











Kiedy system oprogramowania zaczyna skalować się, warstwa danych często staje się najważniejszym węzłem zatkania. Choć kod aplikacji można przepisać, a interfejsy front-endu przeprojektować, schemat bazy danych reprezentuje podstawową prawdę aplikacji. Źle zbudowany diagram związków encji (ERD) to nie tylko nieprzyjemność wizualna; to słabość strukturalna, która się nasila z czasem. Ta analiza bada koszty materialne i niematerialne związane z błędnym modelowaniem bazy danych oraz złożoną rzeczywistością refaktoryzacji tych struktur w późniejszym etapie cyklu rozwoju.
Wiele zespołów traktuje projektowanie schematu jako zadanie wstępne, coś, co należy ukończyć przed rozpoczęciem rzeczywistego kodowania. Jednak gdy wymagania się zmieniają, a logika biznesowa ewoluuje, sztywność źle zaplanowanego diagramu ERD staje się oczywista. Koszt ignorowania tych szczegółów nie jest mierzony tylko godzinami poświęconymi na pisanie SQL, ale także utratą prędkości rozwoju, zwiększeniem ryzyka przestojów i pogorszeniem zaufania zespołu do infrastruktury.
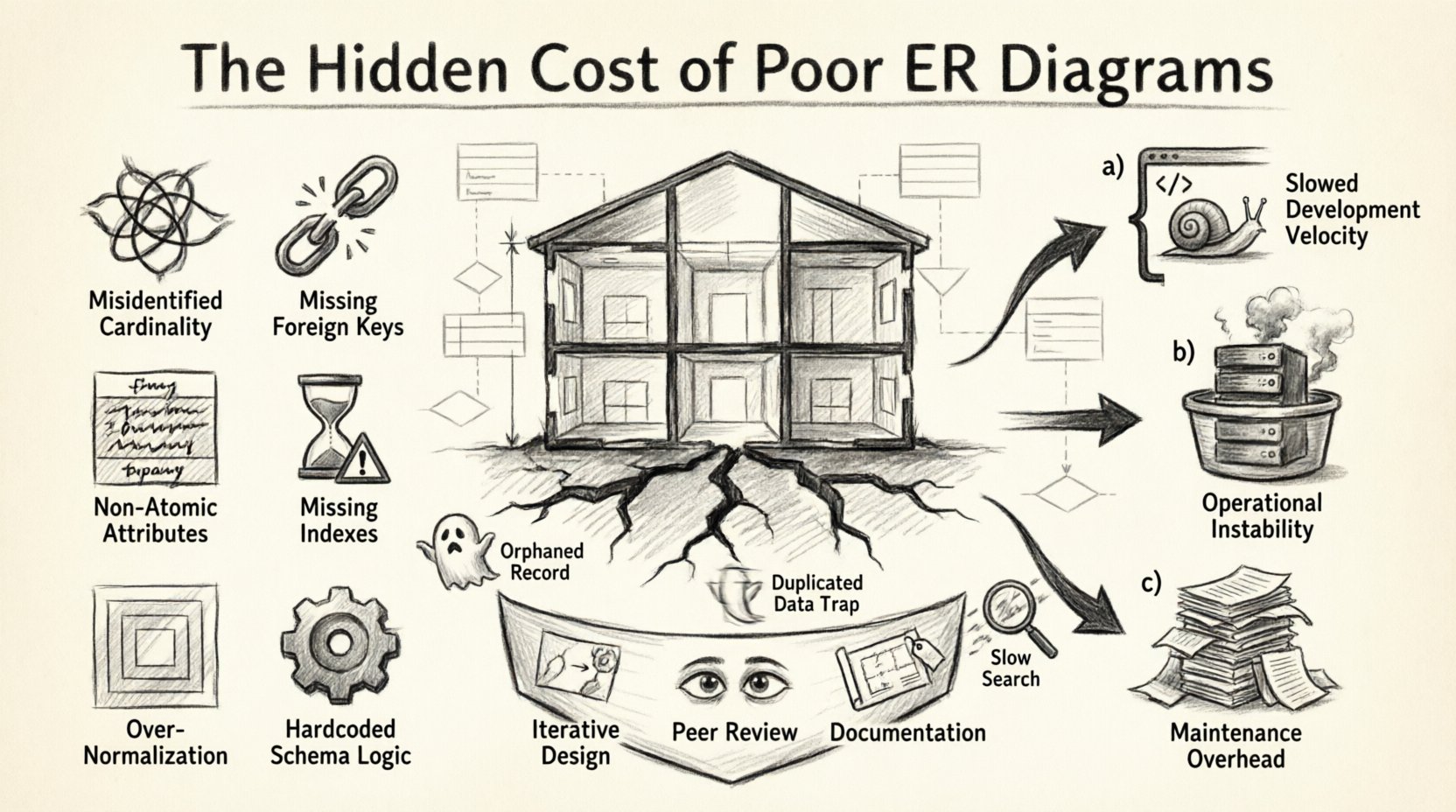
1. Analogia do projektu architektonicznego: dlaczego schemat ma znaczenie 🏗️
Wyobraź sobie schemat bazy danych jako projekt architektoniczny budynku. Jeśli ściany nośne są umieszczone niepoprawnie, albo rury kanalizacyjne są prowadzone nieefektywnie, konstrukcja może początkowo stać. Jednak z czasem pojawiają się pęknięcia. Nadbudowanie dodatkowych funkcji na słabej podstawie prowadzi do awarii strukturalnej. W oprogramowaniu manifestuje się to wolnymi zapytaniami, niezgodnościami danych oraz niemożliwością dodania nowych funkcji bez uszkodzenia istniejących.
Diagram ERD pełni rolę narzędzia komunikacji między stakeholderami, programistami i architektami danych. Definiuje encje, ich atrybuty oraz relacje między nimi. Gdy ten diagram jest niejasny lub niekompletny, prowadzi to do:
- Niejasność implementacji:Programiści robią założenia dotyczące integralności danych, które mogą nie odpowiadać regułom biznesowym.
- Problemy z normalizacją:Dane są albo nadmiernie fragmentowane, co wymaga nadmiernych połączeń, albo nadmiernie nienormalizowane, co prowadzi do anomalii aktualizacji.
- Luki w ograniczeniach:Brak kluczy obcych lub ograniczeń sprawdzających pozwala na wprowadzanie nieprawidłowych danych do systemu.
Te problemy się akumulują. Mały błąd w typie relacji może nie być zauważony przez miesiące, aż do momentu, gdy spowoduje katastrofalną awarię podczas wykonywania konkretnego raportu lub migracji.
2. Anatomia źle zaprojektowanego schematu: typowe błędy modelowania 🔍
Identyfikacja konkretnych błędów w diagramie ERD to pierwszy krok w zrozumieniu ponoszonych kosztów. Poniżej znajduje się analiza typowych pułapek modelowania, które prowadzą do istotnego długu technicznego.
| Kategoria | Typowy błąd | Wpływ na system |
|---|---|---|
| Relacje | Niepoprawnie zidentyfikowana liczność (1:1 vs 1:N) | Nieefektywne przechowywanie danych, skomplikowane połączenia, powielanie danych. |
| Ograniczenia | Brakujące klucze obce | Zaniedbane rekordy, utrata integralności danych, wymagana ręczna czystka. |
| Atrybuty | Nienajmniejsze kolumny | Trudności z zapytaniem, niemożliwość indeksowania konkretnych fragmentów danych. |
| Wydajność | Brakujące indeksy na kluczach obcych | Wolne połączenia, zawieszenie podczas zapisu, wysokie zużycie CPU. |
| Projektowanie | Głęboka normalizacja | Zbyt wiele łączeń tabel dla prostych odczytów, złożoność zapytań. |
| Skalowalność | Zakodowana logika w schemacie | Niesprawna struktura, która nie może dostosować się do nowych stanów biznesowych. |
Każdy z tych wpisów reprezentuje punkt napięcia. Gdy programista napotka błąd w schemacie, często obejmuje go logiką na poziomie aplikacji. Przesuwa to zasady biznesowe do kodu, tworząc rozdzielenie odpowiedzialności, które trudno utrzymać.
3. Kwantyfikacja długu technicznego 💰
Koszt złego projektowania rzadko jest natychmiastowy. To powolne wyczerpywanie zasobów. Możemy te koszty podzielić na trzy główne kategorie: Prędkość rozwoju, Stabilność operacyjna i Obciążenie utrzymania.
3.1 Prędkość rozwoju
Gdy schemat jest niejasny, programiści spędzają czas na odwrotnej analizie modelu danych zamiast budować funkcje. Muszą:
- Śledzić przepływ danych przez wiele tabel, aby zrozumieć pojedyncze pole.
- Pisać złożone zapytania SQL, aby zrekompensować brakujące relacje.
- Radzić sobie z zadaniami czyszczenia danych, które powinny zostać zapobiegane na poziomie źródła.
To spowalnia dostarczanie funkcji. Sprint, który powinien trwać trzy dni, może się przedłużyć do pięciu lub sześciu z powodu debugowania danych. To bezpośredni koszt czasu i budżetu organizacji.
3.2 Stabilność operacyjna
Problemy z bazą danych często pojawiają się w środowisku produkcyjnym pod obciążeniem. Złe strategie indeksowania lub brak ograniczeń może prowadzić do:
- Zawieszenie blokad:Gdy wiele transakcji próbuje zaktualizować te same słabo zorganizowane tabele, system zatrzymuje się.
- Przekroczenie czasu oczekiwania zapytań:Zapytania nieoptymalizowane powodują, że baza danych przeszukuje miliony wierszy bez potrzeby.
- Zakłócenie danych:Bez odpowiednich ograniczeń dane nieprawidłowe mogą się rozprzestrzeniać przez system, co utrudnia zaufanie do raportów.
3.3 Obciążenie utrzymania
Każdy rok, w którym istnieje wadliwy schemat, koszt jego naprawy rośnie. Wynika to z gromadzenia zależności. Nowe funkcje są budowane na starą, wadliwą strukturę. Refaktoryzacja staje się jak przemieszczanie fundamentów domu, gdy ludzie żyją w nim.
4. Proces refaktoryzacji: Złożoność i ryzyko 🛠️
Po podjęciu decyzji o refaktoryzacji bazy danych, proces jest pełen wyzwań. Nie chodzi tylko o zmianę tabel. Wymaga on starannego koordynowania migracji, sprawdzania spójności danych i minimalnego czasu przestoju.
4.1 Strategia migracji
Refaktoryzacja wymaga skryptów migracji. Te skrypty muszą być idempotentne i odwracalne. Jednak jeśli schemat był słabo dokumentowany, pisanie tych skryptów staje się grą zgadówek. Musisz upewnić się, że:
- Istniejące dane są poprawnie przekształcone bez utraty.
- Uruchomione aplikacje nie ulegają awarii podczas przejścia.
- Plan odwrotu jest możliwy, jeśli coś pójdzie nie tak.
W złożonych systemach może to wymagać strategii zapisu podwójnego, w której nowe dane są zapisywane w nowej strukturze, podczas gdy stare dane są migrowane w tle. To tymczasowo podwaja złożoność logiki aplikacji.
4.2 Przerwy w działaniu i dostępność
Niektóre zmiany strukturalne, takie jak dodawanie kolumn z wartościami domyślnymi lub ponowne indeksowanie dużych tabel, mogą blokować bazę danych. Dla systemów o wysokiej dostępności jest to nieakceptowalne. Refaktoryzacja często wymaga planowania okien konserwacyjnych, co wpływa na doświadczenie użytkownika i przychody.
4.3 Czynnik ludzki
Refaktoryzacja to także zdarzenie psychologiczne dla zespołu. Jeśli zespół musi stale radzić sobie z przepływem błędów danych spowodowanych schematem, morale spada. Czują się jakby stale walczyli z infrastrukturą zamiast tworzyć wartość. Czysta, dobrze zaprojektowana baza danych odzyskuje zaufanie do platformy.
5. Strategiczna zapobiegliwość: budowanie odpornych modeli 🛡️
Choć refaktoryzacja jest możliwa, zapobieganie jest znacznie bardziej opłacalne. Przyjęcie dyscyplinowanego podejścia do tworzenia ERD może zmniejszyć większość ryzyk.
5.1 Projektowanie iteracyjne
Nie czekaj na ostateczne wymagania, aby zaprojektować schemat. Zacznij od podstawowych encji i relacji, które są stabilne. Pozwól, by model się rozwijał. Traktuj ERD jako żywy dokument, który jest aktualizowany wraz z prośbami o funkcje.
5.2 Recenzja modeli danych przez kolegów
Tak jak kod jest przeglądany, schematy baz danych powinny być przeglądarkowane. Świeże spojrzenie może zauważyć:
- Zbyteczne pola danych.
- Brakujące relacje między tabelami.
- Potencjalne konflikty nazw.
- Naruszenie zasad normalizacji.
Ten proces przeglądu zapewnia, że model jest zgodny z intencją biznesową, zanim zostanie napisany pierwszy wiersz kodu migracji.
5.3 Dokumentacja i zasady nazewnictwa
Spójność to klucz. Ustanów ścisłe zasady nazewnictwa dla tabel i kolumn. Unikaj skrótów, które nie są powszechnie rozumiane. Dokumentuj regułę biznesową stojącą za każdym kluczem obcym. Zapewnia to, że każdy dołączający do zespołu może zrozumieć dane bez zadawania pytań.
6. Przypadki po incydencie: naucz się z błędów 📝
Przyjrzyjmy się hipotetycznym scenariuszom, w których złe projektowanie ERD prowadziło do istotnych problemów, oferując wskazówki, czego należy unikać.
Scenariusz A: Kriza z porzuconymi rekordami
Sytuacja:Zespół zaprojektował system do śledzenia zamówień użytkowników i adresów wysyłki. Usunięto ograniczenie klucza obcego, aby poprawić wydajność zapisu, zakładając, że logika aplikacji zajmie się walidacją.
Niepowodzenie:W czasie użytkownicy usuwali swoje konta, ale zachowali zamówienia. Adresy wysyłki stały się porzucone. Gdy zespół próbował wygenerować raport podatkowy, połączenie się nie powiodło, ponieważ dane użytkownika zostały usunięte.
Koszt:Zespół musiał napisać skrypt, aby ręcznie połączyć dane historyczne z ogólnym „anonimowym” kontenerem użytkownika. Zajęło to trzy dni pracy inżynierskiej i wymagało pełnego wydruku bazy danych oraz jej przywrócenia, aby bezpiecznie przetestować.
Scenariusz B: Pułapka denormalizacji
Sytuacja:Aby przyspieszyć wydajność odczytu, zespół skopiował dane profilu użytkownika do tabeli zamówień. Przypuszczali, że zmniejszy to liczbę operacji łączenia.
Awaria:Gdy użytkownik zmienił swoje imię, aplikacja zaktualizowała tabelę użytkowników, ale nie zaktualizowała tysięcy rekordów zamówień zawierających stare imię. Raporty pokazywały niezgodne imiona dla tego samego użytkownika.
Koszt:Spójność danych została utracona. Zespół musiał podjąć decyzję, czy zaakceptować niezgodność, czy zaimplementować skomplikowany system wyzwalaczy do synchronizacji danych. Wybrali przeprojektowanie schematu w celu usunięcia powtórzeń, co wymagało ponownego napisania logiki zapisu aplikacji.
Scenariusz C: Ślepy punkt indeksowania
Sytuacja:Funkcja wyszukiwania została zbudowana na tabeli z milionami wierszy. Deweloper założył, że klucz główny będzie wystarczający.
Awaria:W miarę wzrostu tabeli zapytania dotyczące kolumny wyszukiwania spowolniły się do stopnia niemożliwego do wykorzystania. Baza danych musiała wykonać pełne skanowanie tabeli.
Koszt:System stał się niemożliwy do użycia w godzinach szczytu. Dodanie indeksu później wymagało długotrwałej operacji, która zablokowała tabelę na kilka godzin, powodując przestój usługi.
7. Przyszłościowe zabezpieczenie warstwy danych 🔮
Celem każdego wysiłku w zakresie modelowania danych jest stworzenie fundamentu, który wytrzyma zmiany. Choć żaden schemat nie jest idealny na zawsze, dobry ERD zapewnia jasny kierunek rozwoju.
- Kontrola wersji:Traktuj migracje schematu jak kod. Przechowuj je w systemie kontroli wersji, aby śledzić zmiany w czasie.
- Testy automatyczne:Załącz walidację schematu do swojego potoku CI/CD. Upewnij się, że migracje nie naruszają istniejących zapytań.
- Monitorowanie:Monitoruj wydajność zapytań, aby wczesnie wykryć brakujące indeksy lub nieefektywne łączenia.
- Standardy społeczności:Przestrzegaj ugruntowanych najlepszych praktyk dla Twojej konkretnej technologii baz danych, aby zapewnić zgodność i wydajność.
Inwestowanie czasu w fazę ERD nie jest opóźnieniem; jest przyspieszeniem. Zmniejsza opór w przyszłym rozwoju i zapewnia, że dane pozostają wiarygodnym aktywem, a nie obciążeniem.
Wnioski: Koszt ignorancji wobec wartości planowania ⚖️
Ukryty koszt złych diagramów ER często pozostaje niewidoczny, aż jest już za późno. Pojawia się jako wolniejsze wdrażanie funkcji, niestabilne środowiska produkcyjne oraz frustracja zespołów inżynieryjnych. Przeprojektowanie bazy danych to operacja o wysokim ryzyku, wymagająca precyzji, planowania i często długiego czasu przestoju.
Traktując modelowanie danych jako kluczową czynność inżynierską, a nie administracyjną robotę, organizacje mogą uniknąć pułapki długu technologicznego. Dobrze zaprojektowany schemat działa jak zabezpieczenie, zapewniając, że aplikacja pozostaje odporna na miarę wzrostu. Wkład w projektowanie solidnego ERD przynosi zyski w każdej linii kodu napisanej później, w każdym zapytaniu wykonanym i w każdym użytkowniku obsługiwany.
Nie czekaj na analizę po incydencie, by zrozumieć wartość dobrego projektu. Zaczynaj planować z jasnością, precyzją i zaangażowaniem w integralność danych już od pierwszego dnia.

