










Jeder Datenarchitekt steht vor demselben entscheidenden Moment. Sie beginnen mit einem sauberen, normalisierten Schema. Die Datenbank verarbeitet Tausende von Datensätzen mühelos. Abfragen ergeben sich in Millisekunden. Das Entity-Relationship-Diagramm (ERD) wirkt elegant. Dann wächst das Geschäft. Die Nutzerakzeptanz steigt sprunghaft. Die Datenmenge explodiert. Plötzlich verlangsamt sich das System. Joins dauern Sekunden. Sperrungen blockieren Transaktionen. Das ursprüngliche ERD-Design wird zur Belastung.
Diese Anleitung beschreibt den Übergang von einer kleinen Datenbank zu einer Hochvolumenumgebung in der Produktion. Wir untersuchen die strukturellen Änderungen, die erforderlich sind, um die Leistung zu erhalten, ohne die Datenintegrität zu gefährden. Der Fokus bleibt auf der logischen Gestaltung, Indexstrategien und Partitionierungstechniken. Hier werden keine spezifischen Hersteller-Softwareprodukte genannt; die Prinzipien gelten für jedes relationale Speichersystem.
🏗️ Die Grundlage: Gestaltung für Wachstum
Wenn eine Anwendung beginnt, hat die Entwicklungsbeschleunigung Priorität. Das ERD spiegelt den Geschäftsbereich genau wider. Die Normalisierung ist hoch. Dritte Normalform (3NF) ist oft das Ziel. Dies minimiert Redundanz. Es gewährleistet Datenkonsistenz. Dieser Ansatz setzt jedoch ein bestimmtes Lastmuster voraus. Er geht davon aus, dass Abfragen einfach sind. Er nimmt an, dass die Datensammlung bequem im Speicher Platz findet.
Wenn die Datensammlung wächst, versagen die Annahmen. Die Kosten für Joins steigen logarithmisch. Das Datenvolumen, das vom Abfrageprozessor abgerufen wird, wächst linear. Die Festplatten-I/O wird zur Engstelle. Die Architektur erfordert eine Verschiebung von logischer Reinheit hin zu physischer Leistung.
Erkennen des Ausfalls
Bevor Sie umstrukturieren, müssen Sie verstehen, wo das System versagt. Der Übergang von Tausenden zu Millionen von Datensätzen verändert die Physik der Datenabrufung. Achten Sie auf diese Indikatoren:
- Abfrageverzögerung:Abfragen, die 5 ms dauerten, dauern nun 500 ms.
- Sperrkonflikte:Transaktionen warten darauf, dass Sperrungen freigegeben werden.
- Schreibdurchsatz:Einfügungen verlangsamen sich aufgrund der Indexpflege.
- Speicherdruck:Der Pufferpool kann häufig genutzte Tabellen nicht zwischenspeichern.
- Netzwerküberlastung:Große Ergebnismengen verbrauchen Bandbreite.
Wenn diese Symptome auftreten, muss das ERD sich weiterentwickeln. Sie können nicht einfach mehr Hardware hinzufügen. Sie müssen die Struktur optimieren.
🔍 Phase 1: Schema-Refaktorisierung
Der erste Schritt bei der Skalierung ist die Prüfung des Entity-Relationship-Diagramms. Sie müssen überprüfen, ob die aktuelle Struktur die Abfragemuster unterstützt, die bei großer Skalierung erforderlich sind.
Normalisierung vs. Denormalisierung
Die Normalisierung reduziert Datenredundanz. Sie vereinfacht Aktualisierungen. Allerdings zwingt sie zu Joins. Joins sind bei großer Skalierung kostspielig. Die Denormalisierung führt zu Redundanz. Sie reduziert Joins. Sie beschleunigt Lesevorgänge. Dies ist ein Kompromiss, der sorgfältig verwaltet werden muss.
n
Berücksichtigen Sie die folgenden Strategien:
- Leseintensive Workloads:Denormalisieren Sie häufig abgerufene Attribute. Speichern Sie sie direkt in der Haupttabelle, um Joins zu vermeiden.
- Schreibintensive Workloads:Bewahren Sie die Normalisierung bei. Vermeiden Sie kaskadierende Aktualisierungen über mehrere Tabellen hinweg.
- Hybrider Ansatz: Halten Sie das Kernschema normalisiert. Erstellen Sie materialisierte Ansichten oder Zusammenfassungstabellen für Berichterstattung.
In unserer Fallstudie hatte das ursprüngliche Design zehn Tabellen, die zusammengefügt wurden, um ein einzelnes Benutzerprofil abzurufen. Dies verursachte übermäßigen Festplatten-I/O. Durch die Denormalisierung der häufigsten Benutzerattribute in die Hauptprofil-Tabelle reduzierten wir die Anzahl der Joins von zehn auf eins.
Umgang mit großen Textfeldern
Das Speichern großer Zeichenketten (CLOBs) in der Haupttabelle kann das Lesen von Seiten verlangsamen. Die Datenbankengine muss die gesamte Zeile laden, um den Primärschlüssel zu überprüfen. Wenn die Zeile zu groß ist, kann sie auf die Festplatte ausgelagert werden.
Best Practices beinhalten:
- Trennen Sie große Textfelder in eine verknüpfte Tabelle.
- Holen Sie das Textfeld nur ab, wenn es ausdrücklich angefordert wird.
- Speichern Sie Referenzen (IDs) statt Inhalt im Hauptindex.
📈 Phase 2: Indizierungsstrategien
Indizes sind die Triebkraft der Abfrageleistung. Ein gut gestaltetes ERD setzt auf Indizes, um Daten schnell zu finden. Mit wachsenden Datensätzen wächst auch die Größe der Indizes. Die Pflege von Indizes verbraucht Schreibressourcen.
Komposite Indizes
Einzel-Spalten-Indizes sind oft unzureichend. Komposite Indizes ermöglichen es der Engine, gleichzeitig nach mehreren Kriterien zu filtern. Die Reihenfolge der Spalten im Index ist wichtig. Die selektivste Spalte sollte zuerst kommen.
Zum Beispiel, wenn Sie nach Status und Datum, aber Status eine geringe Selektivität hat (z. B. nur drei Werte), platzieren Sie Datumzuerst. Dies verengt den Suchraum schneller.
Deckende Indizes
Ein deckender Index enthält alle Spalten, die von der Abfrage benötigt werden. Die Datenbank kann die Abfrage ausschließlich anhand des Indexes erfüllen. Es ist nicht erforderlich, auf die Tabellendaten (Heap) zuzugreifen. Dies ist ein erheblicher Leistungsgewinn.
- Schließen Sie alle
SELECTSpalten ein. - Schließen Sie alle
WHEREKlausel-Spalten ein. - Schließen Sie alle
SORTIEREN NACHSpalten.
Index-Wartung
Indizes sind nicht statisch. Sie fragmentieren im Laufe der Zeit. Sie wachsen mit den Daten. Regelmäßige Wartung ist erforderlich.
- Neu erstellen:Fragmentiert die Indexstruktur.
- Umbauen:Ordnet die Blattseiten ohne vollständige Neuerstellung um.
- Überwachung: Verfolgen Sie nicht verwendete Indizes. Entfernen Sie sie, um Schreibspeicher zu sparen.
🗄️ Phase 3: Partitionierung und Sharding
Wenn eine einzelne Tabelle die Kapazität einer einzelnen Festplatte oder Speichelpool überschreitet, wird Partitionierung notwendig. Dabei wird eine logische Tabelle in kleinere physische Segmente aufgeteilt.
Bereichs-Partitionierung
Diese Methode teilt die Daten basierend auf einem Bereichswert. Häufig verwendet für Daten oder aufsteigende IDs. Zum Beispiel die Aufteilung der Daten nach Jahr.
- Vorteil: Abfragen, die nach dem Partitionierungsschlüssel filtern, scannen nur ein Segment.
- Nachteil: Abfragen ohne den Partitionierungsschlüssel scannen alle Segmente (vollständige Tabellen-Scans).
Hash-Partitionierung
Diese Methode verteilt die Daten gleichmäßig über die Segmente mithilfe einer Hash-Funktion auf einer Schlüsselspalte. Sie verhindert Hotspots.
- Vorteil: Gleichmäßige Verteilung der Daten.
- Nachteil: Bereichsabfragen werden teuer.
Horizontales vs. Vertikales Sharding
Sharding geht die Partitionierung weiter, indem die Daten über mehrere Datenbankinstanzen verteilt werden.
| Strategie | Beschreibung | Beste Einsatzmöglichkeit |
|---|---|---|
| Horizontales Sharding | Zeilen über Datenbanken auf der Grundlage eines Schlüssels verteilen. | Hohe Schreibvolumina, große Datensätze. |
| Vertikales Sharding | Spalten über Datenbanken auf der Grundlage der Nutzung verteilen. | Große Spalten, unterschiedliche Leseverhalten. |
| Verzeichnis-Sharding | Verwenden Sie eine Suchtabelle, um Abfragen zu leiten. | Komplexe Routing-Logik, dynamische Skalierung. |
In unserer Fallstudie haben wir horizontales Sharding basierend auf der Benutzer-ID implementiert. Dadurch konnten wir die Last auf fünf Knoten verteilen. Jeder Knoten verarbeitete ungefähr 20 % des Datenverkehrs. Dadurch wurde die Last auf jedes einzelne Speicher-Engine reduziert.
🚀 Phase 4: Abfrage-Optimierung
Selbst bei einem perfekten Schema töten schlechte Abfragen die Leistung. Der Optimierer wählt den Ausführungsplan aus. Sie müssen ihn leiten.
Vermeidung von Volltabellen-Scans
Stellen Sie immer sicher, dass eine Abfrage einen Index verwendet. Wenn sie die gesamte Tabelle scannt, wird sie bei großer Skalierung time out. Prüfen Sie den Ausführungsplan. Suchen Sie nach „Index Scan“ oder „Index Seek“ anstelle von „Table Scan“.
Beschränkung der Ergebnismengen
Holen Sie niemals alle Datensätze ab. Verwenden Sie Paginierung. Begrenzen Sie die Anzahl der zurückgegebenen Zeilen pro Anfrage.
- Offset-Grenze: Standard-Paginierung. Kann bei tiefen Offset-Werten langsam sein.
- Keyset-Paginierung: Verwenden Sie die zuletzt gesehene ID, um die nächste Seite abzurufen. Viel schneller.
Batches von Operationen
Führen Sie keine Millionen von Updates in einer einzigen Transaktion aus. Teilen Sie sie in Batches auf.
- Commit nach jedem 1.000 Datensätzen.
- Dies reduziert das Wachstum der Protokolldatei.
- Dies verhindert lang laufende Sperrungen.
⚠️ Häufige Fallen, die vermieden werden sollten
Skalierung bringt neue Risiken mit sich. Seien Sie sich dieser häufigen Fehler bewusst.
- Über-Indizierung: Zu viele Indizes verlangsamen Schreibvorgänge. Überwachen Sie die Schreibleistung.
- Ignorieren von Datentypen: Verwenden
VARCHARfür feste Längen-IDs verschwendet Platz. Verwenden SieINToderBIGINT. - N+1-Abfragen: Abrufen verwandter Daten in einer Schleife. Verwenden Sie vorab geladene Daten oder Batch-Joins.
- Weiche Löschungen:Das Markieren von Datensätzen als gelöscht hält sie für immer in der Tabelle. Archivieren Sie alte Daten.
- Sperren von Schemata: Ändern der Tabellenstruktur, während das System aktiv ist. Verwenden Sie Online-Schemawechsel.
📊 Leistungsmetriken zur Überwachung
Sie können nicht verbessern, was Sie nicht messen. Legen Sie eine Basislinie fest. Überwachen Sie diese Metriken kontinuierlich.
- Zeilen pro Sekunde:Wie schnell werden Daten geschrieben?
- Abfragen pro Sekunde:Wie groß ist der Leseverkehr?
- Cache-Trefferquote:Treffen Lesevorgänge auf Speicher oder Festplatte?
- Wartezeit für Sperren:Warten Transaktionen auf Ressourcen?
- Festplatten-I/O:Ist die Speicherung ausgelastet?
🔄 Die Entwicklung des ERD
Das Entity-Relationship-Diagramm ist kein statisches Dokument. Es ist ein lebendiges Bauplan. Mit der Skalierung des Systems ändert sich der ERD.
Hier ist die Entwicklung unserer Schemaversion:
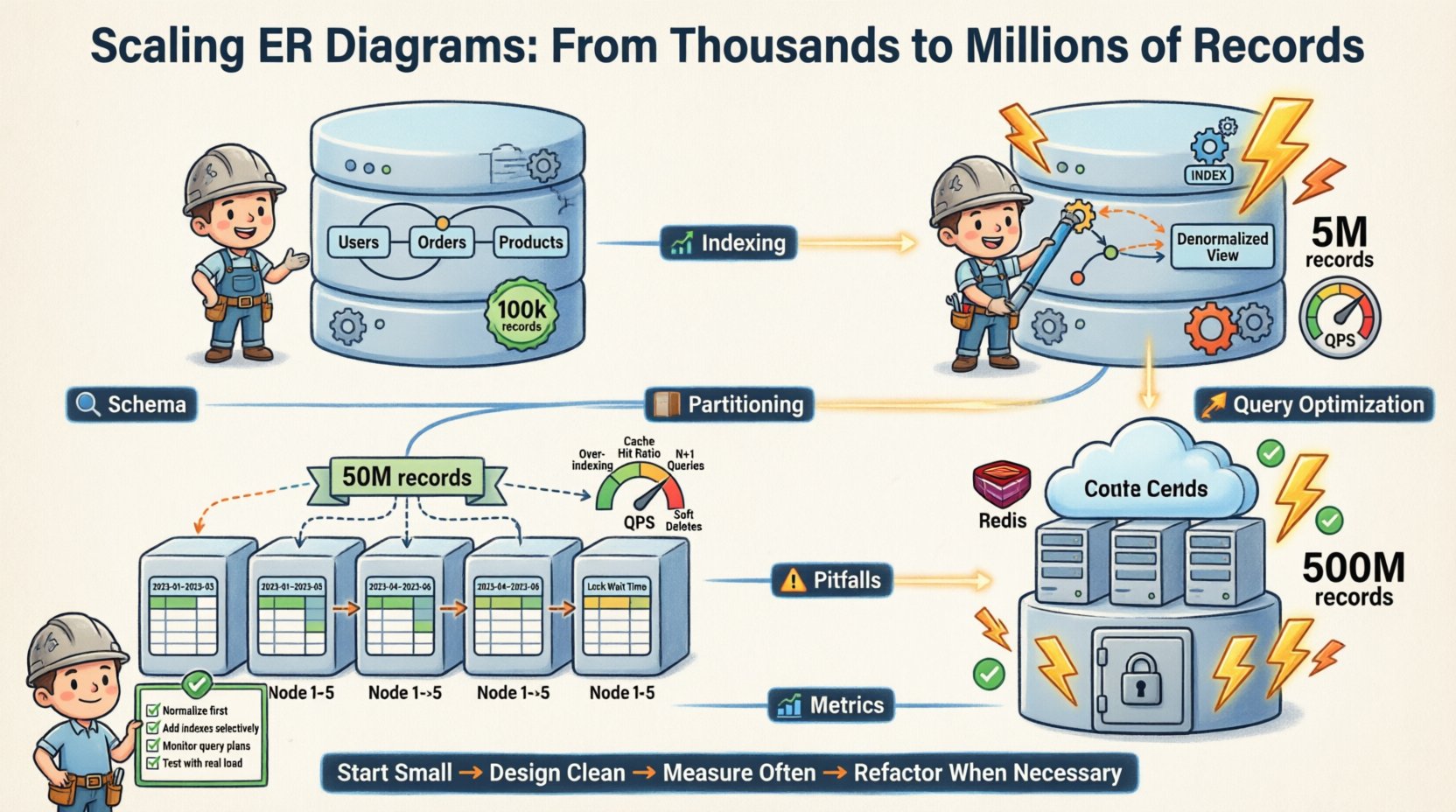
- Phase 1 (Start): Vollständig normalisiert. 3NF. Einzelne Datenbankinstanz. 100.000 Datensätze.
- Phase 2 (Wachstum): Denormalisierung von lesedichten Tabellen. Indizes hinzugefügt. Einzelinstanz. 5 Mio. Datensätze.
- Phase 3 (Skalierung): Horizontale Partitionierung. Aufgeteilt nach Benutzer-ID. Mehrinstanz. 50 Mio. Datensätze.
- Phase 4 (Reife): Archivierung alter Daten. Integration einer Caching-Schicht. Lese-Replicas. 500 Mio. Datensätze.
Jede Phase erforderte spezifische Änderungen am logischen Modell. Die zentralen Beziehungen blieben stabil. Die physische Implementierung passte sich an.
🛠️ Prüfliste für Skalierung
Verwenden Sie diese Prüfliste, bevor Sie in eine Umgebung mit hohem Volumen bereitgestellt werden.
- ☐ Stellen Sie sicher, dass alle Fremdschlüssel unterstützende Indizes haben.
- ☐ Überprüfen Sie auf
SELECT *im Anwendungscode. - ☐ Stellen Sie sicher, dass die Partitionierungsschlüssel gleichmäßig verteilt sind.
- ☐ Testen Sie Failover-Szenarien für Datenbankknoten.
- ☐ Überprüfen Sie die Einstellungen des Verbindungspools.
- ☐ Planen Sie die Archivierung und Bereinigung von Daten.
- ☐ Implementieren Sie Überwachungswarnungen für langsame Abfragen.
- ☐ Dokumentieren Sie die Verfahren zur Schemaänderung.
💡 Letzte Überlegungen zur Zuverlässigkeit
Die Skalierung eines ER-Diagramms geht nicht nur um Geschwindigkeit. Es geht um Zuverlässigkeit. Ein System, das schnell ist, aber unter Last zusammenbricht, ist nutzlos. Ein System, das langsam ist, aber stabil läuft, ist beherrschbar.
Das Ziel ist es, eine Struktur zu entwerfen, die Wachstum vorwegnimmt. Sie müssen die Kosten für Speicher gegen die Kosten für Rechenleistung abwägen. Sie müssen Konsistenz gegen Verfügbarkeit abwägen. Das sind die grundlegenden Kompromisse verteilter Systeme.
Durch die Einhaltung dieser Prinzipien können Sie sicherstellen, dass Ihre Datenarchitektur robust bleibt. Sie können den Übergang von Tausenden zu Millionen ohne Ausfall bewältigen. Der Schlüssel liegt in der Vorbereitung. Der Schlüssel liegt im Testen. Der Schlüssel liegt im Verständnis der zugrundeliegenden Mechanismen Ihrer Speicherengine.
Beginnen Sie klein. Gestalten Sie sauber. Messen Sie häufig. Refaktorisieren Sie, wenn nötig. Das ist der Weg zu einer nachhaltigen Skalierung.

