











एक टिकाऊ बैकएंड आर्किटेक्चर बनाने के लिए केवल कुशल कोड लिखने से ज्यादा चाहिए; इसमें दबाव के तहत डेटा के संरचना, भंडारण और प्राप्ति के बारे में आधारभूत समझ की आवश्यकता होती है। इस ढांचे के केंद्र में एंटिटी रिलेशनशिप डायग्राम (ईआरडी) है। जबकि अक्सर इसे प्रारंभिक योजना चरण के दौरान बनाए गए एक स्थिर नक्शे के रूप में लिया जाता है, एक अच्छी तरह से डिजाइन किया गया ईआरडी उच्च ट्रैफिक सिस्टम की गतिशील रीढ़ की हड्डी के रूप में कार्य करता है। जब ट्रैफिक बढ़ता है, तो डेटाबेस स्कीमा प्रदर्शन, लेटेंसी और उपलब्धता को निर्धारित करता है। खराब ढंग से संरचित मॉडल के कारण श्रृंखलाबद्ध विफलताएं हो सकती हैं, जबकि स्केलेबल डिजाइन वृद्धि को बिना किसी दिक्कत के स्वीकार करता है।
यह गाइड भारी लोड को सहन करने वाले ईआर डायग्राम बनाने के तकनीकी बातचीत का अध्ययन करता है। हम बुनियादी नॉर्मलाइजेशन से आगे बढ़ेंगे और वितरित वातावरणों में संबंधों, सीमाओं और भौतिक भंडारण रणनीतियों के बीच बातचीत का अध्ययन करेंगे। चाहे आप मिलियन लोगों के साथ एक साथ उपयोग करने वाले उपयोगकर्ताओं के लिए डिजाइन कर रहे हों या बस भविष्य के विस्तार की योजना बना रहे हों, यहां बताए गए सिद्धांत टिकाऊ डेटा मॉडलिंग के लिए एक ढांचा प्रदान करते हैं।
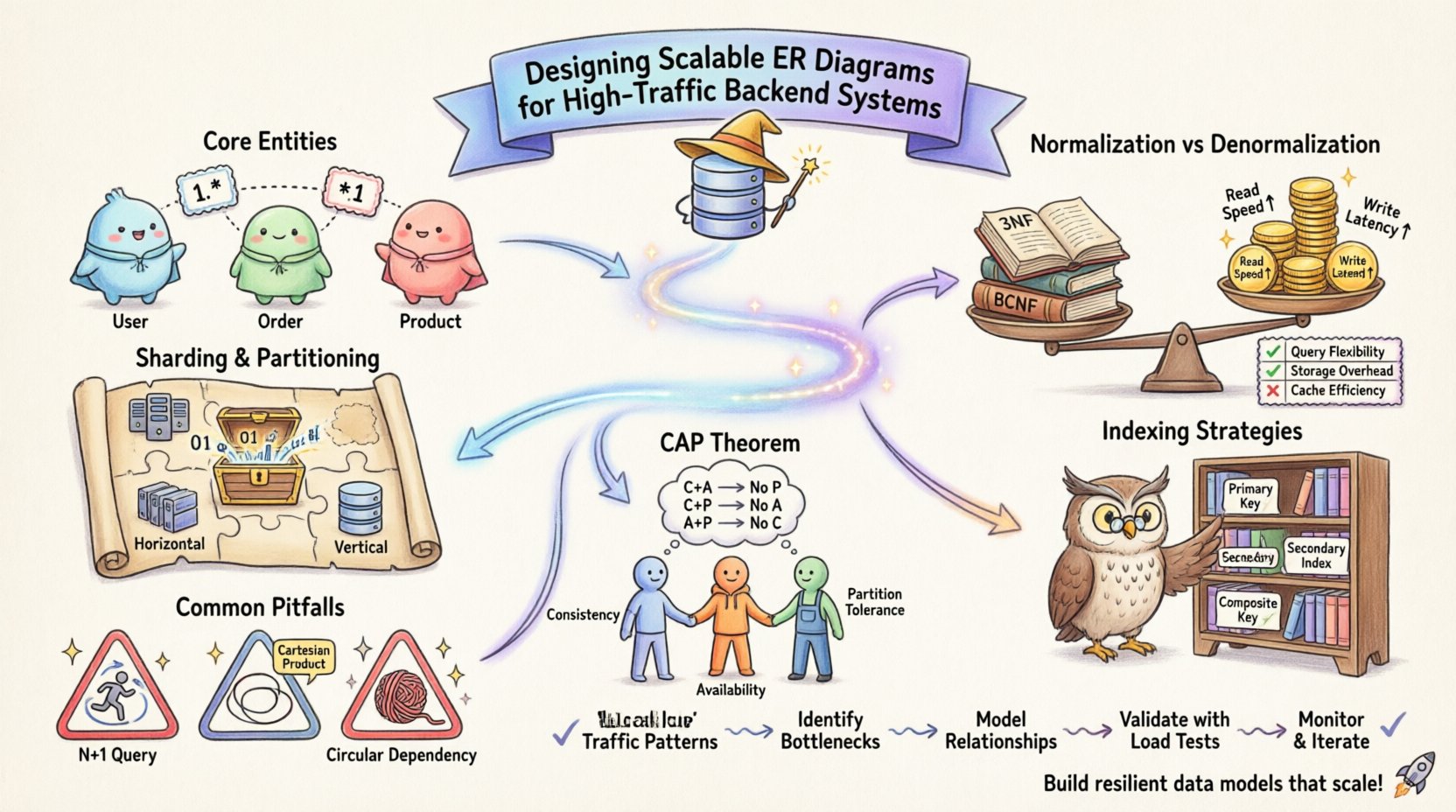
🏗️ स्केल पर एंटिटी रिलेशनशिप मॉडलिंग को समझना
ईआर डायग्राम की मूल इकाई एंटिटी है, जो आपके सिस्टम के भीतर एक अलग वस्तु या अवधारणा का प्रतिनिधित्व करती है। कम ट्रैफिक वाले वातावरण में, सरलता अक्सर शीर्ष पर होती है। हालांकि, जैसे-जैसे लेनदेन की मात्रा बढ़ती है, एंटिटी के बीच बातचीत की जटिलता घातीय रूप से बढ़ती है। उच्च ट्रैफिक सिस्टम में दृष्टिकोण में बदलाव की आवश्यकता होती है – “यह डेटा कैसा दिखना चाहिए?” से “यह डेटा लोड के तहत कैसे प्रदर्शन करेगा?” की ओर।
- मुख्य एंटिटी की पहचान करें:यह तय करें कि कौन सी डेटा वस्तुएं सबसे अधिक बार तक पहुंची जाती हैं। ये आपके हॉट पाथ हैं।
- कार्डिनैलिटी का विश्लेषण करें:एंटिटी के बीच संबंधों को परिभाषित करें। एक से बहुत, बहुत से बहुत, और एक से एक संबंध प्रत्येक के अलग-अलग प्रदर्शन प्रभाव होते हैं।
- एट्रिब्यूट विस्तार:यह तय करें कि एक एट्रिब्यूट में कितना विस्तार भंडारित करना है। अत्यधिक विस्तृत एट्रिब्यूट रो के आकार को बढ़ा सकते हैं, जबकि अत्यधिक व्यापक एट्रिब्यूट प्रश्न की विशिष्टता को बाधित कर सकते हैं।
स्केल के लिए डिजाइन करते समय, डेटा की भौतिक व्यवस्था तर्कसंगत संरचना के बराबर महत्वपूर्ण हो जाती है। ईआरडी को व्यावसायिक तर्क के साथ-साथ स्टोरेज इंजन की संचालन सीमाओं को भी दर्शाना चाहिए। उदाहरण के लिए, कुछ प्रणालियां रो-लेवल लॉकिंग को पेज-लेवल लॉकिंग के विपरीत तरीके से संभालती हैं। आपके डायग्राम को इन सीमाओं की अनुमान लगाने के लिए लड़ाई के बिंदुओं को कम करना चाहिए।
📊 नॉर्मलाइजेशन बनाम डीनॉर्मलाइजेशन: प्रदर्शन का व्यापार बदलाव
नॉर्मलाइजेशन डेटा को व्यवस्थित करने की प्रक्रिया है जिससे अतिरेक को कम किया जाता है और अखंडता में सुधार होता है। जबकि पारंपरिक रूप से इसे एक सार्वभौमिक बेस्ट प्रैक्टिस के रूप में पढ़ाया जाता है, उच्च ट्रैफिक सिस्टम को अक्सर संतुलित दृष्टिकोण की आवश्यकता होती है। तृतीय नॉर्मल फॉर्म (3NF) के सख्त पालन से अत्यधिक जॉइन ऑपरेशन आ सकते हैं। वितरित या उच्च समानांतरता वाले वातावरण में, कई टेबलों के बीच जॉइन बड़े बॉटलनेक के रूप में बन सकते हैं।
विपरीत रूप से, डीनॉर्मलाइजेशन जॉइन की आवश्यकता को कम करने के लिए डेटा की प्रतिलिपि बनाने की प्रक्रिया है। इस रणनीति से पढ़ने के प्रदर्शन में सुधार होता है, लेकिन लेखन ऑपरेशन को जटिल बना देता है। आपको प्रतिलिपि वाले क्षेत्रों में संगतता बनाए रखनी होगी, जिससे आपके एप्लीकेशन लेयर में अतिरिक्त तर्क जोड़ना पड़ता है।
| रणनीति | पढ़ने का प्रदर्शन | लेखन प्रदर्शन | डेटा संगतता | स्टोरेज लागत |
|---|---|---|---|---|
| पूर्ण नॉर्मलाइजेशन | कम (बहुत जॉइन) | अधिक (एकल लेखन) | उच्च | कम |
| आंशिक डीनॉर्मलाइजेशन | उच्च (कम जॉइन) | मध्यम (अपडेट प्रतिलिपि) | मध्यम | मध्यम |
| पूर्ण अनियमितता | बहुत अधिक | कम (जटिल तर्क) | कम (सिंक करने की आवश्यकता है) | उच्च |
सही संतुलन चुनना आपके पढ़ने-लिखने के अनुपात पर निर्भर करता है। यदि आपका सिस्टम पढ़ने पर अधिक निर्भर है, जैसे कि कंटेंट फीड या समाचार प्लेटफॉर्म, तो अनियमितता आमतौर पर आवश्यक होती है। यदि आपका सिस्टम लिखने पर अधिक निर्भर है, जैसे कि लेनदेन लेजर, तो नियमितता असामान्यताओं को रोकने में मदद करती है।
🌐 पढ़ने और लिखने अनुकूलन के रणनीतियाँ
उच्च ट्रैफिक के लिए अनुकूलन करने में विशिष्ट तकनीकों का उपयोग होता है जो आपके एरडी के आकार को प्रभावित करती हैं। इन रणनीतियों का ध्यान जानकारी खोजने या संग्रहीत करने में लगने वाले समय को कम करने पर केंद्रित होता है।
1. स्कीमा में प्रतिबिंबित कैशिंग रणनीतियाँ
जब आप अपने डेटा मॉडल को डिज़ाइन कर रहे हों, तो यह विचार करें कि डेटा कैसे कैश किया जाएगा। अक्सर एक्सेस किए जाने वाले एंटिटीज को आसान सीरियलाइज़ेशन के लिए बनाया जाना चाहिए। अक्सर जोड़े जाने वाली टेबलों में बड़े, चर लंबाई वाले ब्लॉब स्टोर करने से बचें। इसके बजाय, एक संदर्भ कुंजी स्टोर करें और जब आवश्यकता हो तो ब्लॉब को अलग से लाएं। इससे मुख्य कैश परत पर मेमोरी का दबाव कम होता है।
2. पार्टीशनिंग और शार्डिंग कुंजियाँ
जैसे-जैसे डेटा बढ़ता है, एकल टेबल स्टोरेज अक्षम हो जाती है। शार्डिंग डेटा को कई नोड्स पर विभाजित करती है। आपके एरडी में शार्ड कुंजी को स्पष्ट रूप से परिभाषित करना आवश्यक है। यह कुंजी निर्धारित करती है कि पंक्तियाँ कैसे वितरित की जाती हैं। यदि शार्ड कुंजी खराब तरीके से चुनी जाती है, तो आपको ‘हॉट पार्टीशन’ में समाप्त होना पड़ सकता है, जहाँ एक नोड अन्य नोड्स की तुलना में काफी अधिक ट्रैफिक संभालता है।
- क्षैतिज शार्डिंग: एक कुंजी के आधार पर पंक्तियों को विभाजित करता है। एरडी में यह दिखाना आवश्यक है कि कुंजी कैसे वितरित की जाती है।
- उर्ध्वाधर शार्डिंग: कॉलम को टेबलों के बीच विभाजित करता है। भारी कॉलम (जैसे लॉग) को मुख्य लेनदेन डेटा से अलग करने के लिए उपयोगी है।
🔗 पार्टीशन किए गए डेटा में संबंधों का प्रबंधन
संबंध डेटाबेस को एक साथ रखने वाली चिपचिपाई हैं, लेकिन एक वितरित प्रणाली में, वे लेटेंसी का कारण बन सकते हैं। विदेशी कुंजियाँ संदर्भी अखंडता को बनाए रखती हैं, लेकिन शार्डेड वातावरण में नोड्स के बीच इन नियमों को लागू करना महंगा होता है।
बहु-से-बहु संबंधों का प्रबंधन
बहु-से-बहु संबंधों के लिए एक जंक्शन टेबल की आवश्यकता होती है। उच्च ट्रैफिक स्थिति में, इस टेबल को एक बॉटलनेक बन सकती है। यदि आप अक्सर प्रश्न करते हैं, तो संबंध को अनियमित बनाने के बारे में सोचें। जंक्शन टेबल को जोड़ने के बजाय, यदि कार्डिनैलिटी अनुमति देती है, तो संबंध कुंजी को मूल एंटिटी पर सीधे स्टोर करें। इससे प्रश्न की गहराई कम होती है।
स्व-संदर्भित एंटिटीज
कुछ एंटिटीज खुद को संदर्भित करती हैं, जैसे कि श्रेणियाँ या हायरार्किकल कमेंट्स। इन संबंधों को ध्यान से डिज़ाइन करें। प्रश्नों में गहरी रिकर्सन सिस्टम संसाधनों को खत्म कर सकती है। अपनी तर्क में स्व-संदर्भित श्रृंखला की गहराई को सीमित करें, या संभव हो तो सामग्री रूपांतरित मार्गों का उपयोग करके संरचना को समतल करें।
🔍 प्रदर्शन के लिए इंडेक्सिंग रणनीतियाँ
एरडी तार्किक संरचना को परिभाषित करता है, लेकिन इंडेक्स भौतिक प्राप्ति गति को परिभाषित करते हैं। चाहे आरेख में सीधे इंडेक्स न दिखाए जाएँ, डिज़ाइन निर्णय यह निर्धारित करते हैं कि कौन-से इंडेक्स व्यवहार्य हैं।
- मुख्य कुंजियाँ:बहुत सी प्रणालियों में इन्हें समूहित किया जाता है, जिसका अर्थ है कि डेटा इस कुंजी द्वारा भौतिक रूप से क्रमबद्ध होता है। एक मुख्य कुंजी चुनें जो फ्रैगमेंटेशन को न्यूनतम करे और समान वितरण सुनिश्चित करे।
- द्वितीयक इंडेक्स:प्रत्येक इंडेक्स लेखन प्रदर्शन का उपभोग करता है। बहुत सारे इंडेक्स जोड़ने से इन्सर्ट और अपडेट ऑपरेशन धीमे हो जाते हैं। केवल उन कॉलम्स को इंडेक्स करें जो `WHERE`, `JOIN`, या `ORDER BY` क्लॉज में अक्सर उपयोग किए जाते हैं।
- संयुक्त इंडेक्स:जब कई कॉलम एक साथ प्रश्न किए जाते हैं, तो एक संयुक्त इंडेक्स अधिक कुशल हो सकता है। इंडेक्स में कॉलम के क्रम का महत्व होता है और यह सबसे आम प्रश्न पैटर्न के अनुरूप होना चाहिए।
⚖️ वितरित स्कीमा में सुसंगतता बनाम उपलब्धता
डेटाबेस सिद्धांत अक्सर CAP प्रमेय की चर्चा करता है, जो बताता है कि एक प्रणाली केवल तीन में से दो गुणों की गारंटी कर सकती है: सुसंगतता, उपलब्धता और विभाजन सहिष्णुता। आपके एरडी डिजाइन का उन गुणों में से किसे प्राथमिकता देने के निर्णय पर प्रभाव पड़ता है।
यदि आप सुसंगतता को प्राथमिकता देते हैं, तो आप सख्त विदेशी कुंजियों और ACID लेनदेन के साथ डिजाइन करेंगे। इससे डेटा अखंडता सुनिश्चित होती है, लेकिन नेटवर्क विभाजन के दौरान लेटेंसी आ सकती है। यदि आप उपलब्धता को प्राथमिकता देते हैं, तो आप सीमाओं को ढीला कर सकते हैं, जिससे अस्थायी असुसंगतता की अनुमति मिल सकती है। इस मामले में, आपके एरडी में अंततः सुसंगतता पैटर्न का समर्थन करना चाहिए, जैसे कि डेटा के स्थिति को ट्रैक करने के लिए एक “संस्करण” या “स्थिति” कॉलम हो।
🔄 स्कीमा विकास और संस्करण प्रबंधन
सॉफ्टवेयर आवश्यकताएं बदलती हैं। डेटाबेस स्कीमा को बिना डाउनटाइम के विकसित करना होगा। उच्च ट्रैफिक वाली प्रणालियों में, आप सिर्फ टेबल को हटाकर फिर से बना नहीं सकते। माइग्रेशन रणनीतियों को एरडी डिजाइन प्रक्रिया में एम्बेड करना होगा।
- पीछे की ओर संगतता: जब कोई कॉलम जोड़ रहे हों, तो उसे शुरू में nullable बनाएं। इससे पुराने कोड को जारी रखने की अनुमति मिलती है, जबकि नए कोड डेटा को भरता है।
- विस्तारयोग्य प्रकार: जहां संभव हो, निश्चित लंबाई वाले प्रकार से बचें। समय के साथ संरचना बदल सकने वाले लक्षणों के लिए चर लंबाई वाले स्ट्रिंग या JSON फ़ील्ड का उपयोग करें।
- तार्किक हटाना: भौतिक रूप से पंक्तियों को हटाने के बजाय, उन्हें निष्क्रिय चिह्नित करें। इससे ऐतिहासिक डेटा के लिए संदर्भात्मक अखंडता बनी रहती है और बड़े हिस्सों को ताला लगाने वाले कैस्केडिंग हटाने के ऑपरेशन से बचा जा सकता है।
🛑 सामान्य संरचनात्मक फंदे
यहां तक कि अनुभवी वास्तुकार भी स्केलिंग के दौरान फंदों में फंसते हैं। इन सामान्य समस्याओं के बारे में जागरूक रहने से डिजाइन चरण में महत्वपूर्ण समय बच सकता है।
1. एन+1 क्वेरी समस्या
यह तब होता है जब एक एप्लिकेशन रिकॉर्ड्स की सूची लेती है और फिर प्रत्येक रिकॉर्ड के लिए अलग से क्वेरी चलाती है ताकि संबंधित डेटा प्राप्त कर सके। अपने एरडी में उन संबंधों की पहचान करें जिन्हें अक्सर एक साथ एक्सेस किया जाता है। यदि आप अक्सर संबंधित डेटा प्राप्त करने की उम्मीद करते हैं, तो डेनॉर्मलाइज़ करने या विशिष्ट पठन-मॉडल दृश्य बनाने के बारे में सोचें।
2. कार्टेशियन उत्पाद
जब बड़ी टेबलों के बीच बिना उचित फ़िल्टरिंग के जॉइन किया जाता है, तो परिणाम सेट घातीय रूप से बढ़ सकता है। सुनिश्चित करें कि आपके एरडी में ऐसी सीमाएं हैं जो जॉइन परिणामों के संभावित आकार को सीमित करती हैं। रिलेशनशिप के दायरे को सीमित करने के लिए विदेशी कुंजियों पर फ़िल्टर का उपयोग करें।
3. चक्रीय निर्भरता
एंटिटीज को एक दूसरे पर एक चक्र में निर्भर नहीं होना चाहिए। उदाहरण के लिए, एंटिटी A को एंटिटी B की आवश्यकता है, और एंटिटी B को एंटिटी A की आवश्यकता है इनिशियलाइज़ करने के लिए। इससे स्टार्टअप या डेटा लोडिंग के दौरान डेडलॉक स्थिति बनती है। इन चक्रों को एक मध्यस्थ एंटिटी जोड़कर या डेटा को एक विशिष्ट क्रम में इनिशियलाइज़ करके तोड़ें।
📝 रखरखाव और मॉनिटरिंग
डिजाइन एक बार का घटना नहीं है। जब प्रणाली लाइव हो जाती है, तो आपको अपनी डेटा संरचना के स्वास्थ्य को मॉनिटर करना होगा। प्रदर्शन मापदंड भविष्य के एरडी समायोजनों को दिशा देने चाहिए।
- क्वेरी विश्लेषण: नियमित रूप से धीमी क्वेरी लॉग की समीक्षा करें। यदि कोई विशिष्ट जॉइन लगातार धीमी है, तो एरडी को दोबारा देखें ताकि देख सकें कि क्या संबंध को अनुकूलित किया जा सकता है।
- फ्रैगमेंटेशन जांच: समय के साथ, हटाने और अपडेट करने से स्टोरेज फ्रैगमेंट हो सकता है। ऐसे रखरखाव के खंडों की योजना बनाएं जहां इंडेक्स को फिर से बनाया जाए या टेबल को अनुकूलित किया जाए।
- क्षमता योजना: जैसे-जैसे डेटा बढ़ता है, स्टोरेज की आवश्यकताएं बदलती हैं। अपनी सबसे बड़ी टेबलों के वृद्धि दर का अनुमान लगाएं और क्षमता सीमाओं तक पहुंचने से पहले शार्डिंग या पार्टीशनिंग की योजना बनाएं।
🛠️ व्यावहारिक अनुप्रयोग: एक स्केलेबल वर्कफ्लो
इन सिद्धांतों को लागू करने के लिए, अपने डायग्राम बनाते समय एक संरचित कार्य प्रवाह का पालन करें।
- आवश्यकता संग्रह: पढ़ने/लिखने के अनुपात और अपेक्षित ट्रैफिक पैटर्न को परिभाषित करें।
- तार्किक मॉडलिंग:भौतिक सीमाओं के बारे में चिंता किए बिना व्यापार इकाइयों और संबंधों पर ध्यान केंद्रित करके एरडी बनाएं।
- भौतिक मॉडलिंग:तार्किक मॉडल को भौतिक स्कीमा में बदलें। सूचकांक जोड़ें, डेटा प्रकार परिभाषित करें, और विभाजन रणनीतियों पर विचार करें।
- समीक्षा और मान्यता:मॉडल के खिलाफ उच्च भार वाले प्रश्नों का सिमुलेशन करें। जॉइन या लॉकिंग में संभावित बफलेट निर्धारित करें।
- दस्तावेज़ीकरण:डिज़ाइन चयनों के पीछे के तर्क को दस्तावेज़ करें। यह भविष्य के विकासकर्ताओं को समझने में मदद करता है कि किसी विशिष्ट सामान्यीकरण स्तर का चयन क्यों किया गया।
🔮 अपनी आर्किटेक्चर को भविष्य के लिए सुरक्षित बनाएं
तकनीक तेजी से विकसित होती है। आज काम करने वाला कुछ पांच साल बाद काम नहीं कर सकता है। लचीलेपन के साथ डिज़ाइन करें। उस विशिष्ट स्टोरेज इंजन फीचर से अपने स्कीमा को बहुत निकटता से जोड़ने से बचें जो अप्रचलित हो सकता है। तार्किक संबंधों और डेटा अखंडता नियमों पर ध्यान केंद्रित करें, क्योंकि ये तकनीक में बदलाव आने पर भी स्थिर रहते हैं।
इन दिशानिर्देशों का पालन करने से आप एक डेटा मॉडल बनाते हैं जो केवल वर्तमान आवश्यकताओं के लिए कार्यात्मक होता है बल्कि उच्च ट्रैफिक वातावरण की अनिश्चितता को संभालने के लिए पर्याप्त लचीला भी होता है। लक्ष्य एक ऐसी प्रणाली बनाना है जो निरंतर रूप से कार्य करे, क्षैतिज रूप से स्केल हो, और समय के साथ बनाए रखने योग्य बनी रहे।

