











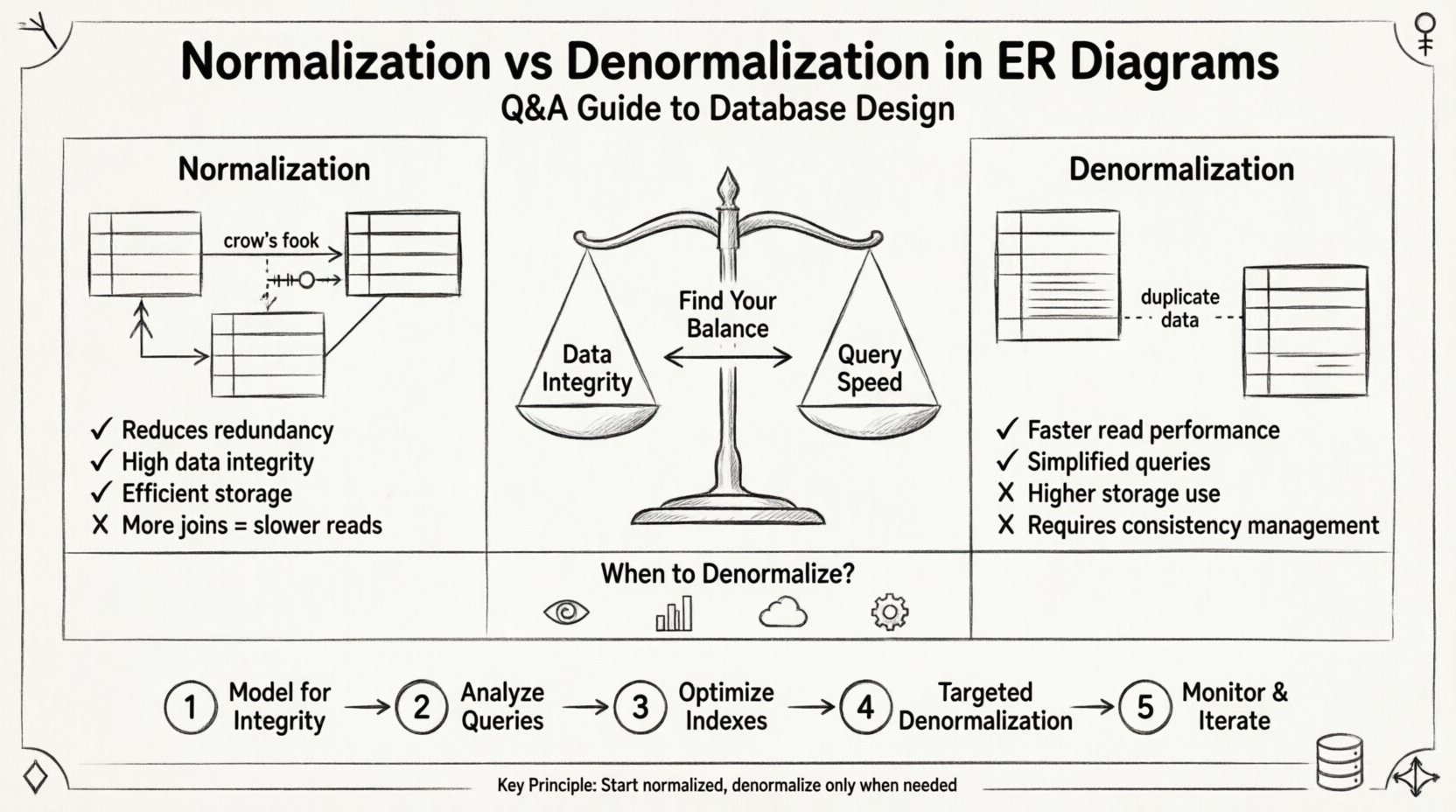
Проектирование баз данных — основа любой надежной системы. При создании диаграммы сущность-связь (ERD) на схему влияют две противоположные силы: нормализация и денормализация. Понимание того, когда применять каждую стратегию, определяет долгосрочное здоровье, производительность и поддерживаемость вашей инфраструктуры данных. В этом руководстве рассматриваются наиболее важные вопросы по этим концепциям, предоставляя четкий путь проектирования эффективных структур баз данных без использования конкретных программных инструментов. 🛠️
Целостность данных и скорость выполнения запросов часто противоречат друг другу. Нормализация приоритизирует целостность за счет уменьшения избыточности. Денормализация приоритизирует скорость за счет введения контролируемой избыточности. Навигация между этим балансом требует глубокого понимания теории отношений и практических требований к производительности. Давайте рассмотрим технические детали через ряд целенаправленных вопросов и ответов. 📊
Понимание основ: с чем мы имеем дело? 🔍
Прежде чем погружаться в конкретные сценарии, мы должны определить основные механизмы, действующие в вашем проектировании диаграммы сущность-связь.
Что такое нормализация? 🔄
Нормализация — это систематический процесс организации данных в базе данных с целью уменьшения избыточности и повышения целостности данных. Она включает разделение больших таблиц на более мелкие, логически связанные таблицы, а также определение отношений между ними. Цель — обеспечить, чтобы каждая часть данных хранилась только в одном месте.
- Цель: Устранить дублирующиеся данные и обеспечить, чтобы зависимости имели смысл.
- Преимущество: Упрощает поддержку данных и снижает требования к хранилищу.
- Риск: Увеличивает сложность запросов из-за необходимости использования операций соединения (joins).
Нормализация обычно достигается через ряд этапов, известных как формы нормализации. Каждая форма строится на предыдущей, устраняя определенные типы аномалий.
Что такое денормализация? ⚖️
Денормализация — это сознательное введение избыточности в нормализованную базу данных. Это делается для оптимизации производительности чтения, особенно в сценариях, где скорость выполнения запросов важнее скорости записи. Она включает слияние таблиц или добавление дублирующих столбцов для избежания дорогостоящих операций соединения (joins).
- Цель: Сократить количество операций соединения, необходимых для сложных запросов.
- Преимущество: Более быстрые операции чтения и упрощенная логика запросов.
- Риск: Увеличение использования хранилища и повышенный риск несогласованности данных.
Вопросы и ответы: глубокое погружение в нормализацию и проектирование диаграмм сущность-связь 📝
Эти вопросы касаются наиболее распространенных трудностей, возникающих при проектировании реляционных схем. Они охватывают переход от теории к практической реализации.
Вопрос 1: Обязательно ли нормализовать всё до 3НФ? 🤷♂️
Краткий ответ — нет. Хотя третья нормальная форма (3НФ) является стандартным ориентиром для многих приложений, она не является жестким правилом для каждого сценария. Нормализация до 3НФ устраняет транзитивные зависимости, обеспечивая, что неполевые атрибуты зависят только от первичного ключа. Однако достижение более высоких форм, таких как форма Бойса-Кодда (BCNF) или четвертая нормальная форма (4НФ), иногда усложняет схему без значительной выгоды.
Рассмотрим компромиссы:
- 3НФ: Подходит для универсальных транзакционных систем, где целостность данных имеет первостепенное значение.
- 4НФ/5НФ: Часто избыточно, если только вы не имеете дело со сложными многосоставными зависимостями или зависимостями соединения.
- Практический подход: Сначала проектируйте для 3НФ. Оценивайте узкие места производительности, прежде чем рассматривать денормализацию или дальнейшую нормализацию.
В2: Как нормализация влияет на производительность запросов? 🐢
Нормализация в первую очередь влияет на производительность из-за необходимости выполнения соединений. Когда данные распределены по нескольким таблицам, для получения полной записи базе данных необходимо соединить эти таблицы. Этот процесс потребляет ресурсы ЦП и памяти.
Ключевые факторы, влияющие на производительность, включают:
- Сложность соединения:Больше таблиц означает больше условий соединения для оценки.
- Индексация:Внешние ключи должны быть проиндексированы, чтобы ускорить соединения. Без правильной индексации нормализация может привести к серьезной деградации производительности.
- Объём данных: По мере роста объёма данных стоимость сканирования и соединения значительно возрастает.
В приложениях с высокой нагрузкой на чтение этот накладной расход может стать узким местом. В приложениях с высокой нагрузкой на запись накладные расходы часто незначительны по сравнению с преимуществом снижения аномалий обновления.
В3: Когда уместно денормализовать? ⚙️
Денормализация не должна быть стандартным состоянием. Это мера исправления, применяемая после выявления конкретных проблем с производительностью. Следует рассмотреть денормализацию в следующих ситуациях:
- Нагрузки с высокой долей чтения: Если система обрабатывает тысячи операций чтения на каждую операцию записи, стоимость соединений может превысить стоимость хранения.
- Панели отчётов:Сложные аналитические запросы часто выигрывают от предварительно соединённых данных, хранящихся в широких таблицах.
- Уровни кэширования: Иногда денормализация реализуется на уровне кэширования, а не в основной системе хранения.
- Ограничения старых систем: Старые движки баз данных или специфические ограничения оборудования могут испытывать трудности с выполнением сложных соединений.
В4: Как управлять согласованностью данных при денормализации? 🛡️
Введение избыточности создаёт риск несогласованности данных. Если вы храните имя клиента в таблице «Заказы» и в таблице «Клиенты», обновление имени в таблице «Клиенты»Заказы и в таблице Клиенты таблице, обновление имени в таблице «Клиенты»Клиенты таблица требует каскадного обновления для Заказы таблицы.
Стратегии поддержания согласованности включают:
- Логика приложения: Убедитесь, что код приложения обновляет все избыточные поля в рамках одной транзакции.
- Триггеры базы данных: Используйте триггеры для автоматической синхронизации избыточных столбцов при изменении исходных данных.
- Периодическая сверка: Запускайте плановые задания для аудита и устранения несогласованности в денормализованных данных.
- Специализация реплик для чтения: Держите основную базу данных полностью нормализованной и используйте денормализованную копию для отчетности.
Вопросы и ответы: Расширенные сценарии и компромиссы ⚖️
Помимо основ, при масштабировании систем возникают конкретные архитектурные вызовы. Эти вопросы затрагивают эти нюансы.
В5: Можно ли смешивать нормализованные и денормализованные таблицы в одной ERD? 🧩
Да, гибридные модели распространены в производственных средах. Стандартной практикой является поддержание основной нормализованной схемы для обеспечения целостности транзакций при создании денормализованных представлений или сводных таблиц для конкретных случаев использования.
Например:
- Основные таблицы: Храните пользователей, товары и заказы в 3НФ для обеспечения точных финансовых записей.
- Таблицы отчетности: Создайте денормализованную таблицу, которая агрегирует итоги заказов и данные о клиентах для быстрого отображения на панели мониторинга.
- Представления: Используйте представления SQL для предоставления денормализованной структуры приложениям без физического дублирования данных.
В6: Нарушает ли денормализация теорию баз данных? 📚
Теоретически — да. Реляционная теория выступает за нормализацию для минимизации аномалий. Однако практическое проектирование часто требует гибкости в этих правилах для достижения требований к производительности. Нарушение преднамеренное и обдуманное. Пока избыточность контролируется и документируется, архитектура остается валидной для своей цели.
В7: Как индексирование взаимодействует с нормализацией? 🔖
Индексирование — основной инструмент для снижения производительностных издержек нормализации. При нормализации создаются внешние ключи. Эти внешние ключи должны быть проиндексированы для эффективного выполнения соединений.
Рассмотрим следующие моменты:
- Индексы внешних ключей: У каждого внешнего ключа должен быть индекс для ускорения соединений.
- Составные индексы: Если запрос объединяет несколько столбцов, составной индекс может охватывать все условия объединения.
- Влияние денормализации: Денормализация часто уменьшает потребность в индексах внешних ключей, что потенциально снижает накладные расходы при записи в индексы.
Сравнение: нормализация против денормализации 📋
Чтобы наглядно представить компромиссы, обратитесь к приведённой ниже таблице. Такая структура помогает при принятии решений на этапе проектирования.
| Функция | Нормализация | Денормализация |
|---|---|---|
| Избыточность данных | Минимизирована | Увеличена |
| Целостность данных | Высокая | Требует управления |
| Пространство хранения | Эффективно | Менее эффективно |
| Производительность чтения | Медленнее (больше соединений) | Быстрее (меньше соединений) |
| Производительность записи | Быстрее (меньше данных для обновления) | Медленнее (обновление всех копий) |
| Сложность | Высокая (много таблиц) | Высокая (логика синхронизации данных) |
| Лучший случай использования | OLTP, транзакционные системы | OLAP, отчетность, системы с высокой нагрузкой на чтение |
Стратегия реализации: пошаговый подход 🚀
Проектирование схемы требует систематического процесса. Не спешите денормализовать. Следуйте этому структурированному подходу, чтобы обеспечить надежную основу.
Шаг 1: Модель для обеспечения целостности сначала 🏗️
Начните с создания полностью нормализованной схемы. Цель — не менее третьей нормальной формы (3НФ). Определите все сущности, атрибуты и отношения. Убедитесь, что каждая таблица имеет первичный ключ, а внешние ключи правильно определены. На этом этапе обеспечивается точность и согласованность ваших данных.
Шаг 2: Анализ шаблонов запросов 🔎
Прежде чем изменять схему, понимайте, как будет осуществляться доступ к данным. Просмотрите требования приложения и журналы запросов. Определите, какие запросы медленные или сложные. Ищите шаблоны, при которых часто требуются множественные соединения.
Шаг 3: Оптимизация индексов ⚡
Прежде чем денормализовать, убедитесь, что ваша нормализованная схема правильно проиндексирована. Часто добавление правильных составных индексов решает проблемы производительности без необходимости изменения структуры таблицы. Протестируйте запросы с текущей схемой и индексами, чтобы установить базовый уровень.
Шаг 4: Целенаправленная денормализация 🎯
Если производительность по-прежнему недостаточна, применяйте денормализацию выборочно. Не денормализуйте всю базу данных. Сосредоточьтесь только на тех таблицах или столбцах, которые вызывают узкое место. Документируйте каждое внесённое изменение для последующего обслуживания.
Шаг 5: Мониторинг и итерации 📈
Проектирование базы данных не является статичным. Мониторьте систему с течением времени. По мере роста объёма данных или изменения паттернов использования баланс может потребовать корректировки. Регулярно пересматривайте схему, чтобы убедиться, что она по-прежнему соответствует требованиям производительности и целостности.
Распространённые ошибки, которых следует избегать 🚫
Даже опытные дизайнеры могут ошибаться при работе с оптимизацией ERD. Следите за этими распространенными ошибками.
- Чрезмерная нормализация:Создание слишком большого количества таблиц делает схему трудной для понимания и запросов. Сохраняйте структуру логичной и интуитивно понятной.
- Недостаточная нормализация:Хранение слишком большого объёма данных в одной таблице приводит к аномалиям обновления и потере места.
- Пренебрежение ростом данных:Проектирование, работающее с 1000 записями, может не справиться с 1 000 000. Планируйте масштабируемость.
- Скрытая денормализация:Денормализация без документации приводит к путанице. Будущие сопровождающие могут не понять, почему данные дублируются.
- Предположение, что все запросы одинаковы: Не все запросы имеют одинаковые требования к производительности. Приоритеты должны быть отданы наиболее частым и критически важным запросам.
Заключительные мысли о архитектуре схемы 🧠
Решение между нормализацией и денормализацией не является бинарным. Это спектр компромиссов, зависящий от конкретных потребностей вашего приложения. Хорошо спроектированная ERD балансирует целостность данных и эффективность запросов. Понимая основополагающие принципы и следуя структурированному подходу, вы можете создавать системы, которые одновременно надёжны и производительны.
Помните, что инструменты и технологии развиваются. Однако принципы реляционного проектирования остаются неизменными. Сосредоточьтесь на самой модели данных, а не на возможностях движка базы данных. Надёжная основа будет поддерживать ваше приложение независимо от будущих изменений инфраструктуры. Держите свою схему чистой, документацию — ясной, а метрики производительности — в поле зрения на каждом этапе. 🌟

