











Lorsqu’un système logiciel commence à évoluer, le niveau de données devient souvent le goulot d’étranglement le plus critique. Alors que le code applicatif peut être réécrit et les interfaces front-end redessinées, le schéma de base de données représente la vérité fondamentale de l’application. Un diagramme Entité-Relation (ER) mal conçu n’est pas simplement un inconvénient visuel ; c’est une faiblesse structurelle qui s’aggrave au fil du temps. Cette analyse examine les coûts tangibles et intangibles liés à une modélisation de base de données défaillante, ainsi que la réalité complexe de la refonte de ces structures plus tard dans le cycle de développement.
Beaucoup d’équipes considèrent la conception du schéma comme une tâche préliminaire, quelque chose à finaliser avant que le véritable développement ne commence. Cependant, au fur et à mesure que les exigences évoluent et que la logique métier évolue, la rigidité d’un ERD mal planifié devient évidente. Le coût d’ignorer ces détails ne se mesure pas seulement en heures passées à écrire du SQL, mais en perte de vitesse, en risque accru de panne et en dégradation de la confiance de l’équipe envers l’infrastructure.
1. L’analogie du plan architectural : pourquoi le schéma compte 🏗️
Imaginez un schéma de base de données comme le plan architectural d’un bâtiment. Si les murs porteurs sont mal placés, ou si les canalisations sont mal orientées, la structure peut tenir au départ. Mais au fil du temps, des fissures apparaissent. Ajouter des fonctionnalités supplémentaires sur une fondation faible conduit à une défaillance structurelle. En logiciel, cela se traduit par des requêtes lentes, des incohérences de données et une impossibilité d’ajouter de nouvelles fonctionnalités sans casser celles existantes.
Un ERD sert d’outil de communication entre les parties prenantes, les développeurs et les architectes de données. Il définit les entités, leurs attributs et les relations entre elles. Lorsque ce diagramme est ambigu ou incomplet, cela entraîne :
- Ambiguïté d’implémentation :Les développeurs font des hypothèses sur l’intégrité des données qui peuvent ne pas correspondre aux règles métiers.
- Problèmes de normalisation :Les données sont soit trop fragmentées, nécessitant des jointures excessives, soit trop dénormalisées, entraînant des anomalies de mise à jour.
- Omissions de contraintes :L’absence de clés étrangères ou de contraintes de vérification permet à des données invalides d’entrer dans le système.
Ces problèmes s’accumulent. Une petite erreur dans le type de relation peut passer inaperçue pendant des mois, pour provoquer une panne catastrophique lors de l’exécution d’un rapport ou d’une migration spécifique.
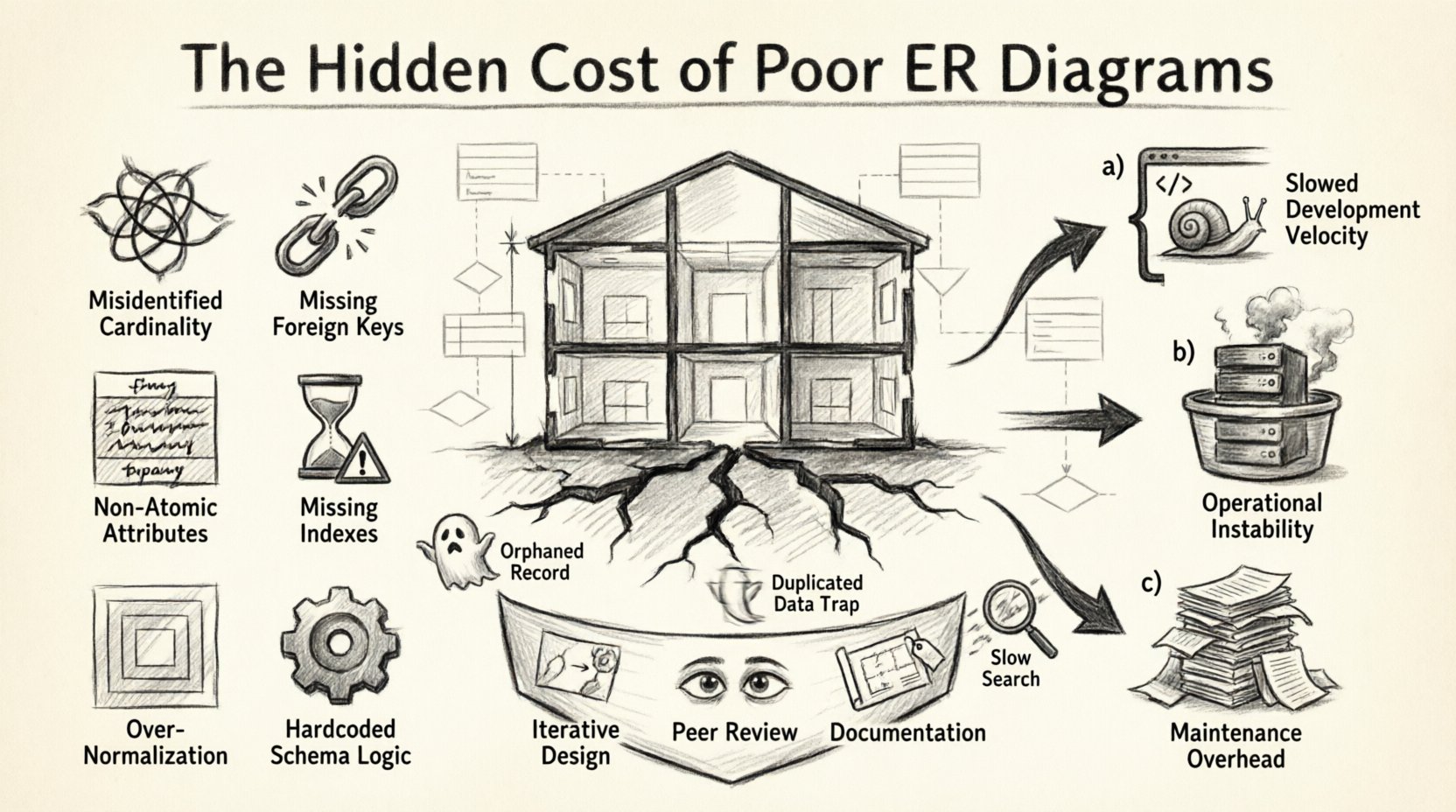
2. Anatomie d’un schéma défectueux : erreurs courantes de modélisation 🔍
Identifier les erreurs spécifiques dans un ERD est la première étape pour comprendre les coûts engagés. Ci-dessous se trouve une analyse des pièges courants de modélisation qui entraînent une dette technique importante.
| Catégorie | Erreur courante | Impact sur le système |
|---|---|---|
| Relations | Cardinalité mal identifiée (1:1 vs 1:N) | Stockage inefficace, jointures complexes, duplication de données. |
| Contraintes | Clés étrangères manquantes | Enregistrements orphelins, perte d’intégrité des données, nettoyage manuel requis. |
| Attributs | Colonnes non atomiques | Difficulté de requêtage, impossibilité d’indexer des parties spécifiques des données. |
| Performance | Index manquant sur les clés étrangères | Jointures lentes, contention de verrouillage lors des écritures, utilisation élevée du CPU. |
| Conception | Normalisation profondément imbriquée | Jointures de tables excessives pour des lectures simples, complexité des requêtes. |
| Évolutivité | Logique codée en dur dans le schéma | Schéma rigide qui ne peut pas s’adapter à de nouveaux états métiers. |
Chacune de ces entrées représente un point de friction. Lorsqu’un développeur rencontre une erreur dans le schéma, il essaie souvent de contourner le problème avec une logique au niveau de l’application. Cela fait passer les règles métier dans la base de code, créant une séparation des préoccupations difficile à maintenir.
3. Quantifier la dette technique 💰
Le coût d’une mauvaise conception est rarement immédiat. Il s’agit d’une fuite lente des ressources. Nous pouvons catégoriser ces coûts en trois grandes catégories : vitesse de développement, stabilité opérationnelle et surcharge de maintenance.
3.1 Vitesse de développement
Lorsque le schéma est flou, les développeurs passent du temps à reconstruire le modèle de données au lieu de développer des fonctionnalités. Ils doivent :
- Suivre le flux des données à travers plusieurs tables pour comprendre un seul champ.
- Écrire des requêtes SQL complexes pour compenser les relations manquantes.
- Gérer des tâches de nettoyage des données qui auraient dû être évitées à la source.
Cela ralentit la livraison des fonctionnalités. Un sprint qui devrait prendre trois jours peut s’étirer sur cinq ou six jours à cause du débogage des données. C’est un coût direct pour le temps et le budget de l’organisation.
3.2 Stabilité opérationnelle
Les problèmes de base de données apparaissent souvent en production sous charge. Des stratégies d’indexation médiocres ou l’absence de contraintes peuvent entraîner :
- Contention sur les verrous :Lorsque plusieurs transactions tentent de mettre à jour les mêmes tables mal structurées, le système s’arrête complètement.
- Délais d’attente des requêtes :Les jointures non optimisées obligent la base de données à scanner des millions de lignes inutilement.
- Corruption des données :Sans contraintes appropriées, des données invalides peuvent se propager dans le système, rendant difficile la confiance dans les rapports.
3.3 Surcharge de maintenance
Chaque année où un schéma défectueux existe, le coût de sa correction augmente. Cela est dû à l’accumulation de dépendances. De nouvelles fonctionnalités sont construites sur la structure ancienne et défectueuse. Le refactoring devient comme déplacer la fondation d’une maison alors que des personnes vivent encore à l’intérieur.
4. Le processus de refactoring : complexité et risque 🛠️
Une fois la décision prise de refactoer la base de données, le processus est semé d’obstacles. Ce n’est pas simplement une question de modifier des tables. Il implique une orchestration soigneuse des migrations, des vérifications de cohérence des données et un temps d’indisponibilité minimal.
4.1 La stratégie de migration
Le refactoring nécessite des scripts de migration. Ces scripts doivent être idempotents et réversibles. Toutefois, si le schéma était mal documenté, la rédaction de ces scripts devient un jeu de devinettes. Vous devez vous assurer que :
- Les données existantes sont transformées correctement sans perte.
- Les applications en cours d’exécution ne plantent pas pendant la transition.
- Les plans de retour en arrière sont viables si quelque chose tourne mal.
Dans les systèmes complexes, cela peut nécessiter une stratégie d’écriture double où les nouvelles données sont écrites dans la nouvelle structure tandis que les anciennes données sont migrées en arrière-plan. Cela double temporairement la complexité de la logique de l’application.
4.2 Interruption et disponibilité
Certaines modifications structurelles, telles que l’ajout de colonnes avec des valeurs par défaut ou le réindexage de grandes tables, peuvent verrouiller la base de données. Pour les systèmes à haute disponibilité, cela est inacceptable. Le restructurage nécessite souvent la planification de fenêtres de maintenance, ce qui affecte l’expérience utilisateur et les revenus.
4.3 Le facteur humain
Le restructurage est aussi un événement psychologique pour l’équipe. Si l’équipe doit faire face à un flux constant de bogues de données causés par le schéma, le moral baisse. Ils se sentent constamment en lutte contre l’infrastructure plutôt que de créer de la valeur. Une base de données propre et bien modélisée redonne confiance dans la plateforme.
5. Prévention stratégique : construction de modèles résilients 🛡️
Bien que le restructurage soit possible, la prévention est bien plus rentable. Adopter une approche disciplinée pour la création des modèles entité-relation permet de réduire la majorité des risques.
5.1 Conception itérative
N’attendez pas les exigences finales pour concevoir le schéma. Commencez par les entités et les relations fondamentales qui sont stables. Permettez au modèle d’évoluer. Traitez le MDR comme un document vivant mis à jour en parallèle des demandes de fonctionnalités.
5.2 Revue par les pairs des modèles de données
Tout comme le code est revu, les schémas de base de données doivent l’être. Une paire d’yeux fraîche peut repérer :
- Champs de données redondants.
- Relations manquantes entre les tables.
- Conflits potentiels de nommage.
- Violation des règles de normalisation.
Ce processus de revue garantit que le modèle est en accord avec l’intention métier avant qu’une seule ligne de code de migration ne soit écrite.
5.3 Documentation et conventions de nommage
La cohérence est essentielle. Établissez des conventions de nommage strictes pour les tables et les colonnes. Évitez les abréviations non largement comprises. Documentez la règle métier derrière chaque clé étrangère. Cela garantit que toute personne rejoignant l’équipe peut comprendre les données sans poser de questions.
6. Scénarios post-mortem : leçons apprises 📝
Examinons des scénarios hypothétiques où une mauvaise conception du MDR a entraîné des problèmes importants, afin d’obtenir des enseignements sur ce qu’il faut éviter.
Scénario A : La crise des enregistrements orphelins
La situation :Une équipe a conçu un système pour suivre les commandes des utilisateurs et leurs adresses de livraison. Ils ont supprimé la contrainte de clé étrangère afin d’améliorer les performances d’écriture, en supposant que la logique de l’application gérerait la validation.
L’échec :Au fil du temps, les utilisateurs ont supprimé leurs comptes tout en conservant leurs commandes. Les adresses de livraison sont devenues orphelines. Lorsque l’équipe a tenté de générer un rapport fiscal, la jointure a échoué car les données utilisateur avaient disparu.
Le coût :L’équipe a dû écrire un script pour lier manuellement les données historiques à un conteneur générique « anonyme » pour les utilisateurs. Cela a pris trois jours de temps d’ingénierie et a exigé un dump complet de la base de données et une restauration pour tester en toute sécurité.
Scénario B : Le piège de la dénormalisation
La situation :Pour accélérer les performances de lecture, une équipe a copié les données du profil utilisateur dans la table des commandes. Elle pensait que cela réduirait les opérations de jointure.
L’échec :Lorsqu’un utilisateur a mis à jour son nom, l’application a mis à jour la table des utilisateurs, mais a échoué à mettre à jour les milliers d’enregistrements de commandes contenant l’ancien nom. Les rapports montraient des noms incohérents pour le même utilisateur.
Le coût :La cohérence des données a été perdue. L’équipe a dû décider entre accepter l’incohérence ou mettre en place un système complexe de déclencheurs pour synchroniser les données. Elle a choisi de restructurer le schéma pour supprimer la duplication, ce qui a exigé une refonte de la logique d’écriture de l’application.
Scénario C : Le point aveugle sur l’indexation
La situation :Une fonctionnalité de recherche a été développée sur une table contenant des millions de lignes. Le développeur supposait que la clé primaire serait suffisante.
L’échec :Au fur et à mesure que la table s’est agrandie, les requêtes sur la colonne de recherche se sont ralenties au point de devenir inutilisables. La base de données a dû effectuer un balayage complet de la table.
Le coût :Le système est devenu inutilisable pendant les heures de pointe. L’ajout d’un index plus tard a nécessité une opération longue qui a verrouillé la table pendant des heures, provoquant une interruption de service.
7. Rendre votre couche de données résistante aux évolutions futures 🔮
L’objectif de toute démarche de modélisation des données est de créer une fondation capable de résister aux changements. Bien qu’aucun schéma ne soit parfait pour toujours, un bon schéma entité-relation fournit une voie claire pour l’évolution.
- Contrôle de version :Traitez vos migrations de schéma comme du code. Stockez-les dans un système de contrôle de version pour suivre les modifications au fil du temps.
- Tests automatisés :Incluez la validation du schéma dans votre pipeline CI/CD. Assurez-vous que les migrations n’interrompent pas les requêtes existantes.
- Surveillance :Surveillez les performances des requêtes pour détecter rapidement les index manquants ou les jointures inefficaces.
- Normes de la communauté :Suivez les bonnes pratiques établies pour votre technologie de base de données spécifique afin d’assurer la compatibilité et les performances.
Investir du temps dans la phase de schéma entité-relation n’est pas un retard ; c’est une accélération. Cela réduit les frictions du développement futur et garantit que les données restent un actif fiable plutôt qu’une charge.
Conclusion : Le coût de l’ignorance face à la valeur de la planification ⚖️
Le coût caché des mauvais schémas entité-relation est souvent invisible jusqu’à ce qu’il soit trop tard. Il se manifeste par une livraison de fonctionnalités plus lente, des environnements de production instables et des équipes d’ingénierie frustrées. Le restructurage d’une base de données est une opération à haut risque qui exige précision, planification et souvent un temps d’arrêt important.
En traitant la modélisation des données comme une tâche d’ingénierie critique plutôt qu’une simple tâche administrative, les organisations peuvent éviter les pièges de la dette technique. Un schéma bien conçu agit comme un garde-fou, garantissant que l’application reste robuste au fil de sa croissance. L’effort consacré à la conception d’un bon schéma entité-relation rapporte des bénéfices dans chaque ligne de code écrite par la suite, chaque requête exécutée et chaque utilisateur servi.
N’attendez pas le rapport d’analyse post-mortem pour comprendre la valeur d’un bon plan. Commencez à planifier avec clarté, rigueur et engagement envers l’intégrité des données dès le premier jour.

