











Quando as organizações passam de arquiteturas monolíticas para microserviços, a abordagem para modelagem de dados frequentemente se torna um ponto de grande controvérsia. Durante décadas, o Diagrama Entidade-Relacionamento (ERD) serviu como o plano mestre para o design de bancos de dados em sistemas centralizados. Ele mapeava tabelas, colunas, chaves e relacionamentos com precisão. No entanto, a natureza distribuída dos microserviços desafia essas convenções tradicionais. A suposição de que um único esquema unificado se aplica a todo o sistema é um equívoco persistente que pode levar a acoplamento rígido e fragilidade operacional.
Este guia examina as crenças comuns sobre diagramas ER em ambientes distribuídos. Ele separa o fato da ficção, focando em como os limites de dados devem ser definidos, como os relacionamentos são geridos sem tabelas compartilhadas e por que a representação visual dos dados precisa mudar ao passar para uma arquitetura orientada a serviços. O objetivo é fornecer uma compreensão clara dos princípios de modelagem de dados que sustentam escalabilidade e resiliência.
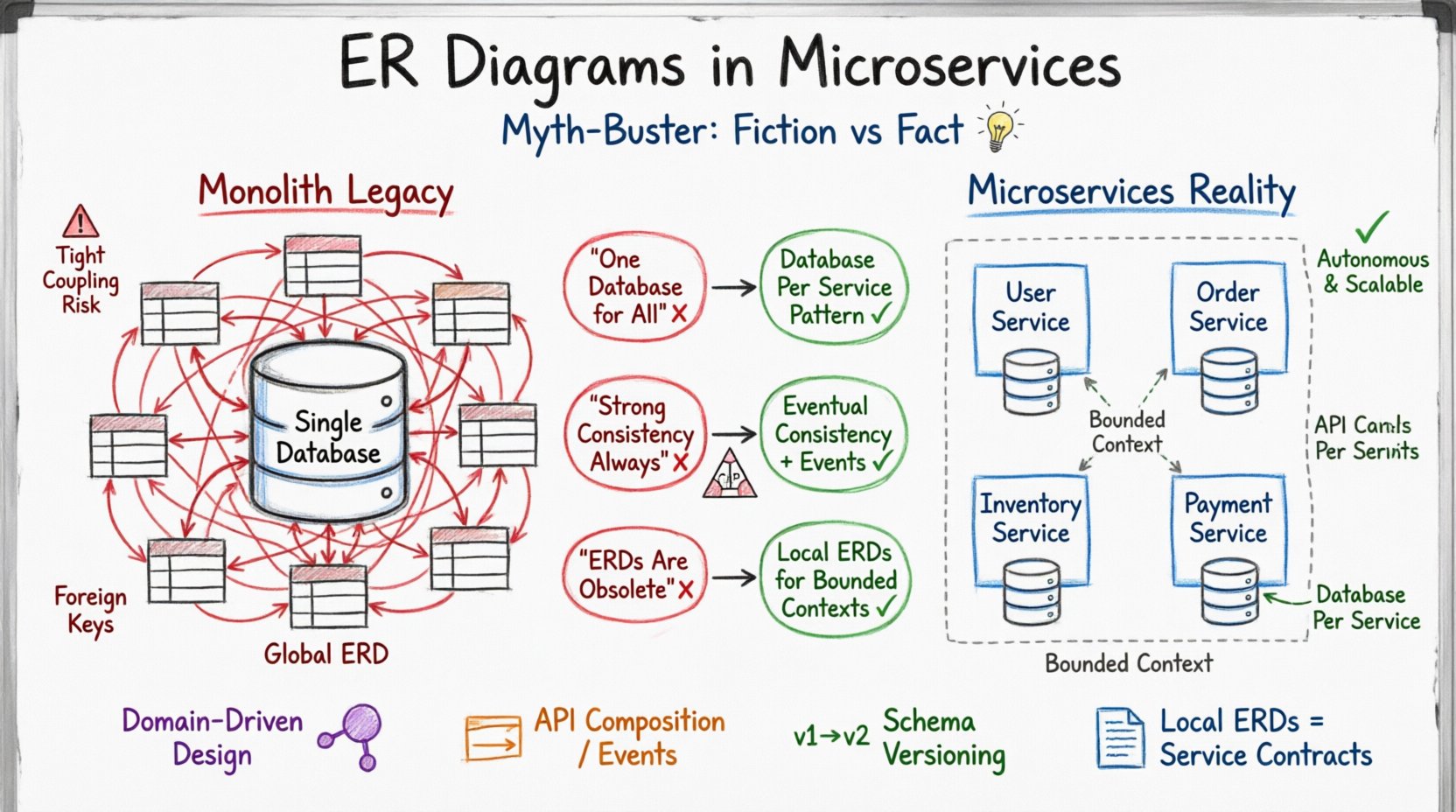
O Legado do Monólito: Por que os Antigos ERDs Não Servem Mais 🏛️
Em uma aplicação monolítica tradicional, o banco de dados atua como a fonte central de verdade. Todas as lógicas da aplicação interagem com um único esquema. Esse ambiente favorece um diagrama ER abrangente que mapeia cada entidade e relacionamento. Os designers podem confiar em chaves estrangeiras para garantir a integridade referencial em toda a extensão do sistema. As transações abrangem múltiplas tabelas dentro da mesma instância de banco de dados, garantindo que as propriedades ACID (Atomicidade, Consistência, Isolamento, Durabilidade) sejam mantidas globalmente.
Quando essa mentalidade é aplicada aos microserviços, surgem atritos. Os microserviços são projetados para serem autônomos. Cada serviço gerencia sua própria camada de persistência de dados. Isso significa que não há banco de dados compartilhado entre os serviços. Se um serviço possui seus dados, outro serviço não pode consultar diretamente usando junções SQL padrão. O ERD, portanto, deve mudar de um mapa de todo o sistema para uma coleção de esquemas específicos do domínio.
- Controle Centralizado: Monólitos permitem que um DBA gerencie todo o esquema.
- Propriedade Distribuída: Microserviços exigem que cada equipe assuma a definição do seu esquema.
- Transações Globais: Monólitos suportam atualizações em uma única transação em múltiplas tabelas.
- Transações Distribuídas: Microserviços exigem padrões de coordenação como Sagas ou consistência eventual.
O primeiro passo para modernizar a modelagem de dados é aceitar que um único ERD que abranja toda a aplicação já não é viável nem desejável. Em vez disso, o foco passa para o design orientado a domínio, onde o modelo de dados alinha-se às capacidades de negócios de cada serviço.
Mito 1: A Falácia do “Um Banco de Dados” 🗄️❌
Uma crença comum entre arquitetos novos em sistemas distribuídos é que eles podem manter um único banco de dados físico enquanto separam logicamente os dados usando prefixos de esquema ou tabelas distintas. Esse método é frequentemente chamado de anti-padrão de “banco de dados compartilhado”. Embora pareça simplificar o design inicial, ele introduz riscos significativos à medida que o sistema cresce.
Por que os Bancos de Dados Compartilhados Falham
Mesmo que os serviços não compartilhem código, compartilhar uma instância de banco de dados cria um acoplamento físico. Se um serviço precisar de uma migração de esquema que afete desempenho ou disponibilidade, todos os outros serviços que compartilham esse banco de dados serão afetados. Isso viola o princípio fundamental de independência nos microserviços.
- Bloqueio na Implantação: Uma migração arriscada para o Serviço A pode impedir que o Serviço B seja implantado.
- Concorrência por Recursos: Consultas pesadas de um serviço podem degradar o desempenho dos outros.
- Riscos de Segurança: Um serviço comprometido poderia potencialmente acessar dados pertencentes a outro serviço.
- Travamento de Tecnologia: Se o Serviço A precisar de um motor de banco de dados diferente do Serviço B, eles não poderão coexistir em um ambiente compartilhado.
A solução é o padrão Banco de Dados por Serviço. Cada serviço provisiona seu próprio banco de dados. Isso garante que as mudanças no esquema sejam isoladas. O diagrama ER para o Serviço A deve refletir apenas as entidades de dados necessárias pelo Serviço A, e não o sistema global.
Mito 2: A Consistência Forte é Sempre Necessária ⚖️
Em um ambiente monolítico, a conformidade com ACID é o padrão. Os desenvolvedores esperam que, assim que uma transação for confirmada, os dados sejam imediatamente consistentes em toda a extensão do sistema. Nos microserviços, essa expectativa é frequentemente irreais. O teorema CAP determina que um sistema distribuído só pode garantir duas das três propriedades: Consistência, Disponibilidade e Tolerância a Partições.
Compreendendo a Consistência Distribuída
Quando os serviços se comunicam por meio de uma rede, a latência e falhas potenciais são inevitáveis. Tentar impor consistência forte entre os limites dos serviços frequentemente leva a alta latência ou indisponibilidade do sistema. Em vez disso, muitos sistemas adotam consistência eventual. Isso significa que os dados podem estar temporariamente inconsistentes entre os serviços, mas convergirão ao longo do tempo.
- Consistência Forte: Os dados são atualizados em todos os lugares imediatamente. Bom para bancos, mas com alta latência.
- Consistência Eventual: Os dados são propagados de forma assíncrona. Bom para perfis de usuários, contagens de estoque.
- Disponibilidade Base: O sistema permanece operacional mesmo durante partições de rede.
O diagrama ER em um microserviço não representa tipicamente relacionamentos que exigem bloqueio imediato. Em vez disso, representa o estado dos dados que são localmente consistentes. Relacionamentos entre serviços são tratados por meio de eventos ou chamadas de API, e não por chaves estrangeiras do banco de dados.
Mitologia 3: Diagramas ER são obsoletos em sistemas distribuídos 📉
Alguns profissionais argumentam que, como os microserviços desacoplam os dados, o conceito de um ERD já não é necessário. Isso está incorreto. Embora um ERD global seja obsoleto, os ERDs locais são mais críticos do que nunca. Sem uma documentação clara da estrutura de dados dentro de um serviço, o risco de desvio de dados e erros de integração aumenta significativamente.
O Papel do ERD Local
Um ERD no contexto de um microserviço serve a um propósito diferente do que em um monólito. Ele define o contexto delimitado. Garante que o serviço saiba exatamente quais dados ele possui e como esses dados são estruturados internamente. Não precisa mostrar relacionamentos com serviços externos.
- Documentação: Atua como um contrato para o modelo de dados interno.
- Comunicação: Ajuda os desenvolvedores a entenderem as entidades de domínio sem precisar conhecer dependências externas.
- Manutenção: Simplifica a integração de novos membros da equipe ao serviço específico.
- Validação: Ajuda a identificar dependências circulares na fase de design.
O diagrama deve se concentrar em entidades, atributos e chaves primárias. As chaves estrangeiras que referenciam serviços externos devem ser removidas ou abstraídas como identificadores, e não como links diretos para tabelas.
Melhores Práticas para Modelagem de Dados em Microserviços 🛠️
Para construir um sistema robusto, as equipes devem adotar estratégias específicas de modelagem que estejam alinhadas com os princípios de arquitetura distribuída. Essas práticas garantem que os serviços permaneçam independentes, mas ainda cooperem para fornecer uma experiência coerente para o usuário.
1. Design Orientado a Domínio (DDD)
Alinhar o esquema do banco de dados com o modelo de domínio é essencial. Cada serviço deve representar uma capacidade de negócios específica. Por exemplo, um ‘Serviço de Usuário’ não deve armazenar detalhes de pedidos. Um ‘Serviço de Pedidos’ não deve armazenar tokens de autenticação de usuário. Essa separação garante que o ERD reflita a lógica de negócios e não conveniências técnicas.
- Defina agregados com base em limites transacionais.
- Mantenha o ERD focado na responsabilidade do serviço.
- Evite criar modelos que abranjam múltiplos domínios de negócios.
2. Tratamento de Relacionamentos entre Fronteiras
Quando o Serviço A precisa de dados pertencentes ao Serviço B, ele não deveria consultar diretamente o banco de dados do Serviço B. Em vez disso, deveria usar um dos seguintes padrões:
- Composição de API:O Serviço A chama a API do Serviço B para recuperar os dados necessários.
- Replicação Eventual:O Serviço A mantém uma cópia dos dados necessários em seu próprio banco de dados, atualizada por meio de eventos.
- Junção por Modelo de Leitura:Um serviço dedicado de leitura agrega dados de várias fontes para otimização de consultas.
3. Versionamento de Esquema
Em um sistema distribuído, os serviços evoluem em velocidades diferentes. Uma alteração no esquema de um serviço não deveria quebrar o consumidor desse serviço. Implementar versionamento de esquema permite compatibilidade reversa.
- Use pontos finais com versão para contratos de API.
- Permita que várias versões de um esquema de dados coexistam durante a migração.
- Deprecie versões antigas de esquema gradualmente, em vez de forçar atualizações imediatas.
Comparação: Arquitetura de Dados Monolítica vs. Microserviços 📊
Para esclarecer as diferenças, a tabela a seguir apresenta as principais distinções entre modelagem de dados em arquiteturas centralizadas versus distribuídas.
| Funcionalidade | Arquitetura Monolítica | Arquitetura de Microserviços |
|---|---|---|
| Armazenamento de Dados | Instância Única de Banco de Dados | Banco de Dados por Serviço |
| Escopo do Diagrama ER | Visão Global do Sistema | Visão Específica do Serviço |
| Relacionamentos | Chaves Estrangeiras (Junções SQL) | Chamadas de API ou Eventos |
| Modelo de Consistência | Consistência Forte (ACID) | Consistência Eventual (BASE) |
| Implantação | Implantação Monolítica | Implantação Independente de Serviço |
| Alterações no Esquema | Migração Centralizada | Gerenciado pela Equipe do Serviço |
| Consulta | SQL Direto | Modelos de Leitura / CQRS |
Gerenciamento de Relacionamentos de Dados Entre Fronteiras 🔗
Uma das partes mais difíceis dos microserviços é gerenciar relacionamentos de dados. Em um monolito, uma chave estrangeira garante que um Pedido pertença a um Usuário. Nos microserviços, a tabela “Usuário” reside no Serviço de Usuário, e a tabela “Pedido” reside no Serviço de Pedido. O Serviço de Pedido não pode manter uma chave estrangeira para o banco de dados do Serviço de Usuário.
Padrões de Integridade Referencial
Para manter a integridade referencial sem tabelas compartilhadas, as equipes podem usar padrões específicos:
- Referências Lógicas: Armazene o ID do Usuário como uma string ou número, mas valide a existência por meio de chamada à API durante a criação.
- Gatilhos de Banco de Dados: Não recomendado entre serviços, mas válido dentro de um serviço.
- Eventos de Validação: O Serviço de Usuário publica um evento “Usuário Criado”. O Serviço de Pedido consome esse evento para reconhecer o relacionamento.
O Problema das Junções
As junções entre fronteiras de serviços são um gargalo de desempenho. Elas introduzem latência de rede e pontos potenciais de falha. Se o Serviço de Usuário estiver fora do ar, o Serviço de Pedido não poderá recuperar os detalhes do pedido se depender de uma junção. Em vez disso, o Serviço de Pedido deveria armazenar os detalhes necessários do usuário (como Nome) de forma redundante no momento da criação do pedido. Esse é um compromisso entre normalização e disponibilidade.
Evolução e Versão de Esquemas 🔄
A evolução de esquemas é inevitável. À medida que os requisitos de negócios mudam, as estruturas de dados devem se adaptar. Em um ambiente de microserviços, alterar um esquema é mais complexo porque múltiplos serviços podem depender da estrutura de dados de outro.
Estratégias para Evolução
- Alterações Aditivas: Adicionar uma nova coluna geralmente é seguro, desde que o aplicativo trate campos ausentes de forma adequada.
- Remoção de Campos: Isso exige um período de desativação em que o campo é oculto, mas ainda presente, e depois removido posteriormente.
- Alterações de Tipo: Alterar um tipo de dado (por exemplo, String para Integer) exige uma estratégia coordenada de migração.
Usar um registro de esquemas pode ajudar a gerenciar essas alterações. Ele atua como uma fonte central de verdade para a estrutura dos dados trocados entre serviços, garantindo que produtores e consumidores concordem com o formato.
Armadilhas Comuns para Evitar 🚧
Mesmo com uma compreensão sólida dos princípios, as equipes frequentemente caem em armadilhas durante a implementação. Identificar essas armadilhas cedo pode poupar uma dívida técnica significativa.
- Sobrenormalização:Tentar manter uma única fonte de verdade em todos os serviços leva a transações distribuídas complexas. Aceite a redundância quando necessário.
- Ignorar Idempotência:Chamadas de rede podem falhar ou ser repetidas. Operações de dados devem ser projetadas para lidar com solicitações duplicadas sem criar duplicatas.
- Sobrecarga de Coreografia:Depender exclusivamente de eventos para consistência de dados pode se tornar inviável. Use orquestração para fluxos de trabalho complexos.
- Subestimar a Latência:Buscar dados entre serviços adiciona milissegundos a cada solicitação. Agregue dados localmente sempre que possível.
- Falta de Documentação:Sem ERDs claros para cada serviço, a integração se torna um jogo de adivinhação.
Pensamentos Finais sobre Clareza Arquitetônica 🧠
A transição de modelagem de dados monolítica para microserviços exige uma mudança de mentalidade. Não se trata apenas de dividir um banco de dados em partes menores. Trata-se de redefinir como a propriedade de dados e as relações são concebidas. O diagrama ER permanece uma ferramenta essencial, mas seu escopo se reduz à fronteira do serviço.
Ao evitar os mitos de bancos de dados compartilhados e consistência global, arquitetos podem construir sistemas resilientes e escaláveis. A chave está em priorizar a autonomia do serviço sobre a normalização de dados. Isso significa aceitar que alguns dados serão duplicados para garantir que os serviços possam funcionar de forma independente. Significa entender que a consistência forte é um luxo, e não uma exigência, para cada operação.
Ao projetar a arquitetura de dados, foque no domínio. Deixe que as capacidades de negócios definam os limites. Use ERDs para esclarecer o estado interno de cada serviço. Use eventos e APIs para gerenciar as conexões entre eles. Essa abordagem garante que o sistema possa evoluir sem comprometer a integridade de dados subjacente.
Em última análise, o objetivo não é replicar o monolito em uma forma distribuída. É criar um sistema onde os dados são gerenciados com a mesma flexibilidade e velocidade do código que os processa. Esse equilíbrio é a base de uma estratégia de microserviços bem-sucedida.

