











Construir una arquitectura de backend robusta requiere más que simplemente escribir código eficiente; exige una comprensión fundamental de cómo se estructura, almacena y recupera la información bajo presión. En el corazón de esta infraestructura se encuentra el Diagrama de Relaciones de Entidades (ERD). Aunque a menudo se trata como un plano estático creado durante la fase inicial de planificación, un ERD bien diseñado sirve como columna vertebral dinámica de los sistemas de alta tráfico. Cuando hay picos de tráfico, el esquema de la base de datos determina el rendimiento, la latencia y la disponibilidad. Un modelo mal estructurado puede provocar fallos en cadena, mientras que un diseño escalable permite crecer de forma fluida.
Esta guía explora las sutilezas técnicas de construir diagramas ER que resisten cargas pesadas. Avanzaremos más allá de la normalización básica y examinaremos cómo interactúan las relaciones, las restricciones y las estrategias de almacenamiento físico en entornos distribuidos. Ya sea que estés diseñando para millones de usuarios concurrentes o simplemente planeando una expansión futura, los principios descritos aquí proporcionan un marco para un modelado de datos resiliente.
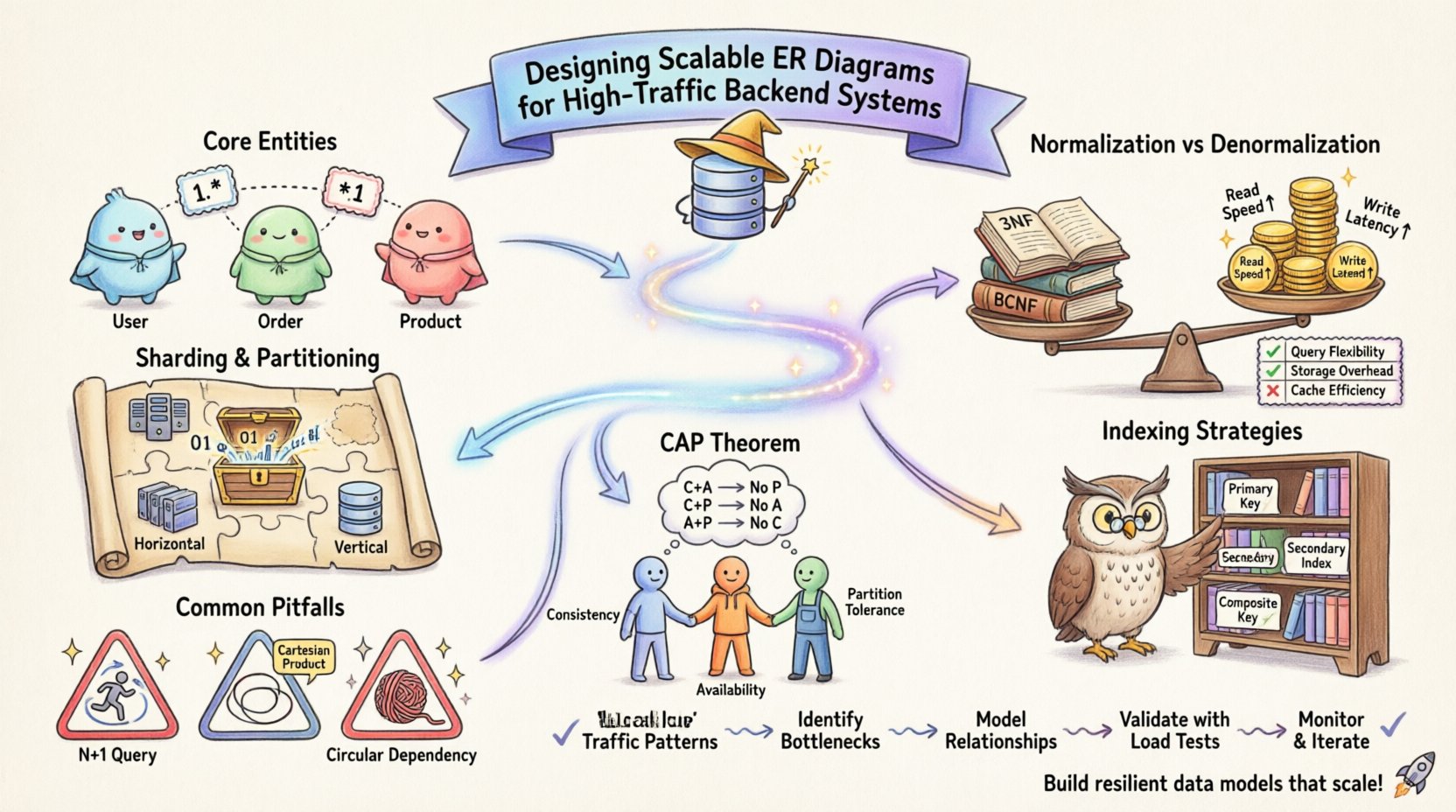
🏗️ Comprendiendo el modelado de relaciones de entidades a escala
La unidad fundamental de un diagrama ER es la entidad, que representa un objeto o concepto distinto dentro de tu sistema. En un entorno de bajo tráfico, la simplicidad suele reinar. Sin embargo, a medida que aumentan los volúmenes de transacciones, la complejidad de las interacciones entre entidades crece exponencialmente. Los sistemas de alta tráfico requieren un cambio de perspectiva, pasando de «¿cómo debería verse esta información?» a «¿cómo se desempeñará esta información bajo carga?».
- Identifica entidades principales: Determina qué objetos de datos se acceden con mayor frecuencia. Estos son tus rutas críticas.
- Analiza la cardinalidad: Define las relaciones entre entidades. Las relaciones uno a muchos, muchos a muchos y uno a uno tienen implicaciones de rendimiento diferentes.
- Granularidad de los atributos: Decide cuánto detalle almacenar dentro de un atributo. Atributos demasiado granulares pueden aumentar excesivamente el tamaño de las filas, mientras que atributos demasiado amplios pueden dificultar la especificidad de las consultas.
Al diseñar para escalar, la disposición física de los datos se vuelve tan importante como la estructura lógica. El ERD debe reflejar no solo la lógica de negocio, sino también las limitaciones operativas del motor de almacenamiento. Por ejemplo, algunos sistemas manejan el bloqueo a nivel de fila de forma diferente al bloqueo a nivel de página. Tu diagrama debería anticipar estas limitaciones minimizando los puntos de contención.
📊 Normalización frente a denormalización: el compromiso de rendimiento
La normalización es el proceso de organizar los datos para reducir la redundancia y mejorar la integridad. Aunque tradicionalmente se enseña como una práctica universal óptima, los sistemas de alta tráfico a menudo requieren un enfoque equilibrado. El cumplimiento estricto de la Tercera Forma Normal (3FN) puede introducir operaciones de unión excesivas. En un entorno distribuido o de alta concurrencia, las uniones entre múltiples tablas pueden convertirse en cuellos de botella significativos.
Por el contrario, la denormalización implica duplicar datos para reducir la necesidad de uniones. Esta estrategia mejora el rendimiento de lectura, pero complica las operaciones de escritura. Debes mantener la consistencia entre los campos duplicados, lo que añade lógica a tu capa de aplicación.
| Estrategia | Rendimiento de lectura | Rendimiento de escritura | Consistencia de los datos | Costo de almacenamiento |
|---|---|---|---|---|
| Normalización completa | Más bajo (varias uniones) | Más alto (escritura única) | Alta | Bajo |
| Denormalización parcial | Alta (menos uniones) | Moderada (actualización de duplicados) | Moderada | Moderada |
| Denormalización completa | Muy alto | Bajo (lógica compleja) | Bajo (requiere sincronización) | Alto |
Elegir el equilibrio adecuado depende de la relación entre lecturas y escrituras. Si su sistema es de lectura intensiva, como una fuente de contenido o una plataforma de noticias, la denormalización a menudo es necesaria. Si su sistema es de escritura intensiva, como un libro mayor de transacciones, la normalización ayuda a prevenir anomalías.
🌐 Estrategias para la optimización de lectura y escritura
Optimizar para alto tráfico implica técnicas específicas que influyen en la forma de su ERD. Estas estrategias se centran en reducir el tiempo necesario para recuperar o almacenar información.
1. Estrategias de caché reflejadas en el esquema
Al diseñar su modelo de datos, considere cómo se almacenará en caché la información. Las entidades con acceso frecuente deben estructurarse para permitir una serialización fácil. Evite almacenar grandes bloques de datos de longitud variable en tablas que se unen con frecuencia. En su lugar, almacene una clave de referencia y recupere el bloque por separado cuando sea necesario. Esto reduce la presión de memoria en la capa principal de caché.
2. Claves de particionado y fragmentación
A medida que los datos crecen, el almacenamiento en una sola tabla se vuelve ineficiente. La fragmentación divide los datos entre múltiples nodos. Su ERD debe definir claramente una clave de fragmentación. Esta clave determina cómo se distribuyen las filas. Si la clave de fragmentación se elige mal, puede terminar con particiones ‘calientes’, donde un nodo maneja significativamente más tráfico que los demás.
- Fragmentación horizontal: Divide las filas según una clave. El ERD debe mostrar cómo se distribuye la clave.
- Fragmentación vertical: Divide las columnas entre tablas. Útil para separar columnas pesadas (como registros) de los datos transaccionales principales.
🔗 Gestión de relaciones en datos particionados
Las relaciones son el pegamento que mantiene unida una base de datos, pero en un sistema distribuido, pueden convertirse en una fuente de latencia. Las claves foráneas garantizan la integridad referencial, pero en un entorno fragmentado, imponer estas restricciones entre nodos es costoso.
Gestión de relaciones muchos a muchos
Las relaciones muchos a muchos requieren una tabla de unión. En un escenario de alto tráfico, esta tabla puede convertirse en un cuello de botella. Si consulta con frecuencia, considere denormalizar la relación. En lugar de unir la tabla de unión, almacene directamente el ID de la relación en la entidad principal si la cardinalidad lo permite. Esto reduce la profundidad de la consulta.
Entidades que se refieren a sí mismas
Algunas entidades se refieren a sí mismas, como categorías o comentarios jerárquicos. Diseñe estas relaciones con cuidado. La recursión profunda en consultas puede agotar los recursos del sistema. Límite la profundidad de las cadenas de referencia en su lógica, o aplane la estructura cuando sea posible usando rutas materializadas.
🔍 Estrategias de indexación para el rendimiento
Un ERD define la estructura lógica, pero los índices definen la velocidad de recuperación física. Aunque el diagrama en sí no muestra índices, las decisiones de diseño afectan qué índices son viables.
- Claves primarias:En muchos sistemas están agrupadas, lo que significa que los datos están físicamente ordenados por esta clave. Elija una clave primaria que minimice la fragmentación y garantice una distribución equilibrada.
- Índices secundarios:Cada índice consume rendimiento de escritura. Añadir demasiados índices ralentiza las operaciones de inserción y actualización. Solo indexe columnas que se usen con frecuencia en cláusulas `WHERE`, `JOIN` o `ORDER BY`.
- Índices compuestos:Cuando se consultan múltiples columnas juntas, un índice compuesto puede ser más eficiente. El orden de las columnas en el índice importa y debe coincidir con los patrones de consulta más comunes.
⚖️ Consistencia frente a disponibilidad en esquemas distribuidos
La teoría de bases de datos a menudo discute el teorema CAP, que sugiere que un sistema solo puede garantizar dos de las tres propiedades: consistencia, disponibilidad y tolerancia a particiones. El diseño de tu ERD influye en cuál de estas propiedades priorizas.
Si priorizas la consistencia, diseñarás con claves foráneas estrictas y transacciones ACID. Esto garantiza la integridad de los datos, pero podría introducir latencia durante particiones de red. Si priorizas la disponibilidad, podrías relajar las restricciones, permitiendo inconsistencias temporales. En este caso, tu ERD debe apoyar patrones de consistencia eventual, como tener una columna de “versión” o “estado” para rastrear el estado de los datos.
🔄 Evolución y versionado de esquemas
Los requisitos de software cambian. El esquema de la base de datos debe evolucionar sin causar tiempos de inactividad. En sistemas de alta carga, no puedes simplemente eliminar y recrear tablas. Las estrategias de migración deben integrarse en el proceso de diseño del ERD.
- Compatibilidad hacia atrás:Al agregar una columna, hazla nula inicialmente. Esto permite que el código antiguo siga funcionando mientras el código nuevo llena los datos.
- Tipos ampliables:Evita los tipos de longitud fija cuando sea posible. Usa cadenas de longitud variable o campos JSON para atributos que puedan cambiar de estructura con el tiempo.
- Eliminaciones lógicas:En lugar de eliminar físicamente filas, marca las como inactivas. Esto preserva la integridad referencial para los datos históricos y evita operaciones de eliminación en cascada que pueden bloquear grandes porciones de la tabla.
🛑 Obstáculos estructurales comunes
Incluso arquitectos experimentados se encuentran con obstáculos al escalar. Estar al tanto de estos problemas comunes puede ahorrar mucho tiempo durante la fase de diseño.
1. El problema de consultas N+1
Esto ocurre cuando una aplicación recupera una lista de registros y luego ejecuta una consulta separada para cada registro para obtener datos relacionados. En tu ERD, identifica relaciones que se accedan frecuentemente juntas. Si anticipas que recuperarás datos relacionados con frecuencia, considera denormalizar o crear vistas específicas de lectura.
2. Productos cartesianos
Cuando se unen múltiples tablas grandes sin filtrado adecuado, el conjunto de resultados puede crecer exponencialmente. Asegúrate de que tu ERD imponga restricciones que limiten el tamaño potencial de los resultados de unión. Usa filtros en claves foráneas para restringir el alcance de las relaciones.
3. Dependencias circulares
Las entidades no deben depender unas de otras en un bucle. Por ejemplo, la entidad A necesita la entidad B, y la entidad B necesita la entidad A para inicializarse. Esto crea una situación de bloqueo durante el arranque o la carga de datos. Rompe estos ciclos introduciendo una entidad intermedia o inicializando los datos en un orden específico.
📝 Mantenimiento y monitoreo
El diseño no es un evento único. Una vez que el sistema está en funcionamiento, debes monitorear la salud de tu estructura de datos. Las métricas de rendimiento deben guiar los ajustes futuros del ERD.
- Análisis de consultas:Revisa regularmente los registros de consultas lentas. Si una unión específica es consistentemente lenta, revisa el ERD para ver si la relación puede optimizarse.
- Verificaciones de fragmentación:Con el tiempo, las eliminaciones y actualizaciones pueden fragmentar el almacenamiento. Planifica ventanas de mantenimiento donde se reconstruyan índices o se optimicen tablas.
- Planificación de capacidad:A medida que los datos crecen, cambian los requisitos de almacenamiento. Estima la tasa de crecimiento de tus tablas más grandes y planifica el particionamiento o shardización antes de alcanzar los límites de capacidad.
🛠️ Aplicación práctica: un flujo de trabajo escalable
Para implementar estos principios, sigue un flujo de trabajo estructurado al crear tu diagrama.
- Recopilación de requisitos: Defina la proporción de lectura/escritura y los patrones de tráfico esperados.
- Modelado lógico: Cree el diagrama ERD centrado en entidades y relaciones empresariales, sin preocuparse por las restricciones físicas.
- Modelado físico: Traduzca el modelo lógico en un esquema físico. Agregue índices, defina tipos de datos y considere estrategias de partición.
- Revisión y validación: Simule consultas de alto volumen contra el modelo. Identifique cuellos de botella potenciales en combinaciones o bloqueos.
- Documentación: Documente la justificación detrás de las decisiones de diseño. Esto ayuda a los desarrolladores futuros a comprender por qué se eligió un nivel específico de normalización.
🔮 Futuroseguridad de tu arquitectura
La tecnología evoluciona rápidamente. Lo que funciona hoy puede no funcionar dentro de cinco años. Diseñe con flexibilidad en mente. Evite vincular su esquema demasiado estrechamente a una característica específica del motor de almacenamiento que podría quedar obsoleta. Enfóquese en las relaciones lógicas y las reglas de integridad de datos, ya que estas permanecen constantes incluso cuando cambia la tecnología subyacente.
Siguiendo estas pautas, crea un modelo de datos que no solo sea funcional para las necesidades actuales, sino también lo suficientemente resistente para manejar la imprevisibilidad de entornos de alto tráfico. El objetivo es construir un sistema que se desempeñe de manera consistente, se escale horizontalmente y permanezca mantenible con el tiempo.

