











Quando um sistema de software começa a escalar, a camada de dados frequentemente se torna o gargalo mais crítico. Enquanto o código da aplicação pode ser reescrito e as interfaces de front-end redesenhadas, o esquema do banco de dados representa a verdade fundamental da aplicação. Um Diagrama Entidade-Relacionamento (ERD) mal construído não é meramente uma inconveniência visual; é uma fragilidade estrutural que se acumula ao longo do tempo. Esta análise examina os custos tangíveis e intangíveis associados ao modelagem incorreta de bancos de dados e a realidade complexa da refatoração dessas estruturas mais tarde no ciclo de desenvolvimento.
Muitas equipes tratam o design do esquema como uma tarefa preliminar, algo a ser finalizado antes do início do código real. No entanto, à medida que os requisitos mudam e a lógica de negócios evolui, a rigidez de um ERD mal planejado torna-se evidente. O custo de ignorar esses detalhes não é apenas medido em horas gastas escrevendo SQL, mas em velocidade perdida, aumento do risco de paradas e deterioração da confiança da equipe na infraestrutura.
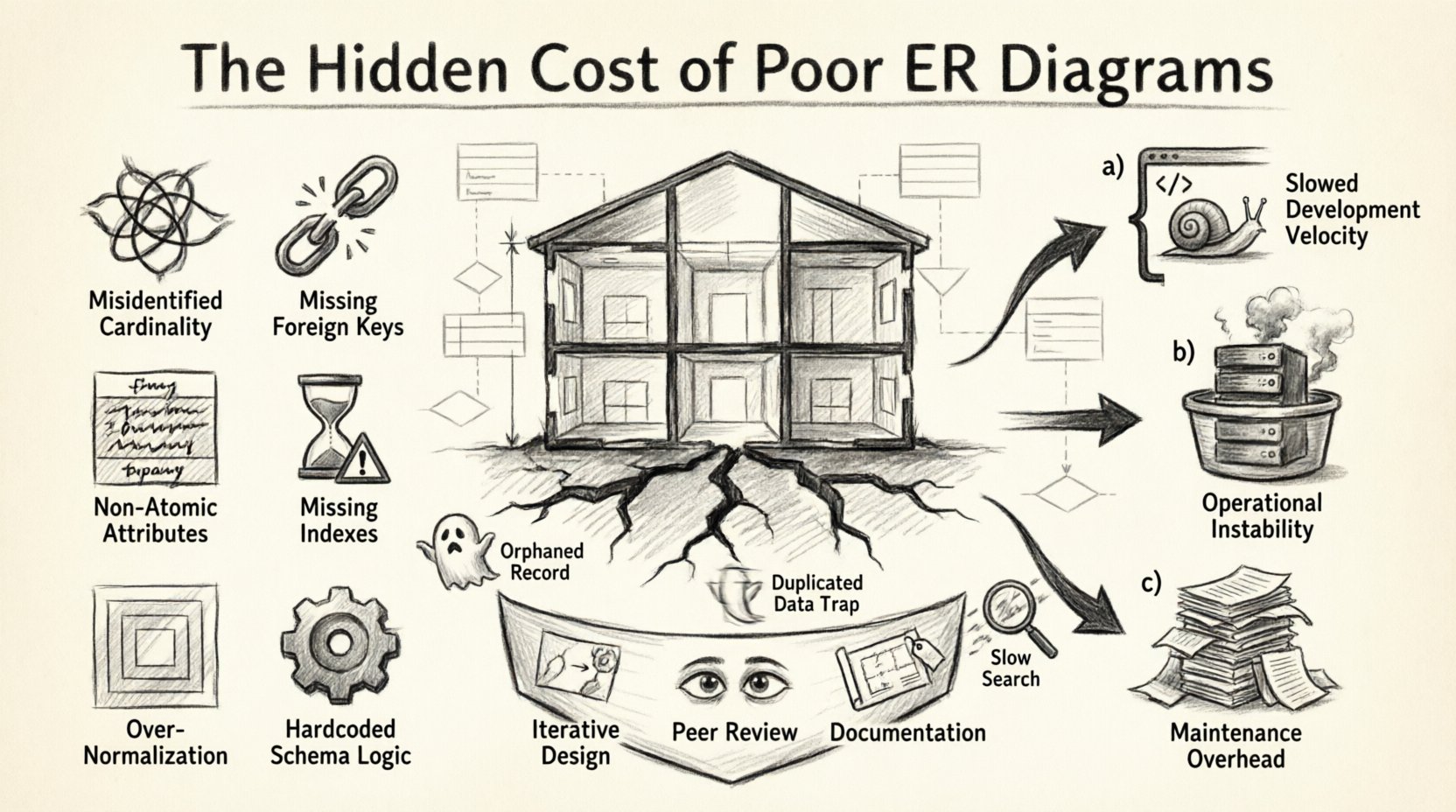
1. A Analogia do Projeto: Por que o Esquema Importa 🏗️
Pense no esquema de banco de dados como o projeto arquitetônico de um edifício. Se as paredes de sustentação forem colocadas incorretamente, ou se os encanamentos forem roteados de forma ineficiente, a estrutura pode permanecer de pé inicialmente. Mas com o tempo, rachaduras aparecem. Acumular recursos adicionais sobre uma fundação fraca leva a falhas estruturais. No software, isso se manifesta em consultas lentas, inconsistências de dados e a impossibilidade de adicionar novas funcionalidades sem quebrar as existentes.
Um ERD serve como ferramenta de comunicação entre partes interessadas, desenvolvedores e arquitetos de dados. Ele define entidades, seus atributos e as relações entre elas. Quando esse diagrama é ambíguo ou incompleto, isso leva a:
- Ambiguidade na Implementação:Desenvolvedores fazem suposições sobre a integridade dos dados que podem não corresponder às regras de negócios.
- Problemas de Normalização:Os dados são ou excessivamente fragmentados, exigindo junções excessivas, ou excessivamente denormalizados, levando a anomalias de atualização.
- Falhas em Restrições:A ausência de chaves estrangeiras ou restrições de verificação permite que dados inválidos entrem no sistema.
Esses problemas se acumulam. Um pequeno erro no tipo de relacionamento pode passar despercebido por meses, apenas para causar uma falha catastrófica quando um relatório específico ou uma migração é executado.
2. Anatomia de um Esquema Defeituoso: Erros Comuns de Modelagem 🔍
Identificar os erros específicos em um ERD é o primeiro passo para compreender os custos envolvidos. Abaixo está uma análise dos erros comuns de modelagem que levam a uma dívida técnica significativa.
| Categoria | Erro Comum | Impacto no Sistema |
|---|---|---|
| Relacionamentos | Cardinalidade Identificada Incorretamente (1:1 vs 1:N) | Armazenamento ineficiente, junções complexas, duplicação de dados. |
| Restrições | Chaves Estrangeiras Ausentes | Registros órfãos, perda de integridade dos dados, limpeza manual necessária. |
| Atributos | Colunas Não Atômicas | Dificuldade em consultar, incapacidade de indexar partes específicas dos dados. |
| Desempenho | Índices Ausentes em Chaves Estrangeiras | Junções lentas, contenção de bloqueio durante gravações, alto uso de CPU. |
| Design | Normalização profundamente aninhada | Junções excessivas de tabelas para leituras simples, complexidade de consultas. |
| Escalabilidade | Lógica codificada no esquema | Esquema rígido que não consegue se adaptar a novos estados de negócios. |
Cada uma dessas entradas representa um ponto de atrito. Quando um desenvolvedor encontra um erro no esquema, ele frequentemente contorna o problema com lógica de nível de aplicação. Isso empurra regras de negócios para o código-fonte, criando uma separação de responsabilidades difícil de manter.
3. Quantificando a Dívida Técnica 💰
O custo de um mau design raramente é imediato. É uma perda lenta de recursos. Podemos categorizar esses custos em três grandes grupos: Velocidade de Desenvolvimento, Estabilidade Operacional e Custo de Manutenção.
3.1 Velocidade de Desenvolvimento
Quando o esquema é pouco claro, os desenvolvedores gastam tempo em reverter o modelo de dados em vez de construir funcionalidades. Eles precisam:
- Rastrear o fluxo de dados entre múltiplas tabelas para entender um único campo.
- Escrever consultas SQL complexas para compensar relacionamentos ausentes.
- Gerenciar tarefas de limpeza de dados que deveriam ter sido evitadas na fonte.
Isso desacelera a entrega de funcionalidades. Um sprint que deveria levar três dias para ser concluído pode se estender para cinco ou seis devido à depuração de dados. Esse é um custo direto para o tempo e orçamento da organização.
3.2 Estabilidade Operacional
Problemas de banco de dados frequentemente surgem em produção sob carga. Estratégias de indexação ruins ou ausência de restrições podem levar a:
- Contenção de bloqueios:Quando múltiplas transações tentam atualizar as mesmas tabelas mal estruturadas, o sistema entra em paralisação.
- Tempo limite de consulta:Junções não otimizadas fazem com que o banco de dados escaneie milhões de linhas desnecessariamente.
- Corrupção de dados:Sem restrições adequadas, dados inválidos podem se propagar pelo sistema, tornando difícil confiar nos relatórios.
3.3 Custo de Manutenção
A cada ano em que um esquema defeituoso existe, o custo para corrigi-lo aumenta. Isso ocorre devido à acumulação de dependências. Novas funcionalidades são construídas sobre a estrutura antiga e defeituosa. Refatorar torna-se como mover a fundação de uma casa enquanto pessoas vivem dentro dela.
4. O Processo de Refatoração: Complexidade e Risco 🛠️
Uma vez tomada a decisão de refatorar o banco de dados, o processo está cheio de desafios. Não se trata apenas de alterar tabelas. Envolve uma coordenação cuidadosa de migrações, verificações de consistência de dados e tempo mínimo de inatividade.
4.1 A Estratégia de Migração
A refatoração exige scripts de migração. Esses scripts devem ser idempotentes e reversíveis. No entanto, se o esquema foi mal documentado, escrever esses scripts torna-se um jogo de adivinhação. Você deve garantir que:
- Os dados existentes sejam transformados corretamente sem perda.
- Aplicações em execução não travam durante a transição.
- Planos de retorno são viáveis caso algo dê errado.
Em sistemas complexos, isso pode exigir uma estratégia de gravação dupla, em que os novos dados são gravados na nova estrutura enquanto os dados antigos são migrados em segundo plano. Isso duplica temporariamente a complexidade da lógica da aplicação.
4.2 Tempo de inatividade e disponibilidade
Algumas alterações estruturais, como adicionar colunas com valores padrão ou reindexar tabelas grandes, podem bloquear o banco de dados. Para sistemas de alta disponibilidade, isso é inaceitável. O refatoramento frequentemente exige a agendamento de janelas de manutenção, o que afeta a experiência do usuário e a receita.
4.3 O Fator Humano
O refatoramento também é um evento psicológico para a equipe. Se a equipe tiver que lidar com uma constante corrente de erros de dados causados pelo esquema, o moral cai. Eles sentem que estão constantemente lutando contra a infraestrutura em vez de criar valor. Um banco de dados limpo e bem modelado restaura a confiança na plataforma.
5. Prevenção Estratégica: Construindo Modelos Resilientes 🛡️
Embora o refatoramento seja possível, a prevenção é muito mais rentável. Adotar uma abordagem disciplinada na criação de ERDs pode mitigar a maioria dos riscos.
5.1 Design Iterativo
Não espere pelas exigências finais para projetar o esquema. Comece com as entidades e relacionamentos principais que são estáveis. Permita que o modelo evolua. Trate o ERD como um documento vivo que é atualizado junto com as solicitações de recursos.
5.2 Revisão por Pares de Modelos de Dados
Assim como o código é revisado, os esquemas de banco de dados também devem ser revisados. Um par de olhos novos pode identificar:
- Campos redundantes de dados.
- Relacionamentos ausentes entre tabelas.
- Conflitos potenciais de nomeação.
- Violação das regras de normalização.
Esse processo de revisão garante que o modelo esteja alinhado com a intenção do negócio antes que uma única linha de código de migração seja escrita.
5.3 Documentação e Convenções de Nomeação
A consistência é fundamental. Estabeleça convenções rigorosas de nomeação para tabelas e colunas. Evite abreviações que não sejam amplamente compreendidas. Documente a regra de negócios por trás de cada chave estrangeira. Isso garante que qualquer pessoa que se junte à equipe possa entender os dados sem precisar fazer perguntas.
6. Cenários Pós-Mortem: Lições Aprendidas 📝
Vamos analisar cenários hipotéticos em que um mau design de ERD levou a problemas significativos, oferecendo insights sobre o que evitar.
Cenário A: A Crise dos Registros Órfãos
A Situação:Uma equipe projetou um sistema para rastrear pedidos dos usuários e endereços de entrega. Removeram a restrição de chave estrangeira para melhorar o desempenho de gravação, assumindo que a lógica da aplicação lidaria com a validação.
A Falha:Com o tempo, os usuários excluíram suas contas, mas mantiveram os pedidos. Os endereços de entrega tornaram-se órfãos. Quando a equipe tentou gerar um relatório de imposto, a junção falhou porque os dados do usuário tinham desaparecido.
O Custo:A equipe teve que escrever um script para vincular manualmente os dados históricos a uma categoria genérica de usuário “anônimo”. Isso consumiu três dias de tempo de engenharia e exigiu um backup completo do banco de dados e uma restauração para testar com segurança.
Cenário B: A Armadilha da Denormalização
A Situação:Para acelerar o desempenho de leitura, uma equipe copiou dados do perfil do usuário para a tabela de pedidos. Eles acreditavam que isso reduziria as operações de junção.
A Falha:Quando um usuário atualizou seu nome, o aplicativo atualizou a tabela de usuários, mas falhou em atualizar os milhares de registros de pedidos que continham o nome antigo. Relatórios mostraram nomes inconsistentes para o mesmo usuário.
O Custo:A consistência dos dados foi perdida. A equipe teve que decidir entre aceitar a inconsistência ou implementar um sistema complexo de gatilhos para sincronizar os dados. Eles optaram por refatorar o esquema para remover a duplicação, exigindo uma reescrita da lógica de gravação do aplicativo.
Cenário C: O Ponto Cego de Indexação
A Situação:Uma funcionalidade de busca foi criada em uma tabela com milhões de linhas. O desenvolvedor assumiu que a chave primária seria suficiente.
A Falha:À medida que a tabela crescia, as consultas na coluna de busca ficavam cada vez mais lentas. O banco de dados precisava realizar uma varredura completa da tabela.
O Custo:O sistema tornou-se inviável durante os horários de pico. Adicionar um índice posteriormente exigiu uma operação demorada que bloqueou a tabela por horas, causando interrupção do serviço.
7. Protegendo Seu Nível de Dados para o Futuro 🔮
O objetivo de qualquer esforço de modelagem de dados é criar uma base capaz de resistir às mudanças. Embora nenhum esquema seja perfeito para sempre, um bom ERD fornece um caminho claro para a evolução.
- Controle de Versão:Trate suas migrações de esquema como código. Armazene-as em controle de versão para rastrear mudanças ao longo do tempo.
- Testes Automatizados:Inclua validação de esquema na sua pipeline CI/CD. Certifique-se de que as migrações não quebrem consultas existentes.
- Monitoramento:Monitore o desempenho das consultas para identificar índices ausentes ou junções ineficientes precocemente.
- Padrões da Comunidade:Siga práticas recomendadas estabelecidas para a sua tecnologia específica de banco de dados para garantir compatibilidade e desempenho.
Investir tempo na fase de ERD não é um atraso; é uma aceleração. Reduz a fricção do desenvolvimento futuro e garante que os dados permaneçam um ativo confiável, e não uma dívida técnica.
Conclusão: O Custo da Ignorância versus o Valor da Planejamento ⚖️
O custo oculto de ERDs ruins é frequentemente invisível até que seja tarde demais. Ele se manifesta como entrega mais lenta de recursos, ambientes de produção instáveis e equipes de engenharia frustradas. Refatorar um banco de dados é uma operação de alto risco que exige precisão, planejamento e, frequentemente, tempo de inatividade significativo.
Tratando a modelagem de dados como uma tarefa crítica de engenharia, e não como uma tarefa administrativa, as organizações podem evitar os perigos da dívida técnica. Um esquema bem projetado atua como uma proteção, garantindo que o aplicativo permaneça robusto à medida que cresce. O esforço investido na criação de um ERD sólido traz benefícios em cada linha de código escrita depois, em cada consulta executada e em cada usuário atendido.
Não espere pelo pós-mortem para perceber o valor de um bom projeto. Comece a planejar com clareza, rigor e compromisso com a integridade dos dados desde o primeiro dia.

