











Projektowanie bazy danych to fundament każdej solidnej aplikacji. Podczas tworzenia diagramu relacji encji (ERD) dwa przeciwstawne siły kształtują schemat: normalizację i denormalizację. Zrozumienie, kiedy stosować każdą z tych strategii, decyduje o długoterminowym zdrowiu, wydajności i utrzymywalności infrastruktury danych. Ten przewodnik omawia najważniejsze pytania dotyczące tych pojęć, zapewniając jasny sposób projektowania efektywnych struktur baz danych bez konieczności korzystania z określonych narzędzi programowych. 🛠️
Integralność danych i szybkość zapytań często działają w przeciwnych kierunkach. Normalizacja priorytetowo dba o integralność poprzez zmniejszanie nadmiarowości. Denormalizacja priorytetowo dba o szybkość poprzez wprowadzanie kontrolowanej nadmiarowości. Znalezienie tego równowagi wymaga głębokiego zrozumienia teorii relacyjnej oraz praktycznych wymagań wydajności. Przejdźmy do szczegółów technicznych poprzez serię skierowanych pytań i odpowiedzi. 📊
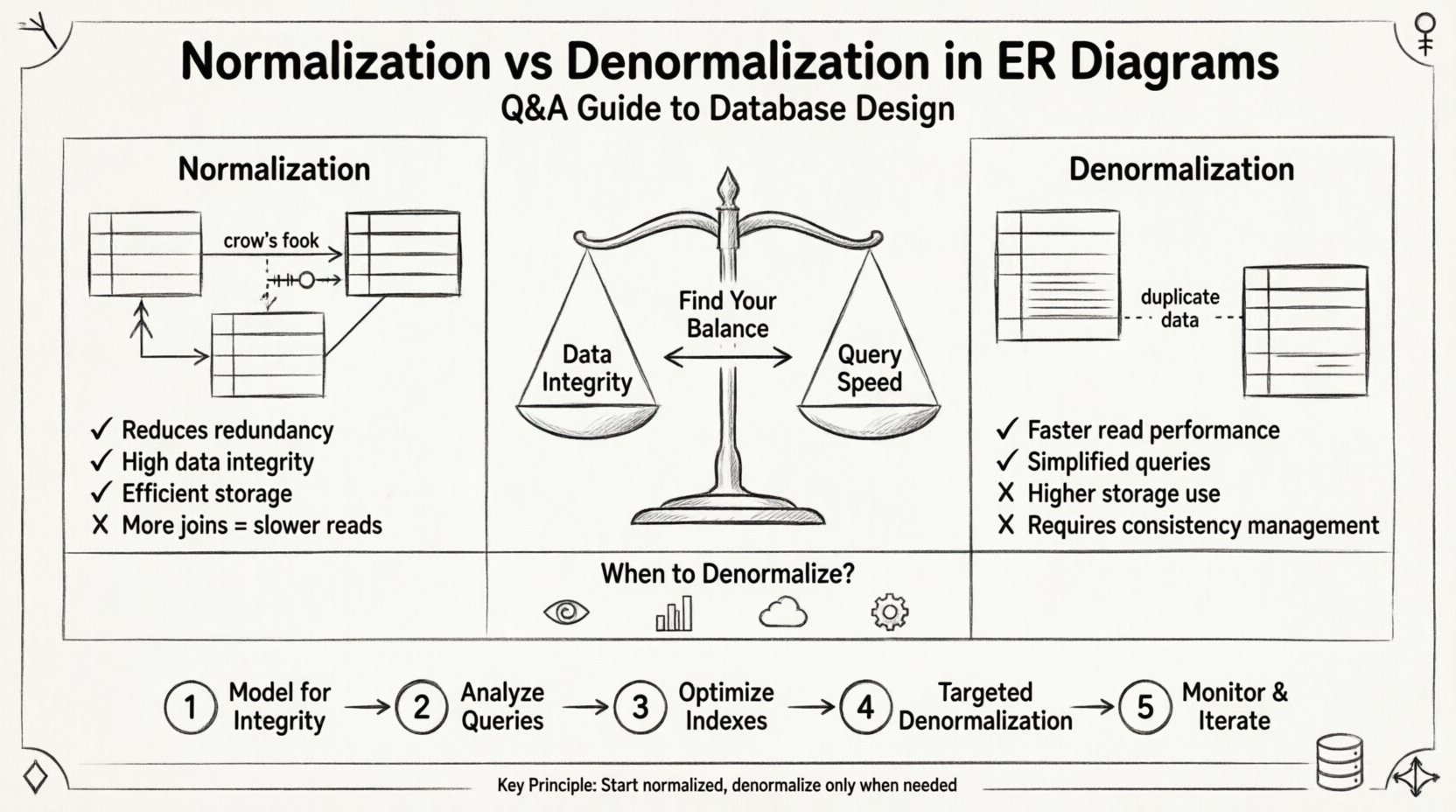
Zrozumienie podstaw: Z czym mamy do czynienia? 🔍
Zanim przejdziemy do konkretnych scenariuszy, musimy zdefiniować podstawowe mechanizmy obowiązujące w twoim projekcie diagramu ERD.
Czym jest normalizacja? 🔄
Normalizacja to systematyczny proces organizowania danych w bazie danych w celu zmniejszenia nadmiarowości i poprawy integralności danych. Polega na dzieleniu dużych tabel na mniejsze, logicznie powiązane tabele oraz definiowaniu między nimi relacji. Celem jest zapewnienie, że każda część danych jest przechowywana tylko w jednym miejscu.
- Cel: Usuń dane powtarzające się i upewnij się, że zależności mają sens.
- Zalety: Uproszczenie utrzymania danych oraz zmniejszenie wymagań pamięciowych.
- Koszt: Zwiększa złożoność zapytań ze względu na konieczność łączenia tabel.
Normalizacja zwykle osiągana jest poprzez szereg etapów znanych jako Formy Normalne. Każda forma opiera się na poprzedniej i rozwiązuje konkretne typy anomalii.
Czym jest denormalizacja? ⚖️
Denormalizacja to celowe wprowadzanie nadmiarowości do normalizowanej bazy danych. Robi się to w celu optymalizacji wydajności odczytu, szczególnie w sytuacjach, gdy szybkość zapytań jest ważniejsza niż szybkość zapisu. Polega na łączeniu tabel lub dodawaniu nadmiarowych kolumn w celu uniknięcia kosztownych operacji łączenia.
- Cel: Zmniejszenie liczby łączeń wymaganych do złożonych zapytań.
- Zalety: Szybsze operacje odczytu oraz uproszczona logika zapytań.
- Koszt: Zwiększone zużycie pamięci i wyższy ryzyko niezgodności danych.
Q&A: Głębokie zapoznanie się z normalizacją i projektowaniem diagramów ERD 📝
Te pytania dotyczą najczęściej występujących trudności podczas projektowania schematów relacyjnych. Omawiają przejście od teorii do praktycznej realizacji.
Pytanie 1: Czy muszę normalizować wszystko do 3NF? 🤷♂️
Krótką odpowiedzią jest nie. Choć Trzecia Forma Normalna (3NF) jest standardowym kryterium dla wielu aplikacji, nie jest surowym prawem dla każdego przypadku. Normalizacja do 3NF eliminuje zależności przechodnie, zapewniając, że atrybuty niekluczowe zależą wyłącznie od klucza głównego. Jednak osiągnięcie wyższych form, takich jak Forma Normalna Boyce’a-Codd’a (BCNF) lub Czwarta Forma Normalna (4NF), czasem komplikuje schemat bez istotnych korzyści.
Zważ zależności:
- 3NF: Dobrze nadaje się do ogólnych systemów transakcyjnych, gdzie integralność danych jest najważniejsza.
- 4NF/5NF: Często nadmiarowe, chyba że masz do czynienia z złożonymi zależnościami wielowartościowymi lub zależnościami połączeń.
- Prawdopodobny podejście: Projektuj zgodnie z 3NF na początku. Ocenić węzły przepustowości przed rozważeniem denormalizacji lub dalszej normalizacji.
Q2: Jak normalizacja wpływa na wydajność zapytań? 🐢
Normalizacja wpływa na wydajność przede wszystkim przez wymóg łączenia tabel. Gdy dane są rozproszone na wielu tabelach, pobranie pełnego rekordu wymaga od silnika bazy danych połączenia tych tabel. Ten proces zużywa zasoby CPU i pamięci.
Kluczowe czynniki wpływające na wydajność to:
- Złożoność połączeń:Więcej tabel oznacza więcej warunków połączeń do oceny.
- Indeksowanie:Klucze obce muszą być indeksowane, aby przyspieszyć połączenia. Bez odpowiedniego indeksowania normalizacja może prowadzić do poważnego spadku wydajności.
- Objętość danych: Wraz ze wzrostem rozmiaru zestawu danych koszt skanowania i łączenia znacznie rośnie.
W aplikacjach z dużym obciążeniem odczytu ten narzut może stać się węzłem przepustowości. W aplikacjach z dużym obciążeniem zapisu narzut jest często zaniedbywalny w porównaniu z korzyścią z zmniejszenia anomalii aktualizacji.
Q3: Kiedy odpowiednie jest denormalizowanie? ⚙️
Denormalizacja nie powinna być stanem domyślnym. Jest to krokiem korygującym stosowanym po identyfikacji konkretnych problemów z wydajnością. Powinieneś rozważyć denormalizację w następujących sytuacjach:
- Obciążenia z dużym udziałem odczytu: Jeśli system przetwarza tysiące odczytów na każdy zapis, koszt połączeń może przewyższać koszt przechowywania danych.
- Pulpity raportujące:Złożone zapytania analityczne często korzystają z danych połączonych z góry przechowywanych w szerokich tabelach.
- Warstwy buforowania: Czasem denormalizacja jest implementowana w warstwie buforowania zamiast w głównym silniku przechowywania danych.
- Ograniczenia spowodowane starszymi systemami:Starsze silniki baz danych lub określone ograniczenia sprzętowe mogą mieć trudności z złożonymi połączeniami.
Q4: Jak zarządzać spójnością danych podczas denormalizacji? 🛡️
Wprowadzanie nadmiarowości stwarza ryzyko niespójności danych. Jeśli przechowujesz nazwę klienta w obu tabelach:Zamówienia oraz w tabeliKlienci to aktualizacja nazwy w tabeliKlienci tabela wymaga aktualizacji kaskadowej dla Zamówienia tabela.
Strategie utrzymania spójności obejmują:
- Logika aplikacji: Upewnij się, że kod aplikacji aktualizuje wszystkie nadmiarowe pola w ramach jednej transakcji.
- Wyzwalacze baz danych: Użyj wyzwalaczy, aby automatycznie zsynchronizować nadmiarowe kolumny w momencie zmiany danych źródłowych.
- Okresowa konsolidacja: Uruchamiaj zaplanowane zadania w celu audytu i naprawy niezgodności w danych znormalizowanych.
- Specjalizacja replik odczytu: Zachowaj główną bazę danych w pełni znormalizowaną i używaj kopii znormalizowanej do raportowania.
Pytania i odpowiedzi: Zaawansowane scenariusze i kompromisy ⚖️
Poza podstawami, pojawiają się konkretne wyzwania architektoniczne podczas skalowania systemów. Te pytania dotyczą tych subtelności.
Pytanie 5: Czy mogę łączyć znormalizowane i zdesnormalizowane tabele w tym samym modelu ERD? 🧩
Tak, modele hybrydowe są powszechne w środowiskach produkcyjnych. Jest standardową praktyką utrzymywanie podstawowego znormalizowanego schematu w celu zapewnienia integralności transakcyjnej, jednocześnie tworząc zdesnormalizowane widoki lub tabele podsumowujące dla określonych przypadków użycia.
Na przykład:
- Tabele główne: Zachowaj użytkowników, produkty i zamówienia w 3NF, aby zapewnić dokładne zapisy finansowe.
- Tabele raportowe: Utwórz zdesnormalizowaną tabelę agregującą sumy zamówień i dane klientów w celu szybkiego renderowania paneli.
- Widoki: Użyj widoków SQL, aby przedstawić strukturę zdesnormalizowaną aplikacjom bez fizycznego duplikowania danych.
Pytanie 6: Czy zdesnormalizacja narusza teorię baz danych? 📚
Teoretycznie tak. Teoria relacyjna promuje znormalizowanie w celu minimalizacji anomalii. Jednak praktyczna inżynieria często wymaga łamania tych zasad, aby spełnić wymagania SLA dotyczące wydajności. Naruszenie jest celowe i obliczone. O ile nadmiarowość jest zarządzana i dokumentowana, projekt pozostaje poprawny dla swojego zaplanowanego przeznaczenia.
Pytanie 7: Jak indeksowanie oddziałuje na znormalizowanie? 🔖
Indeksowanie jest głównym narzędziem zmniejszania kosztu wydajności znormalizowania. Gdy znormalizujesz, tworzysz klucze obce. Te klucze obce muszą być indeksowane, aby umożliwić skuteczne łączenie.
Zastanów się nad poniższymi punktami:
- Indeksy kluczy obcych: Każdy klucz obcy powinien mieć indeks, aby przyspieszyć łączenia.
- Indeksy złożone: Jeśli zapytanie łączy wiele kolumn, indeks złożony może obejmować wszystkie warunki łączenia.
- Wpływ denormalizacji: Denormalizacja często zmniejsza potrzebę indeksów kluczy obcych, potencjalnie zmniejszając obciążenie zapisu na indeksach.
Porównanie: Normalizacja vs. Denormalizacja 📋
Aby jasno zobrazować kompromisy, odwołaj się do poniższej tabeli. Ta struktura pomaga w podejmowaniu decyzji w fazie projektowania.
| Cecha | Normalizacja | Denormalizacja |
|---|---|---|
| Zmieszczanie danych | Minimalizowane | Zwiększone |
| Integralność danych | Wysoka | Wymaga zarządzania |
| Przestrzeń magazynowania | Efektywne | Mniej efektywne |
| Wydajność odczytu | Wolniejsze (więcej łączeń) | Szybsze (mniej łączeń) |
| Wydajność zapisu | Szybsze (mniej danych do aktualizacji) | Wolniejsze (aktualizacja wszystkich kopii) |
| Złożoność | Wysoka (wiele tabel) | Wysoka (logika synchronizacji danych) |
| Najlepsze zastosowanie | OLTP, Systemy transakcyjne | OLAP, Raportowanie, systemy z dużym obciążeniem odczytu |
Strategia wdrożenia: podejście krok po kroku 🚀
Projektowanie schematu wymaga systematycznego podejścia. Nie spiesz się z denormalizacją. Postępuj zgodnie z tym strukturalnym podejściem, aby zapewnić stabilną podstawę.
Krok 1: Modeluj dla integralności najpierw 🏗️
Zacznij od stworzenia w pełni normalizowanego schematu. Dąż do co najmniej trzeciej postaci normalnej (3NF). Zidentyfikuj wszystkie encje, atrybuty i relacje. Upewnij się, że każda tabela ma klucz główny oraz że klucze obce są poprawnie zdefiniowane. Ten etap zapewnia dokładność i spójność danych.
Krok 2: Analizuj wzorce zapytań 🔎
Zanim zmienisz schemat, zrozum, jak dane będą dostępne. Przejrzyj wymagania aplikacji oraz dzienniki zapytań. Zidentyfikuj, które zapytania są wolne lub złożone. Poszukaj wzorców, w których często wymagane są wiele połączeń.
Krok 3: Optymalizuj indeksy ⚡
Zanim denormalizujesz, upewnij się, że twój normalizowany schemat jest poprawnie indeksowany. Często dodanie odpowiednich indeksów złożonych rozwiązuje problemy wydajności bez konieczności zmiany struktury tabeli. Przetestuj zapytania przy obecnym schemacie i indeksach, aby ustalić podstawę porównawczą.
Krok 4: Celowa denormalizacja 🎯
Jeśli wydajność wciąż jest niewystarczająca, stosuj denormalizację selektywnie. Nie denormalizuj całego systemu baz danych. Skup się wyłącznie na konkretnych tabelach lub kolumnach powodujących przepustowość. Dokumentuj każdą zmianę, aby ułatwić późniejszą konserwację.
Krok 5: Monitoruj i iteruj 📈
Projektowanie bazy danych nie jest statyczne. Monitoruj system w czasie. Gdy objętość danych rośnie lub zmieniają się wzorce użytkowania, równowaga może wymagać dostosowania. Regularnie przeglądarkuj schemat, aby upewnić się, że nadal spełnia wymagania dotyczące wydajności i integralności.
Powszechne pułapki do uniknięcia 🚫
Nawet doświadczeni projektanci mogą się pomylić podczas optymalizacji diagramów ERD. Uważaj na te powszechne błędy.
- Zbyt duża normalizacja:Tworzenie zbyt wielu tabel sprawia, że schemat jest trudny do zrozumienia i wykonywania zapytań. Zachowaj strukturę logiczną i intuicyjną.
- Zbyt mała normalizacja:Przechowywanie zbyt dużej ilości danych w jednej tabeli prowadzi do anomalii aktualizacji i marnowania przestrzeni.
- Ignorowanie wzrostu danych:Projekt działający przy 1000 rekordach może zawieść przy 1 000 000. Planuj skalowalność.
- Ukryta denormalizacja:Denormalizacja bez dokumentacji prowadzi do zamieszania. Przyszli utrzymani nie będą rozumieć, dlaczego dane są powielone.
- Zakładanie, że wszystkie zapytania są równe: Nie wszystkie zapytania mają takie same wymagania co do wydajności. Najpierw zadbaj o najczęściej wykonywane i najważniejsze.
Ostateczne rozważania nad architekturą schematu 🧠
Decyzja między normalizacją a denormalizacją nie jest binarna. Jest to spektrum kompromisów zależnych od konkretnych potrzeb aplikacji. Dobrze zaprojektowany diagram ERD równoważy integralność danych z wydajnością zapytań. Zrozumienie podstawowych zasad i stosowanie strukturalnego podejścia pozwala tworzyć systemy zarówno wytrzymałe, jak i wydajne.
Pamiętaj, że narzędzia i technologie się rozwijają. Zasady projektowania relacyjnego pozostają jednak stałe. Skup się na modelu danych, a nie na możliwościach silnika bazy danych. Solidna podstawa wspiera Twoją aplikację niezależnie od zmian infrastruktury w przyszłości. Zachowuj schemat czysty, dokumentację jasną i pomiary wydajności w pamięci przy każdym kroku. 🌟

