











Desain basis data adalah tulang punggung dari setiap aplikasi yang kuat. Saat membuat Diagram Hubungan Entitas (ERD), dua kekuatan yang saling bertentangan membentuk skema: normalisasi dan denormalisasi. Memahami kapan menerapkan masing-masing strategi menentukan kesehatan jangka panjang, kinerja, dan kemudahan pemeliharaan infrastruktur data Anda. Panduan ini membahas pertanyaan-pertanyaan paling krusial mengenai konsep-konsep ini, memberikan jalan yang jelas untuk merancang struktur basis data yang efisien tanpa bergantung pada alat perangkat lunak tertentu. 🛠️
Integritas data dan kecepatan kueri sering kali menarik ke arah yang berlawanan. Normalisasi memprioritaskan integritas dengan mengurangi redundansi. Denormalisasi memprioritaskan kecepatan dengan memperkenalkan redundansi yang terkendali. Menavigasi keseimbangan ini membutuhkan pemahaman mendalam tentang teori relasional dan persyaratan kinerja praktis. Mari kita eksplorasi detail teknis melalui serangkaian pertanyaan dan jawaban yang terfokus. 📊
Memahami Dasar-Dasar: Apa yang Sedang Kita Hadapi? 🔍
Sebelum masuk ke skenario tertentu, kita harus mendefinisikan mekanisme inti yang berperan dalam desain ERD Anda.
Apa itu Normalisasi? 🔄
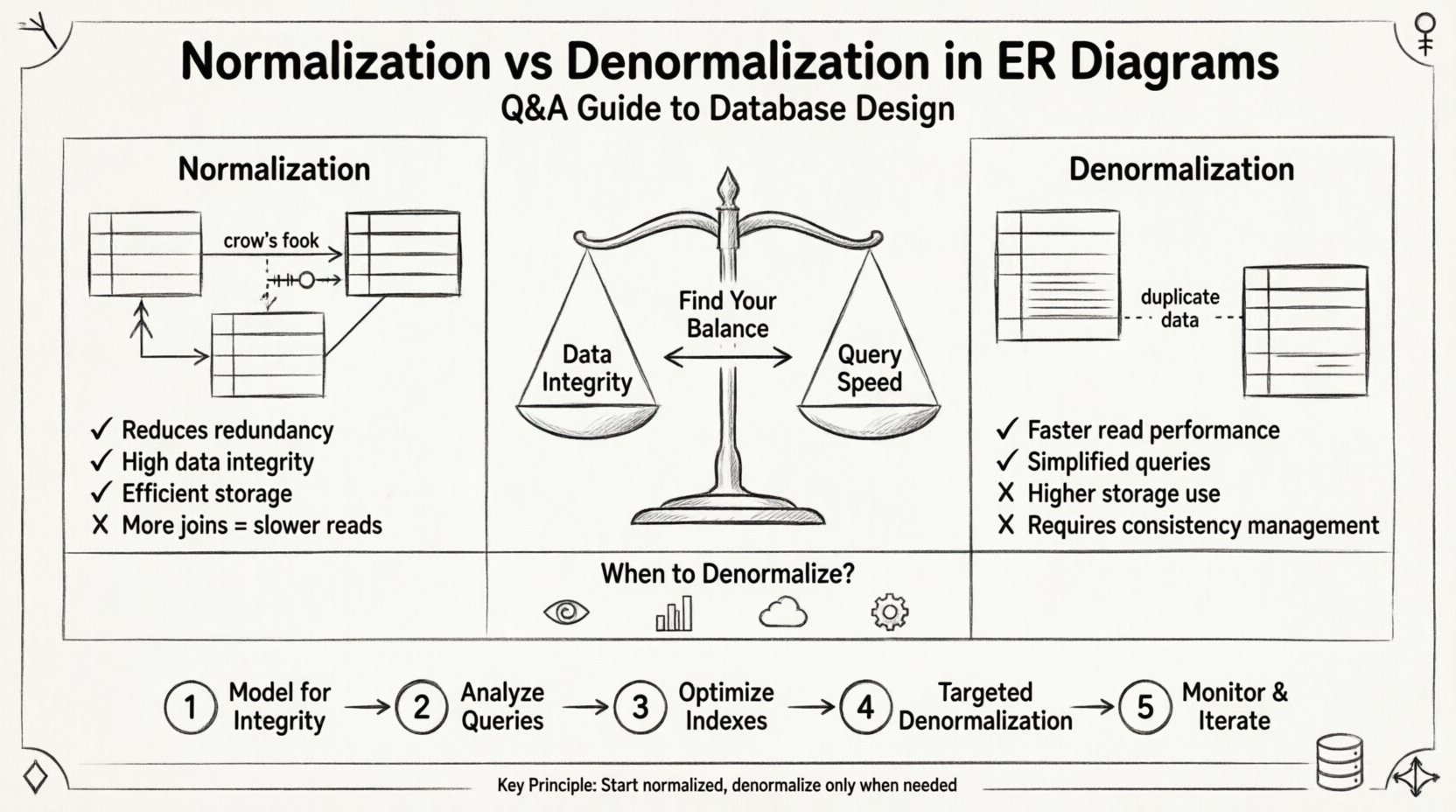
Normalisasi adalah proses sistematis dalam mengatur data di basis data untuk mengurangi redundansi dan meningkatkan integritas data. Ini melibatkan pembagian tabel besar menjadi tabel-tabel kecil yang terhubung secara logis dan mendefinisikan hubungan di antara mereka. Tujuannya adalah memastikan bahwa setiap bagian data disimpan hanya di satu tempat.
- Tujuan: Menghilangkan data duplikat dan memastikan ketergantungan masuk akal.
- Manfaat: Mempermudah pemeliharaan data dan mengurangi kebutuhan penyimpanan.
- Biaya: Meningkatkan kompleksitas kueri karena kebutuhan akan operasi join.
Normalisasi biasanya dicapai melalui serangkaian tahapan yang dikenal sebagai Bentuk Normal. Setiap bentuk dibangun berdasarkan bentuk sebelumnya, menangani jenis anomali tertentu.
Apa itu Denormalisasi? ⚖️
Denormalisasi adalah pengenalan redundansi secara sengaja ke dalam basis data yang telah dinormalisasi. Ini dilakukan untuk mengoptimalkan kinerja baca, khususnya dalam skenario di mana kecepatan kueri lebih penting daripada kecepatan tulis. Ini melibatkan penggabungan tabel atau penambahan kolom redundan untuk menghindari operasi join yang mahal.
- Tujuan: Mengurangi jumlah join yang dibutuhkan untuk kueri kompleks.
- Manfaat: Operasi baca yang lebih cepat dan logika kueri yang disederhanakan.
- Biaya: Peningkatan penggunaan penyimpanan dan risiko yang lebih tinggi terhadap ketidaksesuaian data.
Tanya Jawab: Penjelasan Mendalam tentang Normalisasi dan Desain ERD 📝
Pertanyaan-pertanyaan ini menangani titik-titik ketegangan paling umum yang dihadapi saat merancang skema relasional. Mereka mencakup transisi dari teori ke implementasi praktis.
T1: Apakah saya harus menormalisasi semua hal ke bentuk normal 3NF? 🤷♂️
Jawaban singkatnya adalah tidak. Meskipun Bentuk Normal Ketiga (3NF) merupakan tolok ukur standar untuk banyak aplikasi, bukan aturan keras untuk setiap skenario. Menormalisasi hingga 3NF menghilangkan ketergantungan transitif, memastikan bahwa atribut non-kunci hanya bergantung pada kunci utama. Namun, mencapai bentuk yang lebih tinggi seperti Bentuk Normal Boyce-Codd (BCNF) atau Bentuk Normal Keempat (4NF) terkadang mempersulit skema tanpa memberikan manfaat yang signifikan.
Pertimbangkan pertukarannya:
- 3NF: Baik untuk sistem transaksional umum di mana integritas data sangat penting.
- 4NF/5NF: Sering berlebihan kecuali Anda menangani ketergantungan multi-nilai yang kompleks atau ketergantungan join.
- Pendekatan Praktis: Rancang untuk 3NF terlebih dahulu. Evaluasi bottleneck kinerja sebelum mempertimbangkan denormalisasi atau normalisasi lebih lanjut.
Q2: Bagaimana normalisasi memengaruhi kinerja kueri? 🐢
Normalisasi memengaruhi kinerja terutama melalui kebutuhan akan join. Ketika data tersebar di beberapa tabel, mengambil rekaman lengkap membutuhkan mesin basis data untuk menghubungkan tabel-tabel tersebut. Proses ini mengonsumsi sumber daya CPU dan memori.
Faktor-faktor kunci yang memengaruhi kinerja meliputi:
- Kompleksitas Join:Lebih banyak tabel berarti lebih banyak kondisi join yang harus dievaluasi.
- Pengindeksan:Kunci asing harus diindeks untuk mempercepat join. Tanpa pengindeksan yang tepat, normalisasi dapat menyebabkan penurunan kinerja yang parah.
- Volume Data:Seiring pertumbuhan dataset, biaya pemindaian dan join meningkat secara signifikan.
Pada aplikasi yang banyak membaca, beban ini dapat menjadi bottleneck. Pada aplikasi yang banyak menulis, beban ini sering kali dapat diabaikan dibandingkan manfaat dari pengurangan anomali pembaruan.
Q3: Kapan saatnya tepat untuk melakukan denormalisasi? ⚙️
Denormalisasi sebaiknya bukan keadaan bawaan. Ini merupakan tindakan korektif yang diterapkan setelah mengidentifikasi masalah kinerja tertentu. Anda sebaiknya mempertimbangkan denormalisasi dalam situasi berikut:
- Beban Baca yang Berat:Jika sistem memproses ribuan bacaan untuk setiap penulisan, biaya join dapat melebihi biaya penyimpanan.
- Papan Informasi Pelaporan:Kueri analitik yang kompleks sering mendapat manfaat dari data yang telah dijoin sebelumnya yang disimpan dalam tabel lebar.
- Lapisan Penyimpanan Sementara (Cache):Kadang-kadang denormalisasi diterapkan di lapisan cache daripada mesin penyimpanan utama.
- Keterbatasan Warisan:Mesin basis data yang lebih lama atau keterbatasan perangkat keras tertentu mungkin kesulitan dengan join yang kompleks.
Q4: Bagaimana saya mengelola konsistensi data selama denormalisasi? 🛡️
Mengintroduksi redundansi menciptakan risiko ketidakkonsistenan data. Jika Anda menyimpan nama pelanggan di kedua tabel Pesanan dan tabel Pelanggan , memperbarui nama di tabel Pelanggan tabel memerlukan pembaruan cascade ke Pesanan tabel.
Strategi untuk menjaga konsistensi meliputi:
- Logika Aplikasi: Pastikan kode aplikasi memperbarui semua bidang yang berulang dalam satu transaksi tunggal.
- Pemicu Basis Data: Gunakan pemicu untuk secara otomatis menyinkronkan kolom yang berulang ketika data sumber berubah.
- Rekonsiliasi Berkala: Jalankan pekerjaan terjadwal untuk meninjau dan memperbaiki ketidaksesuaian dalam data yang tidak dinormalisasi.
- Spesialisasi Read-Replica: Pertahankan basis data utama sepenuhnya dinormalisasi dan gunakan salinan yang tidak dinormalisasi untuk pelaporan.
Tanya Jawab: Adegan Lanjutan dan Pertukaran ⚖️
Di luar dasar-dasar, tantangan arsitektur khusus muncul saat mengembangkan sistem. Pertanyaan-pertanyaan ini membahas nuansa tersebut.
Q5: Bisakah saya mencampur tabel yang dinormalisasi dan tidak dinormalisasi dalam ERD yang sama? 🧩
Ya, model hibrida umum terjadi di lingkungan produksi. Praktik standar adalah mempertahankan skema inti yang dinormalisasi untuk menjaga integritas transaksional sementara membuat tampilan yang tidak dinormalisasi atau tabel ringkasan untuk kasus penggunaan tertentu.
Sebagai contoh:
- Tabel Inti: Pertahankan pengguna, produk, dan pesanan dalam bentuk 3NF untuk memastikan catatan keuangan yang akurat.
- Tabel Pelaporan: Buat tabel yang tidak dinormalisasi yang mengagregasi total pesanan dan detail pelanggan untuk tampilan dashboard yang cepat.
- Tampilan: Gunakan tampilan SQL untuk menampilkan struktur yang tidak dinormalisasi ke aplikasi tanpa secara fisik menggandakan data.
Q6: Apakah normalisasi melanggar teori basis data? 📚
Secara teoritis, ya. Teori relasional menganjurkan normalisasi untuk meminimalkan anomali. Namun, rekayasa praktis sering kali mengharuskan melengkungkan aturan ini untuk memenuhi SLA kinerja. Pelanggaran ini sengaja dan dihitung secara matang. Selama redundansi dikelola dan didokumentasikan, desain tetap valid untuk tujuan yang dimaksudkan.
Q7: Bagaimana indeks berinteraksi dengan normalisasi? 🔖
Indeks adalah alat utama untuk mengurangi biaya kinerja dari normalisasi. Saat Anda melakukan normalisasi, Anda membuat kunci asing. Kunci asing ini harus diindeks agar memungkinkan penggabungan yang efisien.
Pertimbangkan poin-poin berikut:
- Indeks Kunci Asing: Setiap kunci asing harus memiliki indeks untuk mempercepat penggabungan.
- Indeks Komposit: Jika sebuah query bergabung pada beberapa kolom, indeks komposit dapat mencakup semua kondisi gabungan.
- Dampak Denormalisasi: Denormalisasi sering mengurangi kebutuhan akan indeks kunci asing, yang berpotensi mengurangi beban tulis pada indeks.
Perbandingan: Normalisasi vs. Denormalisasi 📋
Untuk memvisualisasikan keuntungan dan kerugiannya dengan jelas, rujuk ke tabel di bawah ini. Struktur ini membantu dalam pengambilan keputusan selama tahap desain.
| Fitur | Normalisasi | Denormalisasi |
|---|---|---|
| Redundansi Data | Diminimalkan | Ditingkatkan |
| Integritas Data | Tinggi | Memerlukan Manajemen |
| Ruangan Penyimpanan | Efisien | Kurang Efisien |
| Kinerja Baca | Lebih Lambat (lebih banyak gabungan) | Lebih Cepat (lebih sedikit gabungan) |
| Kinerja Tulis | Lebih Cepat (data yang perlu diperbarui lebih sedikit) | Lebih Lambat (perbarui semua salinan) |
| Kompleksitas | Tinggi (banyak tabel) | Tinggi (logika untuk menyinkronkan data) |
| Kasus Penggunaan Terbaik | OLTP, Sistem Transaksional | OLAP, Pelaporan, Baca Berat |
Strategi Implementasi: Pendekatan Langkah Demi Langkah 🚀
Mendesain skema membutuhkan proses yang terencana. Jangan terburu-buru melakukan denormalisasi. Ikuti pendekatan terstruktur ini untuk memastikan fondasi yang stabil.
Langkah 1: Model untuk Integritas Terlebih Dahulu 🏗️
Mulailah dengan membuat skema yang sepenuhnya dinormalisasi. Tujuan minimal adalah Bentuk Normal Ketiga (3NF). Identifikasi semua entitas, atribut, dan hubungan. Pastikan setiap tabel memiliki kunci utama dan kunci asing didefinisikan dengan benar. Tahap ini memastikan data Anda akurat dan konsisten.
Langkah 2: Analisis Pola Query 🔎
Sebelum mengubah skema, pahami bagaimana data akan diakses. Tinjau persyaratan aplikasi dan log query. Identifikasi query mana yang lambat atau kompleks. Cari pola di mana beberapa join sering diperlukan.
Langkah 3: Optimalisasi Index ⚡
Sebelum melakukan denormalisasi, pastikan skema yang dinormalisasi Anda diindeks dengan benar. Seringkali, menambahkan indeks komposit yang tepat dapat menyelesaikan masalah kinerja tanpa perlu mengubah struktur tabel. Uji query dengan skema dan indeks saat ini untuk menetapkan dasar kinerja.
Langkah 4: Denormalisasi yang Terfokus 🎯
Jika kinerja masih belum memadai, terapkan denormalisasi secara selektif. Jangan melakukan denormalisasi pada seluruh basis data. Fokus hanya pada tabel atau kolom tertentu yang menyebabkan kemacetan. Dokumentasikan setiap perubahan yang dibuat untuk pemeliharaan di masa depan.
Langkah 5: Pantau dan Ulangi 📈
Desain basis data tidak bersifat statis. Pantau sistem dari waktu ke waktu. Seiring volume data meningkat atau pola penggunaan berubah, keseimbangan mungkin perlu disesuaikan. Tinjau skema secara rutin untuk memastikan tetap memenuhi persyaratan kinerja dan integritas.
Rintangan Umum yang Harus Dihindari 🚫
Bahkan desainer berpengalaman bisa terjatuh saat menangani optimasi ERD. Waspadai kesalahan umum berikut ini.
- Over-Normalisasi:Membuat terlalu banyak tabel membuat skema sulit dipahami dan diquery. Pertahankan struktur yang logis dan intuitif.
- Under-Normalisasi:Menyimpan terlalu banyak data dalam satu tabel menyebabkan anomali pembaruan dan pemborosan ruang.
- Mengabaikan Pertumbuhan Data:Desain yang berjalan baik dengan 1.000 catatan bisa gagal dengan 1.000.000. Rencanakan untuk skalabilitas.
- Denormalisasi Tersembunyi:Melakukan denormalisasi tanpa dokumentasi menyebabkan kebingungan. Pemelihara di masa depan mungkin tidak memahami mengapa data diulang.
- Mengasumsikan Semua Query Sama:Tidak semua query memiliki persyaratan kinerja yang sama. Beri prioritas pada query yang paling sering dan paling kritis.
Pikiran Akhir tentang Arsitektur Skema 🧠
Keputusan antara normalisasi dan denormalisasi bukanlah biner. Ini adalah spektrum pertukaran yang tergantung pada kebutuhan aplikasi Anda secara spesifik. ERD yang dirancang dengan baik menyeimbangkan integritas data dengan efisiensi query. Dengan memahami prinsip dasar dan mengikuti pendekatan terstruktur, Anda dapat membangun sistem yang kokoh dan berkinerja tinggi.
Ingatlah bahwa alat dan teknologi terus berkembang. Namun, prinsip desain relasional tetap konstan. Fokuslah pada model data itu sendiri, bukan pada kemampuan mesin basis data. Fondasi yang kuat akan mendukung aplikasi Anda terlepas dari perubahan infrastruktur di masa depan. Jaga skema Anda tetap bersih, dokumentasi Anda jelas, dan pertimbangkan metrik kinerja di setiap langkah. 🌟

