











El diseño de bases de datos es la columna vertebral de cualquier aplicación robusta. Al construir un diagrama de entidades y relaciones (ERD), dos fuerzas opuestas moldean el esquema: la normalización y la denormalización. Comprender cuándo aplicar cada estrategia determina la salud a largo plazo, el rendimiento y la mantenibilidad de su infraestructura de datos. Esta guía aborda las preguntas más críticas sobre estos conceptos, proporcionando una ruta clara para diseñar estructuras de bases de datos eficientes sin depender de herramientas de software específicas. 🛠️
La integridad de los datos y la velocidad de las consultas a menudo tiran en direcciones opuestas. La normalización prioriza la integridad al reducir la redundancia. La denormalización prioriza la velocidad al introducir redundancia controlada. Navegar entre este equilibrio requiere una comprensión profunda de la teoría relacional y de los requisitos prácticos de rendimiento. Exploraremos los detalles técnicos a través de una serie de preguntas y respuestas específicas. 📊
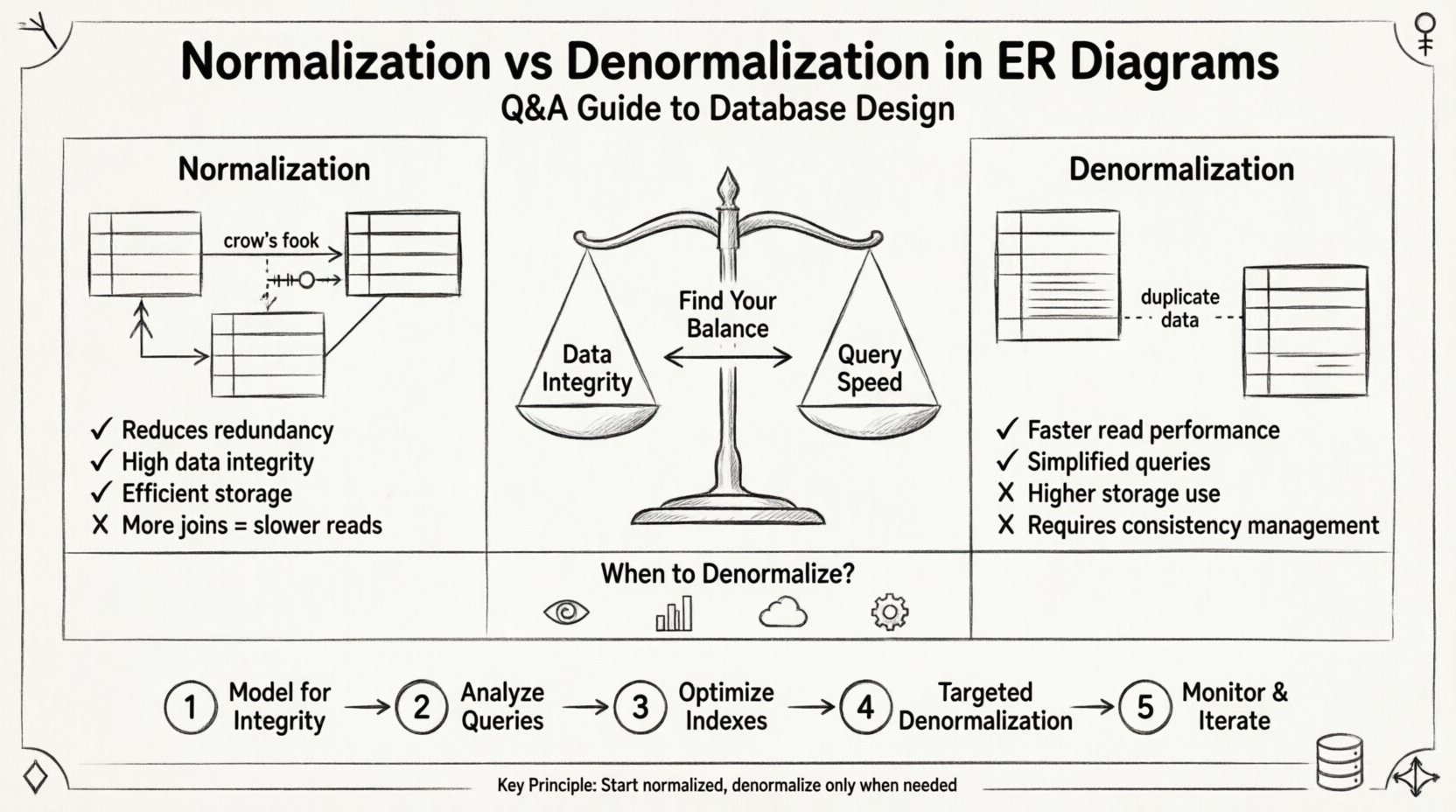
Comprendiendo los fundamentos: ¿Con qué estamos tratando? 🔍
Antes de adentrarnos en escenarios específicos, debemos definir los mecanismos centrales en juego en el diseño de su ERD.
¿Qué es la normalización? 🔄
La normalización es un proceso sistemático de organización de datos en una base de datos para reducir la redundancia y mejorar la integridad de los datos. Implica dividir tablas grandes en tablas más pequeñas y lógicamente conectadas, y definir relaciones entre ellas. El objetivo es garantizar que cada pieza de datos se almacene en un solo lugar.
- Objetivo: Eliminar datos duplicados y asegurar que las dependencias tengan sentido.
- Beneficio: Simplifica el mantenimiento de los datos y reduce los requisitos de almacenamiento.
- Costo: Aumenta la complejidad de las consultas debido a la necesidad de operaciones de unión.
La normalización generalmente se logra a través de una serie de etapas conocidas como Formas Normales. Cada forma se basa en la anterior, abordando tipos específicos de anomalías.
¿Qué es la denormalización? ⚖️
La denormalización es la introducción intencional de redundancia en una base de datos normalizada. Esto se hace para optimizar el rendimiento de lectura, especialmente en escenarios donde la velocidad de consulta es más crítica que la velocidad de escritura. Implica fusionar tablas o agregar columnas redundantes para evitar operaciones de unión costosas.
- Objetivo: Reducir el número de uniones necesarias para consultas complejas.
- Beneficio: Operaciones de lectura más rápidas y lógica de consulta simplificada.
- Costo: Uso de almacenamiento aumentado y mayor riesgo de inconsistencia de datos.
P&R: Análisis profundo sobre normalización y diseño de ERD 📝
Estas preguntas abordan los puntos de fricción más comunes que se encuentran al diseñar esquemas relacionales. Cubren la transición de la teoría a la implementación práctica.
P1: ¿Necesito normalizar todo hasta la 3FN? 🤷♂️
La respuesta corta es no. Aunque la Tercera Forma Normal (3FN) es una referencia estándar para muchas aplicaciones, no es una regla estricta para cada escenario. Normalizar hasta la 3FN elimina las dependencias transitivas, asegurando que los atributos no clave dependan únicamente de la clave primaria. Sin embargo, alcanzar formas superiores como la Forma Normal de Boyce-Codd (BCNF) o la Cuarta Forma Normal (4FN) a veces puede complicar el esquema sin ofrecer beneficios significativos.
Considere los compromisos:
- 3FN: Adecuada para sistemas transaccionales de propósito general donde la integridad de los datos es fundamental.
- 4FN/5FN: A menudo es excesivo a menos que estés manejando dependencias múltiples complejas o dependencias de unión.
- Enfoque práctico: Diseña para la 3FN primero. Evalúa cuellos de botella de rendimiento antes de considerar la denormalización o una normalización adicional.
P2: ¿Cómo afecta la normalización al rendimiento de las consultas? 🐢
La normalización afecta el rendimiento principalmente a través de la necesidad de uniones. Cuando los datos se distribuyen entre múltiples tablas, recuperar un registro completo requiere que el motor de base de datos enlace estas tablas. Este proceso consume recursos de CPU y memoria.
Los factores clave que influyen en el rendimiento incluyen:
- Complejidad de la unión:Más tablas significan más condiciones de unión que evaluar.
- Indización:Las claves foráneas deben estar indexadas para acelerar las uniones. Sin una indexación adecuada, la normalización puede provocar una degradación grave del rendimiento.
- Volumen de datos:A medida que el conjunto de datos crece, el costo de escanear y unir aumenta significativamente.
En aplicaciones con muchas lecturas, esta sobrecarga puede convertirse en un cuello de botella. En aplicaciones con muchas escrituras, la sobrecarga suele ser despreciable en comparación con la ventaja de reducir los anomalías de actualización.
P3: ¿Cuándo es apropiado denormalizar? ⚙️
La denormalización no debería ser el estado predeterminado. Es una medida correctiva que se aplica después de identificar problemas específicos de rendimiento. Deberías considerar la denormalización en las siguientes situaciones:
- Cargas de trabajo con muchas lecturas:Si el sistema procesa miles de lecturas por cada escritura, el costo de las uniones podría superar el costo de almacenamiento.
- Paneles de informes:Las consultas analíticas complejas suelen beneficiarse de datos previamente unidos almacenados en tablas anchas.
- Capas de caché:A veces, la denormalización se implementa en una capa de caché en lugar de en el motor de almacenamiento principal.
- Restricciones heredadas:Los motores de bases de datos antiguos o limitaciones específicas de hardware podrían tener dificultades con uniones complejas.
P4: ¿Cómo gestiono la consistencia de los datos durante la denormalización? 🛡️
Introducir redundancia crea el riesgo de inconsistencia de datos. Si almacenas el nombre de un cliente en ambas tablas Pedidos y la tabla Clientes , actualizar el nombre en la tabla Clientes la tabla requiere una actualización en cascada para el Pedidos tabla.
Las estrategias para mantener la consistencia incluyen:
- Lógica de aplicación: Asegúrese de que el código de la aplicación actualice todos los campos redundantes dentro de una sola transacción.
- Disparadores de base de datos: Utilice disparadores para sincronizar automáticamente las columnas redundantes cuando cambie los datos de origen.
- Reconciliación periódica: Ejecute trabajos programados para auditar y corregir inconsistencias en los datos denormalizados.
- Especialización de réplicas de lectura: Mantenga la base de datos principal completamente normalizada y utilice una copia denormalizada para informes.
Preguntas y respuestas: Escenarios avanzados y compromisos ⚖️
Más allá de lo básico, surgen desafíos arquitectónicos específicos al escalar sistemas. Estas preguntas abordan esas sutilezas.
P5: ¿Puedo mezclar tablas normalizadas y denormalizadas en el mismo diagrama ER? 🧩
Sí, los modelos híbridos son comunes en entornos de producción. Es una práctica estándar mantener un esquema normalizado central para la integridad transaccional, mientras se crean vistas denormalizadas o tablas de resumen para casos de uso específicos.
Por ejemplo:
- Tablas principales: Mantenga usuarios, productos y pedidos en 3FN para asegurar registros financieros precisos.
- Tablas de informes: Cree una tabla denormalizada que agregue totales de pedidos y detalles del cliente para una representación rápida del panel.
- Vistas: Utilice vistas SQL para presentar una estructura denormalizada a las aplicaciones sin duplicar físicamente los datos.
P6: ¿La denormalización viola la teoría de bases de datos? 📚
Teóricamente, sí. La teoría relacional aboga por la normalización para minimizar anomalías. Sin embargo, la ingeniería práctica a menudo requiere flexionar estas reglas para cumplir con los SLAs de rendimiento. La violación es intencional y calculada. Mientras la redundancia se gestione y documente, el diseño sigue siendo válido para su propósito previsto.
P7: ¿Cómo interactúa el índice con la normalización? 🔖
El índice es la herramienta principal para mitigar el costo de rendimiento de la normalización. Cuando normaliza, crea claves foráneas. Estas claves foráneas deben estar indexadas para permitir uniones eficientes.
Considere los siguientes puntos:
- Índices de claves foráneas: Cada clave foránea debe tener un índice para acelerar las uniones.
- Índices compuestos: Si una consulta se une en múltiples columnas, un índice compuesto puede cubrir todas las condiciones de unión.
- Impacto de la denormalización: La denormalización a menudo reduce la necesidad de índices de claves foráneas, reduciendo potencialmente la sobrecarga de escritura en los índices.
Comparación: Normalización frente a denormalización 📋
Para visualizar claramente los compromisos, consulte la tabla a continuación. Esta estructura ayuda en la toma de decisiones durante la fase de diseño.
| Característica | Normalización | Denormalización |
|---|---|---|
| Redundancia de datos | Minimizada | Aumentada |
| Integridad de datos | Alta | Requiere gestión |
| Espacio de almacenamiento | Eficiente | Menos eficiente |
| Rendimiento de lectura | Más lento (más uniones) | Más rápido (menos uniones) |
| Rendimiento de escritura | Más rápido (menos datos que actualizar) | Más lento (actualizar todas las copias) |
| Complejidad | Alta (muchas tablas) | Alta (lógica para sincronizar datos) |
| Mejor caso de uso | OLTP, Sistemas transaccionales | OLAP, Informes, carga intensa de lectura |
Estrategia de implementación: un enfoque paso a paso 🚀
Diseñar un esquema requiere un proceso metódico. No te apresures a denormalizar. Sigue este enfoque estructurado para asegurar una base estable.
Paso 1: Modelar para la integridad primero 🏗️
Comienza creando un esquema completamente normalizado. Apunta al menos a la Tercera Forma Normal (3FN). Identifica todas las entidades, atributos y relaciones. Asegúrate de que cada tabla tenga una clave primaria y que las claves foráneas estén correctamente definidas. Esta fase garantiza que tus datos sean precisos y consistentes.
Paso 2: Analizar patrones de consulta 🔎
Antes de cambiar el esquema, comprende cómo se accederá a los datos. Revisa los requisitos de la aplicación y los registros de consultas. Identifica qué consultas son lentas o complejas. Busca patrones en los que se requieran frecuentemente múltiples uniones.
Paso 3: Optimizar índices ⚡
Antes de denormalizar, asegúrate de que tu esquema normalizado esté correctamente indexado. A menudo, agregar los índices compuestos adecuados resuelve los problemas de rendimiento sin necesidad de modificar la estructura de la tabla. Prueba las consultas con el esquema y los índices actuales para establecer una base de comparación.
Paso 4: Denormalización dirigida 🎯
Si el rendimiento aún es insuficiente, aplica la denormalización de forma selectiva. No denormalices toda la base de datos. Enfócate únicamente en las tablas o columnas específicas que causan el cuello de botella. Documenta cada cambio realizado para facilitar el mantenimiento futuro.
Paso 5: Monitorear e iterar 📈
El diseño de bases de datos no es estático. Monitorea el sistema con el tiempo. A medida que crece el volumen de datos o cambian los patrones de uso, el equilibrio podría necesitar ajustes. Revisa periódicamente el esquema para asegurarte de que aún cumple con los requisitos de rendimiento e integridad.
Errores comunes que debes evitar 🚫
Incluso diseñadores experimentados pueden cometer errores al tratar con la optimización de diagramas ER. Ten cuidado con estos errores comunes.
- Sobrenormalización:Crear demasiadas tablas hace que el esquema sea difícil de entender y consultar. Mantén la estructura lógica e intuitiva.
- Subnormalización:Almacenar demasiados datos en una sola tabla conduce a anomalías de actualización y espacio desperdiciado.
- Ignorar el crecimiento de los datos:Un diseño que funciona con 1.000 registros puede fallar con 1.000.000. Planifica para escalar.
- Denormalización oculta:Denormalizar sin documentación genera confusión. Los futuros mantenimientos podrían no entender por qué los datos están duplicados.
- Suponer que todas las consultas son iguales:No todas las consultas tienen los mismos requisitos de rendimiento. Prioriza las más frecuentes y críticas.
Reflexiones finales sobre la arquitectura del esquema 🧠
La decisión entre normalización y denormalización no es binaria. Es un espectro de compromisos que depende de las necesidades específicas de tu aplicación. Un diagrama ER bien diseñado equilibra la integridad de los datos con la eficiencia de las consultas. Al comprender los principios subyacentes y seguir un enfoque estructurado, puedes construir sistemas que sean tanto robustos como eficientes.
Recuerda que las herramientas y tecnologías evolucionan. Sin embargo, los principios del diseño relacional permanecen constantes. Enfócate en el modelo de datos en sí, más que en las capacidades del motor de base de datos. Una base sólida apoyará tu aplicación sin importar los cambios de infraestructura que vengan en el futuro. Mantén tu esquema limpio, tu documentación clara y tus métricas de rendimiento presentes en cada paso. 🌟

