










Każdy architekt danych stoi przed tym samym kluczowym momentem. Zaczynasz od czystego, znormalizowanego schematu. Baza danych bez problemu obsługuje tysiące rekordów. Zapytania zwracają wyniki w milisekundach. Diagram relacji encji (ERD) wygląda elegancko. Następnie firma rośnie. Użytkownicy zaczynają aktywnie korzystać z systemu. Objętość danych eksploduje. Nagle system zaczyna działać wolniej. Łączenia trwają sekundy. Blokady zatrzymują transakcje. Pierwotny projekt ERD staje się obciążeniem.
Ten przewodnik szczegółowo opisuje przejście od małej bazy danych do środowiska produkcyjnego o wysokim obciążeniu. Przeglądamy zmiany strukturalne wymagane do utrzymania wydajności bez poświęcania integralności danych. Nacisk położony jest na projektowanie logiczne, strategie indeksowania oraz techniki partycjonowania. Tutaj nie wymieniamy konkretnego oprogramowania dostawcy; zasady te dotyczą dowolnego silnika przechowywania danych relacyjnych.
🏗️ Podstawa: projektowanie z myślą o rozwoju
Kiedy aplikacja zaczyna się rozwijać, priorytetem jest szybkość rozwoju. ERD dokładnie odzwierciedla dziedzinę biznesową. Normalizacja jest wysoka. Trzecia postać normalna (3NF) często stanowi cel. Minimalizuje to nadmiarowość. Zapewnia spójność danych. Jednak ten podejście zakłada określony wzorzec obciążenia. Zakłada, że zapytania są proste. Zakłada, że zestaw danych mieści się wygodnie w pamięci.
W miarę rozrostu zestawu danych założenia przestają działać. Koszt łączeń rośnie logarytmicznie. Objętość danych przeszukiwanych przez procesor zapytań rośnie liniowo. Wejście/wyjście dysku staje się węzłem kluczowym. Architektura wymaga zmiany od czystości logicznej do wydajności fizycznej.
Określanie punktu przełomu
Zanim przeprowadzisz refaktoryzację, musisz zrozumieć, gdzie system się zawiesza. Przejście od tysięcy do milionów rekordów zmienia fizykę pobierania danych. Szukaj tych oznak:
- Opóźnienie zapytań:Zapytania, które zajmowały 5ms, teraz trwają 500ms.
- Kontestacja blokad:Transakcje czekają na zwolnienie blokad.
- Przepustowość zapisu:Wstawianie spowalnia się z powodu konserwacji indeksów.
- Napięcie pamięci:Pula buforów nie może buforować często dostępowanych tabel.
- Nasycenie sieci:Duże zestawy wyników zużywają przepustowość.
Kiedy te objawy pojawiają się, ERD musi się rozwijać. Nie możesz po prostu dodać więcej sprzętu. Musisz zoptymalizować strukturę.
🔍 Faza 1: Refaktoryzacja schematu
Pierwszym krokiem w skalowaniu jest audyt diagramu relacji encji. Musisz zweryfikować, czy obecna struktura wspiera wzorce zapytań wymagane na dużą skalę.
Normalizacja wobec denormalizacji
Normalizacja zmniejsza nadmiarowość danych. Uproszcza aktualizacje. Jednak wymusza łączenia. Łączenia są kosztowne w skali. Denormalizacja wprowadza nadmiarowość. Zmniejsza liczbę łączeń. Przyspiesza odczyty. To jest kompromis, który należy dokładnie zarządzać.
n
Rozważ następujące strategie:
- Obciążenia zdominowane odczytami:Denormalizuj często dostępowane atrybuty. Przechowuj je bezpośrednio w głównej tabeli, aby uniknąć łączeń.
- Obciążenia zdominowane zapisami:Utrzymuj normalizację. Unikaj kaskadowych aktualizacji w wielu tabelach.
- Podejście hybrydowe: Zachowaj znormalizowany schemat główny. Utwórz widoki materializowane lub tabele podsumowujące do raportowania.
W naszym przypadku badania, oryginalny projekt miał dziesięć tabel połączonych w celu pobrania jednego profilu użytkownika. Spowodowało to nadmierny I/O dysku. Poprzez zdenormalizowanie najczęściej używanych atrybutów użytkownika w głównej tabeli profilu, zmniejszyliśmy liczbę połączeń z dziesięciu do jednego.
Obsługa dużych pól tekstowych
Przechowywanie dużych ciągów (CLOB) w głównej tabeli może spowolnić odczyt stron. Silnik bazy danych musi załadować całą wiersz, aby sprawdzić klucz główny. Jeśli wiersz jest zbyt duży, może zostać wypchnięty na dysk.
Najlepsze praktyki obejmują:
- Rozdziel duże pola tekstowe na oddzielną tabelę powiązaną.
- Pobieraj pole tekstowe tylko wtedy, gdy jest jawnie żądane.
- Przechowuj odwołania (ID) zamiast treści w głównym indeksie.
📈 Faza 2: Strategie indeksowania
Indeksy są silnikiem wydajności zapytań. Dobrze zaprojektowany ERD opiera się na indeksach, aby szybko lokalizować dane. Wraz ze wzrostem liczby rekordów, rozmiar indeksu również rośnie. Utrzymanie indeksów zużywa zasoby zapisu.
Indeksy złożone
Indeksy jednokolumnowe są często niewystarczające. Indeksy złożone pozwalają silnikowi filtrować według wielu kryteriów jednocześnie. Kolejność kolumn w indeksie ma znaczenie. Najbardziej selektywna kolumna powinna być pierwsza.
Na przykład, jeśli filtrowanie odbywa się według status i datę, ale status ma niską selektywność (np. tylko trzy wartości), umieść datęna pierwszym miejscu. Pozwala to szybciej ograniczyć przestrzeń wyszukiwania.
Indeksy pokrywające
Indeks pokrywający zawiera wszystkie kolumny wymagane przez zapytanie. Baza danych może spełnić zapytanie używając wyłącznie indeksu. Nie musi dotykać danych tabeli (heap). To daje istotną wydajność.
- Uwzględnij wszystkie
SELECTkolumny. - Uwzględnij wszystkie
WHEREkolumny klauzuli WHERE. - Uwzględnij wszystkie
KOLEJNOŚĆ WYBUZUkolumny.
Utrzymanie indeksów
Indeksy nie są statyczne. Z czasem ulegają fragmentacji. Rosną wraz z danymi. Wymagane jest regularne utrzymanie.
- Przebudowa:Fragmentuje strukturę indeksu.
- Przeprowadzanie:Przeprowadza ponowne uporządkowanie stron liści bez pełnej przebudowy.
- Monitorowanie: Śledź nieużywane indeksy. Usuń je, aby zaoszczędzić miejsce na zapis.
🗄️ Faza 3: Partycjonowanie i rozmieszczanie danych
Gdy pojedyncza tabela przekracza pojemność jednego dysku lub puli pamięci, konieczne staje się partycjonowanie. Dzieli ono tabelę logiczną na mniejsze segmenty fizyczne.
Partycjonowanie zakresowe
Ten sposób dzieli dane na podstawie wartości zakresu. Często używany dla dat lub sekwencyjnych identyfikatorów. Na przykład dzielenie danych według roku.
- Zalety: Zapytania filtrowane według klucza partycji skanują tylko jeden segment.
- Wady: Zapytania bez klucza partycji skanują wszystkie segmenty (pełne skanowanie tabeli).
Partycjonowanie haszowe
Ten sposób równomiernie rozdziela dane między segmentami przy użyciu funkcji haszowej na kolumnie klucza. Zapobiega powstawaniu obszarów nadmiernego obciążenia.
- Zalety:Równomierne rozłożenie danych.
- Wady: Zapytania zakresowe stają się kosztowne.
Rozmieszczanie poziome vs. pionowe
Rozmieszczanie danych dalszy krok w stosunku do partycjonowania, polegający na rozprowadzaniu danych na wielu instancjach bazy danych.
| Strategia | Opis | Najlepsze zastosowanie |
|---|---|---|
| Rozmieszczanie poziome | Podziel wiersze między bazami danych na podstawie klucza. | Wysokie obciążenie zapisu, duże zbiory danych. |
| Pionowe shardowanie | Podziel kolumny między bazami danych na podstawie ich użycia. | Duże kolumny, różne wzorce odczytu. |
| Shardowanie katalogowe | Użyj tabeli wyszukiwania do kierowania zapytań. | Złożona logika routingu, dynamiczne skalowanie. |
W naszym przypadku badawczym zaimplementowaliśmy shardowanie poziome na podstawie identyfikatora użytkownika. Pozwoliło to nam rozłożyć obciążenie na pięciu węzłach. Każdy węzeł obsługiwał około 20% ruchu. To zmniejszyło obciążenie każdego pojedynczego silnika przechowywania danych.
🚀 Faza 4: Optymalizacja zapytań
Nawet przy idealnym schemacie złe zapytania zabijają wydajność. Optymalizator wybiera plan wykonania. Musisz go kierować.
Unikanie pełnych skanowań tabel
Zawsze upewnij się, że zapytanie używa indeksu. Jeśli skanuje całą tabelę, to przekroczy limit czasu przy dużych rozmiarach. Sprawdź plan wykonania. Szukaj „Skanowanie indeksu” lub „Poszukiwanie indeksu” zamiast „Skanowania tabeli”.
Ograniczanie zestawów wyników
Nigdy nie pobieraj wszystkich rekordów. Używaj stronicowania. Ogranicz liczbę wierszy zwracanych w jednym żądaniu.
- Limit przesunięcia: Standardne stronicowanie. Może być powolne przy głębokich przesunięciach.
- Stronicowanie oparte na kluczu: Użyj ostatnio widzianego identyfikatora, aby pobrać następną stronę. Znacznie szybsze.
Grupowanie operacji
Nie wykonuj milionów aktualizacji w jednym transakcji. Podziel je na partie.
- Zatwierdź po każdym 1 000 rekordach.
- To zmniejsza wzrost plików dziennika.
- To zapobiega długotrwałym blokadom.
⚠️ Najczęstsze pułapki do uniknięcia
Skalowanie wprowadza nowe ryzyka. Bądź świadom tych typowych błędów.
- Zbyt wiele indeksów: Zbyt wiele indeksów spowalnia zapisy. Monitoruj wydajność zapisu.
- Ignorowanie typów danych: Używanie
VARCHARdla stałych długości identyfikatorów marnuje przestrzeń. UżyjINTlubBIGINT. - Zapytania N+1: Pobieranie powiązanych danych w pętli. Użyj ładowania zgodnego lub grupowych połączeń.
- Miękkie usuwanie: Oznaczanie rekordów jako usunięte utrzymuje je w tabeli na zawsze. Archiwizuj stare dane.
- Blokowanie schematów: Zmiana struktury tabeli podczas działania systemu. Użyj zmian schematu online.
📊 Metryki wydajności do śledzenia
Nie możesz poprawić tego, czego nie mierzyłeś. Ustal podstawę. Monitoruj te metryki ciągle.
- Wierszy na sekundę: Jak szybko dane są zapisywane?
- Zapytań na sekundę: Jaki jest poziom ruchu odczytu?
- Stosunek trafień do pamięci podręcznej: Czy odczyty trafiają do pamięci czy dysku?
- Czas oczekiwania na blokadę: Czy transakcje czekają na zasoby?
- Wejście/wyjście dysku: Czy magazynowanie jest przepięte?
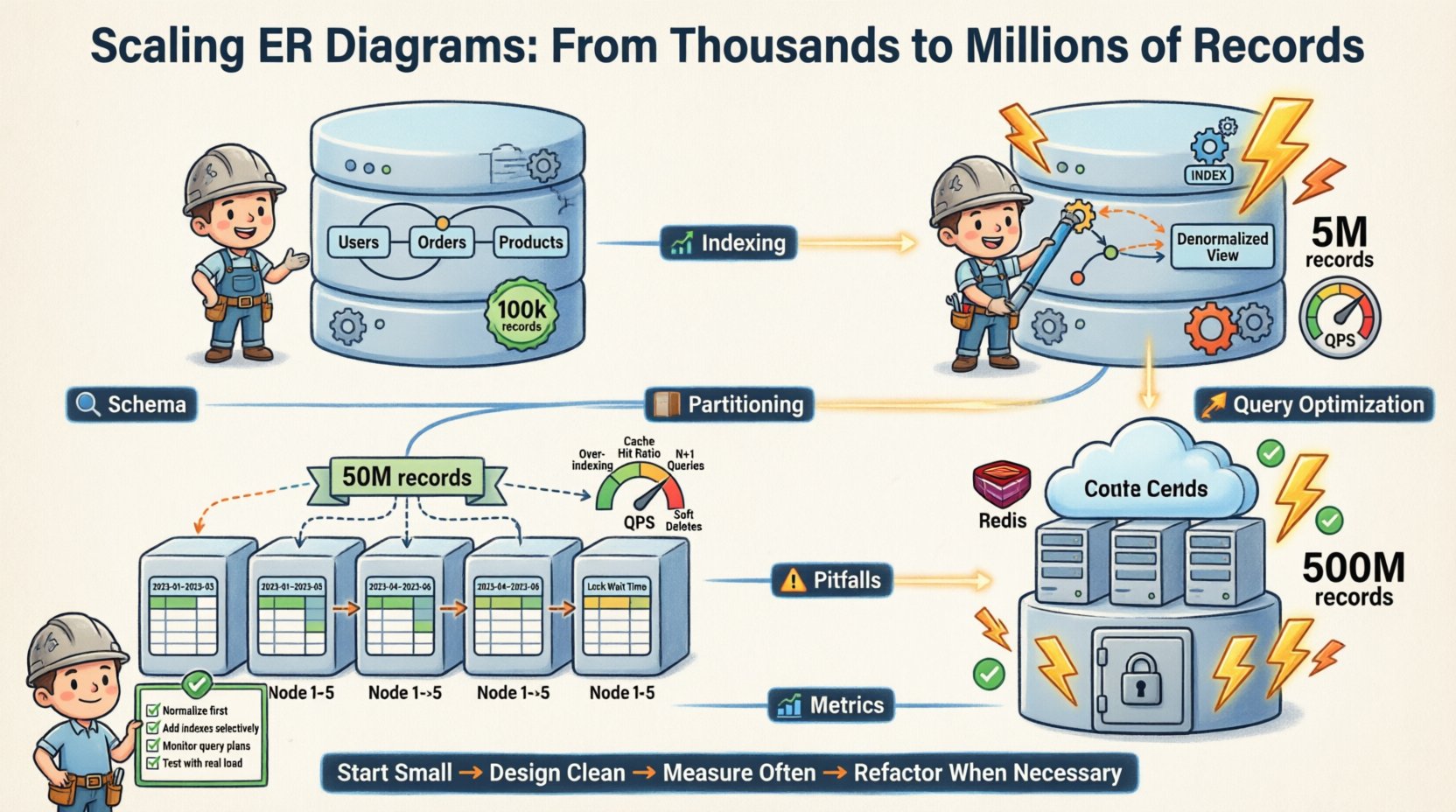
🔄 Ewolucja diagramu ER
Diagram relacji encji nie jest dokumentem statycznym. Jest to żywy projekt. Wraz ze skalowaniem systemu, diagram ER się zmienia.
Oto przebieg ewolucji naszej schematu:
- Faza 1 (Początek): Pełna normalizacja. 3NF. Jedna instancja bazy danych. 100 tys. rekordów.
- Faza 2 (Wzrost): Denormalizacja tabel o wysokim obciążeniu odczytu. Dodane indeksy. Jedno wystąpienie. 5M rekordów.
- Faza 3 (Skalowanie):Pionowe partycjonowanie. Podzielone według ID użytkownika. Wieloinstancyjne. 50M rekordów.
- Faza 4 (Dojrzałość):Archiwizacja danych z przeszłości. Integracja warstwy buforowania. Replikacje do odczytu. 500M rekordów.
Każda faza wymagała konkretnych zmian w modelu logicznym. Podstawowe relacje pozostały stabilne. Implementacja fizyczna została dostosowana.
🛠️ Lista kontrolna skalowania
Użyj tej listy kontrolnej przed wdrożeniem w środowisku o wysokim obciążeniu.
- ☐ Sprawdź, czy wszystkie klucze obce mają wspierające indeksy.
- ☐ Sprawdź, czy nie ma
SELECT *w kodzie aplikacji. - ☐ Upewnij się, że klucze partycjonowania są równomiernie rozłożone.
- ☐ Przetestuj scenariusze przejścia awaryjnego dla węzłów bazy danych.
- ☐ Przejrzyj ustawienia puli połączeń.
- ☐ Zaprojektuj archiwizację i czyszczenie danych.
- ☐ Wprowadź ostrzeżenia monitoringu dla wolnych zapytań.
- ☐ Dokumentuj procedury zmian schematu.
💡 Ostateczne rozważania na temat niezawodności
Skalowanie diagramu ER to nie tylko o prędkości. Chodzi o niezawodność. System, który jest szybki, ale zawiesza się pod obciążeniem, jest bezużyteczny. System, który jest wolny, ale stabilny, można zarządzać.
Cel polega na zaprojektowaniu struktury, która przewiduje wzrost. Musisz zrównoważyć koszt przechowywania z kosztem obliczeń. Musisz zrównoważyć spójność z dostępnością. To podstawowe kompromisy systemów rozproszonych.
Śledząc te zasady, możesz zapewnić, że architektura danych pozostanie odporna. Możesz przejść od tysięcy do milionów rekordów bez uszkodzenia. Kluczem jest przygotowanie. Kluczem jest testowanie. Kluczem jest zrozumienie podstawowych mechanizmów silnika przechowywania danych.
Zacznij mało. Projektuj czysto. Mierz często. Refaktoryzuj, gdy to konieczne. To droga do zrównoważonego skalowania.

