











Die Gestaltung einer robusten Datenstruktur ist die Grundlage jeder erfolgreichen Softwareanwendung. Wenn Projekte über einfache Prototypen hinausgehen und die mittlere Phase erreichen, steigt die Komplexität der Datenbeziehungen erheblich. Genau hier werden Entity-Relationship-Diagramme (ERD) zu entscheidenden Werkzeugen für Kommunikation und Planung. Ein gut gezeichnetes Diagramm garantiert jedoch nicht unbedingt eine funktionierende Datenbank. Viele Entwickler geraten in Fallen während des Normalisierungsprozesses, was später zu Leistungsengpässen oder Datenintegritätsproblemen führen kann.
Diese Anleitung untersucht die wesentlichen Best Practices für ER-Diagramme, wobei der Fokus auf der Vermeidung häufiger Normalisierungsfallen liegt. Wir werden untersuchen, wie man Integrität und Leistung ausbalanciert, um sicherzustellen, dass Ihre Datenbankstruktur auch bei wachsendem Projektumfang wartbar bleibt. Egal, ob Sie für eine mittelgroße E-Commerce-Plattform oder ein komplexes Verwaltungssystem arbeiten – diese Prinzipien helfen Ihnen, eine Grundlage zu schaffen, die der Zeit standhält.
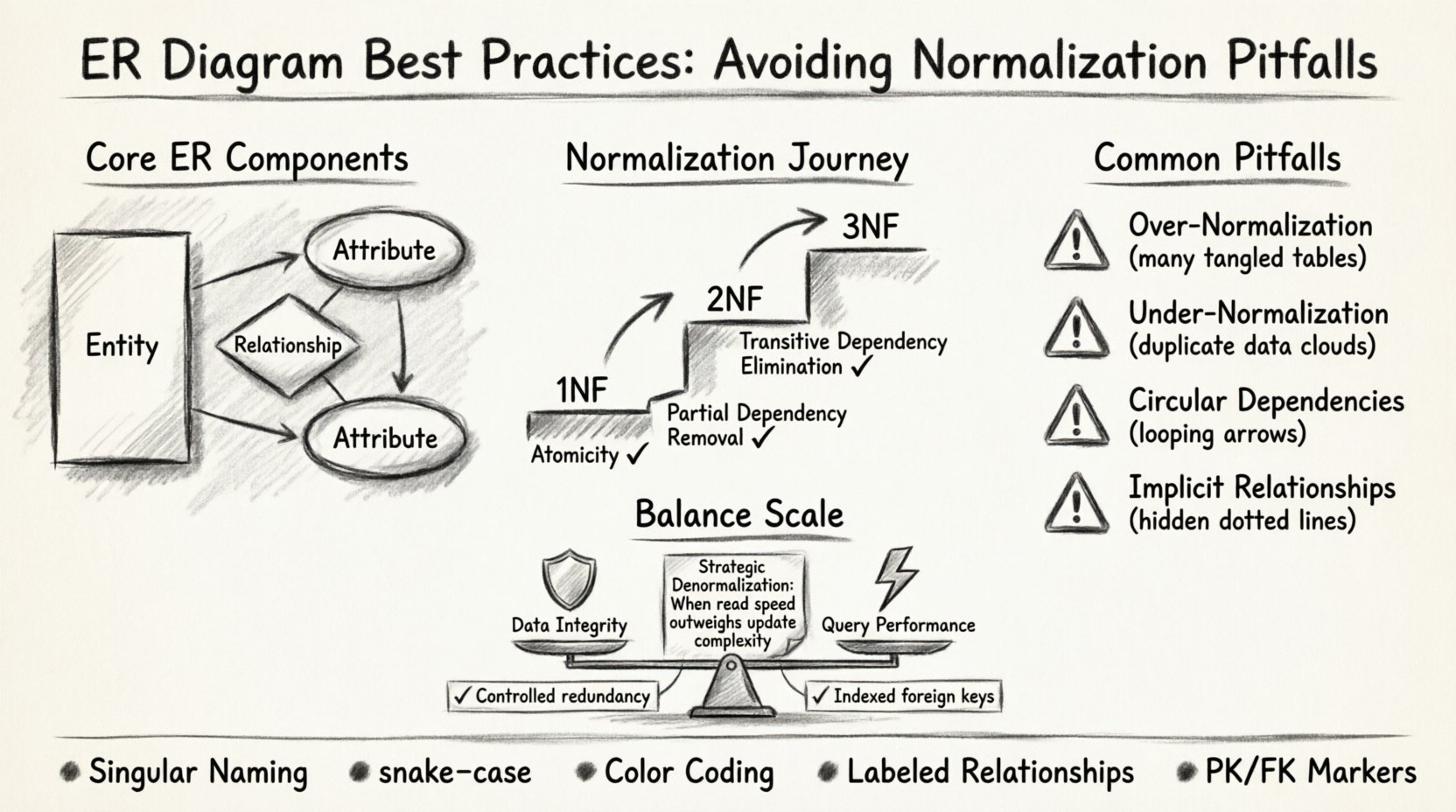
Verständnis der zentralen Komponenten der ER-Modellierung 🏗️
Bevor man sich der Normalisierung widmet, ist es unerlässlich, ein klares Verständnis der grundlegenden Bausteine zu erlangen. Ein ER-Diagramm visualisiert die Struktur einer Datenbank über drei Hauptelemente:
- Entitäten: Dargestellt als Rechtecke, entsprechen sie Tabellen in der Datenbank. Sie beschreiben interessante Objekte, wie zum BeispielKunden, Bestellung, oderProdukt.
- Attribute: Dargestellt als Ellipsen, sind dies die spezifischen Eigenschaften einer Entität. Für einenKunden, könnten Attribute beinhaltenKundenID, Name, undE-Mail-Adresse.
- Beziehungen: Dargestellt als Rauten oder Verbindungslinien, definieren sie, wie Entitäten miteinander interagieren. Eine Beziehung zeigt an, wie Daten in einer Tabelle mit Daten in einer anderen Tabelle verknüpft sind.
Bei mittleren Projekten liegt die Komplexität oft in den Beziehungen. Eine einfache ein-zu-eins-Beziehung ist einfach zu handhaben, aber viele-zu-viele-Beziehungen erfordern sorgfältige Behandlung, um Redundanz zu vermeiden. Visuelle Klarheit ist ebenso wichtig wie logische Richtigkeit. Ein überladenes oder mehrdeutiges Diagramm kann zu Missverständnissen durch Entwickler führen, was bei der Implementierung zu Schema-Inkonsistenzen führt.
Der Normalisierungsprozess: Eine detaillierte Betrachtung 🔍
Die Normalisierung ist der systematische Prozess der Organisation von Daten in einer Datenbank, um Redundanz zu reduzieren und die Datenintegrität zu verbessern. Obwohl sie oft als starre Regelmenge vermittelt wird, ist sie eigentlich ein Ausgleich. Bei mittleren Projekten geht es nicht unbedingt darum, die höchste Normalform zu erreichen, sondern die effizienteste Struktur für den jeweiligen Anwendungsfall zu erzielen.
Erste Normalform (1NF): Die Grundlage
Der erste Schritt besteht darin, die Atomsicherheit zu gewährleisten. Jede Spalte in einer Tabelle muss nur einen einzelnen Wert enthalten. Wiederholungsgruppen oder Arrays sind innerhalb einer einzigen Zelle nicht zulässig.
- Prüfen: Hat jede Zeile einen eindeutigen Bezeichner (Primärschlüssel)?
- Prüfen: Enthalten alle Spalten nur einzelne Werte?
- Beispiel: Eine ProdukteTabelle sollte keine Spalte wie Farben enthalten „Rot, Blau, Grün“. Stattdessen erstellen Sie eine separate ProduktFarbenTabelle.
Zweite Normalform (2NF): Beseitigung partieller Abhängigkeiten
Sobald eine Tabelle in 1NF ist, muss sie auch in 2NF sein. Das bedeutet, partielle Abhängigkeiten zu beseitigen. Jedes nicht-schlüsselbezogene Attribut muss sich auf den gesamten Primärschlüssel beziehen, nicht nur auf einen Teil davon. Dies ist entscheidend bei der Verwendung zusammengesetzter Schlüssel.
- Regel: Wenn eine Tabelle einen zusammengesetzten Primärschlüssel (A + B) hat, muss jedes andere Feld sich auf A und B beziehen, nicht nur auf A.
- Anwendung: In einer BestellDetailsTabelle mit einem zusammengesetzten Schlüssel von BestellID und ProduktID, das Menge hängt von beiden ab. Allerdings hängt ProduktName hängt nur von ProduktID. Verschieben Produktname in eine Produkte Tabelle löst dies.
Dritte Normalform (3NF): Entfernen transitiver Abhängigkeiten
3NF ist das häufigste Ziel für mittlere Projekte. Es erfordert, dass keine Nicht-Schlüssel-Attribute von einem anderen Nicht-Schlüssel-Attribut abhängen. Alle Nicht-Schlüssel-Attribute müssen direkt auf den Primärschlüssel abhängen.
- Szenario: Eine Mitarbeiter Tabelle hat MitarbeiterID, AbteilungsID, und Abteilungsname.
- Problem: Abteilungsname hängt ab von AbteilungsID, nicht MitarbeiterID.
- Lösung: Verschiebe Abteilungsname in eine Abteilungen Tabelle, die durch AbteilungsID.
Häufige Normalisierungsfallen in mittleren Projekten ⚠️
Während die Normalisierung mächtig ist, kann ihre blindlings Anwendung zu erheblichen Problemen führen. Mittlere Projekte haben oft einzigartige Anforderungen, die einen pragmatischen Ansatz erfordern. Nachfolgend finden Sie die häufigsten Fallen, die bei der Entwurf von Schemata auftreten.
| Falle | Folge | Lösung |
|---|---|---|
| Über-Normalisierung | Zu viele Tabellen und komplexe Joins verlangsamen Leseoperationen. | Strategisch denormalisieren: Kombinieren Sie Tabellen für häufig abgerufene, lesedichte Daten. |
| Unter-Normalisierung | Datenspeicherung führt zu Aktualisierungsanomalien und verschwendet Speicherplatz. | 3NF durchsetzen: Stellen Sie sicher, dass nicht-schlüsselbasierte Attribute nicht von anderen nicht-schlüsselbasierten Attributen abhängen. |
| Zirkuläre Abhängigkeiten | Fremdschlüssel erzeugen Schleifen, die die Löschung von Daten erschweren. | Beziehungen überprüfen: Überprüfen Sie alle Fremdschlüsselbeschränkungen auf Zyklen. |
| Implizite Beziehungen | Die Logik ist im Anwendungscode versteckt, anstatt im Schema. | Machen Sie es explizit: Verwenden Sie Fremdschlüssel, um Beziehungen in der Datenbank zu erzwingen. |
Falle 1: Die Leistungsfallen
Eine der häufigsten Fehler ist das Bestreben nach perfekter Normalisierung, ohne die Abfrageleistung zu berücksichtigen. In einem mittleren Projekt könnten Sie Millionen von Datensätzen haben. Eine Abfrage, die fünf verschiedene Tabellen verknüpft, um das Profil eines einzelnen Benutzers abzurufen, kann langsam sein.
- Identifizieren Sie heiße Pfade:Ermitteln Sie, welche Abfragen am häufigsten ausgeführt werden.
- Lesen gegenüber Schreiben:Wenn Ihre Anwendung lesedicht ist, erwägen Sie die Denormalisierung bestimmter Spalten.
- Materialisierte Ansichten:Verwenden Sie Datenbankansichten, um vorberechnete Ergebnisse für komplexe Aggregationen zu speichern.
Falle 2: Ignorieren von Kardinalitätsbeschränkungen
Die Kardinalität definiert die Anzahl der Instanzen einer Entität, die mit jeder Instanz einer anderen Entität assoziiert sein können oder müssen. Das Fehlen einer korrekten Definition in dem ER-Diagramm führt zu Datenfehlern.
- Ein-zu-eins: Ein Benutzer hat genau ein Profil. (z. B. Benutzer und Benutzerprofile).
- Ein-zu-viele: Eine Abteilung hat viele Mitarbeiter. (z. B. Abteilungen und Mitarbeiter).
- Viele-zu-viele: Ein Student kann sich in viele Kurse einschreiben, und ein Kurs hat viele Studenten. Dafür ist eine Verbindungstabelle erforderlich.
Bei der Gestaltung des ER-Diagramms sollten diese Beschränkungen klar gekennzeichnet werden. Mehrdeutigkeiten führen hier oft zu Anwendungsfehlern, bei denen der Code eine Beziehung annimmt, die in der Datenbank nicht existiert.
Visuelle Gestaltungsstandards für Klarheit 📊
Ein Schema, das logisch funktioniert, aber visuell verwirrend ist, ist eine Belastung. Mittlere Projekte beinhalten oft mehrere Entwickler, die an unterschiedlichen Modulen arbeiten. Das ER-Diagramm muss als gemeinsame Sprache dienen.
- Konsistente Namenskonventionen: Verwenden Sie Singular-Nomen für Tabellen (z. B. Kunde nicht Kunden) und snake_case für Spaltennamen (z. B. vorname).
- Logische Gruppierung: Gruppieren Sie verwandte Entitäten zusammen auf der Leinwand. Platzieren Sie Bestellung, Bestellposition, und Produkt in der Nähe voneinander.
- Farbcodierung: Verwenden Sie unterschiedliche Farben für verschiedene Arten von Entitäten (z. B. Kerntabellen im Vergleich zu Konfigurationstabellen), um eine schnelle Erkennung zu erleichtern.
- Bezeichnen Sie Beziehungen: Lassen Sie niemals eine Linie zwischen Tabellen ohne Beschriftung. Geben Sie den Typ an (z. B. „Hat Viele“, „Ist Teil Von“).
Berücksichtigen Sie die folgende Prüfliste, bevor Sie Ihr Diagramm abschließen:
- Sind alle Primärschlüssel eindeutig gekennzeichnet?
- Sind Fremdschlüssel konsistent beschriftet?
- Ist die Richtung der Beziehung klar (von Eltern zu Kind)?
- Sind optionale im Vergleich zu obligatorischen Beziehungen unterschieden?
Behandlung von Many-to-Many-Beziehungen 🔄
Many-to-Many-Beziehungen sind der komplexeste Teil der ER-Modellierung. Sie können nicht durch einen einzigen Fremdschlüssel dargestellt werden. Stattdessen erfordern sie eine assoziative Tabelle, die oft als Verbindungstabelle oder Brückentabelle bezeichnet wird.
Bei der Gestaltung dieser Tabellen sollten Sie einfache Platzhalter vermeiden. Die Verbindungstabelle sollte sinnvolle Daten enthalten, die direkt mit der Beziehung selbst zusammenhängen.
- Schlechte Gestaltung: Eine Tabelle mit nur UserID und GroupID.
- Gute Gestaltung: Eine Tabelle mit UserID, GroupID, JoinDate, und Rolle.
Dieser Ansatz ermöglicht es Ihnen, Metadaten zur Beziehung zu speichern, ohne die Normalisierungsregeln zu verletzen. Er ermöglicht auch Abfragen wie „Finde alle Benutzer, die der Gruppe X nach dem Datum Y beigetreten sind“.
Leistung vs. Integrität – Kompromisse 🛡️
Es gibt kein perfektes Datenbank-Schema. Jede Gestaltungsentscheidung beinhaltet einen Kompromiss. Bei mittleren Projekten sind die Konsequenzen höher als bei Prototypen, aber geringer als bei Unternehmenssystemen. Sie müssen basierend auf den geschäftlichen Anforderungen priorisieren.
Datenintegrität
Die Normalisierung gewährleistet die Integrität. Wenn Sie vollständig normalisieren, vermeiden Sie doppelte Daten und gewährleisten Konsistenz. Dies hat jedoch den Nachteil komplexerer Joins.
- Fremdschlüssel: Verwenden Sie sie, um die Referenzintegrität durchzusetzen.
- Einschränkungen: Verwenden Sie EINDEUTIG, NICHT NULL, und CHECK Einschränkungen, um Daten an der Quelle zu validieren.
Abfrageleistung
Die De-Normalisierung beschleunigt Lesevorgänge, macht aber Schreibvorgänge komplizierter. Wenn Ihre Anwendung Echtzeit-Analysen erfordert, müssen Sie möglicherweise Daten duplizieren.
- Lesereplikate: Berücksichtigen Sie eine getrennte Schema-Struktur, die für Berichterstattung optimiert ist.
- Caching: Verwenden Sie Caching-Ebenen für häufig abgerufene normalisierte Daten.
- Indizierung: Stellen Sie sicher, dass Fremdschlüsselspalten indiziert sind, um Joins zu beschleunigen.
Wartung und Evolution 📝
Datenbankschemata sind selten statisch. Wenn sich die geschäftlichen Anforderungen ändern, muss das ER-Diagramm sich weiterentwickeln. Eine starre Einhaltung eines Entwurfs, der vor Monaten erstellt wurde, kann den Fortschritt behindern.
- Versionskontrolle: Behandeln Sie Ihre Schema-Definitionen wie Code. Verwenden Sie Migrations-Skripte, um Änderungen zu verfolgen.
- Dokumentation:Halten Sie das ER-Diagramm mit der tatsächlichen Datenbank synchron. Ein veraltetes Diagramm ist schlimmer als kein Diagramm.
- Refactoring:Überprüfen Sie regelmäßig das Schema. Gibt es Tabellen, die nicht mehr verwendet werden? Gibt es Spalten, die immer null sind?
Beim Ändern berücksichtigen Sie immer die Auswirkungen auf bestehende Daten. Das Umbenennen einer Spalte könnte Anwendungscode brechen. Das Hinzufügen einer Not-Null-Beschränkung könnte bei bestehenden Null-Werten fehlschlagen. Planen Sie Migrationen sorgfältig.
Fazit zur Schema-Design ⚖️
Die Erstellung eines hochwertigen ER-Diagramms ist ein iterativer Prozess, der technisches Wissen und praktische Urteilsfähigkeit erfordert. Durch das Verständnis von Normalisierungsprinzipien und die Erkennung ihrer Grenzen können Sie häufige Fallstricke vermeiden, die mittlere Projekte belasten. Konzentrieren Sie sich auf Klarheit, Konsistenz und die spezifischen Leistungsanforderungen Ihrer Anwendung.
Denken Sie daran, dass das Ziel nicht nur darin besteht, Daten zu speichern, sondern sie effizient abzurufen und ihre Genauigkeit über die Zeit zu bewahren. Regelmäßige Überprüfungen Ihres Diagramms anhand Ihrer tatsächlichen Abfragen halten Ihr Projekt gesund. Wenden Sie diese Best Practices an, und Ihre Datenbankarchitektur wird die Entwicklung Ihrer Anwendung effektiv unterstützen.
- Überprüfen Ihre Beziehungen regelmäßig.
- Abwägen Normalisierung mit Leistungsanforderungen.
- Dokumentieren Ihre Entscheidungen klar.
- Validieren Ihr Schema mit realen Daten-Szenarien.

