











資料庫設計是任何穩健應用的骨幹。在建立實體關係圖(ERD)時,兩種相互對立的力量塑造了資料結構:正規化與反正規化。了解何時應用每種策略,將決定您的資料基礎設施的長期健康、效能與可維護性。本指南探討這些概念中最關鍵的問題,提供一條明確的路徑,用以設計高效能的資料庫結構,而無需依賴特定的軟體工具。🛠️
資料完整性與查詢速度經常朝相反方向拉扯。正規化透過減少冗餘來優先確保完整性。反正規化則透過引入受控的冗餘來優先提升速度。要掌握這兩者之間的平衡,需要深入理解關係理論與實際的效能需求。讓我們透過一系列針對性的問題與解答,探討技術細節。📊
理解基本概念:我們正在處理什麼問題?🔍
在深入探討特定情境之前,我們必須先定義ERD設計中所涉及的核心機制。
什麼是正規化?🔄
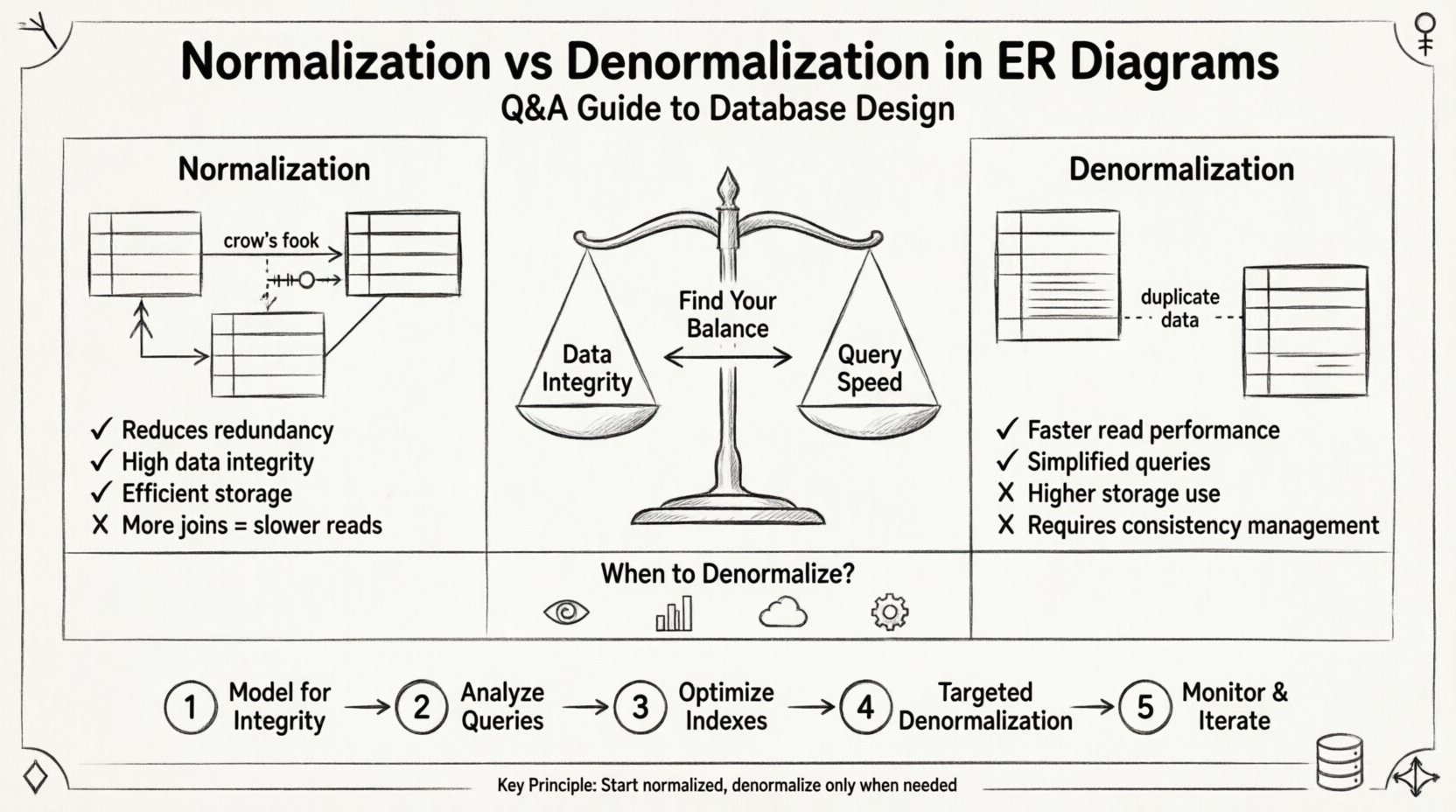
正規化是一種系統性的資料庫資料組織過程,旨在減少冗餘並提升資料完整性。它涉及將大型表格拆分為較小、邏輯上相互關聯的表格,並定義它們之間的關係。目標是確保每筆資料僅儲存在一個位置。
- 目標: 消除重複資料,並確保依賴關係合理。
- 優點: 簡化資料維護,並降低儲存需求。
- 代價: 因需要進行連接(join)操作,而增加查詢的複雜度。
正規化通常透過一系列稱為正規形式的階段來實現。每一種形式都建立在前一形式之上,針對特定類型的異常進行處理。
什麼是反正規化?⚖️
反正規化是將冗餘刻意引入已正規化的資料庫中。這通常用於優化讀取效能,特別是在查詢速度比寫入速度更為關鍵的情境下。它涉及合併表格或新增冗餘欄位,以避免耗時的連接操作。
- 目標: 減少複雜查詢所需的連接次數。
- 優點: 讀取操作更快,查詢邏輯更簡化。
- 代價: 儲存空間使用增加,且資料不一致的風險提高。
Q&A:深入探討正規化與ERD設計📝
這些問題針對設計關係式結構時最常遇到的摩擦點。它們涵蓋了從理論到實際實現的過渡過程。
Q1:我是否需要將所有內容都正規化到第三正規形式(3NF)?🤷♂️
簡短的答案是否定的。雖然第三正規形式(3NF)是許多應用的標準基準,但並非每個情境都必須遵循。將資料正規化至3NF可消除傳遞依賴,確保非鍵屬性僅依賴於主鍵。然而,達到更高形式如博伊斯-科德正規形式(BCNF)或第四正規形式(4NF)時,有時會使結構變得複雜,卻未必帶來顯著效益。
請考慮其中的權衡:
- 3NF: 適合一般用途的交易系統,其中資料完整性至關重要。
- 4NF/5NF: 除非您處理的是複雜的多值依賴或連接依賴,否則通常過度了。
- 實用方法: 首先設計為第三範式(3NF)。在考慮反規範化或進一步規範化之前,先評估性能瓶頸。
Q2:規範化如何影響查詢性能? 🐢
規範化主要透過連接的需求影響性能。當資料分散在多個表格中時,取得完整記錄需要資料庫引擎將這些表格連結起來。此過程會消耗CPU和記憶體資源。
影響性能的主要因素包括:
- 連接複雜度: 表格越多,需要評估的連接條件就越多。
- 索引: 外鍵必須建立索引以加快連接速度。若缺乏適當的索引,規範化可能導致嚴重的性能下降。
- 資料量: 隨著資料集增大,掃描和連接的成本顯著增加。
在讀操作密集的應用中,此開銷可能成為瓶頸。而在寫操作密集的應用中,與減少更新異常的優勢相比,此開銷通常可以忽略不計。
Q3:何時適合反規範化? ⚙️
反規範化不應是預設狀態。它是在識別出特定性能問題後才採取的修正措施。您應在以下情況下考慮反規範化:
- 讀操作密集的工作負載: 如果系統每執行一次寫操作就處理數千次讀取,連接的代價可能超過儲存空間的代價。
- 報表儀表板: 複雜的分析查詢通常能從儲存在寬表中的預先連接資料中受益。
- 快取層: 有時反規範化是在快取層中實現,而非主要儲存引擎中。
- 舊系統限制: 較舊的資料庫引擎或特定硬體限制可能難以處理複雜的連接。
Q4:在反規範化期間如何管理資料一致性? 🛡️
引入冗餘會帶來資料不一致的風險。如果您在「訂單」表格和「客戶」表格中都儲存客戶姓名,若在「客戶」表格中更新姓名,客戶 表格需要對其進行級聯更新訂單 表格。
維持一致性的策略包括:
- 應用程式邏輯: 確保應用程式程式碼在單一交易中更新所有冗餘欄位。
- 資料庫觸發器: 使用觸發器在來源資料變更時自動同步冗餘欄位。
- 定期核對: 執行排定的工作來審核並修復非正規化資料中的不一致。
- 讀取複本專用化: 保持主資料庫完全正規化,並使用非正規化複本進行報表處理。
問答:進階情境與權衡 ⚖️
超越基礎知識,系統擴展時會出現特定的架構挑戰。這些問題探討了這些細節。
Q5:我可以在同一個ERD中混合使用正規化與非正規化表格嗎? 🧩
是的,混合模型在生產環境中很常見。標準做法是維持核心正規化結構以確保交易完整性,同時為特定使用情境建立非正規化檢視或摘要表格。
例如:
- 核心表格: 將使用者、產品和訂單保持在第三正規化形式(3NF),以確保財務記錄的準確性。
- 報表表格: 建立一個非正規化表格,聚合訂單總額與客戶細節,以實現快速的儀表板呈現。
- 檢視: 使用SQL檢視向應用程式呈現非正規化結構,而無需實際複製資料。
Q6:非正規化是否違反資料庫理論? 📚
理論上,是的。關係理論主張正規化以減少異常。然而,實際工程經常需要打破這些規則以滿足效能的服務等級協議(SLA)。這種違反是故意且經過計算的。只要冗餘得到妥善管理並有文件記錄,設計對於其預期用途而言仍然有效。
Q7:索引如何與正規化互動? 🔖
索引是減輕正規化性能成本的主要工具。當你進行正規化時,會建立外鍵。這些外鍵必須建立索引,以實現高效的連接操作。
請考慮以下要點:
- 外鍵索引: 每個外鍵都應建立索引,以加快連接速度。
- 複合索引: 如果查詢在多個欄位上進行連接,複合索引可以涵蓋所有連接條件。
- 反規範化影響: 反規範化通常可以減少對外鍵索引的需求,從而可能降低索引上的寫入開銷。
對比:規範化 vs. 反規範化 📋
為了清楚地呈現權衡關係,請參考下面的表格。這種結構有助於在設計階段做出決策。
| 功能 | 規範化 | 反規範化 |
|---|---|---|
| 資料冗餘 | 最小化 | 增加 |
| 資料完整性 | 高 | 需要管理 |
| 儲存空間 | 高效 | 較低效 |
| 讀取效能 | 較慢(更多連接) | 較快(較少連接) |
| 寫入效能 | 較快(需更新的資料較少) | 較慢(需更新所有副本) |
| 複雜度 | 高(許多表格) | 高(需同步資料的邏輯) |
| 最佳使用情境 | OLTP,交易系統 | OLAP,報表,讀取密集 |
實施策略:逐步方法 🚀
設計資料結構需要有條不紊的過程。不要急於反規範化。遵循此結構化方法,以確保穩固的基礎。
步驟 1:首先確保完整性建模 🏗️
首先建立一個完全規範化的資料結構。目標至少達到第三範式(3NF)。識別所有實體、屬性和關係。確保每張表格都有主鍵,且外鍵定義正確。此階段可確保資料的準確性與一致性。
步驟 2:分析查詢模式 🔎
在更改資料結構之前,先了解資料將如何被存取。檢視應用程式需求與查詢日誌。識別哪些查詢速度慢或結構複雜。尋找經常需要多個連接(JOIN)的模式。
步驟 3:優化索引 ⚡
在反規範化之前,請確保您的規範化資料結構已正確建立索引。通常,加入適當的複合索引即可解決效能問題,無需更改表格結構。使用目前的資料結構與索引測試查詢,以建立基準。
步驟 4:針對性反規範化 🎯
若效能仍不夠,請選擇性地進行反規範化。不要對整個資料庫進行反規範化。僅針對造成瓶頸的特定表格或欄位進行處理。記錄每一項變更,以利未來維護。
步驟 5:監控並迭代 📈
資料庫設計並非一成不變。需持續監控系統。隨著資料量增加或使用模式改變,平衡點可能需要調整。定期檢視資料結構,確保其仍符合效能與完整性需求。
應避免的常見陷阱 🚫
即使經驗豐富的設計師,在處理實體關係圖(ERD)優化時也可能出錯。請留意這些常見錯誤。
- 過度規範化: 建立過多表格會使資料結構難以理解與查詢。保持結構邏輯且直覺。
- 規範化不足: 在單一表格中儲存過多資料,會導致更新異常與空間浪費。
- 忽視資料增長: 一個在 1,000 筆資料下運作良好的設計,可能在 1,000,000 筆資料時失敗。務必為擴展性做規劃。
- 隱藏的反規範化: 未經文件記錄的反規範化會造成混亂。未來的維護人員可能無法理解資料為何重複。
- 假設所有查詢皆相同: 不是所有查詢都具有相同的效能需求。應優先處理最常見且最關鍵的查詢。
關於資料結構架構的最終想法 🧠
在規範化與反規範化之間的決策並非非黑即白。這是一種取捨的光譜,取決於您的特定應用需求。一個設計良好的實體關係圖(ERD)能平衡資料完整性與查詢效率。透過理解基本原理並遵循結構化方法,您可建構出既穩健又高效能的系統。
請記住,工具與技術會不斷演進。然而,關係型設計的原則始終不變。專注於資料模型本身,而非資料庫引擎的功能。穩固的基礎將支援您的應用,無論未來基礎設施如何變動。請始終保持資料結構的整潔、文件的清晰,並在每一步都考慮效能指標。 🌟

