











Concevoir une structure de données solide est le pilier de toute application logicielle réussie. Lorsque les projets dépassent les simples prototypes et entrent dans la phase intermédiaire, la complexité des relations entre les données augmente considérablement. C’est là que les diagrammes Entité-Relation (ERD) deviennent des outils essentiels pour la communication et la planification. Toutefois, un diagramme bien dessiné ne garantit pas une base de données fonctionnant correctement. De nombreux développeurs tombent dans des pièges au cours du processus de normalisation, ce qui entraîne des goulets d’étranglement de performance ou des problèmes d’intégrité des données plus tard dans le développement.
Ce guide explore les meilleures pratiques essentielles pour les diagrammes ER, en se concentrant particulièrement sur l’évitement des pièges courants de la normalisation. Nous examinerons comment équilibrer l’intégrité des données et les performances, en veillant à ce que votre schéma reste maintenable au fur et à mesure de la croissance de votre projet. Que vous conceviez pour une plateforme e-commerce de taille moyenne ou un système de gestion complexe, ces principes vous aideront à bâtir une fondation qui résistera à l’épreuve du temps.
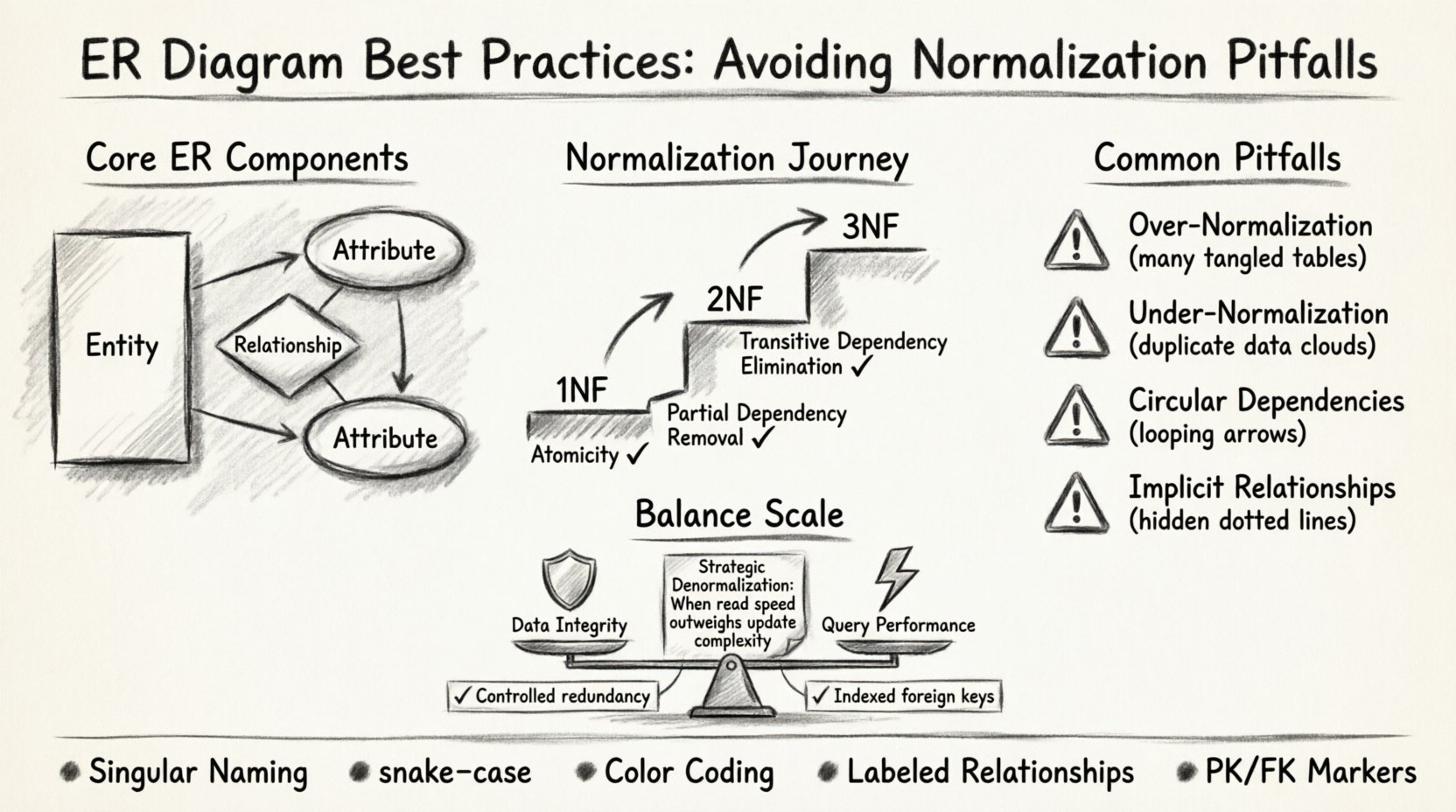
Comprendre les composants fondamentaux de la modélisation ER 🏗️
Avant de plonger dans la normalisation, il est essentiel d’établir une compréhension claire des éléments fondamentaux. Un diagramme ER visualise la structure d’une base de données à travers trois éléments principaux :
- Entités : Représentées par des rectangles, elles correspondent aux tables dans la base de données. Elles décrivent des objets d’intérêt, tels queClient, Commande, ou Produit.
- Attributs : Représentés par des ovales, ce sont les propriétés spécifiques d’une entité. Pour un Client, les attributs pourraient inclure IDClient, Nom, et AdresseEmail.
- Relations : Représentées par des losanges ou des lignes de connexion, elles définissent la manière dont les entités interagissent. Une relation indique comment les données d’une table sont liées aux données d’une autre.
Dans les projets intermédiaires, la complexité réside souvent dans les relations. Une relation simple un-à-un est directe, mais les relations un-à-plusieurs ou plusieurs-à-plusieurs exigent une gestion soigneuse pour éviter la redondance. La clarté visuelle est tout aussi importante que la correction logique. Un diagramme encombré ou ambigu peut entraîner une mauvaise interprétation par les développeurs, ce qui entraîne des incohérences dans le schéma lors de l’implémentation.
Le processus de normalisation : une exploration approfondie 🔍
La normalisation est le processus systématique d’organisation des données dans une base de données afin de réduire la redondance et d’améliorer l’intégrité des données. Bien qu’elle soit souvent enseignée comme un ensemble rigide de règles, elle est en réalité un équilibre. Dans les projets intermédiaires, l’objectif n’est pas nécessairement d’atteindre la forme normale la plus élevée, mais d’obtenir la structure la plus efficace pour le cas d’utilisation spécifique.
Première forme normale (1NF) : La fondation
La première étape consiste à garantir l’atomicité. Chaque colonne d’une table doit contenir une seule valeur. Aucun groupe répétitif ou tableau n’est autorisé dans une seule cellule.
- Vérifier : Chaque ligne possède-t-elle un identifiant unique (clé primaire) ?
- Vérifier : Toutes les colonnes contiennent-elles uniquement des valeurs simples ?
- Exemple : Une Produits table ne devrait pas avoir une colonne comme Couleurs contenant « Rouge, Bleu, Vert ». En revanche, créez une table séparée ProduitCouleurs table.
Deuxième forme normale (2NF) : Élimination des dépendances partielles
Une fois qu’une table est en 1NF, elle doit également être en 2NF. Cela signifie éliminer les dépendances partielles. Chaque attribut non clé doit dépendre de toute la clé primaire, et non seulement d’une partie. Cela est crucial lorsqu’on traite des clés composées.
- Règle : Si une table possède une clé primaire composée (A + B), chaque autre colonne doit dépendre à la fois de A et de B, et non seulement de A.
- Application : Dans une DétailsCommande table ayant une clé composée de IDCommande et IDProduit, la Quantité dépend des deux. Toutefois, NomProduit dépend uniquement de IDProduit. Déplacer NomProduit vers une Produits table résout cela.
Troisième forme normale (3NF) : suppression des dépendances transitives
La 3NF est la cible la plus courante pour les projets intermédiaires. Elle exige qu’aucun attribut non clé ne dépende d’un autre attribut non clé. Tous les attributs non clés doivent dépendre directement de la clé primaire.
- Scénario : Une Employé table contient IDEmployé, IDDépartement, et NomDépartement.
- Problème : NomDépartement dépend de IDDépartement, pas de IDEmployé.
- Solution : Déplacer NomDépartement vers une Départements table liée par IDDépartement.
Péchés courants de la normalisation dans les projets intermédiaires ⚠️
Bien que la normalisation soit puissante, l’appliquer aveuglément peut entraîner des problèmes importants. Les projets intermédiaires ont souvent des exigences spécifiques qui exigent une approche pragmatique. Ci-dessous figurent les pièges les plus fréquents rencontrés lors de la conception du schéma.
| Piège | Conséquence | Solution |
|---|---|---|
| Sur-normalisation | Trop de tables et des jointures complexes ralentissent les opérations de lecture. | Dénormaliser de manière stratégique: Combinez les tables pour les données fréquemment consultées et intensives en lecture. |
| Sous-normalisation | La redondance des données entraîne des anomalies de mise à jour et un gaspillage de stockage. | Appliquez la 3FN: Assurez-vous que les attributs non clés ne dépendent pas d’autres attributs non clés. |
| Dépendances circulaires | Les clés étrangères créent des boucles qui rendent la suppression des données difficile. | Auditer les relations: Revoyez toutes les contraintes de clés étrangères à la recherche de cycles. |
| Relations implicites | La logique est cachée dans le code de l’application plutôt que dans le schéma. | Rendre cela explicite: Utilisez les clés étrangères pour imposer les relations dans la base de données. |
Piège 1 : Le piège des performances
L’une des erreurs les plus fréquentes consiste à viser une normalisation parfaite sans tenir compte des performances des requêtes. Dans un projet intermédiaire, vous pouvez avoir des millions d’enregistrements. Une requête qui joint cinq tables différentes pour récupérer le profil d’un seul utilisateur peut être lente.
- Identifier les chemins critiques : Déterminez quelles requêtes s’exécutent le plus fréquemment.
- Lecture vs. écriture : Si votre application est orientée lecture, envisagez de dénormaliser des colonnes spécifiques.
- Vues matérialisées : Utilisez des vues de base de données pour stocker les résultats pré-calculés des agrégations complexes.
Piège 2 : Ignorer les contraintes de cardinalité
La cardinalité définit le nombre d’instances d’une entité qui peuvent ou doivent être associées à chaque instance d’une autre entité. Ne pas définir correctement cela dans le diagramme ER entraîne des erreurs de données.
- Un à un : Un utilisateur a exactement un profil. (par exemple, Utilisateurs et ProfilsUtilisateurs).
- Un à plusieurs : Un département a plusieurs employés. (par exemple, Départements et Employés).
- Plusieurs à plusieurs : Un étudiant peut s’inscrire à plusieurs cours, et un cours a plusieurs étudiants. Cela nécessite une table de jonction.
Lors de la conception du diagramme ER, marquez clairement ces contraintes. L’ambiguïté ici entraîne souvent des bogues dans l’application où le code suppose une relation qui n’existe pas dans la base de données.
Normes de conception visuelle pour la clarté 📊
Un schéma qui fonctionne logiquement mais qui est visuellement confus est une charge. Les projets intermédiaires impliquent souvent plusieurs développeurs travaillant sur des modules différents. Le diagramme ER doit servir de langage commun.
- Conventions de nommage cohérentes : Utilisez des noms au singulier pour les tables (par exemple, Client pas Clients) et snake_case pour les noms de colonnes (par exemple, premier_nom).
- Regroupement logique : Regroupez les entités liées ensemble sur la toile. Placez Commande, Article de commande, et Produit proches les uns des autres.
- Codage par couleur : Utilisez des couleurs distinctes pour les différents types d’entités (par exemple, tables principales vs. tables de configuration) afin d’aider à une reconnaissance rapide.
- Étiquetage des relations : N’oubliez jamais de laisser une ligne entre les tables sans étiquette. Précisez le type (par exemple, « Possède plusieurs », « Fait partie de »).
Considérez la liste suivante avant de finaliser votre schéma :
- Toutes les clés primaires sont-elles clairement marquées ?
- Les clés étrangères sont-elles étiquetées de manière cohérente ?
- La direction de la relation est-elle claire (du parent vers l’enfant) ?
- Les relations facultatives sont-elles distinguées des relations obligatoires ?
Gestion des relations Many-to-Many 🔄
Les relations Many-to-Many constituent la partie la plus complexe de la modélisation ER. Elles ne peuvent pas être représentées par une seule clé étrangère. En revanche, elles nécessitent une table d’association, souvent appelée table de jonction ou table pont.
Lors de la conception de ces tables, évitez de créer des espaces réservés simples. La table de jonction doit contenir des données pertinentes et significatives relatives à la relation elle-même.
- Mauvaise conception : Une table contenant uniquement IDUtilisateur et IDGroupe.
- Bonne conception : Une table contenant IDUtilisateur, IDGroupe, DateD’inscription, et Rôle.
Cette approche vous permet de stocker des métadonnées sur la relation sans violer les règles de normalisation. Elle permet également des requêtes telles que « Trouver tous les utilisateurs qui ont rejoint le groupe X après la date Y ».
Compromis entre performance et intégrité 🛡️
Il n’existe pas de schéma de base de données parfait. Chaque décision de conception implique un compromis. Dans les projets intermédiaires, les enjeux sont plus élevés que dans les prototypes, mais plus faibles que dans les systèmes d’entreprise. Vous devez prioriser en fonction des besoins métiers.
Intégrité des données
La normalisation assure l’intégrité. Si vous normalisez complètement, vous évitez les données en double et assurez la cohérence. Cependant, cela se fait au prix de jointures plus complexes.
- Clés étrangères : Utilisez-les pour assurer l’intégrité référentielle.
- Contraintes : Utilisez UNIQUE, NOT NULL, et CHECK des contraintes pour valider les données à la source.
Performance des requêtes
La dénormalisation accélère les lectures mais complique les écritures. Si votre application nécessite une analyse en temps réel, vous devrez peut-être dupliquer des données.
- Réplicas de lecture : Pensez à un schéma distinct optimisé pour les rapports.
- Mise en cache : Utilisez des couches de mise en cache pour les données normalisées fréquemment consultées.
- Indexation : Assurez-vous que les colonnes de clés étrangères sont indexées pour accélérer les opérations de jointure.
Maintenance et évolution 📝
Les schémas de base de données sont rarement statiques. Au fur et à mesure que les besoins métiers évoluent, le diagramme ER doit évoluer lui aussi. Une adhésion rigide à une conception réalisée il y a plusieurs mois peut freiner l’avancement.
- Contrôle de version : Traitez vos définitions de schéma comme du code. Utilisez des scripts de migration pour suivre les modifications.
- Documentation :Maintenez le diagramme ER synchronisé avec la base de données réelle. Un diagramme obsolète est pire qu’aucun diagramme.
- Refactoring :Revoyez régulièrement le schéma. Y a-t-il des tables qui ne sont plus utilisées ? Y a-t-il des colonnes toujours nulles ?
Lors de modifications, envisagez toujours l’impact sur les données existantes. Renommer une colonne peut casser le code de l’application. Ajouter une contrainte NOT NULL peut échouer sur des valeurs nulles existantes. Prévoyez soigneusement les migrations.
Conclusion sur la conception du schéma ⚖️
Créer un diagramme ER de haute qualité est un processus itératif qui exige des connaissances techniques et un jugement pratique. En comprenant les principes de normalisation et en reconnaissant leurs limites, vous pouvez éviter les pièges courants qui affectent les projets intermédiaires. Concentrez-vous sur la clarté, la cohérence et les besoins spécifiques de performance de votre application.
Souvenez-vous que l’objectif n’est pas seulement de stocker des données, mais de les récupérer efficacement et de maintenir leur exactitude dans le temps. Des revues régulières de votre diagramme par rapport à vos requêtes réelles maintiendront votre projet en bonne santé. Appliquez ces bonnes pratiques, et votre architecture de base de données soutiendra efficacement la croissance de votre application.
- Revoyez vos relations régulièrement.
- Équilibrez la normalisation avec les besoins de performance.
- Documentez vos décisions clairement.
- Validez votre schéma avec des scénarios de données du monde réel.

