











Membangun arsitektur backend yang kuat membutuhkan lebih dari sekadar menulis kode yang efisien; diperlukan pemahaman dasar tentang bagaimana data disusun, disimpan, dan diambil dalam kondisi tekanan tinggi. Di inti infrastruktur ini terletak diagram hubungan entitas (ERD). Meskipun sering dianggap sebagai gambaran statis yang dibuat selama tahap perencanaan awal, ERD yang dirancang dengan baik berfungsi sebagai tulang punggung dinamis untuk sistem dengan lalu lintas tinggi. Saat lalu lintas meningkat tajam, skema basis data menentukan kinerja, latensi, dan ketersediaan. Model yang tidak terstruktur dengan baik dapat menyebabkan kegagalan berantai, sementara desain yang dapat diperluas dapat menampung pertumbuhan secara mulus.
Panduan ini mengeksplorasi nuansa teknis dalam membuat diagram ER yang tahan terhadap beban berat. Kami akan melampaui normalisasi dasar dan meninjau bagaimana hubungan, batasan, dan strategi penyimpanan fisik berinteraksi dalam lingkungan terdistribusi. Baik Anda merancang untuk jutaan pengguna bersamaan atau hanya merencanakan ekspansi di masa depan, prinsip-prinsip yang diuraikan di sini memberikan kerangka kerja untuk pemodelan data yang tangguh.
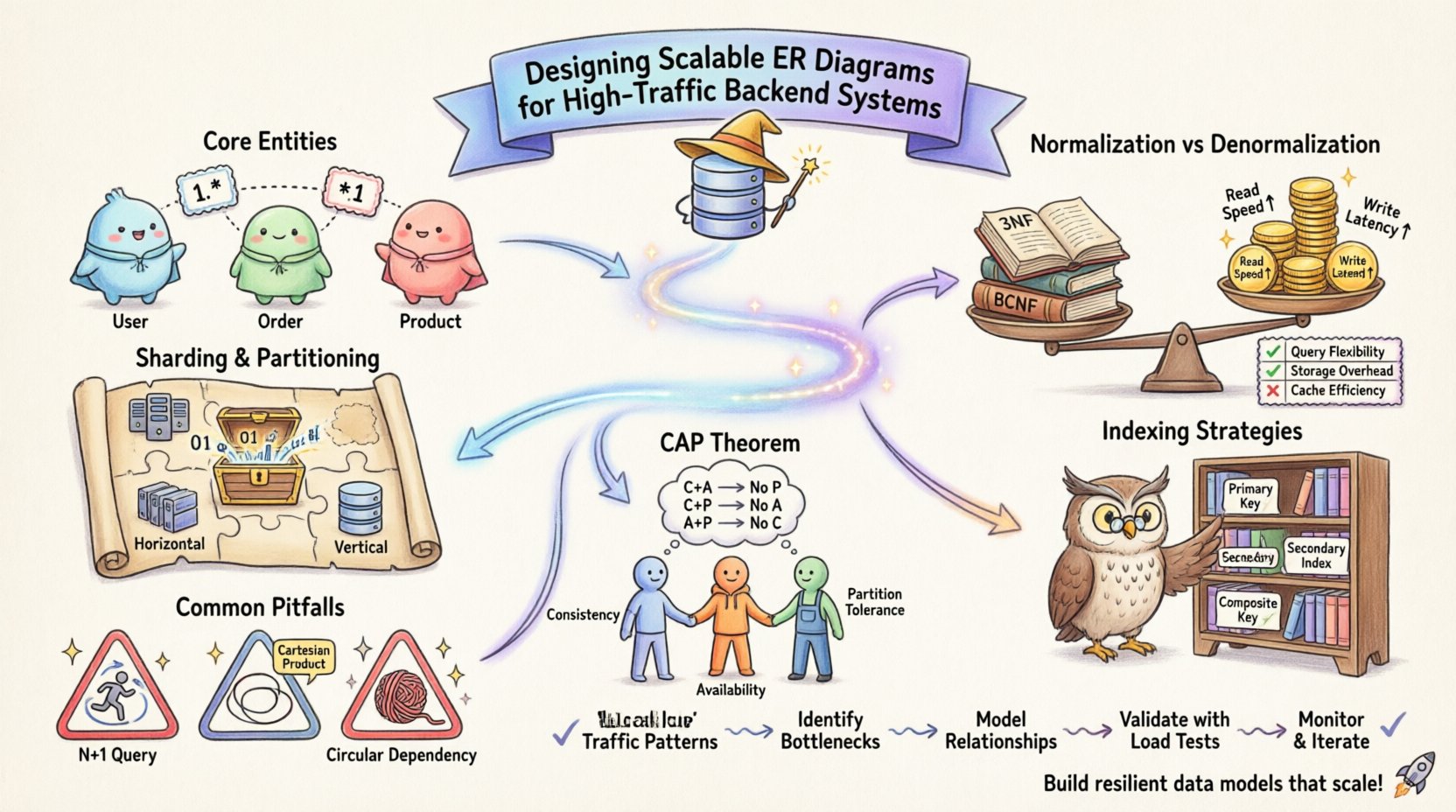
🏗️ Memahami Pemodelan Hubungan Entitas pada Skala Besar
Satuan dasar dari diagram ER adalah entitas, yang mewakili objek atau konsep yang berbeda dalam sistem Anda. Dalam lingkungan lalu lintas rendah, kesederhanaan sering kali menjadi yang utama. Namun, seiring volume transaksi meningkat, kompleksitas interaksi antar entitas tumbuh secara eksponensial. Sistem dengan lalu lintas tinggi membutuhkan pergeseran perspektif dari ‘bagaimana data ini harus terlihat?’ menjadi ‘bagaimana data ini akan berkinerja di bawah beban?’
- Identifikasi Entitas Inti:Tentukan objek data mana yang paling sering diakses. Ini adalah jalur panas Anda.
- Analisis Kardinalitas:Tentukan hubungan antar entitas. Hubungan satu-ke-banyak, banyak-ke-banyak, dan satu-ke-satu masing-masing membawa implikasi kinerja yang berbeda.
- Kerincian Atribut:Tentukan seberapa banyak detail yang disimpan dalam suatu atribut. Atribut yang terlalu rinci dapat membuat ukuran baris membengkak, sementara atribut yang terlalu umum dapat menghambat spesifisitas kueri.
Saat merancang untuk skala besar, tata letak fisik data menjadi sepentingnya struktur logis. Diagram ERD harus mencerminkan tidak hanya logika bisnis tetapi juga batasan operasional mesin penyimpanan. Sebagai contoh, beberapa sistem menangani kunci tingkat baris secara berbeda dibandingkan dengan kunci tingkat halaman. Diagram Anda harus mempertimbangkan batasan ini dengan meminimalkan titik-titik persaingan.
📊 Normalisasi vs. Denormalisasi: Pertukaran Kinerja
Normalisasi adalah proses mengorganisasi data untuk mengurangi redundansi dan meningkatkan integritas. Meskipun secara tradisional diajarkan sebagai praktik terbaik yang universal, sistem dengan lalu lintas tinggi sering kali membutuhkan pendekatan yang seimbang. Ketaatan ketat terhadap Bentuk Normal Ketiga (3NF) dapat menyebabkan operasi join yang berlebihan. Dalam lingkungan terdistribusi atau dengan konkurensi tinggi, join antar beberapa tabel dapat menjadi bottleneck yang signifikan.
Sebaliknya, denormalisasi melibatkan penggandaan data untuk mengurangi kebutuhan akan join. Strategi ini meningkatkan kinerja baca tetapi mempersulit operasi tulis. Anda harus mempertahankan konsistensi di antara bidang yang digandakan, yang menambah logika di lapisan aplikasi Anda.
| Strategi | Kinerja Baca | Kinerja Tulis | Konsistensi Data | Biaya Penyimpanan |
|---|---|---|---|---|
| Normalisasi Penuh | Rendah (Banyak Join) | Tinggi (Tulis Tunggal) | Tinggi | Rendah |
| Denormalisasi Parsial | Tinggi (Lebih Sedikit Join) | Sedang (Pembaruan Duplikasi) | Sedang | Sedang |
| Denormalisasi Penuh | Sangat Tinggi | Rendah (Logika Kompleks) | Rendah (Memerlukan Sinkronisasi) | Tinggi |
Memilih keseimbangan yang tepat tergantung pada rasio baca-terhadap-tulis Anda. Jika sistem Anda bersifat baca berat, seperti umpan konten atau platform berita, denormalisasi seringkali diperlukan. Jika sistem Anda bersifat tulis berat, seperti buku jurnal transaksi, normalisasi membantu mencegah anomali.
🌐 Strategi untuk Optimalisasi Baca dan Tulis
Optimalisasi untuk lalu lintas tinggi melibatkan teknik-teknik khusus yang memengaruhi bentuk ERD Anda. Strategi-strategi ini berfokus pada mengurangi waktu yang dibutuhkan untuk mengambil atau menyimpan informasi.
1. Strategi Penyimpanan Sementara yang Terefleksi dalam Skema
Saat merancang model data Anda, pertimbangkan bagaimana data akan disimpan sementara. Entitas yang sering diakses harus dirancang agar memungkinkan serialisasi yang mudah. Hindari menyimpan blob besar dengan panjang variabel di tabel yang sering digabungkan. Sebaliknya, simpan kunci referensi dan ambil blob secara terpisah ketika dibutuhkan. Ini mengurangi tekanan memori pada lapisan cache utama.
2. Kunci Partisi dan Sharding
Seiring data tumbuh, penyimpanan dalam satu tabel menjadi tidak efisien. Sharding membagi data di antara beberapa node. ERD Anda harus mendefinisikan kunci sharding secara jelas. Kunci ini menentukan bagaimana baris dibagikan. Jika kunci sharding dipilih secara buruk, Anda bisa berakhir dengan ‘partisi panas’ di mana satu node menangani lalu lintas yang jauh lebih besar dibandingkan node lainnya.
- Sharding Horizontal: Membagi baris berdasarkan kunci. ERD harus menunjukkan bagaimana kunci tersebut didistribusikan.
- Sharding Vertikal: Membagi kolom di antara tabel-tabel. Berguna untuk memisahkan kolom berat (seperti log) dari data transaksional inti.
🔗 Mengelola Hubungan dalam Data yang Dipartisi
Hubungan adalah perekat yang mengikat database bersama, tetapi dalam sistem terdistribusi, mereka bisa menjadi sumber latensi. Kunci asing menjamin integritas referensial, tetapi dalam lingkungan sharding, menegakkan batasan ini di antar node menjadi mahal.
Menangani Hubungan Banyak-ke-Banyak
Hubungan banyak-ke-banyak memerlukan tabel sambungan. Dalam skenario lalu lintas tinggi, tabel ini bisa menjadi penjaga. Jika Anda sering melakukan kueri, pertimbangkan untuk melakukan denormalisasi hubungan. Alih-alih bergabung dengan tabel sambungan, simpan ID hubungan secara langsung pada entitas induk jika kardinalitas memungkinkan. Ini mengurangi kedalaman kueri.
Entitas yang Mengacu pada Diri Sendiri
Beberapa entitas mengacu pada dirinya sendiri, seperti kategori atau komentar hierarkis. Rancang hubungan ini dengan hati-hati. Rekursi mendalam dalam kueri dapat menghabiskan sumber daya sistem. Batasi kedalaman rantai referensi diri dalam logika Anda, atau ratakan struktur di tempat yang memungkinkan menggunakan jalur yang telah dibuat sebelumnya.
🔍 Strategi Indeks untuk Kinerja
ERD mendefinisikan struktur logis, tetapi indeks menentukan kecepatan pengambilan fisik. Meskipun diagram itu sendiri tidak menunjukkan indeks, keputusan desain memengaruhi indeks mana yang layak digunakan.
- Kunci Utama: Ini dikelompokkan dalam banyak sistem, yang berarti data secara fisik diurutkan berdasarkan kunci ini. Pilih kunci utama yang meminimalkan fragmentasi dan memastikan distribusi yang merata.
- Indeks Sekunder: Setiap indeks mengonsumsi kinerja tulis. Menambahkan terlalu banyak indeks memperlambat operasi insert dan update. Hanya indeks kolom yang sering digunakan dalam klausa `WHERE`, `JOIN`, atau `ORDER BY`.
- Indeks Komposit: Ketika beberapa kolom di-query bersamaan, indeks komposit bisa lebih efisien. Urutan kolom dalam indeks penting dan harus sesuai dengan pola kueri yang paling umum.
⚖️ Konsistensi vs Ketersediaan dalam Skema Terdistribusi
Teori basis data sering membahas teorema CAP, yang menyiratkan bahwa suatu sistem hanya dapat menjamin dua dari tiga sifat berikut: Konsistensi, Ketersediaan, dan Ketahanan terhadap Pemisahan. Desain ERD Anda memengaruhi sifat mana yang Anda prioritaskan.
Jika Anda memprioritaskan konsistensi, Anda akan merancang dengan kunci asing yang ketat dan transaksi ACID. Ini menjamin integritas data tetapi dapat menimbulkan latensi selama pemisahan jaringan. Jika Anda memprioritaskan ketersediaan, Anda mungkin melonggarkan batasan, memungkinkan ketidaksesuaian sementara. Dalam hal ini, ERD Anda harus mendukung pola konsistensi akhir, seperti memiliki kolom ‘versi’ atau ‘status’ untuk melacak status data.
🔄 Evolusi Skema dan Versi
Persyaratan perangkat lunak berubah. Skema basis data harus berkembang tanpa menyebabkan downtime. Pada sistem dengan lalu lintas tinggi, Anda tidak bisa sekadar menghapus dan membuat ulang tabel. Strategi migrasi harus diintegrasikan ke dalam proses desain ERD.
- Kompatibilitas Mundur: Saat menambahkan kolom, buatlah nullable secara awal. Ini memungkinkan kode lama tetap berfungsi sementara kode baru mengisi data.
- Tipe yang Dapat Diperluas: Hindari tipe berpanjang tetap sebisa mungkin. Gunakan string berpanjang variabel atau bidang JSON untuk atribut yang mungkin berubah strukturnya seiring waktu.
- Penghapusan Logis: Alih-alih menghapus baris secara fisik, tandai mereka sebagai tidak aktif. Ini menjaga integritas referensial untuk data historis dan menghindari operasi penghapusan berantai yang dapat mengunci bagian besar tabel.
🛑 Kesalahan Struktural Umum
Bahkan arsitek berpengalaman mengalami jebakan saat melakukan skalabilitas. Kesadaran terhadap masalah-masalah umum ini dapat menghemat waktu signifikan selama tahap desain.
1. Masalah Query N+1
Ini terjadi ketika aplikasi mengambil daftar catatan dan kemudian menjalankan query terpisah untuk setiap catatan guna mengambil data terkait. Dalam ERD Anda, identifikasi hubungan yang sering diakses bersamaan. Jika Anda memperkirakan akan sering mengambil data terkait, pertimbangkan untuk mendekomposisi atau membuat tampilan khusus untuk pembacaan.
2. Produk Kartesius
Ketika menggabungkan beberapa tabel besar tanpa pemfilteran yang tepat, jumlah hasil dapat tumbuh secara eksponensial. Pastikan ERD Anda menerapkan batasan yang membatasi ukuran potensial hasil penggabungan. Gunakan filter pada kunci asing untuk membatasi cakupan hubungan.
3. Ketergantungan Melingkar
Entitas sebaiknya tidak saling tergantung dalam lingkaran. Misalnya, Entitas A membutuhkan Entitas B, dan Entitas B membutuhkan Entitas A untuk diinisialisasi. Ini menciptakan skenario deadlock saat startup atau saat memuat data. Putuskan siklus ini dengan memperkenalkan entitas perantara atau menginisialisasi data dalam urutan tertentu.
📝 Pemeliharaan dan Pemantauan
Desain bukanlah kejadian satu kali. Setelah sistem berjalan, Anda harus memantau kesehatan struktur data Anda. Metrik kinerja harus menjadi panduan untuk penyesuaian ERD di masa depan.
- Analisis Query: Tinjau secara rutin log query lambat. Jika suatu penggabungan tertentu secara konsisten lambat, tinjau kembali ERD untuk melihat apakah hubungan tersebut dapat dioptimalkan.
- Pemeriksaan Fragmentasi: Seiring waktu, penghapusan dan pembaruan dapat menyebabkan fragmentasi penyimpanan. Rencanakan jendela pemeliharaan di mana indeks dibangun ulang atau tabel dioptimalkan.
- Perencanaan Kapasitas: Seiring pertumbuhan data, kebutuhan penyimpanan berubah. Perkirakan tingkat pertumbuhan tabel terbesar Anda dan rencanakan untuk sharding atau partisi sebelum mencapai batas kapasitas.
🛠️ Aplikasi Praktis: Alur Kerja yang Dapat Diperluas
Untuk menerapkan prinsip-prinsip ini, ikuti alur kerja terstruktur saat membuat diagram Anda.
- Pengumpulan Kebutuhan: Tentukan rasio baca/tulis dan pola lalu lintas yang diharapkan.
- Pemodelan Logis:Buat ERD dengan fokus pada entitas dan hubungan bisnis tanpa perlu khawatir tentang batasan fisik.
- Pemodelan Fisik:Terjemahkan model logis menjadi skema fisik. Tambahkan indeks, tentukan tipe data, dan pertimbangkan strategi partisi.
- Ulasan dan Validasi:Simulasikan query beban tinggi terhadap model. Identifikasi kemungkinan bottleneck pada penggabungan (join) atau penahanan (locking).
- Dokumentasi:Dokumentasikan alasan di balik pilihan desain. Ini membantu pengembang di masa depan memahami mengapa tingkat normalisasi tertentu dipilih.
🔮 Membuat Arsitektur yang Tahan Masa Depan
Teknologi berkembang sangat cepat. Apa yang berfungsi hari ini mungkin tidak berfungsi dalam lima tahun ke depan. Rancang dengan fleksibilitas di pikiran. Hindari mengikat skema Anda terlalu erat dengan fitur mesin penyimpanan tertentu yang mungkin menjadi usang. Fokus pada hubungan logis dan aturan integritas data, karena hal-hal ini tetap konstan meskipun teknologi dasar berubah.
Dengan mengikuti panduan ini, Anda menciptakan model data yang tidak hanya berfungsi untuk kebutuhan saat ini tetapi juga tangguh cukup untuk menghadapi ketidakpastian lingkungan dengan lalu lintas tinggi. Tujuannya adalah membangun sistem yang berkinerja konsisten, dapat diskalakan secara horizontal, dan tetap dapat dipelihara seiring waktu.

