











Projektowanie solidnej struktury danych to fundament każdej pomyślnej aplikacji oprogramowania. Gdy projekty przechodzą poza proste prototypy i wchodzą w fazę pośrednią, złożoność relacji danych znacznie rośnie. To właśnie w tym momencie diagramy relacji encji (ERD) stają się kluczowymi narzędziami do komunikacji i planowania. Jednak dobrze narysowany diagram nie gwarantuje poprawnie działającej bazy danych. Wiele programistów wpada w pułapki podczas procesu normalizacji, co prowadzi później do problemów z wydajnością lub integralnością danych.
Ten przewodnik omawia kluczowe najlepsze praktyki dotyczące diagramów ER, skupiając się z konkretnym naciskiem na unikanie typowych pułapek normalizacji. Przeanalizujemy, jak osiągnąć równowagę między integralnością danych a wydajnością, zapewniając, że Twoja schemat pozostanie łatwy do utrzymania w miarę rozwoju projektu. Niezależnie od tego, czy projektujesz dla platformy e-commerce o średnim zasięgu, czy złożonego systemu zarządzania, te zasady pomogą Ci stworzyć fundament, który wytrzyma próbę czasu.
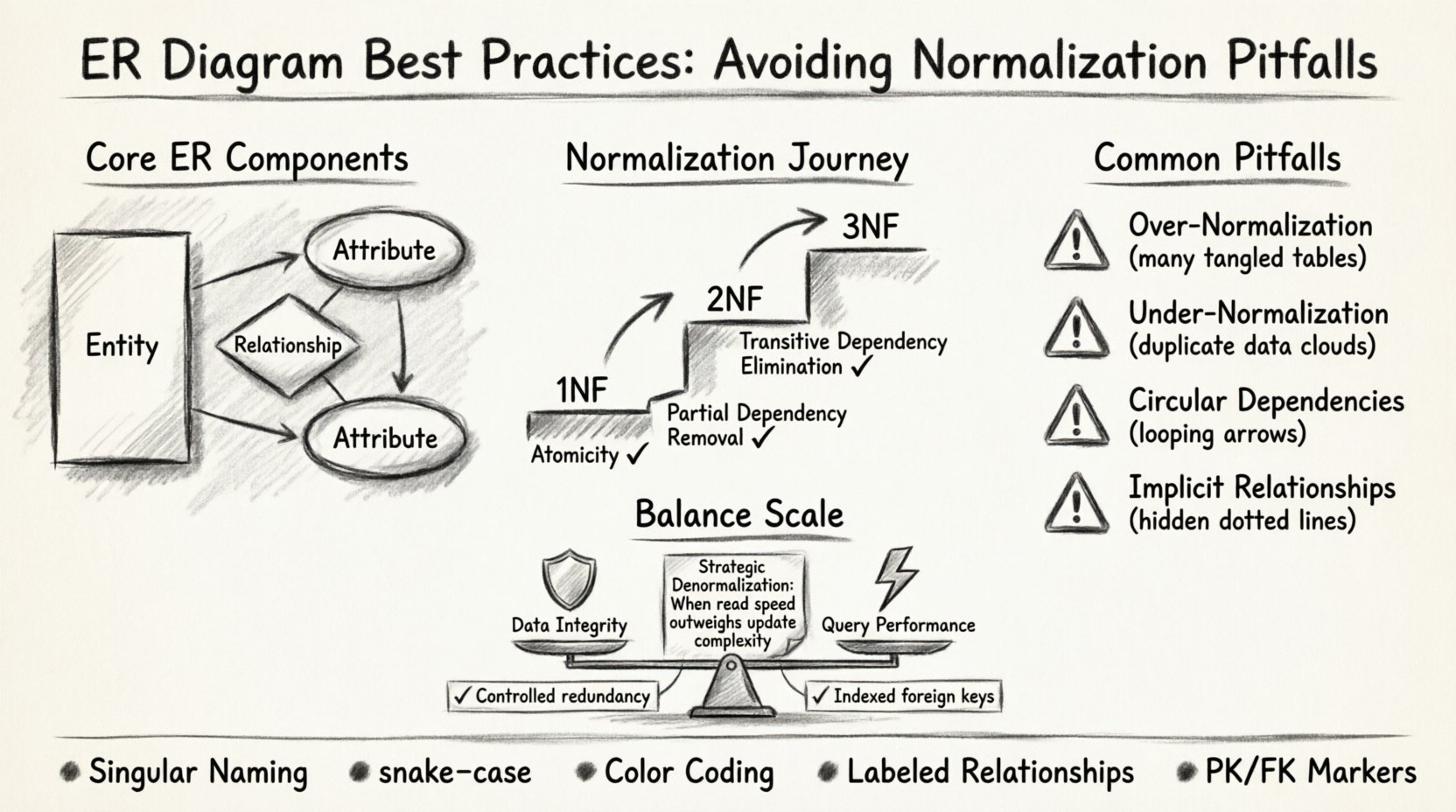
Zrozumienie podstawowych elementów modelowania ER 🏗️
Zanim przejdziesz do normalizacji, konieczne jest zrozumienie podstawowych elementów budowy. Diagram ER wizualizuje strukturę bazy danych za pomocą trzech głównych elementów:
- Encje:Zaznaczane jako prostokąty, odpowiadają one tabelom w bazie danych. Opisują obiekty interesujące, takie jakKlienta, Zamówienie, lubProdukt.
- Atrybuty:Zaznaczane jako elipsy, są to konkretne właściwości encji. DlaKlienta, atrybuty mogą obejmowaćIDKlienta, Imię, orazAdresEmail.
- Relacje:Zaznaczane jako romby lub linie połączeniowe, określają sposób wzajemnego oddziaływania encji. Relacja wskazuje, jak dane w jednej tabeli są powiązane z danymi w innej.
W projektach pośrednich złożoność często tkwi w relacjach. Prosta relacja jeden do jednego jest prosta do zrozumienia, ale relacje wiele do wielu wymagają ostrożnego traktowania, aby uniknąć nadmiarowości. Jasność wizualna jest równie ważna jak poprawność logiczna. Diagram zbyt zatłoczony lub niejasny może prowadzić do nieporozumień wśród programistów, co skutkuje niezgodnościami schematu podczas implementacji.
Proces normalizacji: szczegółowy przegląd 🔍
Normalizacja to systematyczny proces organizowania danych w bazie danych w celu zmniejszenia nadmiarowości i poprawy integralności danych. Choć często nauczana jako sztywny zestaw zasad, jest w rzeczywistości balansowaniem. W projektach pośrednich celem nie musi być osiągnięcie najwyższej postaci normalnej, ale osiągnięcie najefektywniejszej struktury dla konkretnego przypadku użycia.
Pierwsza postać normalna (1NF): Podstawa
Pierwszym krokiem jest zapewnienie atomowości. Każda kolumna w tabeli musi zawierać tylko jedną wartość. W jednym polu nie wolno umieszczać powtarzających się grup ani tablic.
- Sprawdź:Czy każdy wiersz ma unikalny identyfikator (klucz główny)?
- Sprawdź:Czy wszystkie kolumny zawierają tylko pojedyncze wartości?
- Przykład:Tabela Productsnie powinna mieć kolumny takiej jak Colorszawierającej „Czerwony, Niebieski, Zielony”. Zamiast tego utwórz osobną tabelę ProductColorstabelę.
Drugą postać normalną (2NF): eliminacja zależności częściowych
Gdy tabela znajduje się w 1NF, musi również znajdować się w 2NF. Oznacza to eliminację zależności częściowych. Każda atrybut niekluczowy musi zależeć od całego klucza głównego, a nie tylko od jego części. Jest to kluczowe podczas pracy z kluczami złożonymi.
- Zasada:Jeśli tabela ma złożony klucz główny (A + B), każda inna kolumna musi zależeć zarówno od A, jak i od B, a nie tylko od A.
- Zastosowanie:W tabeli OrderDetailsz złożonym kluczem głównym OrderIDiProductID, kolumna Quantityzależy od obu. Jednak ProductNamezależy tylko odProductID. Przenoszenie NazwaProduktu do tabeli Produkty tabela rozwiązuje ten problem.
Trzecia postać normalna (3NF): Usuwanie zależności przechodnich
3NF jest najczęściej wybieranym celem dla projektów pośrednich. Wymaga ona, aby żaden atrybut niekluczowy nie zależał od innego atrybutu niekluczowego. Wszystkie atrybuty niekluczowe muszą zależeć bezpośrednio od klucza głównego.
- Scenariusz: Tabela Pracownik ma IDPracownika, IDOddziału, oraz NazwaOddziału.
- Problem: NazwaOddziału zależy od IDOddziału, a nie IDPracownika.
- Rozwiązanie: Przenieś NazwaOddziału do tabeli Oddziały połączonych za pomocą IDOddziału.
Typowe pułapki normalizacji w projektach pośrednich ⚠️
Choć normalizacja jest potężnym narzędziem, jej ślepe stosowanie może prowadzić do poważnych problemów. Projekty pośrednie często mają unikalne wymagania, które wymagają praktycznego podejścia. Poniżej przedstawiono najczęściej spotykane pułapki podczas projektowania schematu.
| Pułapka | Skutek | Rozwiązanie |
|---|---|---|
| Zbyt duża normalizacja | Zbyt wiele tabel i skomplikowane łączenia spowalniają operacje odczytu. | Znieormalizuj strategicznie: Połącz tabele dla często dostępnego danych o wysokim obciążeniu odczytu. |
| Niewystarczająca normalizacja | Zmiana danych prowadzi do anomalii aktualizacji i marnowania pamięci. | Zastosuj 3NF: Upewnij się, że atrybuty niekluczowe nie zależą od innych atrybutów niekluczowych. |
| Zależności cykliczne | Klucze obce tworzą pętle, które utrudniają usuwanie danych. | Audyt relacji: Przejrzyj wszystkie ograniczenia kluczy obcych pod kątem cykli. |
| Niejawne relacje | Logika jest ukryta w kodzie aplikacji zamiast w schemacie. | Zrób to jawne: Użyj kluczy obcych, aby wymusić relacje w bazie danych. |
Pułapka 1: Pułapka wydajności
Jednym z najczęściej popełnianych błędów jest dążenie do doskonałej normalizacji bez uwzględnienia wydajności zapytań. W projekcie pośrednim możesz mieć miliony rekordów. Zapytanie, które łączy pięć różnych tabel w celu pobrania profilu jednego użytkownika, może być powolne.
- Zidentyfikuj krytyczne ścieżki: Określ, które zapytania są wykonywane najczęściej.
- Odczyt vs. Zapis: Jeśli Twoja aplikacja jest intensywnie odczytująca, rozważ znieormalizowanie określonych kolumn.
- Widoki materializowane: Użyj widoków bazy danych do przechowywania wyników obliczonych z góry dla złożonych agregacji.
Wada 2: Ignorowanie ograniczeń liczności
Liczność określa liczbę wystąpień jednego obiektu, które mogą być lub muszą być powiązane z każdym wystąpieniem innego obiektu. Nieprawidłowe określenie tego w diagramie ER prowadzi do błędów danych.
- Jeden do jednego: Użytkownik ma dokładnie jeden profil. (np. Użytkownicy i ProfiluUżytkowników).
- Jeden do wielu: Departament ma wielu pracowników. (np. Departamenty i Pracownicy).
- Wiele do wielu: Student może zapisywać się na wiele kursów, a kurs ma wielu studentów. Wymaga to tabeli pośredniej.
Podczas projektowania diagramu ER jasno oznaczaj te ograniczenia. Niejasność tutaj często prowadzi do błędów aplikacji, w których kod zakłada relację, która nie istnieje w bazie danych.
Zasady projektowania wizualnego dla przejrzystości 📊
Schemat działający logicznie, ale wizualnie nieczytelny, jest obciążeniem. Projekty pośrednie często obejmują wielu programistów pracujących nad różnymi modułami. Diagram ER musi służyć jako wspólny język.
- Spójne zasady nazewnictwa: Używaj rzeczowników liczby pojedynczej dla tabel (np. Klient nie Klienci) oraz snake_case dla nazw kolumn (np. imie).
- Grupowanie logiczne: Grupuj powiązane obiekty razem na płótnie. Umieść Zamówienie, ElementZamówienia, i Produkt obok siebie.
- Kodowanie kolorów: Używaj różnych kolorów dla różnych typów encji (np. tabel głównych w porównaniu do tabel konfiguracyjnych), aby ułatwić szybkie rozpoznawanie.
- Oznacz relacje: Nie pozostawiaj linii między tabelami bez etykiety. Wskaż typ (np. „Ma wiele”, „Jest częścią”).
Zastanów się nad poniższą listą kontrolną przed zakończeniem tworzenia diagramu:
- Czy wszystkie klucze główne są jasno oznaczone?
- Czy klucze obce są jednolicie oznaczone?
- Czy kierunek relacji jest jasny (od rodzica do dziecka)?
- Czy relacje opcjonalne i wymagane są rozróżniane?
Obsługa relacji wiele do wielu 🔄
Relacje wiele do wielu to najbardziej złożony element modelowania ER. Nie mogą być przedstawione za pomocą pojedynczego klucza obcego. Zamiast tego wymagają tabeli asocjacyjnej, często nazywanej tabelą połączeniową lub mostową.
Podczas projektowania tych tabel unikaj tworzenia prostych miejsc zastępczych. Tabela połączeniowa powinna przechowywać istotne dane dotyczące samej relacji.
- Zły projekt: Tabela z tylkoUserID i GroupID.
- Dobry projekt: Tabela zUserID, GroupID, JoinDate, i Rola.
Ten podejście pozwala przechowywać metadane dotyczące relacji bez naruszania zasad normalizacji. Umożliwia również zapytania typu „Znajdź wszystkich użytkowników, którzy dołączyli do Grupy X po Dacie Y”.
Zdolność wydajności w stosunku do integralności 🛡️
Nie istnieje doskonała schemat bazy danych. Każde decyzje projektowe wiążą się z kompromisem. W projektach pośrednich ryzyko jest większe niż w prototypach, ale mniejsze niż w systemach przedsiębiorstwowych. Musisz priorytetyzować w zależności od potrzeb biznesowych.
Integralność danych
Normalizacja zapewnia integralność. Jeśli całkowicie znormalizujesz, zapobiegasz powielaniu danych i zapewniasz spójność. Jednak to wiąże się z większą złożonością złączeń.
- Klucze obce: Używaj ich do zapewnienia integralności referencyjnej.
- Ograniczenia: Używaj UNIKALNE, NIE NULL, i SPRAWDŹ ograniczenia do weryfikacji danych na poziomie źródła.
Wydajność zapytań
Dekompozycja przyspiesza odczyty, ale utrudnia zapisy. Jeśli Twoja aplikacja wymaga analizy w czasie rzeczywistym, może być konieczne powielenie danych.
- Kopie odczytowe: Rozważ osobny schemat zoptymalizowany pod raportowanie.
- Buforowanie: Używaj warstw buforowania dla często dostępnego danych znormalizowanych.
- Indeksowanie: Upewnij się, że kolumny kluczy obcych są indeksowane, aby przyspieszyć operacje złączenia.
Konserwacja i ewolucja 📝
Schematy baz danych rzadko są statyczne. W miarę zmian wymagań biznesowych diagram ER musi ewoluować. Stale przestrzeganie projektu stworzonego kilka miesięcy temu może utrudniać postępy.
- Kontrola wersji: Traktuj definicje schematu jak kod. Używaj skryptów migracji do śledzenia zmian.
- Dokumentacja: Zachowaj diagram ER w synchronizacji z rzeczywistą bazą danych. Ustareły diagram jest gorszy niż żaden diagram.
- Refaktoryzacja: Regularnie przeglądarka schematu. Czy są tabele, które już nie są używane? Czy są kolumny, które zawsze są puste?
Podczas wprowadzania zmian zawsze rozważ ich wpływ na istniejące dane. Zmiana nazwy kolumny może uszkodzić kod aplikacji. Dodanie ograniczenia NOT NULL może nie powieść się przy istniejących wartościach NULL. Starannie planuj migracje.
Wnioski dotyczące projektowania schematu ⚖️
Tworzenie wysokiej jakości diagramu ER to proces iteracyjny wymagający wiedzy technicznej i praktycznej oceny. Zrozumienie zasad normalizacji i uświadomienie sobie ich ograniczeń pozwala uniknąć typowych pułapek, które atakują projekty pośrednie. Skup się na przejrzystości, spójności i konkretnych potrzebach wydajności Twojej aplikacji.
Pamiętaj, że celem nie jest tylko przechowywanie danych, ale także ich skuteczne pobieranie i utrzymanie dokładności w czasie. Regularne przeglądy diagramu w świetle rzeczywistych zapytań utrzymają Twój projekt w dobrej kondycji. Zastosuj te najlepsze praktyki, a architektura Twojej bazy danych będzie skutecznie wspierać rozwój Twojej aplikacji.
- Przeglądaj swoje relacje regularnie.
- Zrównowag normalizację z potrzebami wydajności.
- Dokumentuj swoje decyzje jasno.
- Weryfikuj swój schemat w scenariuszach danych z rzeczywistego świata.

