach.
10. Przyszłościowe zaprojektowanie architektury danych 🚀
Projektowanie przyszłości wymaga przewidywania wzrostu. Choć nie możesz przewidzieć dokładnych liczb ruchu, możesz zaprojektować elastyczność.
- Ewolucja schematu: Używaj strategii migracji, które pozwalają na nieprzerwane zmiany w modelu danych.
- Skalowalność pozioma: Projektuj tabele w taki sposób, aby wspierały shardowanie od samego początku.
- Odrębna pamięć masowa: Oddziel warstwę przechowywania od warstwy obliczeniowej, aby mogły być skalowane niezależnie.
Przestrzegając tych zasad, budujesz fundament, który wytrzymuje napięcia środowiska produkcyjnego. Celem nie jest tylko naprawa obecnych problemów, ale stworzenie wytrzymałe systemu zdolnego do adaptacji do przyszłych wyzwań.
11. Podsumowanie kluczowych kroków diagnostycznych 📝
Podsumowując, diagnozowanie awarii obciążenia produkcyjnego wymaga podejścia wielowarstwowego.
- Przejrzyj ERD: Sprawdź zbyt skomplikowane relacje oraz brakujące indeksy.
- Analizuj zapytania: Szukaj pełnych skanowań tabel oraz nieefektywnych ścieżek łączenia.
- Monitoruj blokady: Zidentyfikuj punkty zawieszenia powodujące timeouty.
- Sprawdź sprzęt: Upewnij się, że pamięć masowa i pamięć operacyjna nie są węzłami kluczowymi.
- Optymalizuj schemat: Zastosuj strategie partycjonowania i indeksowania.
- Przepisz aplikację: Zmniejsz liczbę wywołań do bazy danych i optymalizuj obsługę transakcji.
Śledzenie tego strukturalnego podejścia zapewnia, że rozwiążesz przyczynę, a nie tylko objawy. Optymalizacja wydajności to proces iteracyjny wymagający cierpliwości i precyzji.
12. Ostateczne rozważania na temat odporności schematu 🧠
Solidny model danych to fundament każdej aplikacji o wysokiej wydajności. Wymaga on ciągłej uwagi oraz gotowości do dostosowania się do zmieniających się wzorców ruchu. Zrozumienie subtelności relacji, indeksowania i współbieżności pozwala uniknąć typowych pułapek prowadzących do awarii w środowisku produkcyjnym.
Pamiętaj, że schemat to narzędzie, a nie system. Prawdziwym testem Twojego projektu jest środowisko produkcyjne. Trzymaj monitorowanie ściśle, indeksy czyste, a transakcje krótkie. Dzięki tym praktykom architektura danych będzie stanowiła wiarygodny fundament dla rozwoju Twojego biznesu.
Bądź na baczności. Monitoruj swoje metryki. Przepisz kod, gdy będzie to konieczne. Twój system Ci podziękuje.

