











組織がモノリシックアーキテクチャからマイクロサービスへ移行する際、データモデリングのアプローチはしばしば大きな論争の的となる。数十年にわたり、エンティティ関係図(ERD)は中央集権型システムにおけるデータベース設計の設計図として機能してきた。テーブル、カラム、キー、関係を正確にマッピングしていた。しかし、マイクロサービスの分散性は、こうした伝統的な規範に挑戦する。システム全体に一貫したスキーマが適用されるという前提は、しばしば根強い誤解であり、強い結合性と運用上の脆弱性を招く可能性がある。
本書は、分散環境におけるER図に関する一般的な信念を検証する。事実とフィクションを明確に分けることで、データ境界の定義方法、共有テーブルなしでの関係の管理方法、およびサービス指向アーキテクチャに移行する際にデータの視覚的表現がなぜ変化する必要があるかに焦点を当てる。その目的は、スケーラビリティとレジリエンスを支えるデータモデリングの原則を明確に理解することにある。
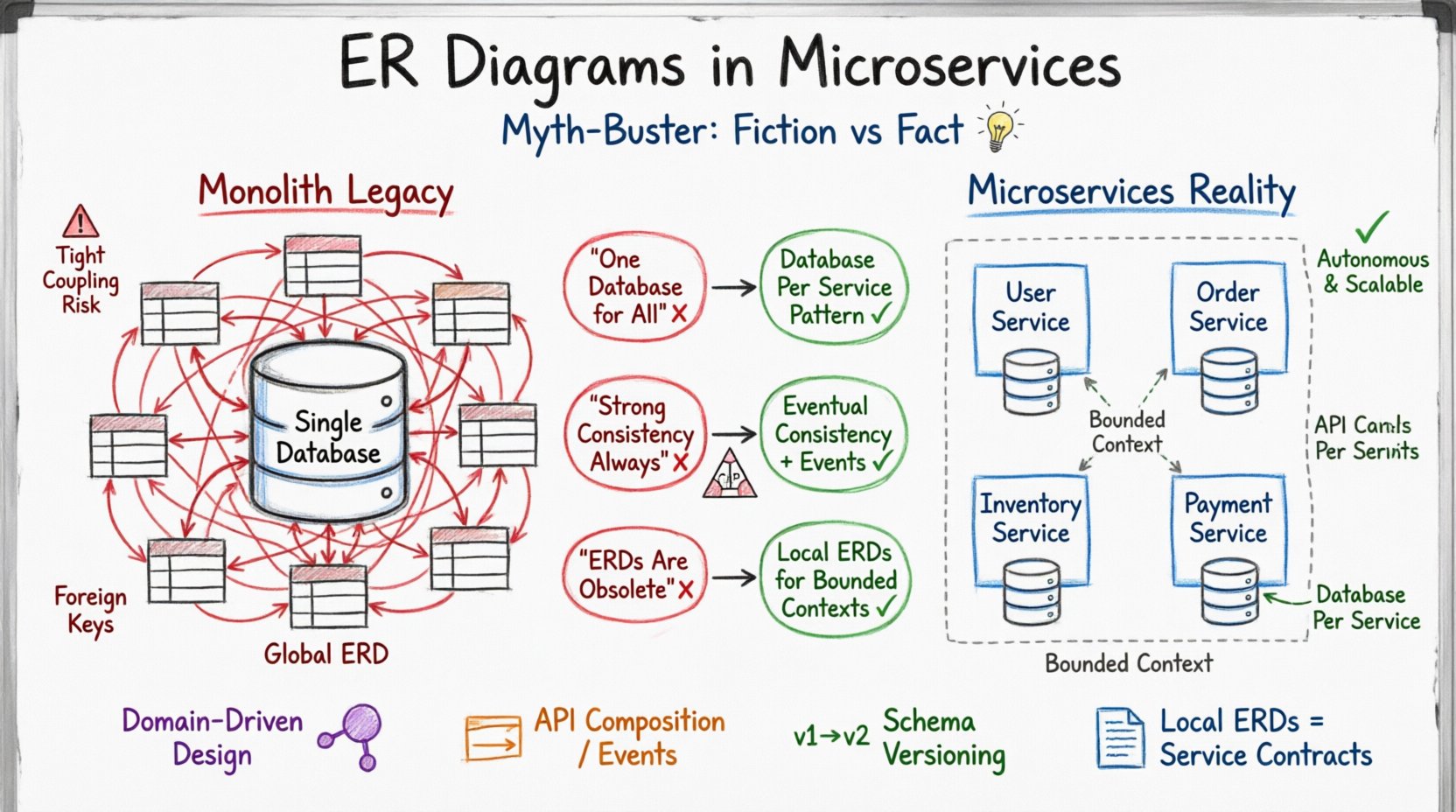
モノリスの遺産:なぜ古いER図は合わないのか 🏛️
従来のモノリシックアプリケーションでは、データベースが中央の真実の源となる。すべてのアプリケーションロジックが単一のスキーマとやり取りする。この環境では、すべてのエンティティと関係をマッピングする包括的なER図が好まれる。デザイナーは外部キーを頼りに、システム全体で参照整合性を維持できる。トランザクションは同じデータベースインスタンス内の複数のテーブルにまたがり、ACID特性(原子性、整合性、分離性、耐久性)がグローバルに保たれる。
この思考様式をマイクロサービスに適用すると、摩擦が生じる。マイクロサービスは自律性を目的として設計されている。各サービスは自らのデータ永続化レイヤーを管理する。つまり、サービス間でデータベースを共有しないということである。あるサービスがデータを所有しているならば、他のサービスは標準的なSQL結合を使って直接そのデータを照会できない。したがって、ER図はシステム全体を網羅する地図から、ドメイン固有のスキーマの集合へと変化しなければならない。
- 中央集権的管理: モノリスでは、DBAが全体のスキーマを管理できる。
- 分散型所有: マイクロサービスでは、各チームが自らのスキーマ定義を所有する必要がある。
- グローバルトランザクション: モノリスは、テーブル間で単一トランザクションによる更新をサポートする。
- 分散トランザクション: マイクロサービスでは、Sagasや最終的整合性といった調整パターンが必要となる。
データモデリングを近代化する第一歩は、アプリケーション全体をカバーする単一のER図がもはや実現不可能であり、望ましくないことを受け入れることである。代わりに、ドメイン駆動設計に注目が移り、データモデルが各サービスのビジネス機能と一致するようになる。
神話1:「1つのデータベース」の誤謬 🗄️❌
分散システムに初めて取り組むアーキテクトの間で一般的な誤解は、物理的に1つのデータベースを維持しつつ、スキーマプレフィックスや別々のテーブルを使って論理的にデータを分離できるということである。このアプローチはしばしば「共有データベース」のアンチパターンと呼ばれる。初期設計を単純化しているように見えるが、システムが成長するにつれて重大なリスクをもたらす。
なぜ共有データベースは失敗するのか
サービス間でコードを共有しなくても、データベースインスタンスを共有することは物理的な結合を生じる。あるサービスがパフォーマンスや可用性に影響を与えるスキーマ移行を必要とする場合、そのデータベースを共有する他のすべてのサービスが影響を受ける。これはマイクロサービスにおける独立性の核心原則に反する。
- デプロイブロッキング: サービスAのリスクの高い移行が、サービスBのデプロイを妨げる可能性がある。
- リソース競合: あるサービスからの重いクエリが、他のサービスのパフォーマンスを低下させる。
- セキュリティリスク: 1つのサービスが侵害されると、他のサービスのデータにアクセスできる可能性がある。
- 技術的ロックイン: サービスAがサービスBとは異なるデータベースエンジンを必要とする場合、共有環境では共存できない。
解決策は「サービスごとのデータベース」パターンである。各サービスが自らのデータベースを確保する。これにより、スキーマ変更が隔離される。サービスAのER図は、サービスAに必要なデータエンティティのみを反映すべきであり、グローバルシステムを反映すべきではない。
神話2:強整合性は常に必要とされる ⚖️
モノリシック環境では、ACID準拠が標準である。開発者は、トランザクションがコミットされると、データがシステム全体で即座に整合性を持つことを期待する。マイクロサービスでは、この期待はしばしば現実的ではない。CAP定理は、分散システムが3つの特性(整合性、可用性、パーティション耐性)のうち2つしか保証できないことを規定している。
分散型一貫性の理解
サービスがネットワークを介して通信する際、遅延や潜在的な障害は避けられない。サービス境界を越えて強い一貫性を強制しようとする試みは、しばしば高遅延やシステムの利用不能を引き起こす。代わりに、多くのシステムは最終的一貫性を採用する。これは、サービス間で一時的にデータが一貫性を欠く可能性があるが、時間とともに収束するということを意味する。
- 強一貫性: データはすべての場所で即座に更新される。銀行業務には適しているが、遅延が高くなる。
- 最終的一貫性: データは非同期的に伝播される。ユーザーのプロフィールや在庫数などに適している。
- 基本可用性: ネットワークのパーティションが発生しても、システムは運用可能である。
マイクロサービス内のER図は、即時ロックを必要とする関係を通常は表現しない。代わりに、ローカルに一貫性を持つデータの状態を表現する。サービス間の関係は、データベースの外部キーではなく、イベントやAPI呼び出しによって処理される。
ミス3:分散システムではER図は陳腐化している 📉
一部の実務家は、マイクロサービスがデータを分離するため、ERDの概念はもはや必要でないと主張する。これは誤りである。グローバルなERDは陳腐化しているが、ローカルなERDはかつてないほど重要である。サービス内のデータ構造について明確なドキュメントがなければ、データのずれや統合エラーのリスクが著しく高まる。
ローカルERDの役割
マイクロサービスの文脈におけるERDはモノリスの場合とは異なる目的を持つ。それは境界付きコンテキストを定義する。サービスが自らが所有するデータと、そのデータの内部構造を正確に把握できることを保証する。外部サービスとの関係を示す必要はない。
- ドキュメント化: インターナルデータモデルの契約として機能する。
- コミュニケーション: 外部依存関係を知らなくても、開発者がドメインエンティティを理解するのを助ける。
- メンテナンス: 新しいチームメンバーのオンボーディングを、特定のサービスに簡単にする。
- 検証: 設計段階で循環依存を特定するのを助ける。
図はエンティティ、属性、主キーに焦点を当てるべきである。外部サービスを参照する外部キーは削除するか、識別子として抽象化すべきであり、直接のテーブルリンクとしては扱わない。
マイクロサービスにおけるデータモデリングのベストプラクティス 🛠️
堅牢なシステムを構築するためには、分散アーキテクチャの原則と整合する特定のモデリング戦略を採用しなければならない。これらの実践により、サービスが独立性を保ちつつ、一貫したユーザー体験を提供するために協働できることが保証される。
1. ドメイン駆動設計(DDD)
データベーススキーマをドメインモデルと一致させることが不可欠である。各サービスは特定のビジネス機能を表すべきである。たとえば、「ユーザー・サービス」は注文の詳細を格納してはならない。また、「注文・サービス」はユーザーの認証トークンを格納してはならない。この分離により、ERDが技術的な便宜ではなく、ビジネス論理を反映するようになる。
- トランザクションの境界に基づいて集約を定義する。
- ERDをサービスの責任に集中させる。
- 複数のビジネスドメインにまたがるモデルを作成しない。
2. 境界を越えた関係の扱い
Service A が Service B が所有するデータを必要とする場合、直接 Service B のデータベースを照会してはならない。代わりに、以下のパターンのいずれかを使用すべきである。
- API コンポジション: Service A は必要なデータを取得するために Service B の API を呼び出す。
- 最終的レプリケーション: Service A は、イベントを介して更新される自身のデータベースに必要なデータのコピーを保持する。
- 読み取りモデルを介した結合:専用の読み取りサービスは、クエリ最適化のために複数のデータソースからデータを集約する。
3. スキーマバージョン管理
分散システムでは、サービスの進化速度が異なる。1つのサービスのスキーマの変更が、そのサービスの消費者を破壊してはならない。スキーマバージョン管理を実装することで、後方互換性を確保できる。
- API契約にはバージョン付きエンドポイントを使用する。
- 移行中に複数のバージョンのデータスキーマが共存することを許可する。
- 即時更新を強制するのではなく、古いスキーマバージョンを段階的に非推奨化する。
比較:モノリス vs. マイクロサービスデータアーキテクチャ 📊
違いを明確にするために、以下の表は、集中型アーキテクチャと分散型アーキテクチャにおけるデータモデリングの主な違いを概説している。
| 機能 | モノリスアーキテクチャ | マイクロサービスアーキテクチャ |
|---|---|---|
| データストレージ | 単一のデータベースインスタンス | サービスごとのデータベース |
| ER図の範囲 | グローバルシステムビュー | サービス固有のビュー |
| 関係性 | 外部キー(SQL結合) | API呼び出しまたはイベント |
| 整合性モデル | 強整合性(ACID) | 最終整合性(BASE) |
| デプロイメント | モノリシックなデプロイ | 独立したサービスのデプロイ |
| スキーマの変更 | 中央集権的な移行 | サービスチームが所有 |
| クエリ処理 | 直接的なSQL | 読み取りモデル / CQRS |
境界を越えたデータ関係の扱い 🔗
マイクロサービスの最も難しい点の一つは、データ関係を管理することです。モノリシックなシステムでは、外部キーが注文がユーザーに属していることを保証します。マイクロサービスでは、「User」テーブルはUserサービスに、「Order」テーブルはOrderサービスに存在します。OrderサービスはUserサービスのデータベースへの外部キーを保持できません。
参照整合性のパターン
共有テーブルを使わずに参照整合性を維持するため、チームは特定のパターンを使用できます:
- 論理的参照:ユーザーIDを文字列または数値として保存するが、作成時にAPI呼び出しで存在を検証する。
- データベーストリガー:サービス間では推奨されませんが、サービス内では有効です。
- 検証イベント:Userサービスが「ユーザー作成」イベントを発行する。Orderサービスはこのイベントを消費して関係を確認する。
結合の問題
サービス境界を越えた結合はパフォーマンスのボトルネックです。ネットワーク遅延や障害の潜在的な原因をもたらします。Userサービスがダウンしている場合、結合に依存しているとOrderサービスは注文の詳細を取得できません。代わりに、Orderサービスは注文作成時に必要なユーザー情報(名前など)を冗長に保存すべきです。これは正規化と可用性のトレードオフです。
スキーマの進化とバージョン管理 🔄
スキーマの進化は避けられないものです。ビジネス要件が変化するにつれて、データ構造も適応しなければなりません。マイクロサービス環境では、複数のサービスが他のサービスのデータ構造に依存しているため、スキーマを変更するのはより複雑です。
進化の戦略
- 追加的な変更:アプリケーションが欠損フィールドを適切に処理できる場合、新しい列を追加することは一般的に安全です。
- フィールドの削除:この変更には、フィールドを非表示にしながら存在させ、後に削除するための非推奨期間が必要です。
- 型の変更:データ型の変更(例:文字列から整数)には、調整された移行戦略が必要です。
スキーマレジストリを使用すると、これらの変更を管理しやすくなります。これは、サービス間でやり取りされるデータの構造に関する中央の真実の源として機能し、プロデューサーとコンシューマーがフォーマットについて合意していることを保証します。
避けるべき一般的な落とし穴 🚧
原則をしっかり理解していても、実装段階でチームはしばしば罠にはまる。これらの落とし穴を早期に特定することで、大きな技術的負債を回避できる。
- 過剰な正規化:すべてのサービス間で単一の真実の源を維持しようとするあまり、複雑な分散トランザクションが生じる。必要に応じて冗長性を受け入れよう。
- 冪等性を無視する:ネットワーク呼び出しは失敗したり再試行されたりする。データ操作は重複リクエストを処理しても重複データを作らないように設計されなければならない。
- 振る舞いの過剰依存:データの一貫性をイベントにのみ依存すると、管理が困難になる。複雑なワークフローにはオーケストレーションを活用しよう。
- 遅延を軽視する:サービス間でのデータ取得は、すべてのリクエストにミリ秒単位の遅延を追加する。可能な限りローカルでデータを集約しよう。
- ドキュメント不足:各サービスに明確なER図がなければ、統合は当てずっぽうのゲームになる。
アーキテクチャの明確さについての最終的な考察 🧠
モノリシックなアーキテクチャからマイクロサービスのデータモデリングへ移行するには、マインドセットの変化が必要である。データベースを小さな部分に分割するだけではない。データの所有権や関係性をどのように捉えるかを再定義することである。ER図は依然として重要なツールだが、その範囲はサービス境界に限定される。
共有データベースやグローバル一貫性の神話から離れることで、耐障害性とスケーラビリティに優れたシステムを構築できる。鍵は、データ正規化よりもサービスの自律性を優先することである。つまり、サービスが独立して動作できるように、一部のデータが重複することを受け入れることを意味する。また、強一貫性はすべての操作に必須というわけではなく、むしろ余裕であることを理解することを意味する。
データアーキテクチャを設計する際は、ドメインに注目しよう。ビジネス機能が境界を決定するようにしよう。各サービスの内部状態を明確にするためにER図を活用し、イベントとAPIを使ってそれらの間の接続を管理しよう。このアプローチにより、システムが進化しても基盤となるデータ整合性が損なわれることを防げる。
結局のところ、目的はモノリスを分散形態で再現することではない。データを処理するコードと同じ柔軟性とスピードで管理できるシステムを構築することである。このバランスこそが、成功するマイクロサービス戦略の基盤となる。

