











ソフトウェアシステムがスケーリングを始めると、データ層はしばしば最も重要なボトルネックとなる。アプリケーションコードは再書き直し可能で、フロントエンドインターフェースも再設計可能だが、データベーススキーマはアプリケーションの基盤となる真実を表している。適切に構築されていないエンティティ関係図(ERD)は、単なる視覚的な不都合ではなく、時間とともに悪化する構造上の弱点である。この分析では、不適切なデータベースモデリングに関連する実質的かつ非実質的なコスト、および開発ライフサイクルの後半にこれらの構造をリファクタリングするという複雑な現実を検証する。
多くのチームはスキーマ設計を初期作業と捉え、本格的なコーディングが始まる前に完了させるものと考える。しかし、要件が変化し、ビジネスロジックが進化する中で、計画が不十分なERDの硬直性が明らかになる。これらの詳細を無視するコストは、SQLを書くために費やす時間だけではなく、開発速度の低下、ダウンタイムリスクの増加、インフラ構造に対するチームの信頼の低下にも表れる。
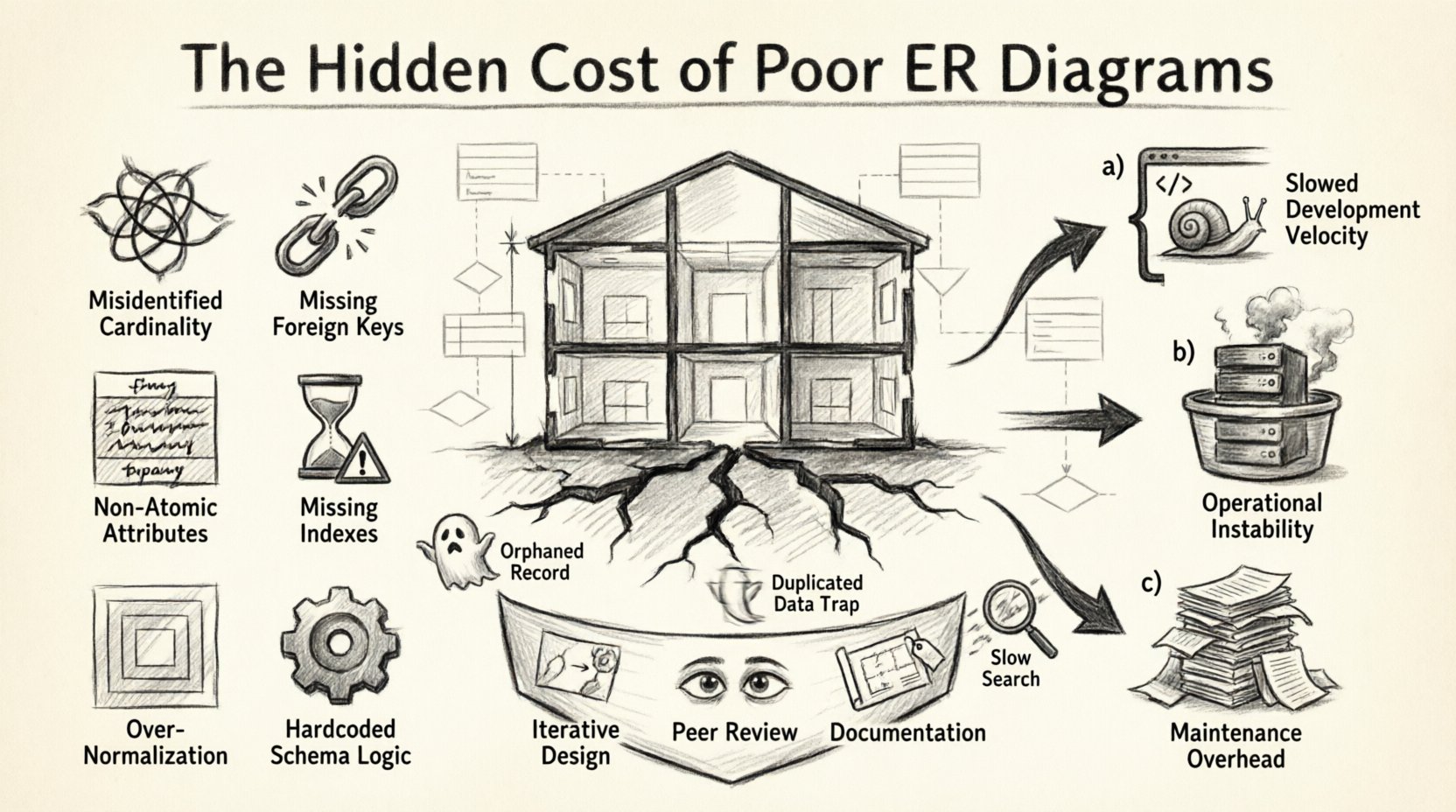
1. ブループリントのたとえ:なぜスキーマが重要なのか 🏗️
データベーススキーマを建物の建築図面にたとえるとよい。荷重壁が誤って配置されたり、配管が非効率に配線されたりすると、構造は一時的には立つかもしれない。しかし時間とともに亀裂が生じる。弱い基盤の上に追加機能を積み重ねると、構造的崩壊が起こる。ソフトウェアにおいては、遅いクエリ、データの不整合、既存の機能を壊さずに新しい機能を追加できないといった問題として現れる。
ERDはステークホルダー、開発者、データアーキテクトの間のコミュニケーションツールとして機能する。エンティティ、その属性、およびそれらの関係性を定義する。この図が曖昧または不完全な場合、以下の問題が生じる。
- 実装の曖昧さ:開発者はデータ整合性についての仮定を行うが、それはビジネスルールと一致しない可能性がある。
- 正規化の問題:データが過度に断片化され、過剰な結合が必要になるか、逆に過度に非正規化され、更新異常が生じる。
- 制約の穴:外部キーまたはチェック制約が欠如しているため、無効なデータがシステムに流入する。
これらの問題は蓄積される。関係性のタイプに関する小さな誤りは数か月間見過ごされることがあり、特定のレポートやマイグレーション実行時に深刻な障害を引き起こす。
2. 不適切なスキーマの構造:一般的なモデリングの誤り 🔍
ERD内の具体的な誤りを特定することは、関連するコストを理解する第一歩である。以下は、大きな技術的負債を生む一般的なモデリングの落とし穴の概要である。
| カテゴリ | 一般的な誤り | システムへの影響 |
|---|---|---|
| 関係性 | 基数の誤認(1:1 と 1:N の混同) | 非効率なストレージ、複雑な結合、データの重複。 |
| 制約 | 外部キーの欠落 | 孤立レコード、データ整合性の喪失、手動でのクリーンアップが必要。 |
| 属性 | 原子的でないカラム | クエリの困難、データの特定部分へのインデックス化が不可能。 |
| パフォーマンス | 外部キーへのインデックスの欠落 | 結合の遅延、書き込み時のロック競合、CPU使用率の上昇。 |
| 設計 | 深くネストされた正規化 | 単純な読み取りのために過剰なテーブル結合が行われ、クエリの複雑さが増す。 |
| スケーラビリティ | スキーマ内のハードコードされたロジック | 新しいビジネス状態に適応できない柔軟性のないスキーマ。 |
これらの各項目は、摩擦のポイントを表しています。開発者がスキーマ内でエラーに遭遇すると、しばしばアプリケーションレベルのロジックで回避策を講じます。これによりビジネスルールがコードベースに押し込まれ、維持が難しいコンセプトの分離が生じます。
3. 技術的負債の測定 💰
悪い設計のコストはほとんど即時には現れません。それはリソースへのゆっくりとした消耗です。これらのコストを、開発速度、運用安定性、保守負荷の3つの主要なカテゴリに分類できます。
3.1 開発速度
スキーマが明確でない場合、開発者は機能の構築ではなく、データモデルの逆工程に時間を費やすことになります。彼らは次のような作業をしなければなりません:
- 単一のフィールドを理解するために、複数のテーブルにわたるデータの流れを追跡する。
- 欠落している関係を補うために、複雑なSQLクエリを書く。
- 元の場所で防止すべきデータのクリーニング作業を処理する。
これにより機能の提供が遅れます。データデバッグのため、3日で終わるスプリントが5日や6日まで延びることもあります。これは組織の時間と予算に対する直接的なコストです。
3.2 運用安定性
データベースの問題は、負荷がかかる本番環境でしばしば顕在化します。悪いインデックス戦略や制約の欠如は、次のような問題を引き起こす可能性があります:
- ロック競合:複数のトランザクションが同じ poorly structured(構造が悪い)テーブルを更新しようとする場合、システムは完全に停止します。
- クエリタイムアウト:最適化されていない結合により、データベースが不要に数百万行をスキャンすることになります。
- データ破損:適切な制約がなければ、無効なデータがシステム内を伝播し、レポートの信頼性が損なわれます。
3.3 保守負荷
flawed(欠陥のある)スキーマが存在する毎年、修正にかかるコストは増加します。これは依存関係の蓄積によるものです。新しい機能は、古い欠陥のある構造の上に構築されます。リファクタリングは、人々が家の中に住んでいる間にその家の基礎を移動するようなものになります。
4. リファクタリングプロセス:複雑性とリスク 🛠️
データベースのリファクタリングを決定した後、そのプロセスは多くの課題に満ちています。単にテーブルを変更するだけの話ではありません。マイグレーション、データ整合性の確認、最小限のダウンタイムを慎重に調整する必要があります。
4.1 マイグレーション戦略
リファクタリングにはマイグレーションスクリプトが必要です。これらのスクリプトは、再実行可能(idempotent)かつ元に戻せる(reversible)ものでなければなりません。しかし、スキーマが適切にドキュメント化されていなければ、これらのスクリプトを書くことは推測のゲームになります。次を確実にしなければなりません:
- 既存のデータが損失なく正しく変換されることを確認する。
- 実行中のアプリケーションは、移行中にクラッシュしない。
- 何か問題が起きた場合、ロールバック計画は実行可能である。
複雑なシステムでは、新しい構造に新しいデータを書き込みながら、古いデータをバックグラウンドで移行する二重書き込み戦略を採用する必要がある場合がある。これは一時的にアプリケーションロジックの複雑性を倍増させる。
4.2 一時停止と可用性
デフォルト付きの列を追加したり、大きなテーブルの再インデックス化など、一部の構造的変更はデータベースをロックする可能性がある。高可用性システムでは、これを受け入れることはできない。リファクタリングはしばしばメンテナンスウィンドウをスケジューリングする必要があり、これはユーザー体験と収益に影響を与える。
4.3 人的要因
リファクタリングはチームにとって心理的な出来事でもある。スキーマによって引き起こされる継続的なデータバグに対処しなければならない場合、士気は低下する。彼らはインフラと戦っていると感じ、価値を創造しているわけではないと感じる。明確で適切にモデル化されたデータベースは、プラットフォームに対する信頼を回復させる。
5. 戦略的予防:レジリエントなモデルの構築 🛡️
リファクタリングは可能だが、予防の方がはるかにコスト効率が良い。ERD作成に厳格なアプローチを取ることで、大多数のリスクを軽減できる。
5.1 反復的設計
最終要件を待ってからスキーマを設計しないでください。安定したコアエンティティと関係性から始めましょう。モデルの進化を許可してください。ERDを機能要件と並行して更新される動的な文書として扱いましょう。
5.2 データモデルの同僚レビュー
コードがレビューされるように、データベーススキーマもレビューされるべきである。新しい目で見ることで、次の点が見つかる可能性がある:
- 重複するデータフィールド。
- テーブル間の欠落した関係性。
- 潜在的な名前衝突。
- 正規化ルールの違反。
このレビュー過程により、移行コードの1行も書かれる前に、モデルがビジネスの意図と一致していることが保証される。
5.3 ドキュメント化と命名規則
一貫性が鍵である。テーブルとカラムに対して厳格な命名規則を設ける。広く理解されていない略語を避ける。すべての外部キーの背後にあるビジネスルールを文書化する。これにより、チームに新しく加わる誰もが、質問せずにデータを理解できるようになる。
6. ポストモーテム事例:学びの整理 📝
悪いERD設計が重大な問題を引き起こした仮想的なシナリオを検討し、避けなければならない点を明らかにする。
シナリオA:孤立したレコードの危機
状況:あるチームは、ユーザーの注文と配送先を追跡するシステムを設計した。書き込みパフォーマンスを向上させるために、外部キー制約を削除し、アプリケーションロジックが検証を処理すると仮定した。
失敗:時間の経過とともに、ユーザーはアカウントを削除したが注文は保持した。配送先が孤立した状態になった。チームが税務レポートを生成しようとすると、ユーザーのデータがなくなったため、結合が失敗した。
コスト:チームは、履歴データを汎用的な「匿名」ユーザー用のバケットに手動でリンクするスクリプトを書かなければならなかった。これにはエンジニアリング作業で3日間を要し、安全にテストするためにはデータベースの完全なダンプと復元が必要だった。
シナリオB:非正規化の罠
状況:読み取りパフォーマンスを向上させるために、チームはユーザーのプロファイルデータを注文テーブルにコピーした。この操作によりジョイン処理が減ると考えていた。
失敗の原因:ユーザーが名前を更新した際、アプリケーションはユーザーテーブルは更新したが、古い名前を含む数千件の注文レコードの更新に失敗した。レポートでは、同じユーザーに対して名前が一貫性のない状態が確認された。
コスト:データの一貫性が失われた。チームは一貫性のない状態を受け入れるか、複雑なトリガー機構を導入してデータを同期するかの選択を迫られた。彼らは重複を削除するためにスキーマを再設計し、アプリケーションの書き込みロジックを再実装することを選択した。
シナリオC:インデックスの見落とし
状況:数百万行のデータを持つテーブル上で検索機能が構築された。開発者はプライマリキーだけで十分だと考えていた。
失敗の原因:テーブルが拡大するにつれて、検索カラムに対するクエリが極端に遅くなった。データベースはフルテーブルスキャンを実行しなければならなくなった。
コスト:ピーク時間帯にシステムが使用不能になった。後にインデックスを追加するには長時間実行される操作が必要となり、テーブルが数時間ロックされたため、サービスの中断が発生した。
7. データレイヤーの将来対応性確保 🔮
いかなるデータモデリング作業の目的も、変化に耐えうる基盤を構築することにある。どんなスキーマも永遠に完璧であるわけではないが、良いERDは進化の明確な道筋を提供する。
- バージョン管理:スキーマのマイグレーションをコードとして扱う。変更履歴を追跡できるように、バージョン管理に保存する。
- 自動テスト:CI/CDパイプラインにスキーマ検証を組み込む。マイグレーションが既存のクエリを破壊しないことを確認する。
- モニタリング:クエリのパフォーマンスを監視し、欠落しているインデックスや非効率な結合を早期に特定する。
- コミュニティの標準:特定のデータベース技術に適した確立されたベストプラクティスに従い、互換性とパフォーマンスを確保する。
ERDフェーズに時間を投資することは遅延ではなく、加速である。将来の開発における摩擦を軽減し、データが負債ではなく信頼できる資産のままであることを保証する。
結論:無知のコストと計画の価値の対比 ⚖️
悪いER図の隠れたコストは、しばしば遅すぎると気づくまで見えない。それは機能の遅延配信、不安定な本番環境、そして苛立つエンジニアリングチームとして現れる。データベースの再設計は、正確さ、計画、そしてしばしば大きなダウンタイムを要する高リスクな作業である。
データモデリングを単なる事務作業ではなく、重要なエンジニアリングタスクとして扱うことで、組織は技術的負債の罠を回避できる。良好に設計されたスキーマは守りとして機能し、アプリケーションが成長しても堅牢な状態を保つ。しっかりとしたERDを設計するための努力は、その後に書かれるすべてのコード、実行されるすべてのクエリ、すべてのユーザーに対して利益をもたらす。
良い設計図の価値に気付くのは、事後分析の後では遅い。最初から明確さ、厳密さ、そしてデータ整合性へのコミットメントを持って計画を始めるべきだ。

