











データベース設計は、あらゆる堅牢なアプリケーションの基盤です。エンティティ関係図(ERD)を構築する際、正規化と非正規化という相反する力がスキーマを形作ります。それぞれの戦略をいつ適用すべきかを理解することは、データインフラの長期的な健全性、パフォーマンス、保守性を決定します。このガイドでは、これらの概念に関する最も重要な質問に答えることで、特定のソフトウェアツールに依存せずに効率的なデータベース構造を設計する明確な道筋を提供します。 🛠️
データの整合性とクエリ速度はしばしば相反する方向に引き寄せられます。正規化は冗長性を減らすことで整合性を最優先します。非正規化は制御された冗長性を導入することで速度を最優先します。このバランスを取るには、関係理論と実際のパフォーマンス要件に対する深い理解が必要です。特定の質問と回答を通じて、技術的な詳細を検証しましょう。 📊
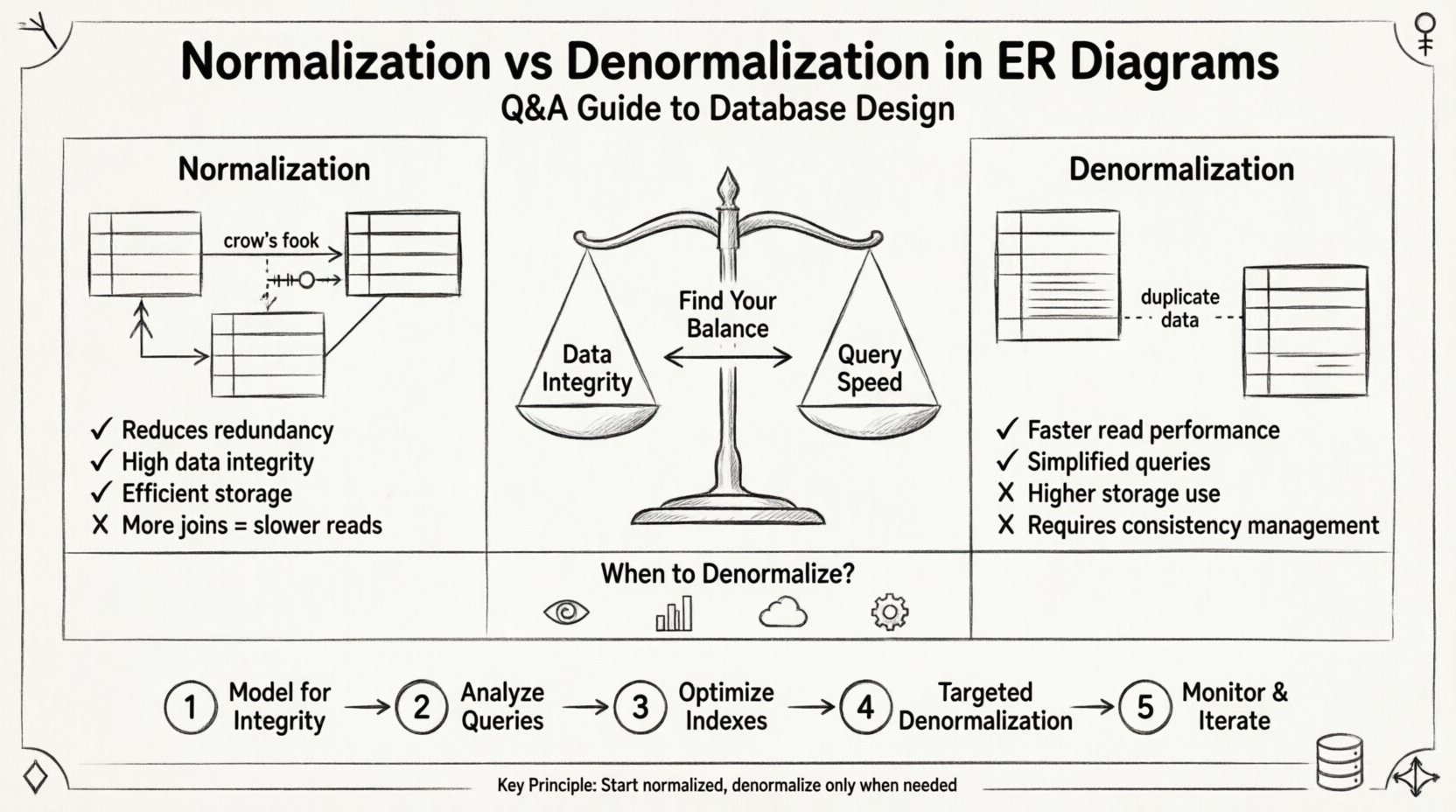
基本を理解する:私たちは何と取り組んでいるのか? 🔍
具体的なシナリオに飛び込む前に、ERD設計における中心的なメカニズムを定義する必要があります。
正規化とは何か? 🔄
正規化とは、データの冗長性を減らし、データの整合性を向上させるために、データベース内のデータを体系的に整理するプロセスです。大きなテーブルを論理的に関連する小さなテーブルに分割し、それらの間の関係を定義します。目的は、各データが唯一の場所に格納されることを保証することです。
- 目的:重複データを排除し、依存関係が意味を持つことを確認する。
- 利点:データのメンテナンスを簡素化し、ストレージ要件を削減する。
- コスト:結合が必要になるため、クエリの複雑性が増す。
正規化は通常、正規形と呼ばれる段階的なプロセスを通じて達成されます。各正規形は前の段階を基盤としており、特定の異常を解決します。
非正規化とは何か? ⚖️
非正規化とは、正規化されたデータベースに意図的に冗長性を導入することです。これは、読み取りパフォーマンスを最適化するためであり、特に書き込み速度よりも読み取り速度がより重要となる状況で行われます。結合操作のコストを避けるために、テーブルをマージしたり、冗長な列を追加したりします。
- 目的:複雑なクエリに必要な結合の数を減らす。
- 利点:読み取り操作が高速化され、クエリロジックが簡素化される。
- コスト:ストレージ使用量の増加と、データの整合性が保てないリスクの上昇。
Q&A:正規化とERD設計の詳細な検証 📝
これらの質問は、関係スキーマを設計する際に最もよく遭遇する摩擦点を扱います。理論から実際の実装への移行をカバーしています。
Q1:すべてを3NFまで正規化する必要があるのか? 🤷♂️
短い答えはいいえです。第3正規形(3NF)は多くのアプリケーションにおける標準的な基準ですが、すべてのシナリオに適用される硬いルールではありません。3NFまで正規化することで、推移的依存関係を排除し、非キー属性が主キーのみに依存することを保証します。しかし、ボイス・コッド正規形(BCNF)や第4正規形(4NF)などのより高い正規形を達成することは、しばしばスキーマを複雑化するだけで、大きな利点をもたらさないこともあります。
トレードオフを検討する:
- 3NF:データの整合性が最も重要となる汎用的なトランザクションシステムに適している。
- 4NF/5NF: 複雑な多値依存関係や結合依存関係を扱っている場合を除き、過剰な対応となることが多い。
- 実用的なアプローチ: まず3NFを想定して設計する。正規化またはさらに正規化を検討する前に、パフォーマンスのボトルネックを評価する。
Q2:正規化はクエリのパフォーマンスにどのように影響しますか? 🐢
正規化は主に結合の必要性を通じてパフォーマンスに影響を与えます。データが複数のテーブルに分散している場合、完全なレコードを取得するにはデータベースエンジンがこれらのテーブルを結合する必要があります。このプロセスはCPUとメモリリソースを消費します。
パフォーマンスに影響を与える主な要因には以下が含まれます:
- 結合の複雑さ:テーブルが多いほど、評価すべき結合条件が多くなる。
- インデックス化:結合を高速化するためには外部キーをインデックス化する必要がある。適切なインデックス化がなければ、正規化によって深刻なパフォーマンス低下が生じる可能性がある。
- データ量: データセットが大きくなるにつれて、スキャンや結合のコストが顕著に増加する。
読み込みが重いアプリケーションでは、このオーバーヘッドがボトルネックになることがある。書き込みが重いアプリケーションでは、更新異常の削減という利点に比べて、オーバーヘッドはしばしば無視できる程度である。
Q3:どのような場合に非正規化が適切ですか? ⚙️
非正規化はデフォルトの状態にしてはならない。特定のパフォーマンス問題を特定した後に適用される是正措置である。以下の状況では非正規化を検討すべきである:
- 読み込みが重いワークロード: 1回の書き込みに対して数千回の読み込みが行われる場合、結合のコストがストレージコストを上回る可能性がある。
- レポートダッシュボード: 複雑な分析クエリは、広いテーブルに事前に結合されたデータを格納することで恩恵を受けることが多い。
- キャッシュレイヤー: 時には非正規化が主なストレージエンジンではなく、キャッシュレイヤーに実装されることがある。
- レガシー制約: 古いデータベースエンジンや特定のハードウェア制限は、複雑な結合に対応しづらいことがある。
Q4:非正規化中にデータの一貫性をどのように管理しますか? 🛡️
冗長性を導入すると、データの一貫性のリスクが生じる。顧客名を「注文」テーブルと「顧客」テーブルの両方に格納している場合、注文テーブルと顧客テーブルに更新すると、顧客 テーブルは、次のものに対して連鎖更新が必要です注文 テーブル。
一貫性を維持するための戦略には以下が含まれます:
- アプリケーションロジック:アプリケーションコードが、すべての冗長フィールドを単一のトランザクション内で更新することを保証する。
- データベーストリガー:ソースデータが変更されたときに、冗長カラムを自動的に同期するためにトリガーを使用する。
- 定期的な照合:正規化されていないデータの不整合を監査および修正するために、スケジュールされたジョブを実行する。
- 読み取りレプリカの専用化:プライマリデータベースを完全に正規化した状態で保持し、レポート作成には正規化されていないコピーを使用する。
Q&A:高度なシナリオとトレードオフ ⚖️
基本を越えて、システムをスケーリングする際には特定のアーキテクチャ上の課題が生じます。これらの質問は、そのような細部を扱います。
Q5:同じERDに正規化されたテーブルと非正規化されたテーブルを混在させることは可能ですか? 🧩
はい、ハイブリッドモデルは本番環境で一般的です。トランザクションの整合性を保つためにコアとなる正規化されたスキーマを維持しつつ、特定の用途向けに非正規化されたビューまたは要約テーブルを作成することが標準的な手法です。
たとえば:
- コアテーブル:ユーザー、製品、注文を3NFに保つことで、正確な財務記録を確保する。
- レポート用テーブル:注文の合計と顧客情報を集約した非正規化テーブルを作成し、ダッシュボードの高速レンダリングを実現する。
- ビュー:SQLビューを使用して、データを物理的に複製せずにアプリケーションに非正規化構造を提示する。
Q6:非正規化はデータベース理論に違反しますか? 📚
理論的には、はい。関係理論は、異常を最小限に抑えるために正規化を推奨しています。しかし、実際のエンジニアリングでは、パフォーマンスのSLAを満たすためにこれらのルールを曲げることがしばしば求められます。この違反は意図的で計算されたものです。冗長性が適切に管理され、文書化されていれば、設計はその目的に対して有効なままです。
Q7:インデックスは正規化とどのように相互作用しますか? 🔖
インデックスは、正規化によるパフォーマンスコストを軽減する主な手段です。正規化を行うと外部キーが作成されます。これらの外部キーは、効率的な結合を可能にするためにインデックス化する必要があります。
以下の点を検討してください:
- 外部キーインデックス:すべての外部キーにはインデックスを設定し、結合を高速化する。
- 複合インデックス: クエリが複数の列で結合する場合、複合インデックスはすべての結合条件をカバーできます。
- 非正規化の影響: 非正規化は、外部キーインデックスの必要性をしばしば減少させ、インデックスの書き込みオーバーヘッドを削減する可能性があります。
比較:正規化対非正規化 📋
利点と欠点を明確に可視化するため、以下の表を参照してください。この構造は設計段階での意思決定を支援します。
| 機能 | 正規化 | 非正規化 |
|---|---|---|
| データの重複 | 最小化される | 増加する |
| データの整合性 | 高い | 管理が必要 |
| ストレージスペース | 効率的 | やや非効率 |
| 読み取りパフォーマンス | 遅い(結合が多い) | 速い(結合が少ない) |
| 書き込みパフォーマンス | 速い(更新するデータが少ない) | 遅い(すべてのコピーを更新する) |
| 複雑さ | 高い(多くのテーブル) | 高い(データ同期のロジック) |
| 最適な使用ケース | OLTP、トランザクション系システム | OLAP、レポート作成、読み取り中心 |
実装戦略:ステップバイステップアプローチ 🚀
スキーマの設計には体系的なプロセスが必要です。非正規化を急いで行わないでください。安定した基盤を確保するために、この構造化されたアプローチに従ってください。
ステップ1:整合性を最優先にモデル化 🏗️
まず、完全に正規化されたスキーマを作成してください。少なくとも第三正規形(3NF)を目指してください。すべてのエンティティ、属性、関係を特定してください。すべてのテーブルに主キーがあり、外部キーが適切に定義されていることを確認してください。この段階で、データの正確性と一貫性が保証されます。
ステップ2:クエリパターンの分析 🔎
スキーマを変更する前に、データがどのようにアクセスされるかを理解してください。アプリケーションの要件とクエリログを確認してください。遅いまたは複雑なクエリを特定してください。複数の結合が頻繁に必要とされるパターンを探してください。
ステップ3:インデックスの最適化 ⚡
非正規化を行う前に、正規化されたスキーマが適切にインデックス化されていることを確認してください。多くの場合、適切な複合インデックスを追加することで、テーブル構造を変更せずにパフォーマンス問題を解決できます。現在のスキーマとインデックスを使ってクエリをテストし、基準値を設定してください。
ステップ4:ターゲットされた非正規化 🎯
パフォーマンスがまだ不十分な場合、非正規化を特定して適用してください。データベース全体を非正規化しないでください。ボトルネックを引き起こしている特定のテーブルやカラムにのみ注目してください。すべての変更を記録し、将来のメンテナンスに備えてください。
ステップ5:監視と反復 📈
データベース設計は静的ではありません。時間とともにシステムを監視してください。データ量が増加したり、使用パターンが変化したりすると、バランスの調整が必要になる場合があります。パフォーマンスと整合性の要件を満たしているか、定期的にスキーマを見直してください。
避けるべき一般的な落とし穴 🚫
経験豊富なデザイナーでも、ERDの最適化を扱う際に失敗することがあります。以下の一般的な誤りに注意してください。
- 過剰な正規化:テーブルを多すぎると、スキーマが理解しにくくなり、クエリが困難になります。構造は論理的で直感的であるように保ってください。
- 不足した正規化:1つのテーブルに多すぎるデータを格納すると、更新異常や無駄なスペースが発生します。
- データの増加を無視する:1,000件のレコードで動作する設計でも、100万件になると失敗する可能性があります。スケーラビリティを計画してください。
- 隠れた非正規化:文書化せずに非正規化すると混乱を招きます。将来のメンテナスは、なぜデータが重複しているのか理解できない可能性があります。
- すべてのクエリが同等であると仮定する:すべてのクエリが同じパフォーマンス要件を持つわけではありません。最も頻繁に実行され、重要なクエリを優先してください。
スキーマアーキテクチャについての最終的な考察 🧠
正規化と非正規化のどちらを選ぶかは、二択ではありません。特定のアプリケーションのニーズに応じた、さまざまなトレードオフの連続です。適切に設計されたERDは、データの整合性とクエリ効率のバランスをとります。根本的な原則を理解し、構造化されたアプローチに従うことで、堅牢かつパフォーマンスの高いシステムを構築できます。
ツールや技術は進化するということを忘れないでください。しかし、リレーショナル設計の原則は常に一定です。データベースエンジンの機能よりも、データモデルそのものに注目してください。堅固な基盤があれば、将来のインフラ構成の変化があってもアプリケーションを支えられます。スキーマは常に清潔に、ドキュメントは明確に、パフォーマンス指標を常に意識してください。 🌟

