











Cuando un sistema de software comienza a escalar, la capa de datos a menudo se convierte en el cuello de botella más crítico. Mientras que el código de la aplicación puede reescribirse y las interfaces de front-end rediseñarse, el esquema de la base de datos representa la verdad fundamental de la aplicación. Un diagrama de entidad-relación (ERD) mal construido no es simplemente una molestia visual; es una debilidad estructural que se agrava con el tiempo. Este análisis examina los costos tangibles e intangibles asociados con el modelado deficiente de bases de datos y la compleja realidad de refactorizar estas estructuras más adelante en el ciclo de vida del desarrollo.
Muchos equipos tratan el diseño de esquemas como una tarea preliminar, algo que debe finalizarse antes de que comience la programación real. Sin embargo, a medida que los requisitos cambian y la lógica de negocio evoluciona, la rigidez de un ERD mal planificado se vuelve evidente. El costo de ignorar estos detalles no se mide solo en horas dedicadas a escribir SQL, sino también en la pérdida de velocidad, el aumento del riesgo de interrupciones y la degradación de la confianza del equipo en la infraestructura.
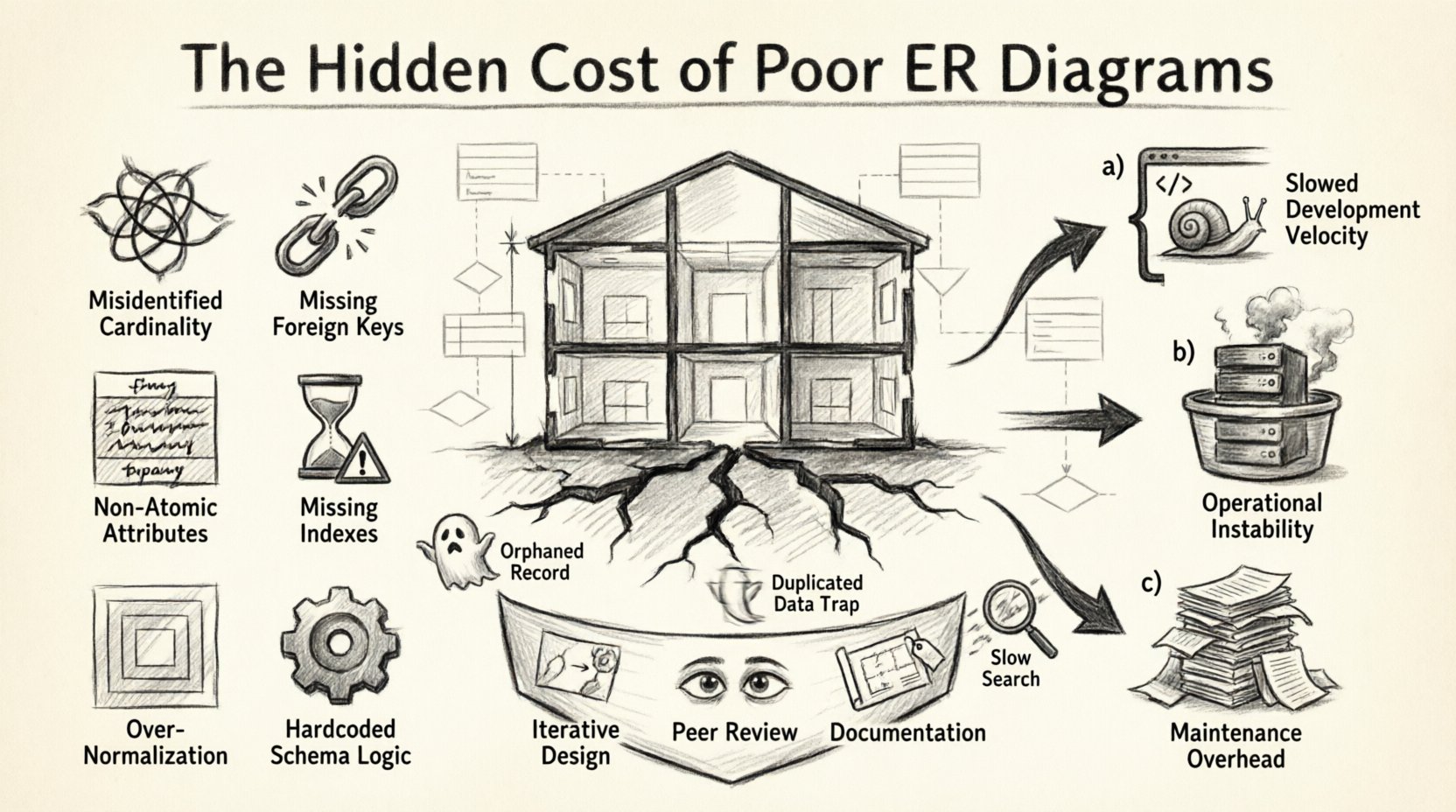
1. La analogía del plano: por qué el esquema importa 🏗️
Piensa en un esquema de base de datos como el plano arquitectónico de un edificio. Si las paredes portantes están colocadas incorrectamente, o si las tuberías de fontanería están mal trazadas, la estructura puede mantenerse inicialmente. Pero con el tiempo aparecen grietas. Añadir funciones adicionales sobre una base débil conduce a un colapso estructural. En software, esto se manifiesta como consultas lentas, inconsistencias de datos y la imposibilidad de añadir nuevas funcionalidades sin romper las existentes.
Un ERD sirve como herramienta de comunicación entre los interesados, desarrolladores y arquitectos de datos. Define entidades, sus atributos y las relaciones entre ellas. Cuando este diagrama es ambiguo o incompleto, conduce a:
- Ambigüedad en la implementación:Los desarrolladores hacen suposiciones sobre la integridad de los datos que podrían no coincidir con las reglas del negocio.
- Problemas de normalización:Los datos están o bien excesivamente fragmentados, lo que requiere uniones excesivas, o excesivamente denormalizados, lo que conduce a anomalías de actualización.
- Fallas en las restricciones:La ausencia de claves foráneas o restricciones de verificación permite que datos inválidos ingresen al sistema.
Estos problemas se acumulan. Un pequeño error en el tipo de relación podría pasar desapercibido durante meses, solo para causar un fallo catastrófico cuando se ejecuta un informe específico o una migración.
2. Anatomía de un esquema defectuoso: errores comunes en el modelado 🔍
Identificar los errores específicos en un ERD es el primer paso para comprender los costos involucrados. A continuación se presenta un desglose de los errores comunes en el modelado que generan una deuda técnica significativa.
| Categoría | Error común | Impacto en el sistema |
|---|---|---|
| Relaciones | Cardinalidad mal identificada (1:1 frente a 1:N) | Almacenamiento ineficiente, uniones complejas, duplicación de datos. |
| Restricciones | Faltan claves foráneas | Registros huérfanos, pérdida de integridad de datos, limpieza manual requerida. |
| Atributos | Columnas no atómicas | Dificultad para consultar, imposibilidad de indexar partes específicas de los datos. |
| Rendimiento | Faltan índices en claves foráneas | Uniones lentas, contención de bloqueos durante escrituras, alto uso de CPU. |
| Diseño | Normalización profundamente anidada | Unión excesiva de tablas para lecturas simples, complejidad de consultas. |
| Escalabilidad | Lógica codificada en el esquema | Esquema inflexible que no puede adaptarse a nuevos estados del negocio. |
Cada uno de estos elementos representa un punto de fricción. Cuando un desarrollador encuentra un error en el esquema, a menudo lo evita con lógica a nivel de aplicación. Esto traslada las reglas de negocio al código, creando una separación de responsabilidades que es difícil de mantener.
3. Cuantificación de la deuda técnica 💰
El costo del mal diseño rara vez es inmediato. Es una pérdida lenta de recursos. Podemos categorizar estos costos en tres grandes grupos: Velocidad de desarrollo, Estabilidad operativa y Sobrecarga de mantenimiento.
3.1 Velocidad de desarrollo
Cuando el esquema es poco claro, los desarrolladores dedican tiempo a reconstruir el modelo de datos en lugar de crear funcionalidades. Deben:
- Rastrear el flujo de datos a través de múltiples tablas para entender un solo campo.
- Escribir consultas SQL complejas para compensar las relaciones faltantes.
- Manejar tareas de limpieza de datos que deberían haberse evitado en la fuente.
Esto ralentiza la entrega de funcionalidades. Un sprint que debería completarse en tres días puede extenderse a cinco o seis debido a la depuración de datos. Este es un costo directo para el tiempo y el presupuesto de la organización.
3.2 Estabilidad operativa
Los problemas de base de datos surgen con frecuencia en producción bajo carga. Estrategias de indexación deficientes o la falta de restricciones pueden provocar:
- Contención de bloqueos:Cuando múltiples transacciones intentan actualizar las mismas tablas mal estructuradas, el sistema se detiene por completo.
- Tiempo de espera de consultas:Las uniones no optimizadas hacen que la base de datos escanee millones de filas innecesariamente.
- Corrupción de datos:Sin restricciones adecuadas, los datos inválidos pueden propagarse por el sistema, dificultando la confianza en los informes.
3.3 Sobrecarga de mantenimiento
Cada año que un esquema defectuoso existe, el costo para corregirlo aumenta. Esto se debe a la acumulación de dependencias. Las nuevas funcionalidades se construyen sobre la estructura antigua y defectuosa. Refactorizar se convierte en algo similar a mover la fundación de una casa mientras las personas viven dentro de ella.
4. El proceso de refactorización: complejidad y riesgo 🛠️
Una vez que se toma la decisión de refactorizar la base de datos, el proceso está lleno de desafíos. No se trata simplemente de modificar tablas. Implica una cuidadosa coordinación de migraciones, verificaciones de consistencia de datos y tiempo de inactividad mínimo.
4.1 La estrategia de migración
La refactorización requiere scripts de migración. Estos scripts deben ser idempotentes y reversibles. Sin embargo, si el esquema estaba mal documentado, escribir estos scripts se convierte en un juego de adivinanzas. Debe asegurarse de que:
- Los datos existentes se transforman correctamente sin pérdida.
- Las aplicaciones en ejecución no se bloquean durante la transición.
- Los planes de reversión son viables si algo sale mal.
En sistemas complejos, esto podría requerir una estrategia de escritura dual en la que los nuevos datos se escriban en la nueva estructura mientras los datos antiguos se migran en segundo plano. Esto duplica temporalmente la complejidad de la lógica de la aplicación.
4.2 Tiempo de inactividad y disponibilidad
Algunos cambios estructurales, como agregar columnas con valores predeterminados o volver a indexar tablas grandes, pueden bloquear la base de datos. Para sistemas de alta disponibilidad, esto es inaceptable. El refactoring a menudo requiere programar ventanas de mantenimiento, lo que afecta la experiencia del usuario y los ingresos.
4.3 El factor humano
El refactoring también es un evento psicológico para el equipo. Si el equipo debe lidiar con una constante corriente de errores de datos causados por el esquema, la moral baja. Sienten que están luchando constantemente contra la infraestructura en lugar de crear valor. Una base de datos limpia y bien modelada restaura la confianza en la plataforma.
5. Prevención estratégica: Construcción de modelos resilientes 🛡️
Aunque el refactoring es posible, la prevención es mucho más rentable. Adoptar un enfoque disciplinado en la creación de ERD puede mitigar la mayoría de los riesgos.
5.1 Diseño iterativo
No espere a tener los requisitos finales para diseñar el esquema. Comience con las entidades y relaciones fundamentales que son estables. Permita que el modelo evolucione. Trate el ERD como un documento vivo que se actualiza junto con las solicitudes de funcionalidades.
5.2 Revisión entre pares de modelos de datos
Al igual que el código se revisa, los esquemas de base de datos también deben revisarse. Una mirada fresca puede detectar:
- Campos de datos redundantes.
- Relaciones faltantes entre tablas.
- Posibles conflictos de nombres.
- Violación de las reglas de normalización.
Este proceso de revisión garantiza que el modelo se alinee con la intención del negocio antes de que se escriba una sola línea de código de migración.
5.3 Documentación y convenciones de nomenclatura
La consistencia es clave. Establezca convenciones estrictas de nomenclatura para tablas y columnas. Evite abreviaturas que no sean ampliamente comprendidas. Documente la regla de negocio detrás de cada clave foránea. Esto garantiza que cualquiera que se incorpore al equipo pueda entender los datos sin hacer preguntas.
6. Escenarios de casos post-mortem: Lecciones aprendidas 📝
Examinemos escenarios hipotéticos en los que un mal diseño de ERD condujo a problemas importantes, ofreciendo ideas sobre qué evitar.
Escenario A: La crisis de registros huérfanos
La situación:Un equipo diseñó un sistema para rastrear pedidos de usuarios y direcciones de envío. Eliminaron la restricción de clave foránea para mejorar el rendimiento de escritura, asumiendo que la lógica de la aplicación manejaría la validación.
El fallo:Con el tiempo, los usuarios eliminaron sus cuentas pero conservaron sus pedidos. Las direcciones de envío se convirtieron en huérfanas. Cuando el equipo intentó generar un informe de impuestos, la unión falló porque los datos del usuario habían desaparecido.
El costo:El equipo tuvo que escribir un script para vincular manualmente los datos históricos a una categoría genérica de usuario «anónimo». Esto tomó tres días de tiempo de ingeniería y requirió una copia de seguridad completa y restauración de la base de datos para probarlo de forma segura.
Escenario B: La trampa de la desnormalización
La situación:Para acelerar el rendimiento de lectura, un equipo copió los datos del perfil de usuario en la tabla de pedidos. Creían que esto reduciría las operaciones de unión.
El fallo:Cuando un usuario actualizó su nombre, la aplicación actualizó la tabla de usuarios pero no actualizó los miles de registros de pedidos que contenían el nombre antiguo. Los informes mostraron nombres inconsistentes para el mismo usuario.
El costo:Se perdió la consistencia de los datos. El equipo tuvo que decidir si aceptar la inconsistencia o implementar un sistema complejo de desencadenadores para sincronizar los datos. Optaron por refactorizar el esquema para eliminar la duplicación, lo que requirió volver a escribir la lógica de escritura de la aplicación.
Escenario C: El punto ciego de los índices
La situación:Se creó una función de búsqueda en una tabla con millones de filas. El desarrollador asumió que la clave principal sería suficiente.
El fallo:A medida que la tabla crecía, las consultas en la columna de búsqueda se ralentizaron hasta un punto insoportable. La base de datos tuvo que realizar una escaneo completo de la tabla.
El costo:El sistema se volvió inutilizable durante las horas pico. Añadir un índice más tarde requirió una operación de larga duración que bloqueó la tabla durante horas, causando interrupciones del servicio.
7. Proteger tu capa de datos para el futuro 🔮
El objetivo de cualquier esfuerzo de modelado de datos es crear una base que pueda resistir el cambio. Aunque ningún esquema es perfecto para siempre, un buen diagrama ER proporciona una ruta clara para la evolución.
- Control de versiones:Trata tus migraciones de esquema como código. Almacénalas en control de versiones para rastrear los cambios con el tiempo.
- Pruebas automatizadas:Incluye la validación de esquema en tu pipeline de CI/CD. Asegúrate de que las migraciones no rompan consultas existentes.
- Monitoreo:Monitorea el rendimiento de las consultas para identificar índices faltantes o uniones ineficientes desde temprano.
- Normas de la comunidad:Sigue las prácticas recomendadas establecidas para tu tecnología de base de datos específica para garantizar compatibilidad y rendimiento.
Invertir tiempo en la fase de ERD no es una demora; es una aceleración. Reduce la fricción del desarrollo futuro y asegura que los datos sigan siendo un activo confiable en lugar de una carga.
Conclusión: El costo de la ignorancia frente al valor de la planificación ⚖️
El costo oculto de los diagramas ER deficientes a menudo no es visible hasta que ya es demasiado tarde. Se manifiesta como una entrega más lenta de funciones, entornos de producción inestables y equipos de ingeniería frustrados. Refactorizar una base de datos es una operación de alto riesgo que requiere precisión, planificación y a menudo, tiempos de inactividad significativos.
Al tratar el modelado de datos como una tarea de ingeniería crítica, y no como una tarea administrativa, las organizaciones pueden evitar los peligros de la deuda técnica. Un esquema bien diseñado actúa como una protección, asegurando que la aplicación permanezca robusta mientras crece. El esfuerzo invertido en diseñar un ERD sólido genera beneficios en cada línea de código escrita después, cada consulta ejecutada y cada usuario atendido.
No esperes al informe posterior para darte cuenta del valor de un buen plano. Comienza a planificar con claridad, rigor y un compromiso con la integridad de los datos desde el primer día.

