











डेटाबेस डिजाइन किसी भी विश्वसनीय एप्लिकेशन की रीढ़ है। एंटिटी रिलेशनशिप डायग्राम (ERD) बनाते समय, दो विपरीत बल ढांचे के आकार को आकार देते हैं: नॉर्मलाइजेशन और डीनॉर्मलाइजेशन। प्रत्येक रणनीति कब लागू करनी चाहिए, इसकी समझ आपकी डेटा इंफ्रास्ट्रक्चर की लंबी अवधि की स्वास्थ्य, प्रदर्शन और रखरखाव क्षमता को निर्धारित करती है। यह गाइड इन अवधारणाओं के संबंध में सबसे महत्वपूर्ण प्रश्नों का समाधान करता है, विशिष्ट सॉफ्टवेयर टूल्स पर निर्भर न होकर कुशल डेटाबेस संरचनाओं के डिजाइन के लिए स्पष्ट मार्ग प्रदान करता है। 🛠️
डेटा अखंडता और प्रश्न गति अक्सर विपरीत दिशाओं में खींचती हैं। नॉर्मलाइजेशन अतिरिक्त डेटा को कम करके अखंडता को प्राथमिकता देता है। डीनॉर्मलाइजेशन नियंत्रित अतिरिक्त डेटा शामिल करके गति को प्राथमिकता देता है। इस संतुलन को समझने के लिए संबंधित सिद्धांत और व्यावहारिक प्रदर्शन आवश्यकताओं की गहन समझ की आवश्यकता होती है। आइए लक्षित प्रश्नों और उत्तरों के माध्यम से तकनीकी विवरणों का अध्ययन करें। 📊
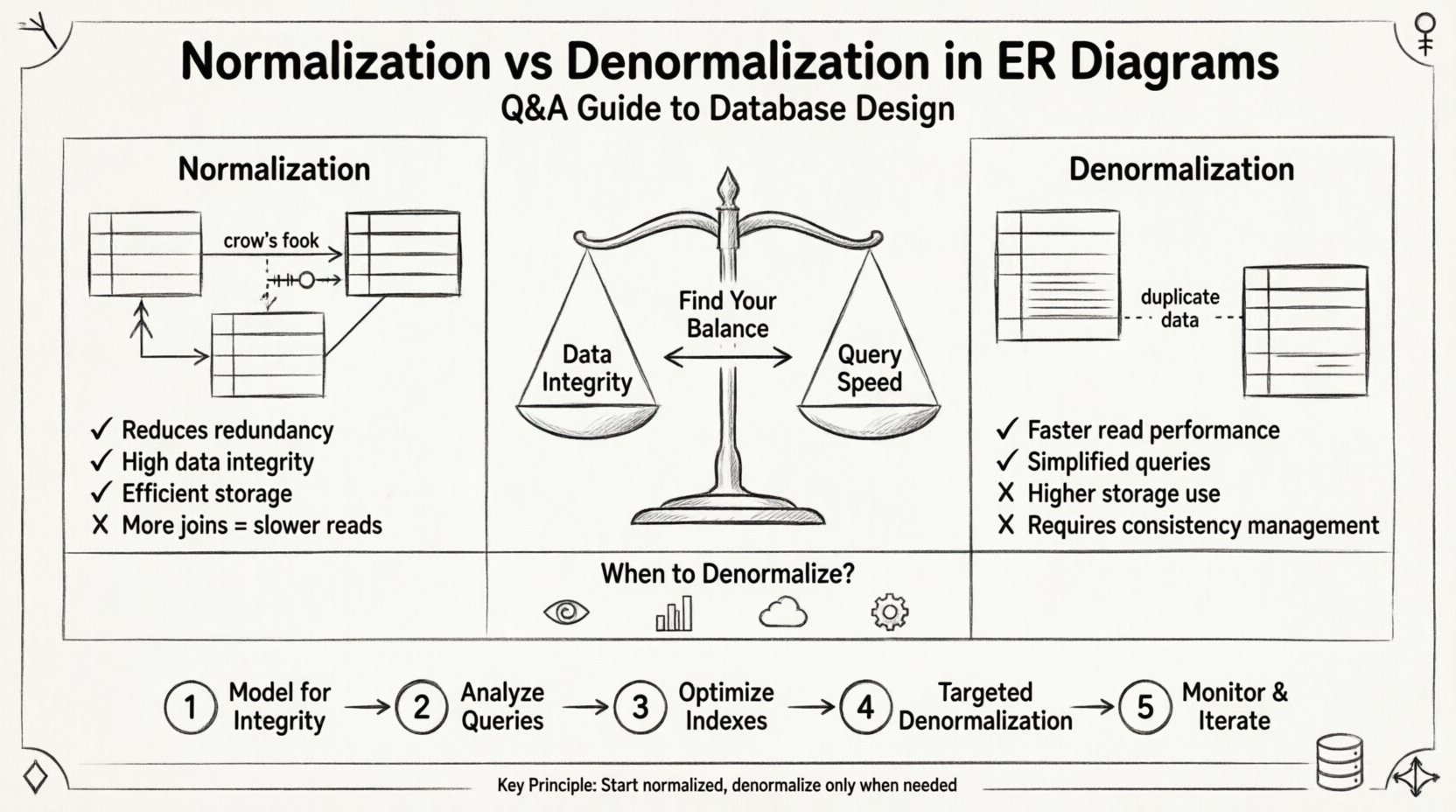
मूल बातों को समझना: हम किससे संबंधित हैं? 🔍
विशिष्ट परिदृश्यों में डुबकी लगाने से पहले, हमें अपने ईआरडी डिजाइन में काम कर रहे मुख्य तंत्रों को परिभाषित करना होगा।
नॉर्मलाइजेशन क्या है? 🔄
नॉर्मलाइजेशन डेटाबेस में डेटा को व्यवस्थित करने की एक व्यवस्थित प्रक्रिया है जिसका उद्देश्य अतिरिक्त डेटा को कम करना और डेटा अखंडता में सुधार करना है। इसमें बड़ी तालिकाओं को छोटी, तार्किक रूप से जुड़ी तालिकाओं में विभाजित करना और उनके बीच संबंधों को परिभाषित करना शामिल है। उद्देश्य यह सुनिश्चित करना है कि प्रत्येक डेटा के एक ही स्थान पर संग्रहीत होना है।
- लक्ष्य: डुप्लीकेट डेटा को समाप्त करें और यह सुनिश्चित करें कि निर्भरताएं समझ में आएं।
- लाभ: डेटा रखरखाव को सरल बनाता है और स्टोरेज की आवश्यकता को कम करता है।
- लागत: जॉइन की आवश्यकता के कारण प्रश्नों की जटिलता बढ़ जाती है।
नॉर्मलाइजेशन आमतौर पर नॉर्मल फॉर्म्स के नाम से जाने वाले चरणों के एक श्रृंखला के माध्यम से प्राप्त किया जाता है। प्रत्येक फॉर्म पिछले एक पर आधारित होता है और विशिष्ट प्रकार की विचलनों को संबोधित करता है।
डीनॉर्मलाइजेशन क्या है? ⚖️
डीनॉर्मलाइजेशन एक नॉर्मलाइज्ड डेटाबेस में अतिरिक्त डेटा को जानबूझकर शामिल करना है। इसका उद्देश्य पढ़ने के प्रदर्शन को अनुकूलित करना है, विशेष रूप से उन परिदृश्यों में जहां प्रश्न गति लेखन गति से अधिक महत्वपूर्ण है। इसमें तालिकाओं को मिलाना या अतिरिक्त कॉलम जोड़ना शामिल है ताकि महंगे जॉइन ऑपरेशन से बचा जा सके।
- लक्ष्य: जटिल प्रश्नों के लिए आवश्यक जॉइन की संख्या को कम करें।
- लाभ: तेज पढ़ने की क्रियाएं और सरलीकृत प्रश्न तर्क।
- लागत: स्टोरेज के उपयोग में वृद्धि और डेटा असंगति के उच्च जोखिम।
प्रश्न और उत्तर: नॉर्मलाइजेशन और ईआरडी डिजाइन में गहन अध्ययन 📝
इन प्रश्नों का संबंध तार्किक स्कीमा डिजाइन करते समय सामना की जाने वाली सबसे आम बाधाओं से है। इनमें सिद्धांत से व्यावहारिक कार्यान्वयन तक के संक्रमण को शामिल किया गया है।
प्रश्न 1: क्या मुझे सभी को 3NF तक नॉर्मलाइज़ करने की आवश्यकता है? 🤷♂️
छोटा उत्तर नहीं है। जबकि तृतीय सामान्य रूप (3NF) कई एप्लिकेशनों के लिए एक मानक मापदंड है, यह हर परिदृश्य के लिए एक कठोर नियम नहीं है। 3NF तक नॉर्मलाइज़ करने से स्थानांतरित निर्भरताएं समाप्त हो जाती हैं, जिससे यह सुनिश्चित होता है कि गैर-की विशेषताएं केवल मुख्य की पर निर्भर हों। हालांकि, बॉयस-कॉड नॉर्मल फॉर्म (BCNF) या चौथा नॉर्मल फॉर्म (4NF) जैसे उच्च रूपों को प्राप्त करना कभी-कभी स्कीमा को जटिल बना देता है बिना महत्वपूर्ण लाभ के।
विकल्पों को विचार करें:
- 3NF: सामान्य उद्देश्य वाले लेन-देन प्रणालियों के लिए अच्छा है जहां डेटा अखंडता महत्वपूर्ण है।
- 4NF/5NF: अक्सर अत्यधिक उपकरण है जब तक कि आप जटिल बहु-मूल्य निर्भरताओं या जॉइन निर्भरताओं के साथ नहीं निपट रहे हैं।
- व्यावहारिक दृष्टिकोण: पहले 3NF के लिए डिज़ाइन करें। असंगठित या अधिक नियमितता के विचार करने से पहले प्रदर्शन की सीमाओं का मूल्यांकन करें।
प्रश्न 2: नियमितीकरण प्रश्न प्रदर्शन को कैसे प्रभावित करता है? 🐢
नियमितीकरण प्रदर्शन को मुख्य रूप से जॉइन की आवश्यकता के माध्यम से प्रभावित करता है। जब डेटा एक से अधिक तालिकाओं में फैला होता है, तो एक पूर्ण रिकॉर्ड प्राप्त करने के लिए डेटाबेस इंजन को इन तालिकाओं को एक साथ जोड़ने की आवश्यकता होती है। इस प्रक्रिया में सीपीयू और मेमोरी संसाधन का उपयोग होता है।
प्रदर्शन को प्रभावित करने वाले मुख्य कारक शामिल हैं:
- जॉइन की जटिलता: अधिक तालिकाएं अधिक जॉइन शर्तों के मूल्यांकन के अर्थ हैं।
- इंडेक्सिंग: विदेशी कुंजियों को जॉइन को तेज करने के लिए इंडेक्स किया जाना चाहिए। उचित इंडेक्सिंग के बिना, नियमितीकरण को गंभीर प्रदर्शन गिरावट के कारण बन सकता है।
- डेटा आयतन: जैसे ही डेटासेट बढ़ता है, स्कैनिंग और जॉइन की लागत में काफी वृद्धि होती है।
पढ़ने पर अधिक निर्भर एप्लिकेशन में, इस ओवरहेड को एक बॉटलनेक बन सकता है। लेखन पर अधिक निर्भर एप्लिकेशन में, अपडेट अनियमितताओं में कमी के लाभ की तुलना में ओवरहेड अक्सर नगण्य होता है।
प्रश्न 3: असंगठित करना कब उचित है? ⚙️
असंगठित करना डिफ़ॉल्ट स्थिति नहीं होना चाहिए। यह विशिष्ट प्रदर्शन समस्याओं की पहचान के बाद लागू किया जाने वाला एक सुधारात्मक उपाय है। निम्न स्थितियों में आपको असंगठित करने के बारे में सोचना चाहिए:
- पढ़ने पर अधिक निर्भर कार्यभार: यदि प्रणाली प्रत्येक लेखन के लिए हजारों पढ़ने को प्रक्रिया करती है, तो जॉइन की लागत स्टोरेज लागत से अधिक हो सकती है।
- रिपोर्टिंग डैशबोर्ड: जटिल विश्लेषणात्मक प्रश्नों को अक्सर विस्तृत तालिकाओं में संग्रहीत पूर्व-जॉइन किए गए डेटा से लाभ मिलता है।
- कैश परतें: कभी-कभी असंगठित करना प्राथमिक स्टोरेज इंजन के बजाय कैश परत में लागू किया जाता है।
- पुरानी सीमाएं: पुराने डेटाबेस इंजन या विशिष्ट हार्डवेयर सीमाएं जटिल जॉइन के साथ कठिनाई महसूस कर सकते हैं।
प्रश्न 4: असंगठित करते समय डेटा संगतता का प्रबंधन कैसे करें? 🛡️
अतिरिक्तता को लागू करने से डेटा असंगति का जोखिम बढ़ता है। यदि आप एक ग्राहक का नाम दोनों में संग्रहीत करते हैं आदेशों तालिका और ग्राहकों तालिका में, नाम को अपडेट करने पर ग्राहकों तालिका को एक कैस्केड अपडेट की आवश्यकता होती है आदेश तालिका।
सुसंगतता बनाए रखने के लिए रणनीतियाँ शामिल हैं:
- एप्लिकेशन तर्क: सुनिश्चित करें कि एप्लिकेशन कोड सभी अतिरिक्त फ़ील्ड को एक ही लेनदेन के भीतर अपडेट करे।
- डेटाबेस ट्रिगर्स: स्रोत डेटा में परिवर्तन होने पर अतिरिक्त कॉलम को स्वचालित रूप से सिंक करने के लिए ट्रिगर्स का उपयोग करें।
- आवधिक समन्वय: अननॉर्मलाइज़्ड डेटा में असंगतियों की जांच और ठीक करने के लिए योजनाबद्ध कार्यक्रम चलाएं।
- रीड-रिप्लिका विशेषज्ञता: मुख्य डेटाबेस को पूरी तरह से नॉर्मलाइज़्ड रखें और रिपोर्टिंग के लिए एक अननॉर्मलाइज़्ड कॉपी का उपयोग करें।
प्रश्न-उत्तर: उन्नत परिदृश्य और व्यापार विकल्प ⚖️
आधारभूत बातों से आगे, जब सिस्टम को स्केल किया जाता है तो विशिष्ट आर्किटेक्चरल चुनौतियाँ उत्पन्न होती हैं। इन प्रश्नों का उद्देश्य उन बातों को संबोधित करना है।
प्रश्न 5: क्या मैं एक ही ERD में नॉर्मलाइज़्ड और अननॉर्मलाइज़्ड तालिकाओं को मिला सकता हूँ? 🧩
हाँ, हाइब्रिड मॉडल प्रोडक्शन वातावरणों में आम हैं। लेनदेन संपूर्णता के लिए मुख्य नॉर्मलाइज़्ड स्कीमा बनाए रखना मानक प्रथा है, जबकि विशिष्ट उपयोग के मामलों के लिए अननॉर्मलाइज़्ड दृश्य या सारांश तालिकाएं बनाई जाती हैं।
उदाहरण के लिए:
- मुख्य तालिकाएं: उपयोगकर्ताओं, उत्पादों और आदेशों को 3NF में रखें ताकि लेखांकन रिकॉर्ड सही हों।
- रिपोर्टिंग तालिकाएं: त्वरित डैशबोर्ड रेंडरिंग के लिए आदेश कुल और ग्राहक विवरण को एकत्र करने वाली अननॉर्मलाइज़्ड तालिका बनाएं।
- दृश्य: डेटा की भौतिक दोहराव किए बिना एप्लिकेशन को अननॉर्मलाइज़्ड संरचना प्रस्तुत करने के लिए SQL दृश्यों का उपयोग करें।
प्रश्न 6: क्या अननॉर्मलाइज़ेशन डेटाबेस सिद्धांत का उल्लंघन करता है? 📚
सिद्धांत रूप से, हाँ। संबंधित सिद्धांत अनियमितताओं को कम करने के लिए नॉर्मलाइज़ेशन के पक्ष में है। हालांकि, व्यावहारिक इंजीनियरिंग के लिए अक्सर इन नियमों को तोड़ने की आवश्यकता होती है ताकि प्रदर्शन SLA पूरे किए जा सकें। उल्लंघन जानबूझकर और गणना के आधार पर किया जाता है। जब तक अतिरिक्तता का प्रबंधन और दस्तावेज़ीकरण किया जाता है, डिज़ाइन उसके उद्देश्य के लिए वैध रहता है।
प्रश्न 7: इंडेक्सिंग नॉर्मलाइज़ेशन के साथ कैसे बातचीत करती है? 🔖
इंडेक्सिंग नॉर्मलाइज़ेशन के प्रदर्शन लागत को कम करने का प्राथमिक उपकरण है। जब आप नॉर्मलाइज़ करते हैं, तो आप विदेशी कुंजियाँ बनाते हैं। इन विदेशी कुंजियों को अनुक्रमण करना आवश्यक है ताकि कुशल जोड़ की अनुमति मिल सके।
निम्नलिखित बिंदुओं पर विचार करें:
- विदेशी कुंजी इंडेक्स: प्रत्येक विदेशी कुंजी को जोड़ को तेज करने के लिए इंडेक्स होना चाहिए।
- संयुक्त सूचीकरण: यदि एक प्रश्न बहुत से कॉलम पर जोड़ता है, तो एक संयुक्त सूचीकरण सभी जॉइन शर्तों को कवर कर सकता है।
- अनियमितता का प्रभाव: अनियमितता अक्सर विदेशी कुंजी सूचियों की आवश्यकता को कम करती है, जिससे सूचियों पर लेखन ओवरहेड कम हो सकता है।
तुलना: नियमितीकरण बनाम अनियमितता 📋
व्यापार के लाभ-हानि को स्पष्ट रूप से देखने के लिए नीचे दी गई तालिका को देखें। यह संरचना डिज़ाइन चरण के दौरान निर्णय लेने में मदद करती है।
| विशेषता | नियमितीकरण | अनियमितता |
|---|---|---|
| डेटा अतिरेक | न्यूनतम | बढ़ाया गया |
| डेटा अखंडता | उच्च | प्रबंधन की आवश्यकता होती है |
| स्टोरेज स्पेस | कुशल | कम कुशल |
| पढ़ने का प्रदर्शन | धीमा (अधिक जॉइन) | तेज (कम जॉइन) |
| लेखन प्रदर्शन | तेज (अपडेट करने के लिए कम डेटा) | धीमा (सभी प्रतियों को अपडेट करना) |
| जटिलता | उच्च (बहुत सारी तालिकाएं) | उच्च (डेटा सिंक करने के लिए तर्क) |
| सर्वोत्तम उपयोग केस | OLTP, लेनदेन प्रणाली | OLAP, रिपोर्टिंग, पढ़ने पर अधिक निर्भर |
कार्यान्वयन रणनीति: एक चरणबद्ध दृष्टिकोण 🚀
एक स्कीम को डिज़ाइन करने के लिए एक व्यवस्थित प्रक्रिया की आवश्यकता होती है। अस्वीकृति के लिए जल्दबाज़ी न करें। एक स्थिर आधार सुनिश्चित करने के लिए इस संरचित दृष्टिकोण का पालन करें।
चरण 1: प्रथम अखंडता के लिए मॉडल बनाएं 🏗️
पूरी तरह से सामान्यीकृत स्कीम बनाने से शुरुआत करें। कम से कम तृतीय सामान्य रूप (3NF) तक पहुंचने का प्रयास करें। सभी प्राथमिकताएं, गुण और संबंधों की पहचान करें। यह सुनिश्चित करें कि प्रत्येक तालिका में प्राथमिक कुंजी हो और विदेशी कुंजियों को सही तरीके से परिभाषित किया गया हो। इस चरण में यह सुनिश्चित करने के लिए कि आपके डेटा सही और संगत है।
चरण 2: प्रश्न पैटर्न का विश्लेषण करें 🔎
स्कीम में बदलाव करने से पहले, यह समझें कि डेटा कैसे प्राप्त किया जाएगा। एप्लिकेशन की आवश्यकताओं और प्रश्न लॉग की समीक्षा करें। यह पहचानें कि कौन से प्रश्न धीमे या जटिल हैं। ऐसे पैटर्न की तलाश करें जहां बार-बार बहुत से जॉइन की आवश्यकता होती है।
चरण 3: इंडेक्स को अनुकूलित करें ⚡
अस्वीकृति करने से पहले, यह सुनिश्चित करें कि आपकी सामान्यीकृत स्कीम सही तरीके से इंडेक्स की गई है। अक्सर, सही संयुक्त इंडेक्स जोड़ने से टेबल संरचना बदले बिना प्रदर्शन की समस्याओं का समाधान हो जाता है। वर्तमान स्कीम और इंडेक्स के साथ प्रश्नों का परीक्षण करके एक आधार तैयार करें।
चरण 4: लक्षित अस्वीकृति 🎯
यदि प्रदर्शन अभी भी पर्याप्त नहीं है, तो अस्वीकृति को चयनात्मक रूप से लागू करें। पूरे डेटाबेस को अस्वीकृत न करें। केवल उन विशिष्ट तालिकाओं या कॉलम पर ध्यान केंद्रित करें जो बफलेट का कारण बन रहे हैं। भविष्य के रखरखाव के लिए प्रत्येक बदलाव का दस्तावेज़ीकरण करें।
चरण 5: मॉनिटर करें और अनुकूलित करें 📈
डेटाबेस डिज़ाइन स्थिर नहीं है। समय के साथ प्रणाली को मॉनिटर करें। जैसे-जैसे डेटा का आकार बढ़ता है या उपयोग के पैटर्न बदलते हैं, संतुलन को समायोजित करने की आवश्यकता हो सकती है। प्रदर्शन और अखंडता की आवश्यकताओं को अभी भी पूरा करता है या नहीं, इसकी नियमित रूप से समीक्षा करें।
बचने के लिए सामान्य गलतियां 🚫
यहां तक कि अनुभवी डिज़ाइनर भी ईआरडी अनुकूलन के साथ गलती कर सकते हैं। इन सामान्य त्रुटियों से बचें।
- अत्यधिक सामान्यीकरण:बहुत सारी तालिकाएं बनाने से स्कीम को समझने और प्रश्न करने में कठिनाई होती है। संरचना को तार्किक और स्पष्ट रखें।
- अपर्याप्त सामान्यीकरण:एक ही तालिका में बहुत अधिक डेटा संग्रहित करने से अपडेट विचलन और बर्बाद स्थान की समस्या उत्पन्न होती है।
- डेटा वृद्धि को नजरअंदाज करना:1,000 रिकॉर्ड्स के साथ काम करने वाला डिज़ाइन 1,000,000 रिकॉर्ड्स के साथ विफल हो सकता है। स्केल के लिए योजना बनाएं।
- छिपी हुई अस्वीकृति:दस्तावेज़ीकरण के बिना अस्वीकृति करने से भ्रम उत्पन्न होता है। भविष्य के रखरखाव करने वाले यह नहीं समझ पाएंगे कि डेटा क्यों दोहराया गया है।
- सभी प्रश्न समान हैं, इसका मानना:सभी प्रश्नों की प्रदर्शन आवश्यकताएं समान नहीं होती हैं। सबसे अधिक बार आने वाले और महत्वपूर्ण प्रश्नों को प्राथमिकता दें।
स्कीम आर्किटेक्चर पर अंतिम विचार 🧠
सामान्यीकरण और अस्वीकृति के बीच निर्णय द्विआधारी नहीं है। यह एक विभिन्न विकल्पों का स्पेक्ट्रम है जो आपकी विशिष्ट एप्लिकेशन की आवश्यकताओं पर निर्भर करता है। एक अच्छी तरह से डिज़ाइन किए गए ईआरडी में डेटा अखंडता और प्रश्न की कार्यक्षमता का संतुलन होता है। आधारभूत सिद्धांतों को समझने और एक संरचित दृष्टिकोण का पालन करने से आप ऐसी प्रणालियां बना सकते हैं जो दोनों तरह से मजबूत और कार्यक्षम हों।
याद रखें कि उपकरण और तकनीक विकसित होती रहती हैं। हालांकि, संबंधात्मक डिज़ाइन के सिद्धांत स्थिर रहते हैं। डेटाबेस इंजन की क्षमताओं के बजाय डेटा मॉडल पर ध्यान केंद्रित करें। भविष्य में आने वाले बुनियादी ढांचे के बदलावों के बावजूद एक मजबूत आधार आपके एप्लिकेशन का समर्थन करेगा। अपनी स्कीम साफ रखें, अपने दस्तावेज़ीकरण स्पष्ट रखें, और हर चरण पर अपने प्रदर्शन मापदंडों को ध्यान में रखें। 🌟

