











Cuando las organizaciones pasan de arquitecturas monolíticas a microservicios, el enfoque para el modelado de datos a menudo se convierte en un punto de gran controversia. Durante décadas, el Diagrama Entidad-Relación (ERD) sirvió como plano maestro para el diseño de bases de datos en sistemas centralizados. Representaba con precisión tablas, columnas, claves y relaciones. Sin embargo, la naturaleza distribuida de los microservicios pone a prueba estas convenciones tradicionales. La suposición de que un único esquema unificado se aplica en todo el sistema es un error persistente que puede provocar acoplamiento fuerte y fragilidad operativa.
Esta guía examina las creencias comunes sobre los diagramas ER en entornos distribuidos. Separa la realidad de la ficción, centrándose en cómo deben definirse los límites de los datos, cómo se gestionan las relaciones sin tablas compartidas y por qué la representación visual de los datos debe cambiar al pasar a una arquitectura orientada a servicios. El objetivo es proporcionar una comprensión clara de los principios de modelado de datos que respaldan la escalabilidad y la resiliencia.
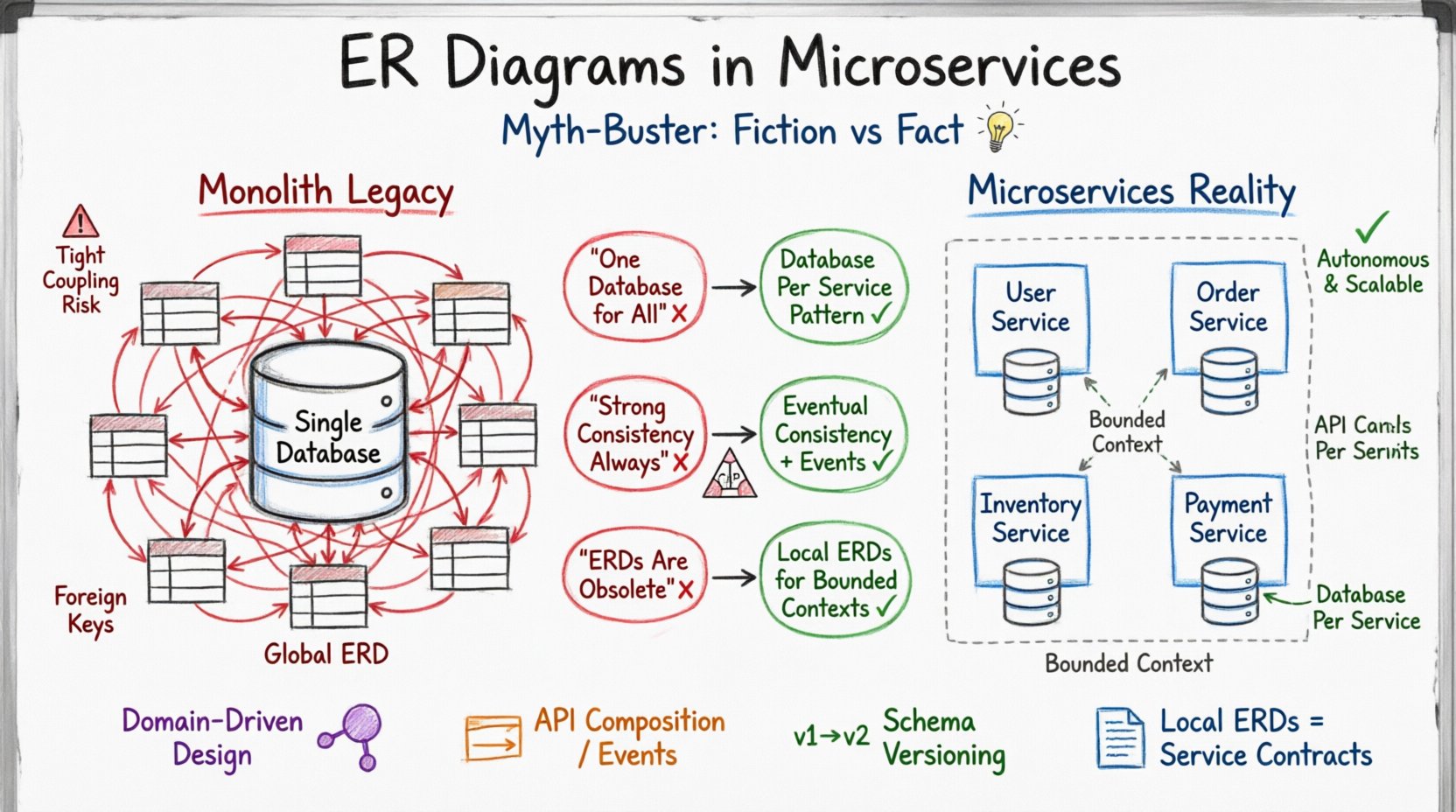
El legado del monolito: Por qué los viejos ERD no encajan 🏛️
En una aplicación monolítica tradicional, la base de datos actúa como la fuente central de verdad. Toda la lógica de la aplicación interactúa con un único esquema. Este entorno favorece un diagrama ER completo que representa cada entidad y relación. Los diseñadores pueden confiar en las claves foráneas para garantizar la integridad referencial en todo el sistema. Las transacciones abarcan múltiples tablas dentro de la misma instancia de base de datos, asegurando que se mantengan las propiedades ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad) a nivel global.
Cuando esta mentalidad se aplica a los microservicios, surge fricción. Los microservicios están diseñados para ser autónomos. Cada servicio gestiona su propia capa de persistencia de datos. Esto significa que no hay una base de datos compartida entre servicios. Si un servicio posee sus datos, otro servicio no puede consultarlos directamente usando uniones SQL estándar. Por lo tanto, el ERD debe pasar de ser un mapa a nivel del sistema a convertirse en una colección de esquemas específicos del dominio.
- Control centralizado: Los monolitos permiten a un DBA gestionar todo el esquema.
- Propiedad distribuida: Los microservicios requieren que cada equipo posea la definición de su esquema.
- Transacciones globales: Los monolitos permiten actualizaciones en una sola transacción a través de tablas.
- Transacciones distribuidas: Los microservicios requieren patrones de coordinación como Sagas o consistencia eventual.
El primer paso para modernizar el modelado de datos es aceptar que ya no es factible ni deseable un único ERD que abarque toda la aplicación. En su lugar, el enfoque se desplaza hacia el diseño centrado en el dominio, donde el modelo de datos se alinea con las capacidades empresariales de cada servicio.
Mito 1: La falacia de la “base de datos única” 🗄️❌
Una creencia común entre arquitectos nuevos en sistemas distribuidos es que pueden mantener una única base de datos física mientras separan lógicamente los datos usando prefijos de esquema o tablas distintas. Este enfoque a menudo se conoce como el patrón anti de “base de datos compartida”. Aunque parece simplificar el diseño inicial, introduce riesgos significativos a medida que el sistema crece.
Por qué fracasan las bases de datos compartidas
Aunque los servicios no compartan código, compartir una instancia de base de datos crea un acoplamiento físico. Si un servicio requiere una migración de esquema que afecta el rendimiento o la disponibilidad, todos los demás servicios que comparten esa base de datos se ven afectados. Esto viola el principio fundamental de independencia en los microservicios.
- Bloqueo de despliegue: Una migración arriesgada para el Servicio A podría impedir que el Servicio B se despliegue.
- Contención de recursos: Las consultas pesadas de un servicio pueden degradar el rendimiento de otros.
- Riesgos de seguridad: Un servicio comprometido podría acceder potencialmente a datos pertenecientes a otro servicio.
- Bloqueo tecnológico: Si el Servicio A necesita un motor de base de datos diferente al del Servicio B, no pueden coexistir en un entorno compartido.
La solución es el patrón de base de datos por servicio. Cada servicio provisióna su propia base de datos. Esto garantiza que los cambios de esquema estén aislados. El diagrama ER para el Servicio A solo debe reflejar las entidades de datos requeridas por el Servicio A, no el sistema global.
Mito 2: La consistencia fuerte siempre es necesaria ⚖️
En un entorno monolítico, el cumplimiento ACID es la norma. Los desarrolladores esperan que una vez que una transacción se confirma, los datos sean inmediatamente consistentes en todo el sistema. En los microservicios, esta expectativa a menudo es irreales. El teorema CAP establece que un sistema distribuido solo puede garantizar dos de las tres propiedades: Consistencia, Disponibilidad y Tolerancia a particiones.
Comprensión de la consistencia distribuida
Cuando los servicios se comunican a través de una red, la latencia y las fallas potenciales son inevitables. Intentar imponer una consistencia fuerte a través de los límites de los servicios a menudo conduce a alta latencia o inaccesibilidad del sistema. En cambio, muchas arquitecturas adoptan la consistencia eventual. Esto significa que los datos pueden estar temporalmente inconsistentes entre servicios, pero convergerán con el tiempo.
- Consistencia fuerte: Los datos se actualizan en todos lados de inmediato. Bueno para bancos, pero con alta latencia.
- Consistencia eventual: Los datos se propagan de forma asíncrona. Bueno para perfiles de usuarios, conteos de inventario.
- Disponibilidad básica: El sistema permanece operativo incluso durante particiones de red.
El diagrama ER en un microservicio no representa típicamente relaciones que requieran bloqueos inmediatos. En cambio, representa el estado de los datos que son localmente consistentes. Las relaciones entre servicios se gestionan mediante eventos o llamadas a API, no mediante claves foráneas de base de datos.
Mitología 3: Los diagramas ER son obsoletos en sistemas distribuidos 📉
Algunos profesionales argumentan que, debido a que los microservicios desacoplan los datos, el concepto de un ERD ya no es necesario. Esto es incorrecto. Aunque un ERD global es obsoleto, los ERD locales son más críticos que nunca. Sin una documentación clara de la estructura de datos dentro de un servicio, el riesgo de desviación de datos y errores de integración aumenta significativamente.
El papel del ERD local
Un ERD en el contexto de un microservicio cumple una función diferente que en un monolito. Define el contexto acotado. Asegura que el servicio conozca exactamente qué datos posee y cómo están estructurados internamente. No necesita mostrar relaciones con servicios externos.
- Documentación: Actúa como un contrato para el modelo de datos interno.
- Comunicación: Ayuda a los desarrolladores a comprender las entidades del dominio sin necesidad de conocer dependencias externas.
- Mantenimiento: Facilita la incorporación de nuevos miembros del equipo al servicio específico.
- Validación: Ayuda a identificar dependencias circulares durante la fase de diseño.
El diagrama debe centrarse en entidades, atributos y claves primarias. Las claves foráneas que hacen referencia a servicios externos deben eliminarse o abstraerse como identificadores, no como enlaces directos a tablas.
Mejores prácticas para el modelado de datos en microservicios 🛠️
Para construir un sistema robusto, los equipos deben adoptar estrategias específicas de modelado que se alineen con los principios de arquitectura distribuida. Estas prácticas aseguran que los servicios permanezcan independientes, pero aún cooperen para ofrecer una experiencia coherente al usuario.
1. Diseño centrado en el dominio (DDD)
Alinear el esquema de la base de datos con el modelo de dominio es esencial. Cada servicio debe representar una capacidad empresarial específica. Por ejemplo, un «Servicio de Usuario» no debería almacenar detalles de pedidos. Un «Servicio de Pedido» no debería almacenar tokens de autenticación de usuarios. Esta separación asegura que el ERD refleje la lógica del negocio y no la conveniencia técnica.
- Defina agregados según los límites transaccionales.
- Mantenga el ERD centrado en la responsabilidad del servicio.
- Evite crear modelos que abarquen múltiples dominios empresariales.
2. Manejo de relaciones a través de límites
Cuando el servicio A necesita datos propiedad del servicio B, no debería consultar directamente la base de datos del servicio B. En cambio, debería utilizar uno de los siguientes patrones:
- Composición de API:El servicio A llama a la API del servicio B para recuperar los datos necesarios.
- Replicación eventual:El servicio A mantiene una copia de los datos necesarios en su propia base de datos, actualizada mediante eventos.
- Unión mediante modelo de lectura:Un servicio dedicado de lectura agrega datos de múltiples fuentes para optimizar las consultas.
3. Versionado de esquemas
En un sistema distribuido, los servicios evolucionan a velocidades diferentes. Un cambio en el esquema de un servicio no debería romper al consumidor de ese servicio. Implementar el versionado de esquemas permite la compatibilidad hacia atrás.
- Utilice puntos finales con versiones para los contratos de API.
- Permita que múltiples versiones de un esquema de datos coexistan durante la migración.
- Deprecie las versiones antiguas de esquemas de forma gradual en lugar de obligar actualizaciones inmediatas.
Comparación: Arquitectura de datos monolítica frente a microservicios 📊
Para aclarar las diferencias, la siguiente tabla describe las principales diferencias entre el modelado de datos en arquitecturas centralizadas frente a distribuidas.
| Característica | Arquitectura monolítica | Arquitectura de microservicios |
|---|---|---|
| Almacenamiento de datos | Instancia única de base de datos | Base de datos por servicio |
| Alcance del diagrama ER | Vista global del sistema | Vista específica del servicio |
| Relaciones | Claves foráneas (uniones SQL) | Llamadas a API o eventos |
| Modelo de consistencia | Consistencia fuerte (ACID) | Consistencia eventual (BASE) |
| Despliegue | Despliegue monolítico | Despliegue independiente del servicio |
| Cambios en el esquema | Migración centralizada | Propiedad del equipo del servicio |
| Consulta | SQL directo | Modelos de lectura / CQRS |
Gestión de relaciones de datos a través de límites 🔗
Uno de los aspectos más difíciles de los microservicios es gestionar las relaciones de datos. En un monolito, una clave foránea garantiza que un pedido pertenezca a un usuario. En los microservicios, la tabla «Usuario» reside en el servicio de Usuario, y la tabla «Pedido» reside en el servicio de Pedidos. El servicio de Pedidos no puede tener una clave foránea hacia la base de datos del servicio de Usuario.
Patrones de integridad referencial
Para mantener la integridad referencial sin tablas compartidas, los equipos pueden utilizar patrones específicos:
- Referencias lógicas:Almacene el ID de usuario como cadena o número, pero valide su existencia mediante una llamada a la API durante la creación.
- Disparadores de base de datos:No recomendado entre servicios, pero válido dentro de un servicio.
- Eventos de validación:El servicio de Usuario publica un evento «Usuario creado». El servicio de Pedidos consume este evento para reconocer la relación.
El problema de los joins
Los joins a través de límites de servicios son un cuello de botella de rendimiento. Introducen latencia de red y puntos potenciales de fallo. Si el servicio de Usuario está caído, el servicio de Pedidos no puede recuperar los detalles del pedido si depende de un join. En su lugar, el servicio de Pedidos debería almacenar de forma redundante los detalles necesarios del usuario (como el nombre) en el momento de la creación del pedido. Esta es una compensación entre normalización y disponibilidad.
Evolution y versionado de esquemas 🔄
La evolución del esquema es inevitable. A medida que cambian los requisitos del negocio, las estructuras de datos deben adaptarse. En un entorno de microservicios, cambiar un esquema es más complejo porque múltiples servicios pueden depender de la estructura de datos de otro.
Estrategias para la evolución
- Cambios aditivos:Agregar una nueva columna generalmente es seguro si la aplicación maneja de forma adecuada los campos faltantes.
- Eliminación de campos:Esto requiere un período de desuso en el que el campo se oculta pero sigue presente, para luego eliminarse más adelante.
- Cambios de tipo:Cambiar un tipo de datos (por ejemplo, String a Integer) requiere una estrategia coordinada de migración.
El uso de un registro de esquemas puede ayudar a gestionar estos cambios. Actúa como una fuente central de verdad para la estructura de los datos intercambiados entre servicios, asegurando que productores y consumidores estén de acuerdo con el formato.
Errores comunes a evitar 🚧
Aunque se tenga una comprensión sólida de los principios, los equipos a menudo caen en trampas durante la implementación. Identificar estos errores temprano puede ahorrar una deuda técnica significativa.
- Sobrenormalización: Intentar mantener una única fuente de verdad en todos los servicios conduce a transacciones distribuidas complejas. Acepte la redundancia cuando sea necesario.
- Ignorar la idempotencia:Las llamadas de red pueden fallar o reintentarse. Las operaciones de datos deben diseñarse para manejar solicitudes duplicadas sin crear duplicados.
- Sobrecarga de coreografía:Depender únicamente de eventos para la consistencia de datos puede volverse inmanejable. Utilice la orquestación para flujos de trabajo complejos.
- Subestimar la latencia:Recuperar datos entre servicios añade milisegundos a cada solicitud. Agrupe los datos localmente cuando sea posible.
- Falta de documentación:Sin diagramas ER claros para cada servicio, la integración se convierte en un juego de adivinanzas.
Reflexiones finales sobre la claridad arquitectónica 🧠
La transición de un modelo de datos monolítico a uno de microservicios requiere un cambio de mentalidad. No se trata únicamente de dividir una base de datos en piezas más pequeñas. Se trata de redefinir cómo se conceptualizan la propiedad de los datos y sus relaciones. El diagrama ER sigue siendo una herramienta fundamental, pero su alcance se reduce al límite del servicio.
Al evitar los mitos de las bases de datos compartidas y la consistencia global, los arquitectos pueden construir sistemas resilientes y escalables. La clave está en priorizar la autonomía del servicio sobre la normalización de datos. Esto significa aceptar que algunos datos se duplicarán para garantizar que los servicios puedan funcionar de forma independiente. Significa comprender que la consistencia fuerte es un lujo, no una necesidad, para cada operación.
Al diseñar la arquitectura de datos, enfóquese en el dominio. Deje que las capacidades del negocio determinen los límites. Utilice diagramas ER para aclarar el estado interno de cada servicio. Utilice eventos y APIs para gestionar las conexiones entre ellos. Este enfoque garantiza que el sistema pueda evolucionar sin romper la integridad de los datos subyacentes.
En última instancia, el objetivo no es replicar el monolito en una forma distribuida. Es crear un sistema en el que los datos se gestionen con la misma flexibilidad y velocidad que el código que los procesa. Este equilibrio es la base de una estrategia de microservicios exitosa.

