











La conception des bases de données est le pilier de toute application robuste. Lors de la construction d’un diagramme d’entités et de relations (ERD), deux forces opposées façonnent le schéma : la normalisation et la dénormalisation. Comprendre quand appliquer chaque stratégie détermine la santé à long terme, les performances et la maintenabilité de votre infrastructure de données. Ce guide aborde les questions les plus critiques concernant ces concepts, offrant une voie claire pour concevoir des structures de bases de données efficaces sans dépendre d’outils logiciels spécifiques. 🛠️
L’intégrité des données et la vitesse des requêtes s’opposent souvent. La normalisation privilégie l’intégrité en réduisant la redondance. La dénormalisation privilégie la vitesse en introduisant une redondance contrôlée. Naviguer entre ces deux aspects exige une compréhension approfondie de la théorie relationnelle et des exigences pratiques de performance. Explorons ensemble les détails techniques à travers une série de questions et réponses ciblées. 📊
Comprendre les fondamentaux : De quoi avons-nous affaire ? 🔍
Avant de plonger dans des scénarios spécifiques, nous devons définir les mécanismes fondamentaux en jeu dans la conception de votre ERD.
Qu’est-ce que la normalisation ? 🔄
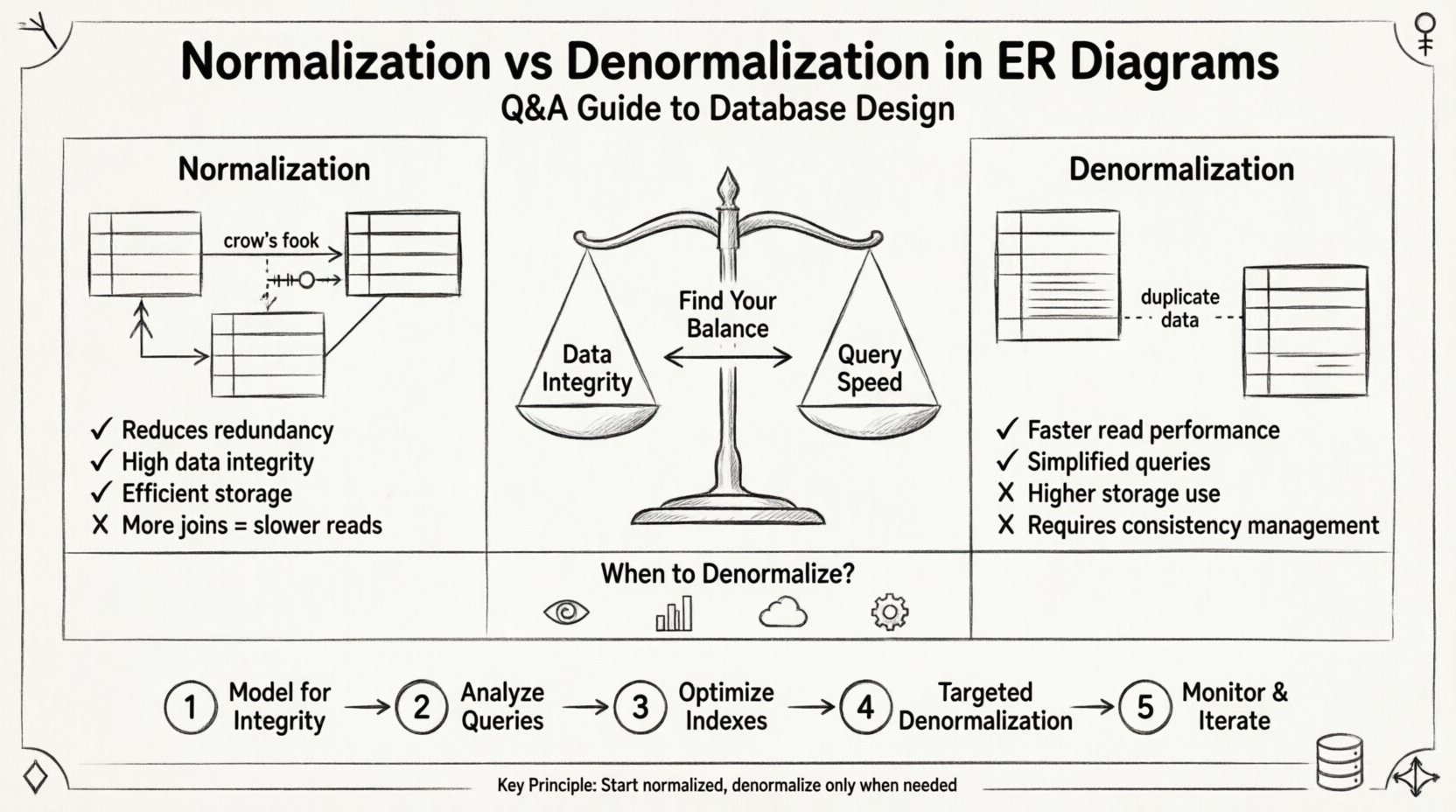
La normalisation est un processus systématique d’organisation des données dans une base de données afin de réduire la redondance et d’améliorer l’intégrité des données. Elle consiste à diviser de grandes tables en tables plus petites, logiquement connectées, et à définir des relations entre elles. L’objectif est de garantir que chaque morceau de données soit stocké à un seul endroit.
- Objectif : Éliminer les données en double et s’assurer que les dépendances ont un sens.
- Avantage : Simplifie la maintenance des données et réduit les besoins de stockage.
- Coût : Augmente la complexité des requêtes en raison de la nécessité d’opérations de jointure.
La normalisation est généralement obtenue à travers une série d’étapes appelées Formes Normales. Chaque forme s’appuie sur la précédente, en traitant des types spécifiques d’anomalies.
Qu’est-ce que la dénormalisation ? ⚖️
La dénormalisation consiste à introduire intentionnellement de la redondance dans une base de données normalisée. Cela vise à optimiser les performances de lecture, notamment dans les scénarios où la vitesse des requêtes est plus critique que celle des écritures. Elle consiste à fusionner des tables ou à ajouter des colonnes redondantes afin d’éviter des opérations de jointure coûteuses.
- Objectif : Réduire le nombre de jointures nécessaires pour les requêtes complexes.
- Avantage : Opérations de lecture plus rapides et logique de requête simplifiée.
- Coût : Utilisation accrue du stockage et risque accru d’incohérence des données.
Q&R : Approfondissement sur la normalisation et la conception d’ERD 📝
Ces questions abordent les points de friction les plus courants rencontrés lors de la conception de schémas relationnels. Elles couvrent la transition entre la théorie et la mise en œuvre pratique.
Q1 : Dois-je normaliser tout au 3FN ? 🤷♂️
La réponse courte est non. Bien que la Troisième Forme Normale (3FN) soit une référence standard pour de nombreuses applications, elle n’est pas une règle absolue pour chaque scénario. Normaliser jusqu’à la 3FN élimine les dépendances transitives, en garantissant que les attributs non clés dépendent uniquement de la clé primaire. Toutefois, atteindre des formes supérieures comme la Forme Normale de Boyce-Codd (BCNF) ou la Quatrième Forme Normale (4NF) peut parfois compliquer le schéma sans apporter de bénéfices significatifs.
Pesez les compromis :
- 3FN : Adapté aux systèmes transactionnels généraux où l’intégrité des données est primordiale.
- 4FN/5FN : Souvent excessif, sauf si vous traitez des dépendances multivaluées complexes ou des dépendances de jointure.
- Approche pratique : Concevez d’abord pour la 3FN. Évaluez les goulets d’étranglement de performance avant de considérer la dénormalisation ou une normalisation supplémentaire.
Q2 : Comment la normalisation affecte-t-elle les performances des requêtes ? 🐢
La normalisation affecte les performances principalement à travers la nécessité de jointures. Lorsque les données sont réparties sur plusieurs tables, la récupération d’un enregistrement complet exige que le moteur de base de données lie ensemble ces tables. Ce processus consomme des ressources CPU et mémoire.
Les facteurs clés influençant les performances incluent :
- Complexité des jointures :Plus de tables signifient plus de conditions de jointure à évaluer.
- Indexation :Les clés étrangères doivent être indexées pour accélérer les jointures. Sans indexation appropriée, la normalisation peut entraîner une dégradation sévère des performances.
- Volume des données :Au fur et à mesure que l’ensemble de données grandit, le coût du balayage et des jointures augmente considérablement.
Dans les applications à forte charge de lecture, ce surcoût peut devenir un goulot d’étranglement. Dans les applications à forte charge d’écriture, le surcoût est souvent négligeable par rapport aux avantages d’une réduction des anomalies de mise à jour.
Q3 : Quand est-il approprié de dénormaliser ? ⚙️
La dénormalisation ne doit pas être l’état par défaut. C’est une mesure corrective appliquée après avoir identifié des problèmes de performance spécifiques. Vous devriez envisager la dénormalisation dans les situations suivantes :
- Charge de travail à forte lecture :Si le système traite des milliers de lectures pour chaque écriture, le coût des jointures peut dépasser celui du stockage.
- Tableaux de bord de reporting :Les requêtes analytiques complexes bénéficient souvent des données pré-jointes stockées dans des tables larges.
- Niveaux de mise en cache :Parfois, la dénormalisation est mise en œuvre au niveau d’une couche de mise en cache plutôt que dans le moteur de stockage principal.
- Contraintes héritées :Les anciens moteurs de base de données ou des limitations matérielles spécifiques pourraient avoir des difficultés avec des jointures complexes.
Q4 : Comment gérer la cohérence des données pendant la dénormalisation ? 🛡️
L’introduction de redondance crée le risque d’incohérence des données. Si vous stockez le nom d’un client à la fois dans la table Orders et dans la table Customers , la mise à jour du nom dans la table Customers la table nécessite une mise à jour en cascade vers le Commandes table.
Les stratégies pour maintenir la cohérence incluent :
- Logique d’application : Assurez-vous que le code de l’application met à jour tous les champs redondants au sein d’une seule transaction.
- Déclencheurs de base de données :Utilisez des déclencheurs pour synchroniser automatiquement les colonnes redondantes lorsque les données sources changent.
- Reconnaissance périodique :Exécutez des tâches planifiées pour auditer et corriger les incohérences dans les données dénormalisées.
- Spécialisation des répliques en lecture :Maintenez la base de données principale entièrement normalisée et utilisez une copie dénormalisée pour les rapports.
Q&R : Scénarios avancés et compromis ⚖️
Au-delà des bases, des défis architecturaux spécifiques apparaissent lors du dimensionnement des systèmes. Ces questions abordent ces nuances.
Q5 : Puis-je mélanger des tables normalisées et dénormalisées dans le même schéma ER ? 🧩
Oui, les modèles hybrides sont courants dans les environnements de production. Il est standard de maintenir un schéma normalisé central pour assurer l’intégrité transactionnelle tout en créant des vues dénormalisées ou des tables de synthèse pour des cas d’utilisation spécifiques.
Par exemple :
- Tables principales :Gardez les utilisateurs, les produits et les commandes en 3NF pour garantir des enregistrements financiers précis.
- Tables de reporting :Créez une table dénormalisée qui agrège les totaux des commandes et les détails des clients pour un rendu rapide des tableaux de bord.
- Vues :Utilisez des vues SQL pour présenter une structure dénormalisée aux applications sans dupliquer physiquement les données.
Q6 : La dénormalisation viole-t-elle la théorie des bases de données ? 📚
Théoriquement, oui. La théorie relationnelle préconise la normalisation pour minimiser les anomalies. Toutefois, l’ingénierie pratique exige souvent de déroger à ces règles pour respecter les SLA de performance. La violation est intentionnelle et calculée. Tant que la redondance est gérée et documentée, le design reste valide pour son usage prévu.
Q7 : Comment l’indexation interagit-elle avec la normalisation ? 🔖
L’indexation est l’outil principal pour atténuer le coût de performance de la normalisation. Lorsque vous normalisez, vous créez des clés étrangères. Ces clés étrangères doivent être indexées pour permettre des jointures efficaces.
Prenez en compte les points suivants :
- Index des clés étrangères :Chaque clé étrangère doit avoir un index pour accélérer les jointures.
- Index composés : Si une requête effectue un jointure sur plusieurs colonnes, un index composé peut couvrir toutes les conditions de jointure.
- Impact de la dénormalisation : La dénormalisation réduit souvent le besoin d’index de clés étrangères, ce qui peut réduire la charge d’écriture sur les index.
Comparaison : Normalisation vs. Dénormalisation 📋
Pour visualiser clairement les compromis, reportez-vous au tableau ci-dessous. Cette structure aide à la prise de décision pendant la phase de conception.
| Fonctionnalité | Normalisation | Dénormalisation |
|---|---|---|
| Redondance des données | Minimisée | Augmentée |
| Intégrité des données | Élevée | Nécessite une gestion |
| Espace de stockage | Efficace | Moins efficace |
| Performance de lecture | Plus lente (plus de jointures) | Plus rapide (moins de jointures) |
| Performance d’écriture | Plus rapide (moins de données à mettre à jour) | Plus lente (mise à jour de toutes les copies) |
| Complexité | Élevée (nombreuses tables) | Élevée (logique pour synchroniser les données) |
| Meilleur cas d’utilisation | OLTP, systèmes transactionnels | OLAP, rapports, lecture intensive |
Stratégie de mise en œuvre : une approche étape par étape 🚀
Concevoir un schéma nécessite une démarche méthodique. Ne vous précipitez pas pour dénormaliser. Suivez cette approche structurée pour assurer une base stable.
Étape 1 : Modéliser pour l’intégrité en premier 🏗️
Commencez par créer un schéma entièrement normalisé. Visez au moins la Troisième Forme Normale (3FN). Identifiez toutes les entités, attributs et relations. Assurez-vous que chaque table dispose d’une clé primaire et que les clés étrangères sont correctement définies. Cette phase garantit que vos données sont précises et cohérentes.
Étape 2 : Analyser les modèles de requêtes 🔎
Avant de modifier le schéma, comprenez comment les données seront accessibles. Revoyez les exigences de l’application et les journaux de requêtes. Identifiez les requêtes lentes ou complexes. Recherchez des modèles où des jointures multiples sont fréquemment nécessaires.
Étape 3 : Optimiser les index ⚡
Avant de dénormaliser, assurez-vous que votre schéma normalisé est correctement indexé. Souvent, l’ajout des bons index composés résout les problèmes de performance sans avoir à modifier la structure des tables. Testez les requêtes avec le schéma et les index actuels pour établir une base de référence.
Étape 4 : Dénormalisation ciblée 🎯
Si les performances restent insuffisantes, appliquez la dénormalisation de manière sélective. Ne dénormalisez pas l’ensemble de la base de données. Concentrez-vous uniquement sur les tables ou colonnes spécifiques qui causent le goulot d’étranglement. Documentez chaque modification effectuée pour faciliter la maintenance future.
Étape 5 : Surveiller et itérer 📈
La conception d’une base de données n’est pas statique. Surveillez le système au fil du temps. Au fur et à mesure que le volume de données augmente ou que les modèles d’utilisation évoluent, l’équilibre peut nécessiter des ajustements. Revoyez régulièrement le schéma pour vous assurer qu’il répond toujours aux exigences de performance et d’intégrité.
Péchés courants à éviter 🚫
Même les concepteurs expérimentés peuvent commettre des erreurs lors de l’optimisation des diagrammes ER. Faites attention à ces erreurs fréquentes.
- Sur-normalisation : Créer trop de tables rend le schéma difficile à comprendre et à interroger. Gardez la structure logique et intuitive.
- Sous-normalisation : Stocker trop de données dans une seule table entraîne des anomalies de mise à jour et un gaspillage d’espace.
- Ignorer la croissance des données : Un design fonctionnant avec 1 000 enregistrements peut échouer avec 1 000 000. Prévoyez l’évolutivité.
- Dénormalisation cachée : Dénormaliser sans documentation entraîne de la confusion. Les futurs mainteneurs peuvent ne pas comprendre pourquoi les données sont redondantes.
- Supposer que toutes les requêtes sont équivalentes : Toutes les requêtes n’ont pas les mêmes exigences de performance. Priorisez celles qui sont les plus fréquentes et les plus critiques.
Réflexions finales sur l’architecture du schéma 🧠
Le choix entre normalisation et dénormalisation n’est pas binaire. C’est un spectre d’alternatives qui dépend des besoins spécifiques de votre application. Un schéma bien conçu équilibre l’intégrité des données et l’efficacité des requêtes. En comprenant les principes fondamentaux et en suivant une approche structurée, vous pouvez construire des systèmes à la fois robustes et performants.
Souvenez-vous que les outils et les technologies évoluent. Les principes de conception relationnelle, en revanche, restent constants. Concentrez-vous sur le modèle de données lui-même plutôt que sur les capacités du moteur de base de données. Une fondation solide soutiendra votre application, quelle que soit l’évolution de l’infrastructure à venir. Gardez votre schéma propre, votre documentation claire, et gardez vos métriques de performance à l’esprit à chaque étape. 🌟

