











当软件系统开始扩展时,数据层往往成为最关键的瓶颈。尽管应用代码可以重写,前端界面也可以重新设计,但数据库模式却是应用程序的基础真相。一个设计不良的实体关系图(ERD)不仅仅是视觉上的不便,更是一种会随着时间累积的结构性缺陷。本分析探讨了错误数据库建模所带来的真实与无形成本,以及在开发生命周期后期重构这些结构的复杂现实。
许多团队将模式设计视为初步任务,在真正编码开始前完成即可。然而,随着需求变化和业务逻辑演进,设计不佳的ERD的僵化性便逐渐显现。忽视这些细节的成本不仅体现在编写SQL所耗费的小时数上,更体现在开发速度的损失、停机风险的增加,以及团队对基础设施信任度的下降。
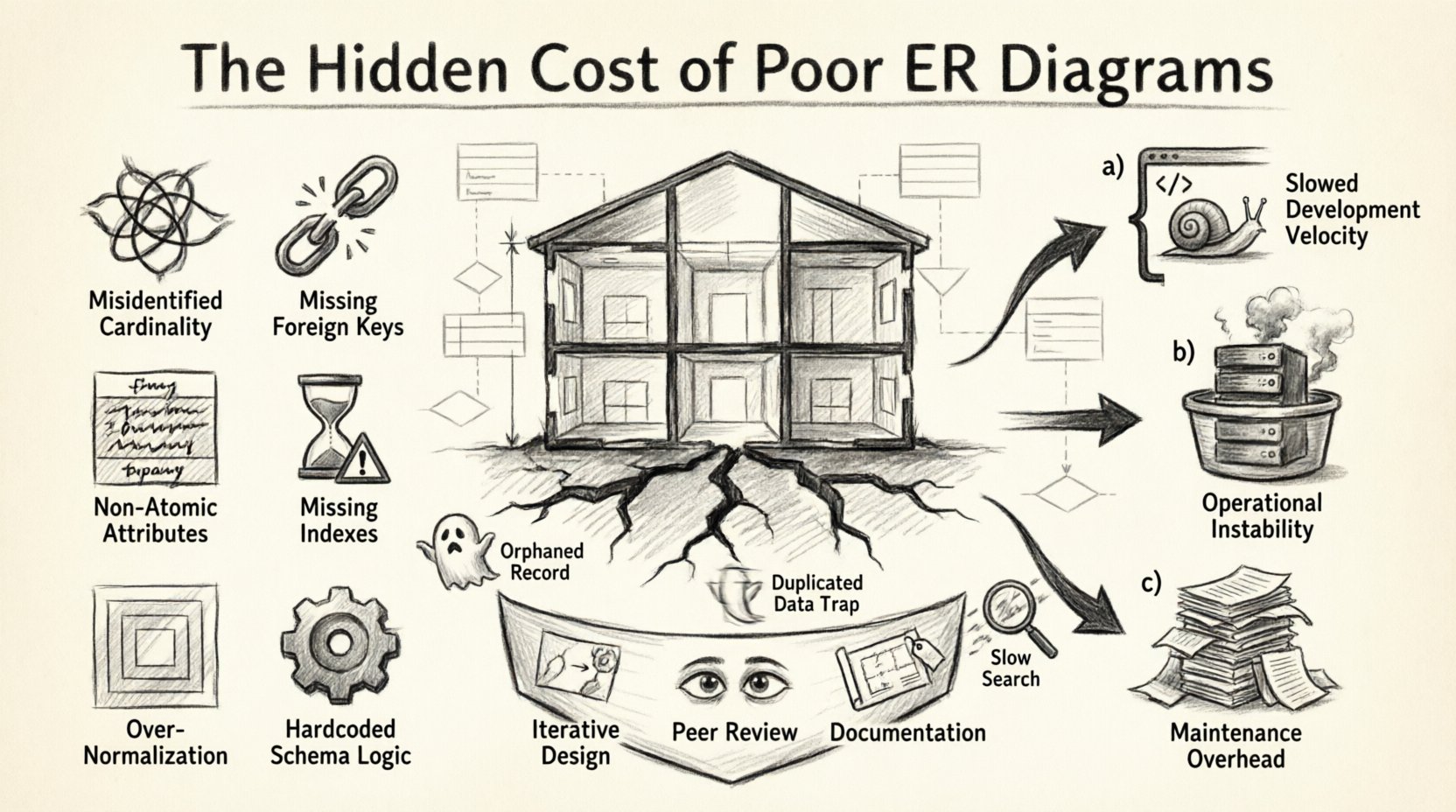
1. 蓝图类比:为什么模式至关重要 🏗️
将数据库模式视为建筑的建筑设计图。如果承重墙位置错误,或管道布局效率低下,建筑初期或许仍能屹立。但随着时间推移,裂缝逐渐出现。在薄弱基础上不断叠加新功能,最终会导致结构崩溃。在软件中,这表现为查询缓慢、数据不一致,以及无法在不破坏现有功能的前提下添加新特性。
ERD是利益相关者、开发人员和数据架构师之间的沟通工具。它定义了实体、它们的属性以及实体之间的关系。当该图示模糊或不完整时,会导致:
- 实现上的模糊性:开发人员对数据完整性做出假设,这些假设可能与业务规则不符。
- 规范化问题:数据要么过度碎片化,导致需要大量连接操作;要么过度非规范化,引发更新异常。
- 约束缺失:缺少外键或检查约束,使得无效数据得以进入系统。
这些问题会不断累积。一个关系类型的微小错误可能在数月内未被察觉,却在执行特定报告或数据迁移时引发灾难性故障。
2. 有缺陷模式的解剖:常见的建模错误 🔍
识别ERD中的具体错误,是理解相关成本的第一步。以下是导致重大技术债务的常见建模陷阱的分解。
| 类别 | 常见错误 | 对系统的影响 |
|---|---|---|
| 关系 | 错误识别基数(1:1 与 1:N) | 存储效率低下,连接操作复杂,数据重复。 |
| 约束 | 缺少外键 | 孤立记录,数据完整性丢失,需手动清理。 |
| 属性 | 非原子列 | 查询困难,无法对数据的特定部分建立索引。 |
| 性能 | 外键上缺少索引 | 连接缓慢,在写入时出现锁争用,CPU使用率高。 |
| 设计 | 深度嵌套的规范化 | 为简单的读取操作进行过多的表连接,查询复杂度高。 |
| 可扩展性 | 模式中的硬编码逻辑 | 僵化的模式,无法适应新的业务状态。 |
这些条目中的每一个都代表一个摩擦点。当开发者在模式中遇到错误时,他们通常会使用应用层逻辑来绕过问题。这会导致业务规则被推入代码库,造成难以维护的关注点分离。
3. 量化技术债务 💰
糟糕设计的成本很少是立即显现的。它是一种对资源的缓慢消耗。我们可以将这些成本分为三大类:开发速度、运营稳定性和维护开销。
3.1 开发速度
当模式不清晰时,开发者会花费时间逆向工程数据模型,而不是开发功能。他们必须:
- 跨多个表追踪数据流,以理解单个字段。
- 编写复杂的SQL查询,以弥补缺失的关系。
- 处理本应在源头就防止的数据清理任务。
这会减慢功能交付速度。一个本应三天完成的冲刺,可能因数据调试而延长至五到六天。这对组织的时间和预算造成了直接成本。
3.2 运营稳定性
数据库问题通常在高负载的生产环境中显现。糟糕的索引策略或缺乏约束可能导致:
- 锁争用:当多个事务尝试更新同一张结构不良的表时,系统会陷入停滞。
- 查询超时:未优化的连接会导致数据库不必要地扫描数百万行数据。
- 数据损坏:如果没有适当的约束,无效数据可能在整个系统中传播,导致难以信任报告。
3.3 维护开销
每一年存在一个有缺陷的模式,修复它的成本就会增加。这是因为依赖关系不断累积。新功能都是建立在旧的、有缺陷的结构之上。重构就像在人们住在屋内时移动房屋的地基。
4. 重构过程:复杂性与风险 🛠️
一旦决定重构数据库,这一过程就充满了挑战。这不仅仅是修改表那么简单,还涉及迁移、数据一致性检查和最小停机时间的精心协调。
4.1 迁移策略
重构需要迁移脚本。这些脚本必须具有幂等性和可逆性。然而,如果模式文档不完善,编写这些脚本就会变成一种猜测。你必须确保:
- 现有数据被正确转换,且无丢失。
- 运行中的应用程序在转换过程中不会崩溃。
- 如果出现问题,回滚计划是可行的。
在复杂系统中,这可能需要采用双写策略,即新数据写入新结构的同时,旧数据在后台被迁移。这会暂时使应用逻辑的复杂性翻倍。
4.2 停机时间和可用性
一些结构上的更改,例如添加带有默认值的列或重新索引大型表,可能会锁定数据库。对于高可用性系统而言,这是不可接受的。重构通常需要安排维护窗口,这会影响用户体验和收入。
4.3 人为因素
重构对团队来说也是一次心理上的挑战。如果团队不得不持续应对由模式引起的大量数据错误,士气会下降。他们会感觉一直在与基础设施斗争,而不是在创造价值。一个清晰且设计良好的数据库能够重振团队对平台的信心。
5. 战略性预防:构建稳健的模型 🛡️
虽然重构是可行的,但预防远比重构更具有成本效益。采用严谨的方法来创建ERD可以降低大多数风险。
5.1 迭代式设计
不要等到最终需求确定后再设计模式。从那些稳定的核心实体和关系开始。允许模型逐步演进。将ERD视为一个持续更新的活文档,随着功能需求的提出而不断调整。
5.2 数据模型的同行评审
正如代码需要评审一样,数据库模式也应进行评审。一双全新的眼睛可以发现:
- 冗余的数据字段。
- 表之间的关联关系缺失。
- 潜在的命名冲突。
- 违反规范化规则。
这一评审过程确保在编写任何迁移代码之前,模型就与业务意图保持一致。
5.3 文档化与命名规范
一致性是关键。为表和列建立严格的命名规范。避免使用不广为人知的缩写。为每个外键记录其背后对应的业务规则。这能确保任何新加入团队的人都能理解数据而无需提问。
6. 事后分析案例:经验教训 📝
让我们分析一些假设场景,这些场景中糟糕的ERD设计导致了重大问题,从而提供避免类似问题的启示。
情景A:孤立记录危机
情况:一个团队设计了一个系统来追踪用户订单和配送地址。他们移除了外键约束以提升写入性能,假设应用逻辑会处理验证。
失败原因:随着时间推移,用户删除了账户但保留了订单。配送地址因此变成了孤立记录。当团队尝试生成税务报告时,连接操作失败,因为用户数据已不存在。
代价:团队不得不编写脚本,将历史数据手动关联到一个通用的“匿名”用户桶中。这耗费了三天的工程时间,并且需要进行完整的数据库备份和恢复以安全测试。
情景B:反规范化陷阱
情况:为了加快读取性能,一个团队将用户资料数据复制到了订单表中。他们认为这将减少连接操作。
失败:当用户更新姓名时,应用程序更新了用户表,但未能更新包含旧姓名的数千条订单记录。报告表明,同一个用户的姓名不一致。
代价:数据一致性丢失。团队不得不决定是接受不一致,还是实现一个复杂的触发器系统来同步数据。他们选择重构模式以消除重复,这需要重写应用程序的写入逻辑。
场景C:索引盲点
情况:一个搜索功能建立在包含数百万行记录的表上。开发者认为主键就足够了。
失败:随着表的增长,搜索列上的查询速度变得极慢。数据库不得不执行全表扫描。
代价:系统在高峰时段变得无法使用。之后添加索引需要长时间运行的操作,导致表被锁定数小时,造成服务中断。
7. 为你的数据层做好未来准备 🔮
任何数据建模工作的目标都是创建一个能够承受变化的基础。尽管没有哪种模式能永远完美,但一个良好的ERD能为演进提供清晰的路径。
- 版本控制:将你的模式迁移视为代码。将其存储在版本控制系统中,以追踪随时间的变化。
- 自动化测试:在CI/CD流水线中包含模式验证。确保迁移不会破坏现有的查询。
- 监控:监控查询性能,以便尽早发现缺失的索引或低效的连接。
- 社区标准:遵循你特定数据库技术的既定最佳实践,以确保兼容性和性能。
在ERD阶段投入时间并不是延迟,而是一种加速。它减少了未来开发的阻力,并确保数据始终是可靠的资产,而非负担。
结论:无知的代价 vs. 规划的价值 ⚖️
糟糕的ER图的隐性成本通常在为时已晚之前都难以察觉。它表现为功能交付变慢、生产环境不稳定以及工程师团队的挫败感。重构数据库是一项高风险操作,需要精确、规划,通常还需要长时间停机。
通过将数据建模视为关键的工程任务而非行政琐事,组织可以避免技术债务的陷阱。一个设计良好的模式起到了保护作用,确保应用在成长过程中依然稳健。在设计一个稳固的ERD上投入的努力,将在后续编写的每一行代码、执行的每一次查询以及服务的每一位用户身上获得回报。
不要等到事后分析才意识到良好蓝图的价值。从第一天起就以清晰、严谨和对数据完整性的承诺开始规划。

