










Setiap arsitek data menghadapi momen penting yang sama. Anda memulai dengan skema yang bersih dan ternormalisasi. Basis data menangani ribuan rekaman dengan mudah. Permintaan mengembalikan hasil dalam milidetik. Diagram Hubungan Entitas (ERD) terlihat elegan. Lalu, bisnis berkembang. Adopsi pengguna melonjak. Volume data meledak. Tiba-tiba, sistem melambat. Gabungan (join) memakan waktu detik. Kunci (lock) menghambat transaksi. Desain ERD awal menjadi beban.
Panduan ini menjelaskan transisi dari basis data skala kecil ke lingkungan produksi volume tinggi. Kami mengeksplorasi perubahan struktural yang diperlukan untuk mempertahankan kinerja tanpa mengorbankan integritas data. Fokus tetap pada desain logis, strategi indeks, dan teknik partisi. Tidak ada perangkat lunak vendor tertentu yang disebutkan di sini; prinsip-prinsip ini berlaku untuk mesin penyimpanan relasional apa pun.
🏗️ Dasar: Merancang untuk Pertumbuhan
Ketika sebuah aplikasi dimulai, prioritasnya adalah kecepatan pengembangan. ERD mencerminkan domain bisnis secara akurat. Normalisasi tinggi. Bentuk Normal Ketiga (3NF) sering menjadi tujuan. Ini meminimalkan duplikasi. Menjamin konsistensi data. Namun, pendekatan ini mengasumsikan pola kerja tertentu. Mengasumsikan permintaan sederhana. Mengasumsikan dataset muat dengan nyaman di memori.
Saat dataset membesar, asumsi-asumsi itu gagal. Biaya join meningkat secara logaritmik. Volume data yang dipindai oleh prosesor permintaan tumbuh secara linear. I/O disk menjadi penghalang utama. Arsitektur membutuhkan pergeseran dari kemurnian logis ke kinerja fisik.
Mengidentifikasi Titik Pemecahan
Sebelum melakukan refaktor, Anda harus memahami di mana sistem gagal. Transisi dari ribuan hingga jutaan rekaman mengubah fisika pengambilan data. Perhatikan indikator-indikator berikut:
- Latensi Permintaan: Permintaan yang sebelumnya memakan 5ms kini memakan 500ms.
- Persaingan Kunci: Transaksi menunggu kunci dilepaskan.
- Throughput Tulis: Penyisipan melambat karena pemeliharaan indeks.
- Tekanan Memori: Pool buffer tidak dapat menyimpan tabel yang sering diakses.
- Jenuh Jaringan: Hasil permintaan besar menghabiskan bandwidth.
Ketika gejala-gejala ini muncul, ERD harus berkembang. Anda tidak bisa hanya menambah perangkat keras. Anda harus mengoptimalkan struktur.
🔍 Tahap 1: Refaktor Skema
Langkah pertama dalam peningkatan adalah meninjau Diagram Hubungan Entitas. Anda perlu memverifikasi apakah struktur saat ini mendukung pola permintaan yang dibutuhkan pada skala besar.
Normalisasi vs. Denormalisasi
Normalisasi mengurangi duplikasi data. Mempermudah pembaruan. Namun, memaksa penggunaan join. Join mahal pada skala besar. Denormalisasi memperkenalkan redundansi. Mengurangi join. Mempercepat pembacaan. Ini adalah pertukaran yang harus dikelola secara hati-hati.
n
Pertimbangkan strategi-strategi berikut:
- Beban Baca Berat: Denormalisasi atribut yang sering diakses. Simpan langsung di tabel utama untuk menghindari join.
- Beban Tulis Berat: Pertahankan normalisasi. Hindari pembaruan yang menyebar ke beberapa tabel.
- Pendekatan Hibrida: Pertahankan skema inti dalam bentuk normal. Buat tampilan yang dibuat secara material atau tabel ringkasan untuk pelaporan.
Dalam studi kasus kami, desain awal memiliki sepuluh tabel yang digabungkan untuk mengambil satu profil pengguna. Hal ini menyebabkan I/O disk yang berlebihan. Dengan mendeknormalisasi atribut pengguna yang paling umum ke dalam tabel profil utama, kami mengurangi jumlah penggabungan dari sepuluh menjadi satu.
Penanganan Bidang Teks Besar
Menyimpan string besar (CLOBs) di tabel utama dapat memperlambat pembacaan halaman. Mesin basis data harus memuat seluruh baris untuk memeriksa kunci utama. Jika baris terlalu besar, dapat tumpah ke disk.
Praktik terbaik meliputi:
- Pisahkan bidang teks besar ke dalam tabel terhubung.
- Hanya ambil bidang teks ketika diminta secara eksplisit.
- Simpan referensi (ID) alih-alih konten di indeks utama.
📈 Fase 2: Strategi Indeks
Indeks adalah mesin kinerja kueri. ERD yang dirancang dengan baik bergantung pada indeks untuk menemukan data dengan cepat. Seiring pertumbuhan catatan, ukuran indeks juga meningkat. Pemeliharaan indeks mengonsumsi sumber daya tulis.
Indeks Komposit
Indeks kolom tunggal sering kali tidak cukup. Indeks komposit memungkinkan mesin untuk menyaring berdasarkan beberapa kriteria secara bersamaan. Urutan kolom dalam indeks sangat penting. Kolom yang paling selektif sebaiknya ditempatkan di awal.
Sebagai contoh, jika Anda menyaring berdasarkan status dan tanggal, tetapi status memiliki selektivitas rendah (misalnya, hanya tiga nilai), tempatkan tanggalpertama. Ini mempersempit ruang pencarian lebih cepat.
Indeks Meliputi
Indeks meliputi mencakup semua kolom yang dibutuhkan oleh kueri. Basis data dapat memenuhi kueri hanya menggunakan indeks. Tidak perlu menyentuh data tabel (heap). Ini merupakan peningkatan kinerja yang signifikan.
- Sertakan semua
SELECTkolom. - Sertakan semua
WHEREkolom klausa. - Sertakan semua
URUTKAN BERDASARKANkolom.
Pemeliharaan Indeks
Indeks tidak bersifat statis. Mereka mengalami fragmentasi seiring waktu. Mereka tumbuh seiring data. Pemeliharaan rutin diperlukan.
- Membangun Ulang:Menghilangkan fragmentasi struktur indeks.
- Mengatur Ulang:Mengurutkan ulang halaman daun tanpa pembangunan ulang penuh.
- Pemantauan: Lacak indeks yang tidak digunakan. Hapus mereka untuk menghemat ruang tulis.
🗄️ Fase 3: Partisi dan Sharding
Ketika satu tabel melebihi kapasitas satu disk atau pool memori, partisi menjadi diperlukan. Ini membagi satu tabel logis menjadi bagian-bagian fisik yang lebih kecil.
Partisi Berdasarkan Rentang
Metode ini membagi data berdasarkan nilai rentang. Umum digunakan untuk tanggal atau ID berurutan. Misalnya, membagi data berdasarkan tahun.
- Manfaat:Kueri yang menyaring berdasarkan kunci partisi hanya memindai satu segmen.
- Kekurangan:Kueri tanpa kunci partisi memindai semua segmen (pemindaian tabel penuh).
Partisi Berdasarkan Hash
Ini mendistribusikan data secara merata di seluruh segmen menggunakan fungsi hash pada kolom kunci. Ini mencegah hotspot.
- Manfaat:Distribusi data yang merata.
- Kekurangan:Kueri rentang menjadi mahal.
Sharding Horizontal vs. Vertikal
Sharding mengambil partisi lebih jauh dengan mendistribusikan data di seluruh beberapa instance basis data.
| Strategi | Deskripsi | Kasus Penggunaan Terbaik |
|---|---|---|
| Sharding Horizontal | Memisahkan baris di antara basis data berdasarkan kunci. | Volume tulis tinggi, dataset besar. |
| Pembagian Vertikal | Memisahkan kolom di antara basis data berdasarkan penggunaan. | Kolom besar, pola baca yang berbeda. |
| Pembagian Direktori | Gunakan tabel pencarian untuk mengarahkan kueri. | Logika pengalihan yang kompleks, skala dinamis. |
Dalam studi kasus kami, kami menerapkan pembagian horizontal berdasarkan ID pengguna. Ini memungkinkan kami mendistribusikan beban di antara lima node. Setiap node menangani sekitar 20% lalu lintas. Ini mengurangi beban pada mesin penyimpanan tunggal.
🚀 Fase 4: Optimasi Kueri
Bahkan dengan skema yang sempurna, kueri buruk membunuh kinerja. Optimizer memilih rencana eksekusi. Anda harus membimbingnya.
Menghindari Pemindaian Seluruh Tabel
Pastikan kueri selalu menggunakan indeks. Jika melakukan pemindaian seluruh tabel, akan mengalami timeout saat skala besar. Periksa rencana eksekusi. Cari ‘Pemindaian Indeks’ atau ‘Pencarian Indeks’ alih-alih ‘Pemindaian Tabel’.
Membatasi Hasil Kueri
Jangan pernah mengambil semua catatan. Gunakan pembagian halaman. Batasi jumlah baris yang dikembalikan per permintaan.
- Offset Batas:Pembagian halaman standar. Bisa lambat pada offset yang dalam.
- Pembagian Halaman Berbasis Kunci:Gunakan ID terakhir yang dilihat untuk mengambil halaman berikutnya. Jauh lebih cepat.
Pengelompokan Operasi
Jangan lakukan jutaan pembaruan dalam satu transaksi. Pisahkan menjadi batch.
- Komit setelah setiap 1.000 catatan.
- Ini mengurangi pertumbuhan ukuran file log.
- Ini mencegah terjadinya kunci yang berjalan lama.
⚠️ Kesalahan Umum yang Harus Dihindari
Skala menimbulkan risiko baru. Waspadai kesalahan umum ini.
- Indeks Berlebihan:Terlalu banyak indeks memperlambat tulisan. Pantau kinerja tulisan.
- Mengabaikan Tipe Data: Menggunakan
VARCHARuntuk ID dengan panjang tetap membuang ruang. GunakanINTatauBIGINT. - Kueri N+1: Mengambil data terkait dalam loop. Gunakan pemuatan cepat atau penggabungan batch.
- Penghapusan Lembut: Menandai catatan sebagai dihapus menyimpannya di tabel selamanya. Arsipkan data lama.
- Skema Penguncian: Mengubah struktur tabel saat sistem sedang berjalan. Gunakan perubahan skema online.
📊 Metrik Kinerja yang Harus Dipantau
Anda tidak dapat meningkatkan apa yang tidak diukur. Tetapkan dasar pengukuran. Pantau metrik ini secara terus-menerus.
- Baris per Detik:Seberapa cepat data sedang ditulis?
- Kueri per Detik:Berapa banyak lalu lintas baca yang ada?
- Rasio Kenaikan Cache:Apakah bacaan mengenai memori atau disk?
- Waktu Tunggu Kunci:Apakah transaksi menunggu sumber daya?
- I/O Disk:Apakah penyimpanan sudah jenuh?
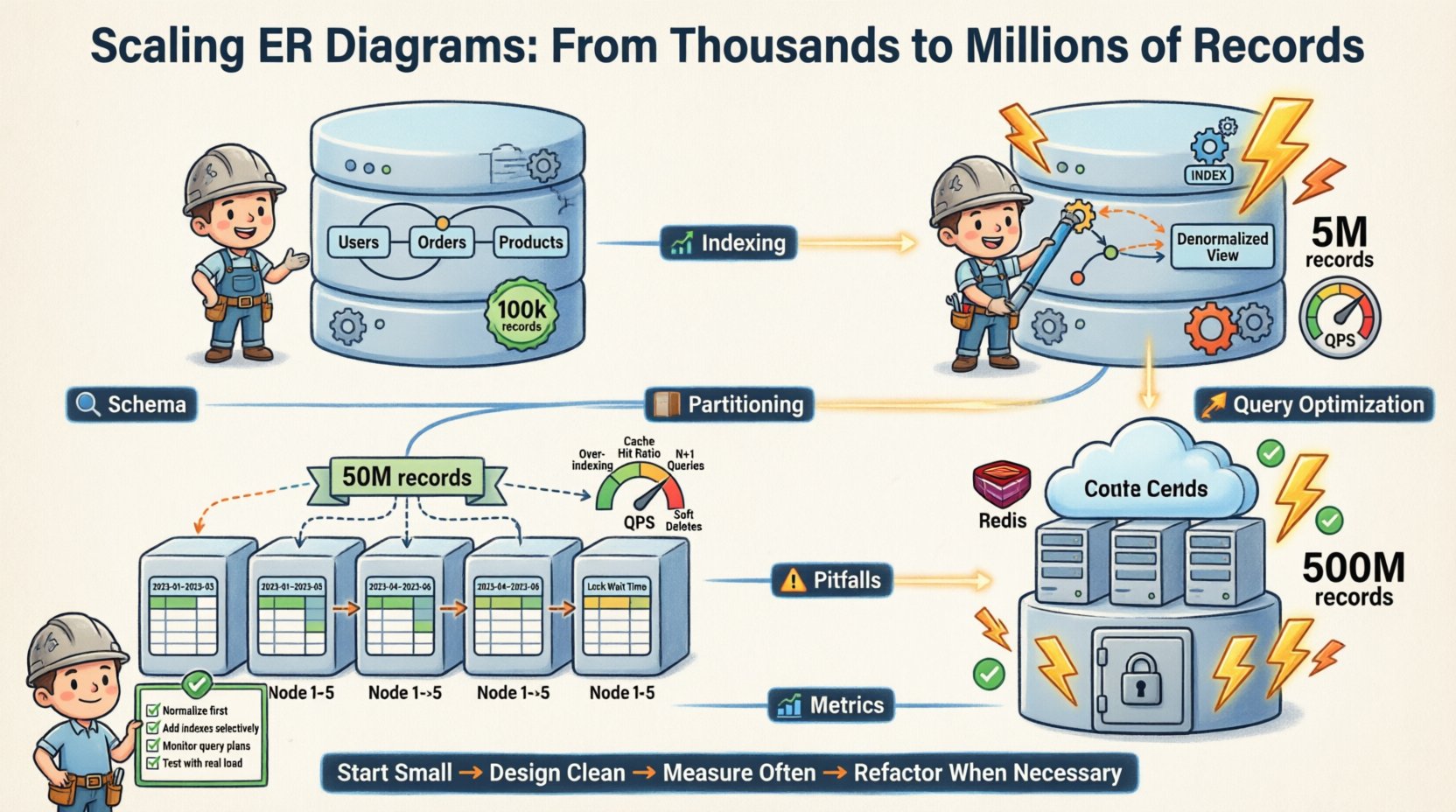
🔄 Evolusi ERD
Diagram Hubungan Entitas bukan dokumen statis. Ini adalah gambaran hidup. Saat sistem berkembang, ERD berubah.
Berikut adalah perkembangan evolusi skema kita:
- Fase 1 (Mulai):Benar-benar dinormalisasi. 3NF. Satu instance basis data. 100k catatan.
- Fase 2 (Pertumbuhan): Denormalisasi tabel yang banyak dibaca. Menambahkan indeks. Instans tunggal. 5 juta catatan.
- Fase 3 (Skala):Pembagian horizontal. Dibagi berdasarkan ID pengguna. Banyak instans. 50 juta catatan.
- Fase 4 (Kematangan):Arsip data lama. Integrasi lapisan caching. Replika baca. 500 juta catatan.
Setiap fase membutuhkan perubahan khusus pada model logis. Hubungan inti tetap stabil. Implementasi fisik beradaptasi.
🛠️ Daftar Periksa untuk Skala
Gunakan daftar periksa ini sebelum menerapkan ke lingkungan dengan volume tinggi.
- ☐ Verifikasi semua kunci asing memiliki indeks pendukung.
- ☐ Periksa untuk
SELECT *di kode aplikasi. - ☐ Pastikan kunci pembagian didistribusikan secara merata.
- ☐ Uji skenario failover untuk node basis data.
- ☐ Tinjau pengaturan pool koneksi.
- ☐ Rencanakan arsip data dan pembersihan.
- ☐ Implementasikan peringatan pemantauan untuk kueri lambat.
- ☐ Dokumentasikan prosedur perubahan skema.
💡 Pikiran Akhir tentang Keandalan
Mengembangkan diagram ER bukan hanya soal kecepatan. Ini tentang keandalan. Sistem yang cepat tetapi runtuh saat beban tinggi tidak berguna. Sistem yang lambat tetapi stabil bisa dikelola.
Tujuannya adalah merancang struktur yang memprediksi pertumbuhan. Anda harus menyeimbangkan biaya penyimpanan terhadap biaya komputasi. Anda harus menyeimbangkan konsistensi terhadap ketersediaan. Ini adalah pertukaran mendasar dalam sistem terdistribusi.
Dengan mengikuti prinsip-prinsip ini, Anda dapat memastikan arsitektur data Anda tetap kuat. Anda dapat menghadapi transisi dari ribuan menjadi jutaan tanpa gagal. Kuncinya adalah persiapan. Kuncinya adalah pengujian. Kuncinya adalah memahami mekanisme dasar dari mesin penyimpanan Anda.
Mulai kecil. Rancang bersih. Ukur secara rutin. Refaktor jika diperlukan. Ini adalah jalan menuju skala yang berkelanjutan.

