











O design de banco de dados é a base de qualquer aplicação robusta. Ao construir um Diagrama de Relacionamento de Entidades (ERD), duas forças opostas moldam o esquema: normalização e denormalização. Compreender quando aplicar cada estratégia determina a saúde a longo prazo, o desempenho e a manutenibilidade da sua infraestrutura de dados. Este guia aborda as perguntas mais críticas sobre esses conceitos, fornecendo um caminho claro para projetar estruturas de banco de dados eficientes sem depender de ferramentas de software específicas. 🛠️
A integridade dos dados e a velocidade das consultas frequentemente puxam em direções opostas. A normalização prioriza a integridade reduzindo a redundância. A denormalização prioriza a velocidade introduzindo redundância controlada. Navegar nesse equilíbrio exige um profundo entendimento da teoria relacional e dos requisitos práticos de desempenho. Vamos explorar os detalhes técnicos por meio de uma série de perguntas e respostas direcionadas. 📊
Compreendendo os Fundamentos: Com O Que Estamos Lidando? 🔍
Antes de mergulhar em cenários específicos, precisamos definir os mecanismos centrais em jogo no seu design de ERD.
O que é Normalização? 🔄
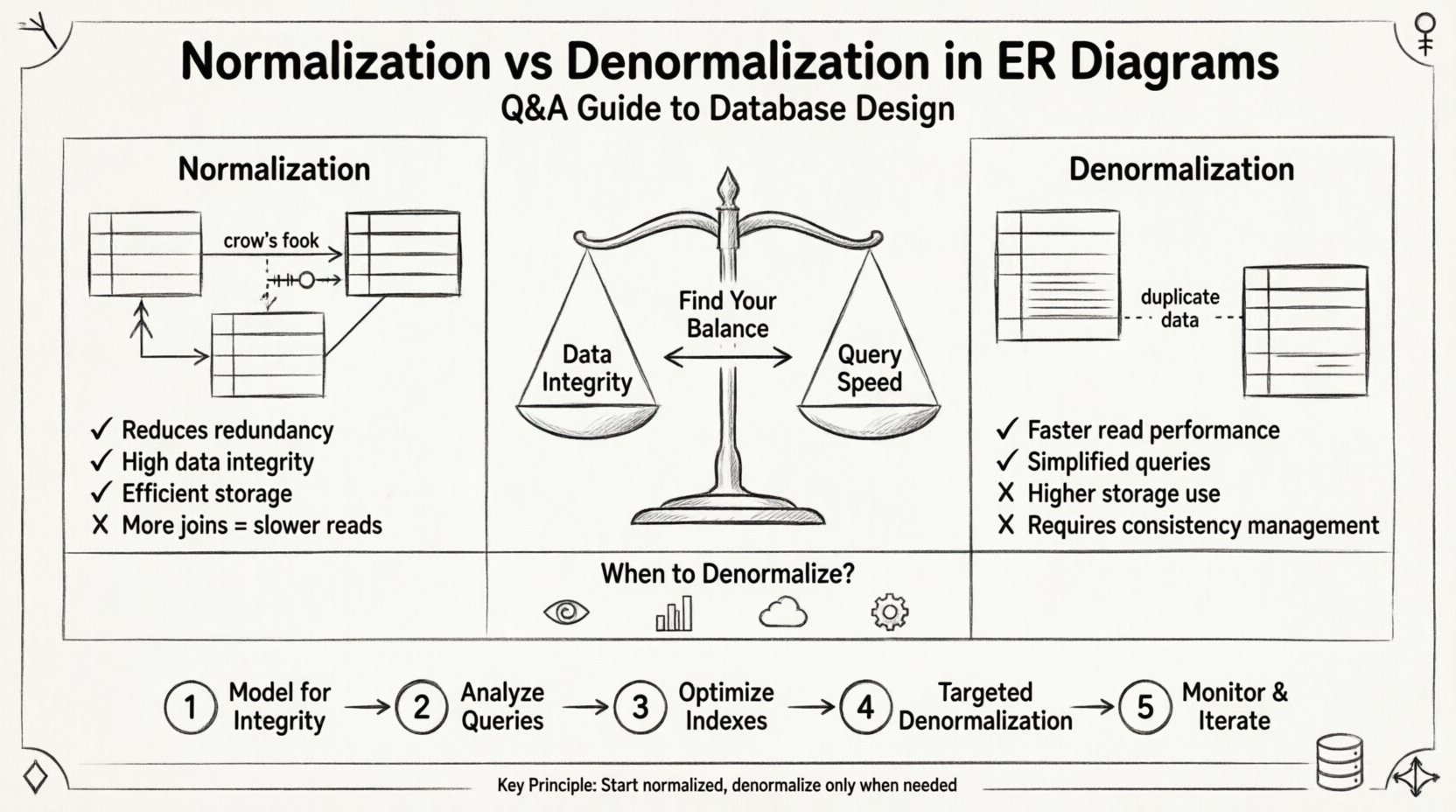
A normalização é um processo sistemático de organização de dados em um banco de dados para reduzir a redundância e melhorar a integridade dos dados. Envolve dividir tabelas grandes em tabelas menores, logicamente conectadas, e definir relacionamentos entre elas. O objetivo é garantir que cada peça de dados seja armazenada em apenas um local.
- Objetivo: Eliminar dados duplicados e garantir que as dependências façam sentido.
- Benefício: Simplifica a manutenção dos dados e reduz os requisitos de armazenamento.
- Custo: Aumenta a complexidade das consultas devido à necessidade de junções (joins).
A normalização é geralmente alcançada por meio de uma série de estágios conhecidos como Formas Normais. Cada forma constrói sobre a anterior, abordando tipos específicos de anomalias.
O que é Denormalização? ⚖️
A denormalização é a introdução intencional de redundância em um banco de dados normalizado. Isso é feito para otimizar o desempenho de leitura, especificamente em cenários onde a velocidade das consultas é mais crítica do que a velocidade de gravação. Envolve a fusão de tabelas ou a adição de colunas redundantes para evitar operações de junção (join) dispendiosas.
- Objetivo: Reduzir o número de junções necessárias para consultas complexas.
- Benefício: Operações de leitura mais rápidas e lógica de consulta simplificada.
- Custo: Uso aumentado de armazenamento e maior risco de inconsistência de dados.
P&R: Aprofundamento na Normalização e no Design de ERD 📝
Essas perguntas abordam os pontos de atrito mais comuns encontrados ao projetar esquemas relacionais. Elas cobrem a transição da teoria para a implementação prática.
P1: Preciso normalizar tudo até a 3FN? 🤷♂️
A resposta curta é não. Embora a Terceira Forma Normal (3FN) seja uma referência padrão para muitos aplicativos, não é uma regra rígida para todos os cenários. Normalizar até a 3FN elimina dependências transitivas, garantindo que atributos não-chave dependam apenas da chave primária. No entanto, alcançar formas superiores como a Forma Normal de Boyce-Codd (BCNF) ou a Quarta Forma Normal (4FN) pode, às vezes, complicar o esquema sem oferecer benefícios significativos.
Considere as trade-offs:
- 3FN: Boa para sistemas transacionais de propósito geral onde a integridade dos dados é fundamental.
- 4FN/5FN: Muitas vezes exagerado, a menos que você esteja lidando com dependências complexas de múltiplos valores ou dependências de junção.
- Abordagem Prática: Projete para a 3FN primeiro. Avalie gargalos de desempenho antes de considerar a desnormalização ou uma normalização adicional.
Q2: Como a normalização afeta o desempenho das consultas? 🐢
A normalização afeta o desempenho principalmente pela necessidade de junções. Quando os dados estão espalhados por várias tabelas, recuperar um registro completo exige que o motor do banco de dados vincule essas tabelas. Esse processo consome recursos de CPU e memória.
Fatores-chave que influenciam o desempenho incluem:
- Complexidade da Junção:Mais tabelas significam mais condições de junção para avaliar.
- Indexação:Chaves estrangeiras devem ser indexadas para acelerar as junções. Sem indexação adequada, a normalização pode levar a uma degradação severa do desempenho.
- Volume de Dados:À medida que o conjunto de dados cresce, o custo de varredura e junção aumenta significativamente.
Em aplicações com leituras intensivas, esse sobrecarga pode se tornar um gargalo. Em aplicações com escritas intensivas, a sobrecarga geralmente é negligenciável em comparação com o benefício de reduzir anomalias de atualização.
Q3: Quando é apropriado realizar a desnormalização? ⚙️
A desnormalização não deve ser o estado padrão. É uma medida corretiva aplicada após identificar problemas específicos de desempenho. Você deve considerar a desnormalização em situações a seguir:
- Cargas de trabalho com leituras intensivas:Se o sistema processa milhares de leituras para cada escrita, o custo das junções pode superar o custo de armazenamento.
- Painéis de Relatórios:Consultas analíticas complexas frequentemente se beneficiam de dados pré-juntados armazenados em tabelas amplas.
- Camadas de Cache:Às vezes, a desnormalização é implementada em uma camada de cache em vez do motor de armazenamento principal.
- Restrições Herdadas:Engines de banco de dados mais antigas ou limitações específicas de hardware podem ter dificuldades com junções complexas.
Q4: Como gerencio a consistência dos dados durante a desnormalização? 🛡️
Introduzir redundância cria o risco de inconsistência de dados. Se você armazena o nome de um cliente em ambas as tabelas Pedidos e a tabela Clientes tabela, atualizar o nome na tabela Clientes a tabela requer uma atualização em cascata para o Pedidos tabela.
Estratégias para manter a consistência incluem:
- Lógica do Aplicativo: Certifique-se de que o código da aplicação atualize todos os campos redundantes em uma única transação.
- Gatilhos do Banco de Dados:Use gatilhos para sincronizar automaticamente colunas redundantes quando os dados de origem forem alterados.
- Reconciliação Periódica:Execute trabalhos agendados para auditar e corrigir inconsistências em dados desnormalizados.
- Especialização de Réplicas de Leitura:Mantenha o banco de dados principal totalmente normalizado e use uma cópia desnormalizada para relatórios.
P&D: Cenários Avançados e Compromissos ⚖️
Além dos fundamentos, desafios arquitetônicos específicos surgem ao escalar sistemas. Essas perguntas abordam essas nuances.
P5: Posso misturar tabelas normalizadas e desnormalizadas na mesma ERD? 🧩
Sim, modelos híbridos são comuns em ambientes de produção. É prática padrão manter um esquema normalizado central para a integridade transacional, enquanto se criam visualizações desnormalizadas ou tabelas de resumo para casos de uso específicos.
Por exemplo:
- Tabelas Principais:Mantenha usuários, produtos e pedidos na 3FN para garantir registros financeiros precisos.
- Tabelas de Relatórios:Crie uma tabela desnormalizada que agregue totais de pedidos e detalhes do cliente para renderização rápida de painéis.
- Visualizações:Use visualizações SQL para apresentar uma estrutura desnormalizada às aplicações sem duplicar fisicamente os dados.
P6: A desnormalização viola a teoria de banco de dados? 📚
Teoricamente, sim. A teoria relacional defende a normalização para minimizar anomalias. No entanto, a engenharia prática frequentemente exige flexibilizar essas regras para atender aos SLAs de desempenho. A violação é intencional e calculada. Desde que a redundância seja gerenciada e documentada, o projeto permanece válido para sua finalidade pretendida.
P7: Como o indexamento interage com a normalização? 🔖
O indexamento é a principal ferramenta para mitigar o custo de desempenho da normalização. Quando você normaliza, cria chaves estrangeiras. Essas chaves estrangeiras devem ser indexadas para permitir junções eficientes.
Considere os seguintes pontos:
- Índices de Chaves Estrangeiras:Toda chave estrangeira deve ter um índice para acelerar as junções.
- Índices Compostos: Se uma consulta faz junção em múltiplas colunas, um índice composto pode cobrir todas as condições de junção.
- Impacto da Denormalização: A denormalização frequentemente reduz a necessidade de índices de chaves estrangeiras, potencialmente reduzindo a sobrecarga de escrita nos índices.
Comparação: Normalização vs. Denormalização 📋
Para visualizar claramente os trade-offs, consulte a tabela abaixo. Essa estrutura ajuda na tomada de decisões durante a fase de design.
| Funcionalidade | Normalização | Denormalização |
|---|---|---|
| Redundância de Dados | Minimizada | Aumentada |
| Integridade dos Dados | Alta | Requer Gerenciamento |
| Espaço de Armazenamento | Eficiente | Menos Eficiente |
| Desempenho de Leitura | Mais lento (mais junções) | Mais rápido (menos junções) |
| Desempenho de Escrita | Mais rápido (menos dados para atualizar) | Mais lento (atualizar todas as cópias) |
| Complexidade | Alta (muitas tabelas) | Alta (lógica para sincronizar dados) |
| Melhor Caso de Uso | OLTP, Sistemas Transacionais | OLAP, Relatórios, Leitura Intensa |
Estratégia de Implementação: Uma Abordagem Passo a Passo 🚀
Projetar um esquema exige um processo metódico. Não se apresse em denormalizar. Siga esta abordagem estruturada para garantir uma base estável.
Passo 1: Modelar para Integridade em Primeiro Lugar 🏗️
Comece criando um esquema totalmente normalizado. Busque pelo menos a Terceira Forma Normal (3FN). Identifique todas as entidades, atributos e relacionamentos. Certifique-se de que cada tabela tenha uma chave primária e que as chaves estrangeiras estejam corretamente definidas. Esta fase garante que seus dados sejam precisos e consistentes.
Passo 2: Analisar Padrões de Consulta 🔎
Antes de alterar o esquema, entenda como os dados serão acessados. Revise os requisitos da aplicação e os logs de consultas. Identifique quais consultas são lentas ou complexas. Procure padrões em que múltiplos joins sejam frequentemente necessários.
Passo 3: Otimizar Índices ⚡
Antes de denormalizar, certifique-se de que o seu esquema normalizado esteja corretamente indexado. Muitas vezes, adicionar os índices compostos adequados resolve problemas de desempenho sem precisar alterar a estrutura da tabela. Teste as consultas com o esquema e os índices atuais para estabelecer uma base de comparação.
Passo 4: Denormalização Direcionada 🎯
Se o desempenho ainda for insuficiente, aplique a denormalização de forma seletiva. Não denormalize todo o banco de dados. Foque apenas nas tabelas ou colunas específicas que causam o gargalo. Documente todas as alterações feitas para manutenção futura.
Passo 5: Monitorar e Iterar 📈
O projeto de banco de dados não é estático. Monitore o sistema ao longo do tempo. À medida que o volume de dados cresce ou os padrões de uso mudam, o equilíbrio pode precisar ser ajustado. Revise regularmente o esquema para garantir que ainda atenda aos requisitos de desempenho e integridade.
Armadilhas Comuns para Evitar 🚫
Mesmo projetistas experientes podem tropeçar ao lidar com a otimização de ERD. Fique atento a esses erros comuns.
- Sobrenormalização: Criar demasiadas tabelas torna o esquema difícil de entender e consultar. Mantenha a estrutura lógica e intuitiva.
- Subnormalização: Armazenar muitos dados em uma única tabela leva a anomalias de atualização e ao desperdício de espaço.
- Ignorar o Crescimento de Dados: Um projeto que funciona com 1.000 registros pode falhar com 1.000.000. Planeje para escala.
- Denormalização Oculta: Denormalizar sem documentação leva à confusão. Mantenedores futuros podem não entender por que os dados estão duplicados.
- Supor que todas as consultas são iguais: Nem todas as consultas têm os mesmos requisitos de desempenho. Priorize as mais frequentes e críticas.
Pensamentos Finais sobre a Arquitetura de Esquema 🧠
A decisão entre normalização e denormalização não é binária. É um espectro de compromissos que depende das necessidades específicas da sua aplicação. Um ERD bem projetado equilibra a integridade dos dados com a eficiência das consultas. Ao compreender os princípios subjacentes e seguir uma abordagem estruturada, você pode construir sistemas que sejam tanto robustos quanto eficientes.
Lembre-se de que ferramentas e tecnologias evoluem. Os princípios do design relacional, no entanto, permanecem constantes. Foque no modelo de dados em si, e não nas capacidades do motor do banco de dados. Uma base sólida apoiará sua aplicação, independentemente das mudanças na infraestrutura que venham no futuro. Mantenha seu esquema limpo, sua documentação clara e seus métricas de desempenho em mente em cada etapa. 🌟

