










प्रत्येक डेटा आर्किटेक्ट को एक ही महत्वपूर्ण क्षण का सामना करना पड़ता है। आप एक साफ, सामान्यीकृत स्कीमा के साथ शुरुआत करते हैं। डेटाबेस हजारों रिकॉर्ड को आसानी से संभालता है। प्रश्नों के उत्तर मिलते हैं मिलीसेकंड में। एंटिटी रिलेशनशिप डायग्राम (ERD) सुंदर लगता है। फिर व्यवसाय बढ़ता है। उपयोगकर्ता स्वीकृति तेजी से बढ़ती है। डेटा का आयतन फूटता है। अचानक, प्रणाली धीमी हो जाती है। जॉइन्स सेकंड में लगते हैं। लॉक लेनदेन को रोकते हैं। मूल ERD डिजाइन एक दोष बन जाता है।
यह गाइड छोटे पैमाने वाले डेटाबेस से उच्च आयतन वाले उत्पादन परिवेश में संक्रमण के विवरण प्रदान करता है। हम प्रदर्शन को बनाए रखते हुए डेटा अखंडता के नुकसान के बिना आवश्यक संरचनात्मक परिवर्तनों का अध्ययन करते हैं। ध्यान तार्किक डिजाइन, इंडेक्सिंग रणनीतियों और पार्टीशनिंग तकनीकों पर बना रहता है। यहाँ किसी विशिष्ट विक्रेता सॉफ्टवेयर का नाम नहीं लिया गया है; ये सिद्धांत किसी भी संबंधात्मक भंडारण इंजन पर लागू होते हैं।
🏗️ मूल बिंदु: विकास के लिए डिजाइन करना
जब कोई एप्लिकेशन शुरू होता है, तो विकास की गति प्राथमिकता होती है। ERD व्यवसाय क्षेत्र को सटीक रूप से प्रतिबिंबित करता है। सामान्यीकरण उच्च होता है। तीसरा सामान्य रूप (3NF) अक्सर लक्ष्य होता है। इससे अतिरिक्तता कम होती है। यह डेटा सुसंगतता सुनिश्चित करता है। हालांकि, इस दृष्टिकोण में एक विशिष्ट कार्यभार पैटर्न के बारे में मान्यता है। यह मानता है कि प्रश्न सरल हैं। यह मानता है कि डेटासेट स्मृति में आराम से फिट होता है।
जैसे ही डेटासेट बढ़ता है, मान्यताएं विफल हो जाती हैं। जॉइन्स की लागत लघुगणकीय रूप से बढ़ती है। प्रश्न प्रोसेसर द्वारा स्कैन किए जाने वाले डेटा का आयतन रैखिक रूप से बढ़ता है। डिस्क I/O बाधा बन जाता है। आर्किटेक्चर को तार्किक शुद्धता से भौतिक प्रदर्शन की ओर बदलाव की आवश्यकता होती है।
टूटने के बिंदु की पहचान करना
पुनर्गठन से पहले, आपको यह समझना होगा कि प्रणाली कहाँ विफल होती है। हजारों से लाखों रिकॉर्ड तक संक्रमण डेटा प्राप्ति के भौतिकी को बदल देता है। इन संकेतों को देखें:
- प्रश्न लेटेंसी:जो प्रश्न 5ms में लेते थे, अब 500ms लेते हैं।
- लॉक प्रतिस्पर्धा:लेनदेन लॉक रिलीज करने का इंतजार करते हैं।
- लेखन थ्रूपुट:इंडेक्स रखरखाव के कारण इन्सर्ट धीमे हो जाते हैं।
- मेमोरी दबाव:बफर पूल अक्सर एक्सेस किए जाने वाले तालिकाओं को कैश नहीं कर सकता है।
- नेटवर्क संतृप्ति:बड़े परिणाम सेट बैंडविड्थ का उपयोग करते हैं।
जब ये लक्षण दिखाई देते हैं, तो ERD का विकास करना होगा। आप बस अधिक हार्डवेयर जोड़कर नहीं बच सकते। आपको संरचना को अनुकूलित करना होगा।
🔍 चरण 1: स्कीमा पुनर्गठन
स्केलिंग का पहला चरण एंटिटी रिलेशनशिप डायग्राम की समीक्षा करना है। आपको यह सत्यापित करने की आवश्यकता है कि वर्तमान संरचना स्केल पर आवश्यक प्रश्न पैटर्न का समर्थन करती है या नहीं।
सामान्यीकरण बनाम असामान्यीकरण
सामान्यीकरण डेटा दोहराव को कम करता है। यह अपडेट को सरल बनाता है। हालांकि, यह जॉइन्स को बाध्य करता है। स्केल पर जॉइन्स महंगे होते हैं। असामान्यीकरण अतिरिक्तता लाता है। यह जॉइन्स को कम करता है। यह पढ़ने की गति बढ़ाता है। यह एक व्यापार बदलाव है जिसे ध्यान से प्रबंधित करने की आवश्यकता होती है।
n
निम्नलिखित रणनीतियों पर विचार करें:
- पढ़ने-भारी कार्यभार:अक्सर एक्सेस किए जाने वाले गुणों को असामान्यीकृत करें। उन्हें मुख्य तालिका में सीधे संग्रहीत करें ताकि जॉइन्स से बचा जा सके।
- लेखन-भारी कार्यभार:सामान्यीकरण बनाए रखें। एकाधिक तालिकाओं के माध्यम से चेन अपडेट से बचें।
- हाइब्रिड दृष्टिकोण: मुख्य स्कीमा को सामान्यीकृत रखें। रिपोर्टिंग के लिए सामग्री दृश्य या सारांश तालिकाएं बनाएं।
हमारे केस स्टडी में, मूल डिजाइन में एक ही उपयोगकर्ता प्रोफाइल को प्राप्त करने के लिए दस तालिकाओं को जोड़ा गया था। इससे अत्यधिक डिस्क I/O हुआ। सबसे आम उपयोगकर्ता विशेषताओं को मुख्य प्रोफाइल तालिका में असामान्य बनाकर, हमने जॉइन की संख्या दस से एक कर दी।
बड़े टेक्स्ट फील्ड्स का प्रबंधन
मुख्य तालिका में बड़े स्ट्रिंग्स (CLOBs) स्टोर करने से पेज पढ़ने की गति धीमी हो सकती है। डेटाबेस इंजन को प्राथमिक कुंजी की जांच करने के लिए पूरी पंक्ति लोड करनी होती है। यदि पंक्ति बहुत बड़ी है, तो यह डिस्क पर बह भी सकती है।
सर्वोत्तम अभ्यास शामिल हैं:
- बड़े टेक्स्ट फील्ड्स को एक जुड़ी तालिका में अलग करें।
- केवल तब तक टेक्स्ट फील्ड को प्राप्त करें जब उसे स्पष्ट रूप से मांगा जाए।
- मुख्य इंडेक्स में सामग्री के बजाय संदर्भ (आईडी) स्टोर करें।
📈 चरण 2: इंडेक्सिंग रणनीतियाँ
इंडेक्स प्रश्न प्रदर्शन का इंजन हैं। अच्छी तरह से डिजाइन किए गए ईआरडी को डेटा को तेजी से खोजने के लिए इंडेक्स पर निर्भर रहना होता है। जैसे-जैसे रिकॉर्ड बढ़ते हैं, इंडेक्स का आकार बढ़ता है। इंडेक्स को बनाए रखने में लेखन संसाधनों का उपयोग होता है।
कॉम्पोजिट इंडेक्स
एकल-स्तंभ इंडेक्स अक्सर पर्याप्त नहीं होते हैं। कॉम्पोजिट इंडेक्स इंजन को एक साथ कई मानदंडों पर फ़िल्टर करने की अनुमति देते हैं। इंडेक्स में स्तंभों का क्रम महत्वपूर्ण होता है। सबसे अधिक चयनकारी स्तंभ पहले आना चाहिए।
उदाहरण के लिए, यदि आप स्थिति और तारीख, लेकिन स्थिति की चयनकारिता कम है (उदाहरण के लिए, केवल तीन मान हैं), तो तारीख पहले रखें। इससे खोज के क्षेत्र को तेजी से सीमित किया जा सकता है।
कवरिंग इंडेक्स
एक कवरिंग इंडेक्स में प्रश्न द्वारा आवश्यक सभी स्तंभ शामिल होते हैं। डेटाबेस केवल इंडेक्स का उपयोग करके प्रश्न को संतुष्ट कर सकता है। इसे तालिका डेटा (हीप) को छूने की आवश्यकता नहीं होती है। यह एक महत्वपूर्ण प्रदर्शन लाभ है।
- सभी को शामिल करें
SELECTस्तंभ। - सभी को शामिल करें
WHEREक्लॉज स्तंभ। - सभी को शामिल करें
क्रम द्वारा व्यवस्थित करेंस्तंभ।
インडेक्स रखरखाव
इंडेक्स स्थिर नहीं होते हैं। समय के साथ वे टूट जाते हैं। डेटा के साथ वे बढ़ते हैं। नियमित रखरखाव की आवश्यकता होती है।
- पुनर्निर्माण: इंडेक्स संरचना को फिर से बनाता है।
- पुनर्व्यवस्थित करना: पूर्ण पुनर्निर्माण के बिना पत्ती पृष्ठों को फिर से क्रमबद्ध करता है।
- निगरानी: अनियोजित इंडेक्स का अनुसरण करें। लेखन स्थान बचाने के लिए उन्हें हटाएं।
🗄️ चरण 3: विभाजन और शैडिंग
जब एक तालिका एकल डिस्क या मेमोरी पूल की क्षमता को पार कर जाती है, तो विभाजन आवश्यक हो जाता है। इससे एक तार्किक तालिका को छोटे-छोटे भौतिक खंडों में विभाजित किया जाता है।
रेंज विभाजन
इस विधि में डेटा को एक रेंज मान के आधार पर विभाजित किया जाता है। इसका उपयोग आमतौर पर तारीखों या क्रमागत आईडी के लिए किया जाता है। उदाहरण के लिए, वर्ष के आधार पर डेटा को विभाजित करना।
- लाभ: पार्टीशन की चयन करने वाले प्रश्न केवल एक सेगमेंट को स्कैन करते हैं।
- नुकसान: पार्टीशन की चयन करने वाले प्रश्न सभी सेगमेंट को स्कैन करते हैं (पूरी तालिका स्कैन)।
हैश विभाजन
इस विधि में एक की कॉलम पर हैश फंक्शन का उपयोग करके डेटा को सेगमेंट्स के बीच समान रूप से वितरित किया जाता है। इससे हॉटस्पॉट्स को रोका जाता है।
- लाभ: डेटा का समान वितरण।
- नुकसान: रेंज प्रश्न महंगे हो जाते हैं।
क्षैतिज बनाम लंबवत शैडिंग
शैडिंग डेटा को कई डेटाबेस इंस्टेंसेज के बीच वितरित करके विभाजन को आगे बढ़ाती है।
| रणनीति | विवरण | सर्वोत्तम उपयोग केस |
|---|---|---|
| क्षैतिज शैडिंग | एक कुंजी के आधार पर डेटाबेस में पंक्तियों को विभाजित करें। | उच्च लेखन आयतन, बड़े डेटासेट। |
| ऊर्ध्वाधर शार्डिंग | उपयोग के आधार पर डेटाबेस में कॉलम को विभाजित करें। | बड़े कॉलम, अलग पढ़ने के पैटर्न। |
| निर्देशिका शार्डिंग | प्रश्नों को रूट करने के लिए एक लुकअप तालिका का उपयोग करें। | जटिल रूटिंग तर्क, डायनामिक स्केलिंग। |
हमारे केस स्टडी में, हमने उपयोगकर्ता ID के आधार पर क्षैतिज शार्डिंग कार्यान्वित की। इससे हमें पांच नोड्स के बीच लोड को वितरित करने की अनुमति मिली। प्रत्येक नोड लगभग 20% ट्रैफिक को संभालता था। इससे किसी भी एक स्टोरेज इंजन पर लोड कम हुआ।
🚀 चरण 4: प्रश्न अनुकूलन
एक सही स्कीमा के साथ भी, बुरे प्रश्न प्रदर्शन को मार देते हैं। ऑप्टिमाइज़र निष्पादन योजना चुनता है। आपको इसे मार्गदर्शन करना होगा।
पूरी तालिका स्कैन से बचें
हमेशा सुनिश्चित करें कि एक प्रश्न एक सूचकांक का उपयोग करता है। यदि यह पूरी तालिका को स्कैन करता है, तो बड़े पैमाने पर यह समय सीमा समाप्त हो जाएगा। निष्पादन योजना की जांच करें। “Index Scan” या “Index Seek” के बजाय “Table Scan” की बजाय देखें।
परिणाम सेट को सीमित करना
कभी भी सभी रिकॉर्ड न लें। पृष्ठांकन का उपयोग करें। प्रत्येक अनुरोध के लिए लौटाए गए पंक्तियों की संख्या को सीमित करें।
- ऑफसेट सीमा: मानक पृष्ठांकन। गहरे ऑफसेट पर धीमा हो सकता है।
- कीसेट पृष्ठांकन: अगला पृष्ठ प्राप्त करने के लिए अंतिम देखा गया ID का उपयोग करें। बहुत तेज।
ऑपरेशन को बैच में करें
एक ही लेनदेन में लाखों अपडेट न करें। उन्हें बैच में बांटें।
- प्रत्येक 1,000 रिकॉर्ड के बाद कॉमिट करें।
- इससे लॉग फाइल के विस्तार को कम किया जाता है।
- इससे लंबे समय तक चलने वाले लॉक को रोका जाता है।
⚠️ बचने के लिए सामान्य त्रुटियां
स्केलिंग नए जोखिम लाता है। इन सामान्य गलतियों के बारे में जागरूक रहें।
- अत्यधिक सूचकांक लगाना: बहुत सारे सूचकांक लेखन को धीमा कर देते हैं। लेखन प्रदर्शन को मॉनिटर करें।
- डेटा प्रकारों के बारे में ध्यान न देना: उपयोग करना
VARCHARनिश्चित लंबाई के आईडी के लिए स्थान का बर्बाद करता है। उपयोग करेंINTयाBIGINT. - एन+1 क्वेरीज़: लूप में संबंधित डेटा को प्राप्त करना। एजी लोडिंग या बैच जॉइन्स का उपयोग करें।
- सॉफ्ट डिलीट्स: रिकॉर्ड्स को हटाए जाने के रूप में चिह्नित करने से उन्हें टेबल में हमेशा के लिए रखा जाता है। पुराने डेटा को आर्काइव करें।
- लॉकिंग स्कीमाज़: सिस्टम चल रहे होने के दौरान टेबल संरचना बदलना। ऑनलाइन स्कीमा बदलाव का उपयोग करें।
📊 प्रदर्शन मापदंडों को ट्रैक करना
आप उसका सुधार नहीं कर सकते जिसका आप माप नहीं करते। एक बेसलाइन स्थापित करें। इन मापदंडों को निरंतर ट्रैक करें।
- प्रति सेकंड पंक्तियाँ: डेटा कितनी तेजी से लिखे जा रहे हैं?
- प्रति सेकंड क्वेरीज़: कितना रीड ट्रैफिक मौजूद है?
- कैश हिट अनुपात: क्या पढ़ाई मेमोरी या डिस्क पर हो रही है?
- लॉक वेट समय: क्या लेनदेन संसाधनों का इंतजार कर रहे हैं?
- डिस्क आई/ओ: क्या स्टोरेज संतृप्त है?
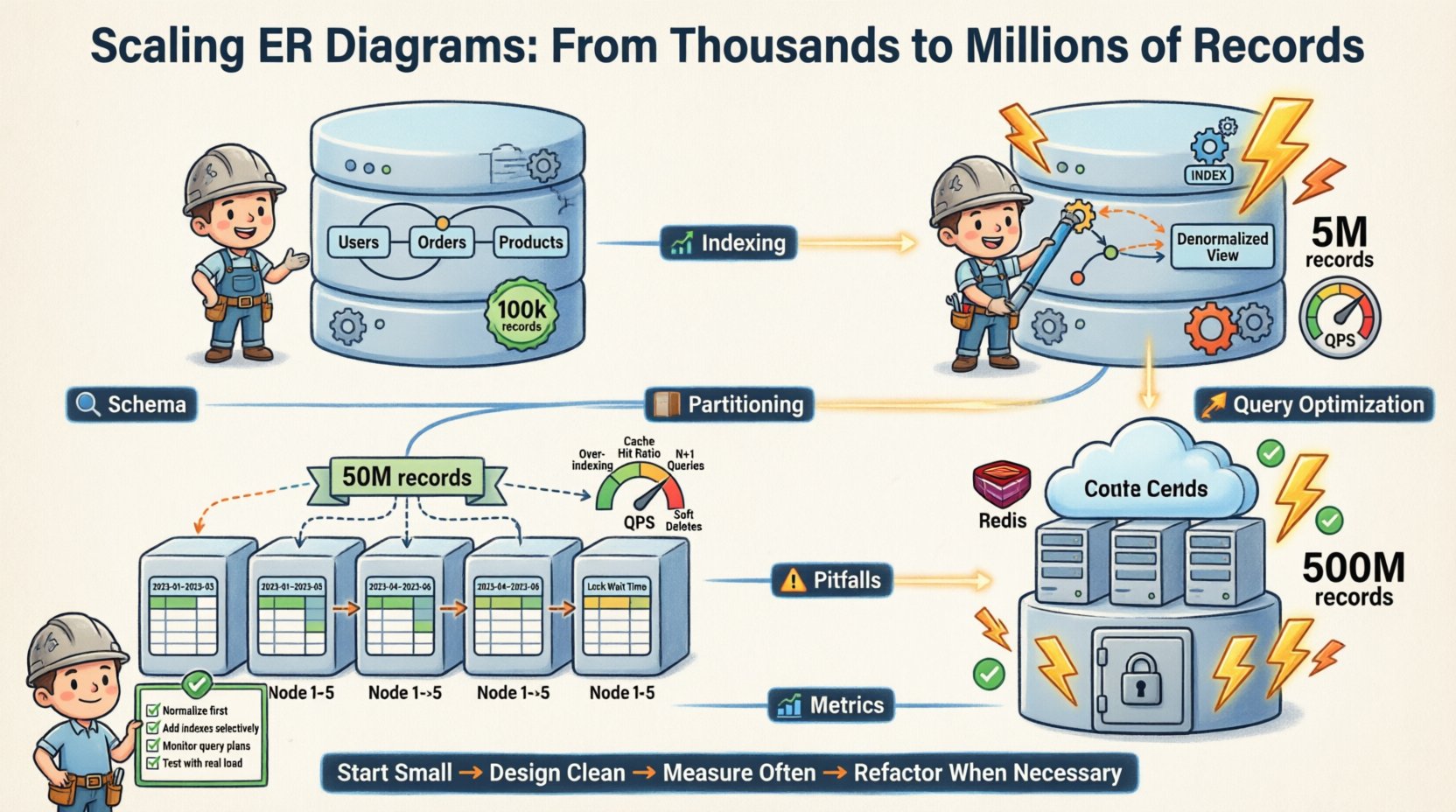
🔄 ईआरडी का विकास
एंटिटी रिलेशनशिप डायग्राम एक स्थिर दस्तावेज़ नहीं है। यह एक जीवंत नक्शा है। जैसे ही सिस्टम का पैमाना बढ़ता है, ईआरडी बदलता है।
यहाँ हमारे स्कीमा विकास की प्रगति है:
- चरण 1 (शुरुआत): पूरी तरह से सामान्यीकृत। 3NF। एकल डेटाबेस इंस्टेंस। 100k रिकॉर्ड।
- चरण 2 (वृद्धि): पढ़ने वाली तालिकाओं के अनियमित रूप से बदलना। सूचकांक जोड़े गए। एकल प्रतिनिधि। 5M रिकॉर्ड।
- चरण 3 (स्केल): क्षैतिज विभाजन। उपयोगकर्ता ID द्वारा शैड। बहु-प्रतिनिधि। 50M रिकॉर्ड।
- चरण 4 (परिपक्वता): पुराने डेटा को संग्रहीत करना। कैशिंग परत का एकीकरण। पढ़ने के लिए प्रतिकृति। 500M रिकॉर्ड।
प्रत्येक चरण में तार्किक मॉडल में विशिष्ट परिवर्तन की आवश्यकता थी। मूल संबंध स्थिर रहे। भौतिक कार्यान्वयन अनुकूलित हुआ।
🛠️ स्केलिंग के लिए चेकलिस्ट
उच्च आयतन वाले वातावरण में डेप्लॉय करने से पहले इस चेकलिस्ट का उपयोग करें।
- ☐ सभी विदेशी कुंजियों के समर्थन करने वाले सूचकांक हैं या नहीं जांचें।
- ☐ जांचें कि
SELECT *एप्लिकेशन कोड में है। - ☐ यह सुनिश्चित करें कि विभाजन कुंजियां समान रूप से वितरित हैं।
- ☐ डेटाबेस नोड्स के फेलओवर परिदृश्यों का परीक्षण करें।
- ☐ कनेक्शन पूल सेटिंग्स की समीक्षा करें।
- ☐ डेटा संग्रहीत करने और साफ करने की योजना बनाएं।
- ☐ धीमे प्रश्नों के लिए मॉनिटरिंग चेतावनी कार्यान्वयन करें।
- ☐ स्कीमा परिवर्तन प्रक्रियाओं को दस्तावेज़ीकृत करें।
💡 विश्वसनीयता पर अंतिम विचार
ER आरेख को स्केल करना केवल गति के बारे में नहीं है। यह विश्वसनीयता के बारे में है। एक तेज़ प्रणाली जो भार के तहत गिर जाती है, बेकार है। एक धीमी परंतु स्थिर प्रणाली प्रबंधनीय है।
लक्ष्य वृद्धि की अपेक्षा करते हुए एक संरचना डिज़ाइन करना है। आपको स्टोरेज की लागत के बीच संतुलन बनाना होगा और गणना की लागत। आपको सुसंगतता और उपलब्धता के बीच संतुलन बनाना होगा। ये वितरित प्रणालियों के मूल व्यापार बदलाव हैं।
इन सिद्धांतों का पालन करके, आप यह सुनिश्चित कर सकते हैं कि आपकी डेटा संरचना लचीली बनी रहे। आप हजारों से मिलियन तक के संक्रमण को बिना टूटे संभाल सकते हैं। महत्वपूर्ण बात तैयारी है। महत्वपूर्ण बात परीक्षण है। महत्वपूर्ण बात आपके स्टोरेज इंजन के आधारभूत तकनीक को समझना है।
छोटे से शुरू करें। साफ डिज़ाइन करें। अक्सर मापें। आवश्यकता होने पर पुनर्गठित करें। यह स्थायी स्केल का रास्ता है।

