











Die Datenbankgestaltung ist die Grundlage jeder robusten Anwendung. Beim Erstellen eines Entitäts-Beziehungs-Diagramms (ERD) prägen zwei gegensätzliche Kräfte das Schema: Normalisierung und Denormalisierung. Das Verständnis, wann welche Strategie angewendet werden sollte, bestimmt die langfristige Gesundheit, Leistungsfähigkeit und Wartbarkeit Ihrer Dateninfrastruktur. Dieser Leitfaden beantwortet die wichtigsten Fragen zu diesen Konzepten und bietet einen klaren Weg zur Gestaltung effizienter Datenbankstrukturen, ohne auf spezifische Softwaretools angewiesen zu sein. 🛠️
Datenintegrität und Abfragegeschwindigkeit ziehen oft in entgegengesetzte Richtungen. Die Normalisierung setzt den Schwerpunkt auf Integrität durch Reduzierung von Redundanz. Die Denormalisierung setzt den Schwerpunkt auf Geschwindigkeit durch gezielte Einführung von Redundanz. Die Bewältigung dieses Gleichgewichts erfordert ein tiefes Verständnis der relationalen Theorie und praktischer Leistungsanforderungen. Lassen Sie uns die technischen Details anhand einer Reihe gezielter Fragen und Antworten untersuchen. 📊
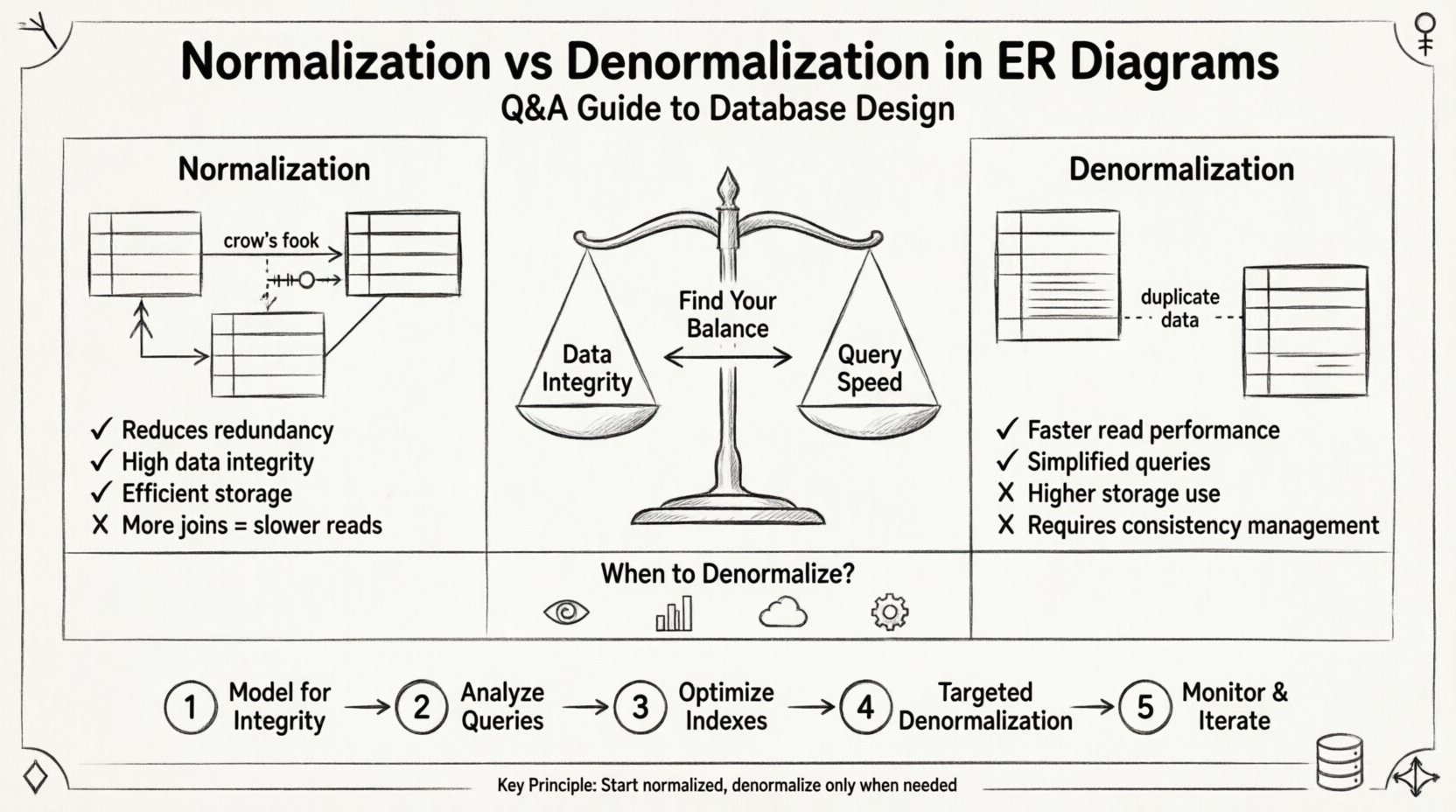
Verständnis der Grundlagen: Was haben wir hier vor? 🔍
Bevor wir uns spezifischen Szenarien zuwenden, müssen wir die zentralen Mechanismen definieren, die bei Ihrer ERD-Designarbeit eine Rolle spielen.
Was ist Normalisierung? 🔄
Normalisierung ist ein systematischer Prozess zur Organisation von Daten in einer Datenbank, um Redundanz zu reduzieren und die Datenintegrität zu verbessern. Dabei werden große Tabellen in kleinere, logisch verbundene Tabellen aufgeteilt, und Beziehungen zwischen ihnen werden definiert. Ziel ist es, sicherzustellen, dass jeder Datenbestand an nur einer Stelle gespeichert wird.
- Ziel: Doppelte Daten entfernen und sicherstellen, dass Abhängigkeiten sinnvoll sind.
- Vorteil: Vereinfacht die Datenpflege und reduziert die Speicheranforderungen.
- Kosten: Erhöht die Komplexität von Abfragen aufgrund der Notwendigkeit von Joins.
Die Normalisierung wird typischerweise durch eine Reihe von Stufen erreicht, die als Normalformen bekannt sind. Jede Form baut auf der vorhergehenden auf und behebt spezifische Arten von Anomalien.
Was ist Denormalisierung? ⚖️
Die Denormalisierung ist die bewusste Einführung von Redundanz in eine normalisierte Datenbank. Dies geschieht, um die Leseleistung zu optimieren, insbesondere in Szenarien, in denen die Abfragegeschwindigkeit wichtiger ist als die Schreibgeschwindigkeit. Dabei werden Tabellen zusammengeführt oder redundante Spalten hinzugefügt, um kostspielige Join-Operationen zu vermeiden.
- Ziel: Die Anzahl der für komplexe Abfragen erforderlichen Joins reduzieren.
- Vorteil: Schnellere Leseoperationen und vereinfachte Abfrage-Logik.
- Kosten: Höherer Speicherverbrauch und erhöhtes Risiko von Dateninkonsistenzen.
Q&A: Tiefgang in Normalisierung und ERD-Design 📝
Diese Fragen behandeln die häufigsten Schwierigkeiten, die bei der Gestaltung relationaler Schemata auftreten. Sie decken die Übergänge von der Theorie zur praktischen Umsetzung ab.
F1: Muss ich alles auf 3NF normalisieren? 🤷♂️
Die kurze Antwort lautet nein. Obwohl die Dritte Normalform (3NF) für viele Anwendungen ein Standardmaßstab ist, ist sie keine harte Regel für jedes Szenario. Die Normalisierung auf 3NF beseitigt transitive Abhängigkeiten und stellt sicher, dass nicht-schlüsselbasierte Attribute sich nur auf den Primärschlüssel beziehen. Die Erreichung höherer Formen wie der Boyce-Codd-Normalform (BCNF) oder der Vierten Normalform (4NF) kann jedoch manchmal das Schema komplizierter machen, ohne signifikante Vorteile zu bieten.
Berücksichtigen Sie die Abwägungen:
- 3NF: Gut geeignet für allgemeine transaktionale Systeme, bei denen die Datenintegrität von höchster Bedeutung ist.
- 4NF/5NF: Oft übertrieben, es sei denn, Sie haben es mit komplexen mehrwertigen Abhängigkeiten oder Verknüpfungsabhängigkeiten zu tun.
- Praktischer Ansatz: Gestalten Sie zunächst für 3NF. Beurteilen Sie Leistungsbottlenecks, bevor Sie eine De-Normalisierung oder weitere Normalisierung in Betracht ziehen.
F2: Wie wirkt sich Normalisierung auf die Abfrageleistung aus? 🐢
Die Normalisierung beeinflusst die Leistung vor allem durch die Notwendigkeit von Verknüpfungen. Wenn Daten über mehrere Tabellen verteilt sind, erfordert die Abrufung eines vollständigen Datensatzes, dass die Datenbankengine diese Tabellen miteinander verknüpft. Dieser Vorgang verbraucht CPU- und Speicherressourcen.
Wichtige Faktoren, die die Leistung beeinflussen, sind:
- Komplexität der Verknüpfung:Mehr Tabellen bedeuten mehr Verknüpfungsbedingungen, die bewertet werden müssen.
- Indizierung:Fremdschlüssel müssen indiziert werden, um Verknüpfungen zu beschleunigen. Ohne eine angemessene Indizierung kann die Normalisierung zu einer erheblichen Leistungseinbuße führen.
- Datenvolumen: Je größer die Datensammlung wird, desto deutlicher steigen die Kosten für das Durchsuchen und Verknüpfen.
Bei anwendungsintensiven Leseoperationen kann diese Überhead zu einer Engstelle werden. Bei anwendungsintensiven Schreiboperationen ist der Overhead im Vergleich zum Vorteil einer reduzierten Anzahl von Aktualisierungsanomalien oft vernachlässigbar.
F3: Wann ist eine De-Normalisierung angemessen? ⚙️
Die De-Normalisierung sollte nicht der Standardzustand sein. Sie ist eine korrigierende Maßnahme, die nach Identifizierung spezifischer Leistungsprobleme angewendet wird. Sie sollten eine De-Normalisierung in folgenden Situationen erwägen:
- Leseintensive Workloads:Wenn das System Tausende von Lesevorgängen pro Schreibvorgang verarbeitet, können die Kosten für Verknüpfungen die Speicherkosten übersteigen.
- Berichts- und Dashboard-Systeme:Komplexe analytische Abfragen profitieren oft von vorverknüpften Daten, die in breiten Tabellen gespeichert sind.
- Caching-Ebenen:Manchmal wird die De-Normalisierung in einer Cachenebene statt im primären Speicher-Engine implementiert.
- Veraltete Einschränkungen:Ältere Datenbank-Engines oder spezifische Hardwarebeschränkungen könnten mit komplexen Verknüpfungen Schwierigkeiten haben.
F4: Wie verwaltet man die Datenkonsistenz während der De-Normalisierung? 🛡️
Die Einführung von Redundanz birgt das Risiko von Dateninkonsistenzen. Wenn Sie einen Kundennamen in beiden Tabellen Bestellungen und der KundenTabelle speichern, führt die Aktualisierung des Namens in der Kunden Tabelle erfordert ein kaskadenartiges Aktualisieren der Bestellungen Tabelle.
Strategien zur Aufrechterhaltung der Konsistenz umfassen:
- Anwendungslogik: Stellen Sie sicher, dass der Anwendungscode alle redundanten Felder innerhalb einer einzigen Transaktion aktualisiert.
- Datenbanktrigger:Verwenden Sie Trigger, um redundanten Spalten automatisch bei Änderungen der Quelldaten zu synchronisieren.
- Periodische Abstimmung:Führen Sie geplante Aufgaben aus, um Inkonsistenzen in denormalisierten Daten zu überprüfen und zu beheben.
- Spezialisierung von Lese-Replikaten:Halten Sie die primäre Datenbank vollständig normalisiert und verwenden Sie eine denormalisierte Kopie für Berichterstattung.
Fragen und Antworten: Fortgeschrittene Szenarien und Abwägungen ⚖️
Über die Grundlagen hinaus ergeben sich spezifische architektonische Herausforderungen bei der Skalierung von Systemen. Diese Fragen behandeln diese Feinheiten.
F5: Kann ich normierte und denormierte Tabellen in derselben ERD mischen? 🧩
Ja, hybride Modelle sind in Produktionsumgebungen üblich. Es ist übliche Praxis, ein zentrales normiertes Schema für die Transaktionsintegrität aufrechtzuerhalten, während für bestimmte Anwendungsfälle denormierte Ansichten oder Zusammenfassungstabellen erstellt werden.
Zum Beispiel:
- Kerntabellen:Halten Sie Benutzer, Produkte und Bestellungen in der 3. Normalform, um genaue Finanzdaten zu gewährleisten.
- Berichtstabellen:Erstellen Sie eine denormierte Tabelle, die Bestellsummen und Kundendaten zusammenfasst, um eine schnelle Darstellung in Dashboards zu ermöglichen.
- Ansichten:Verwenden Sie SQL-Ansichten, um eine denormierte Struktur an Anwendungen zu präsentieren, ohne Daten physisch zu duplizieren.
F6: Verletzt Denormalisierung die Datenbanktheorie? 📚
Theoretisch ja. Die relationale Theorie befürwortet die Normalisierung, um Anomalien zu minimieren. Praktische Ingenieursarbeit erfordert jedoch oft, diese Regeln zu umgehen, um Leistungs-SLAs zu erfüllen. Die Verletzung ist bewusst und abgewogen. Solange die Redundanz verwaltet und dokumentiert wird, bleibt das Design für seinen vorgesehenen Zweck gültig.
F7: Wie interagiert Indizierung mit der Normalisierung? 🔖
Indizierung ist das primäre Werkzeug zur Minderung der Leistungskosten der Normalisierung. Wenn Sie normalisieren, erstellen Sie Fremdschlüssel. Diese Fremdschlüssel müssen indiziert werden, um effizientes Verknüpfen zu ermöglichen.
Berücksichtigen Sie die folgenden Punkte:
- Fremdschlüssel-Indizes:Jeder Fremdschlüssel sollte einen Index haben, um Joins zu beschleunigen.
- Komposite Indizes: Wenn eine Abfrage auf mehreren Spalten verknüpft, kann ein komposites Index alle Verknüpfungsbedingungen abdecken.
- Auswirkungen der De-Normalisierung: Die De-Normalisierung verringert oft die Notwendigkeit für Fremdschlüssel-Indizes und reduziert potenziell die Schreibbelastung auf Indizes.
Vergleich: Normalisierung vs. De-Normalisierung 📋
Um die Kompromisse klar zu visualisieren, ziehen Sie die Tabelle unten heran. Diese Struktur unterstützt die Entscheidungsfindung im Gestaltungsphase.
| Funktion | Normalisierung | De-Normalisierung |
|---|---|---|
| Datenduplikation | Minimiert | Erhöht |
| Datenintegrität | Hoch | Erfordert Verwaltung |
| Speicherplatz | Effizient | Weniger effizient |
| Lesegeschwindigkeit | Langsam (mehr Joins) | Schneller (weniger Joins) |
| Schreibgeschwindigkeit | Schneller (weniger Daten zum Aktualisieren) | Langsam (Aktualisierung aller Kopien) |
| Komplexität | Hoch (viele Tabellen) | Hoch (Logik zur Synchronisierung von Daten) |
| Beste Anwendungsfälle | OLTP, Transaktionssysteme | OLAP, Berichterstattung, Lese-lastig |
Implementierungsstrategie: Ein schrittweiser Ansatz 🚀
Die Gestaltung einer Schema erfordert einen systematischen Prozess. Eile nicht dazu, die Normalform aufzugeben. Folge diesem strukturierten Ansatz, um eine stabile Grundlage zu gewährleisten.
Schritt 1: Modell für Integrität zuerst 🏗️
Beginnen Sie damit, ein vollständig normalisiertes Schema zu erstellen. Streben Sie mindestens die dritte Normalform (3NF) an. Identifizieren Sie alle Entitäten, Attribute und Beziehungen. Stellen Sie sicher, dass jede Tabelle einen Primärschlüssel besitzt und Fremdschlüssel korrekt definiert sind. Diese Phase stellt sicher, dass Ihre Daten genau und konsistent sind.
Schritt 2: Analyse von Abfragemustern 🔎
Bevor Sie das Schema ändern, verstehen Sie, wie die Daten abgerufen werden. Überprüfen Sie die Anwendungsanforderungen und Abfrageprotokolle. Identifizieren Sie langsame oder komplexe Abfragen. Suchen Sie nach Mustern, bei denen häufig mehrere Joins erforderlich sind.
Schritt 3: Optimierung von Indizes ⚡
Bevor Sie die Normalform aufgeben, stellen Sie sicher, dass Ihr normalisiertes Schema korrekt indiziert ist. Oft löst die Hinzufügung der richtigen zusammengesetzten Indizes Leistungsprobleme, ohne dass die Tabellenstruktur geändert werden muss. Testen Sie die Abfragen mit dem aktuellen Schema und den Indizes, um eine Basislinie zu erstellen.
Schritt 4: Gezielte Aufhebung der Normalform 🎯
Wenn die Leistung immer noch unzureichend ist, wenden Sie die Aufhebung der Normalform gezielt an. Denormalisieren Sie nicht die gesamte Datenbank. Konzentrieren Sie sich nur auf die spezifischen Tabellen oder Spalten, die die Engpässe verursachen. Dokumentieren Sie jede Änderung für die zukünftige Wartung.
Schritt 5: Überwachen und iterieren 📈
Die Datenbankgestaltung ist nicht statisch. Überwachen Sie das System über die Zeit. Wenn sich das Datenvolumen erhöht oder die Nutzungsmuster ändern, könnte das Gleichgewicht angepasst werden müssen. Überprüfen Sie das Schema regelmäßig, um sicherzustellen, dass es weiterhin die Leistungs- und Integritätsanforderungen erfüllt.
Häufige Fehler, die vermieden werden sollten 🚫
Selbst erfahrene Designer können bei der Optimierung von ERDs ins Straucheln geraten. Achten Sie auf diese häufigen Fehler.
- Über-Normalisierung:Die Erstellung zu vieler Tabellen macht das Schema schwer verständlich und abfragbar. Halten Sie die Struktur logisch und intuitiv.
- Unter-Normalisierung:Die Speicherung zu viel Daten in einer einzigen Tabelle führt zu Aktualisierungsanomalien und verschwendet Platz.
- Ignorieren des Datenwachstums:Ein Design, das mit 1.000 Datensätzen funktioniert, kann bei 1.000.000 versagen. Planen Sie die Skalierung.
- Versteckte Aufhebung der Normalform:Die Aufhebung der Normalform ohne Dokumentation führt zu Verwirrung. Zukünftige Wartende können nicht verstehen, warum Daten dupliziert sind.
- Annahme, dass alle Abfragen gleich sind:Nicht alle Abfragen haben die gleichen Leistungsanforderungen. Priorisieren Sie die häufigsten und kritischsten Abfragen.
Letzte Gedanken zur Schema-Architektur 🧠
Die Entscheidung zwischen Normalisierung und Aufhebung der Normalform ist nicht binär. Es handelt sich um ein Spektrum von Kompromissen, das von Ihren spezifischen Anwendungsanforderungen abhängt. Ein gut gestaltetes ERD balanciert Datenintegrität mit Abfrageeffizienz. Durch Verständnis der zugrundeliegenden Prinzipien und Anwendung eines strukturierten Ansatzes können Sie Systeme bauen, die sowohl robust als auch leistungsfähig sind.
Denken Sie daran, dass Werkzeuge und Technologien sich weiterentwickeln. Die Prinzipien der relationalen Gestaltung bleiben jedoch konstant. Konzentrieren Sie sich auf das Datenmodell selbst und nicht auf die Fähigkeiten der Datenbank-Engine. Eine solide Grundlage wird Ihre Anwendung unabhängig von zukünftigen Infrastrukturänderungen unterstützen. Halten Sie Ihr Schema sauber, Ihre Dokumentation klar und Ihre Leistungsmetriken bei jedem Schritt im Auge. 🌟

