











Wenn ein Software-System zu skalieren beginnt, wird die Datenebene oft zur kritischsten Engstelle. Während Anwendungscode neu geschrieben und Frontend-Oberflächen neu gestaltet werden können, stellt das Datenbank-Schema die grundlegende Wahrheit der Anwendung dar. Ein schlecht konstruiertes Entity-Relationship-Diagramm (ERD) ist nicht nur eine visuelle Unannehmlichkeit, sondern eine strukturelle Schwäche, die sich im Laufe der Zeit verstärkt. Diese Analyse untersucht die greifbaren und ungreifbaren Kosten, die mit fehlerhafter Datenbankmodellierung verbunden sind, sowie die komplexe Realität der Refaktorisierung dieser Strukturen später im Entwicklungszyklus.
Viele Teams betrachten die Schema-Design-Aufgabe als vorläufige Aufgabe, die vor Beginn der eigentlichen Programmierung abgeschlossen werden soll. Doch wenn sich Anforderungen ändern und die Geschäftslogik sich weiterentwickelt, wird die Starrheit eines schlecht geplanten ERD offensichtlich. Die Kosten, die durch Ignorieren dieser Details entstehen, werden nicht nur anhand der Stunden gemessen, die für SQL-Code aufgewendet werden, sondern auch anhand verlorener Geschwindigkeit, erhöhtem Risiko von Ausfällen und einem Abbau des Vertrauens der Teams in die Infrastruktur.
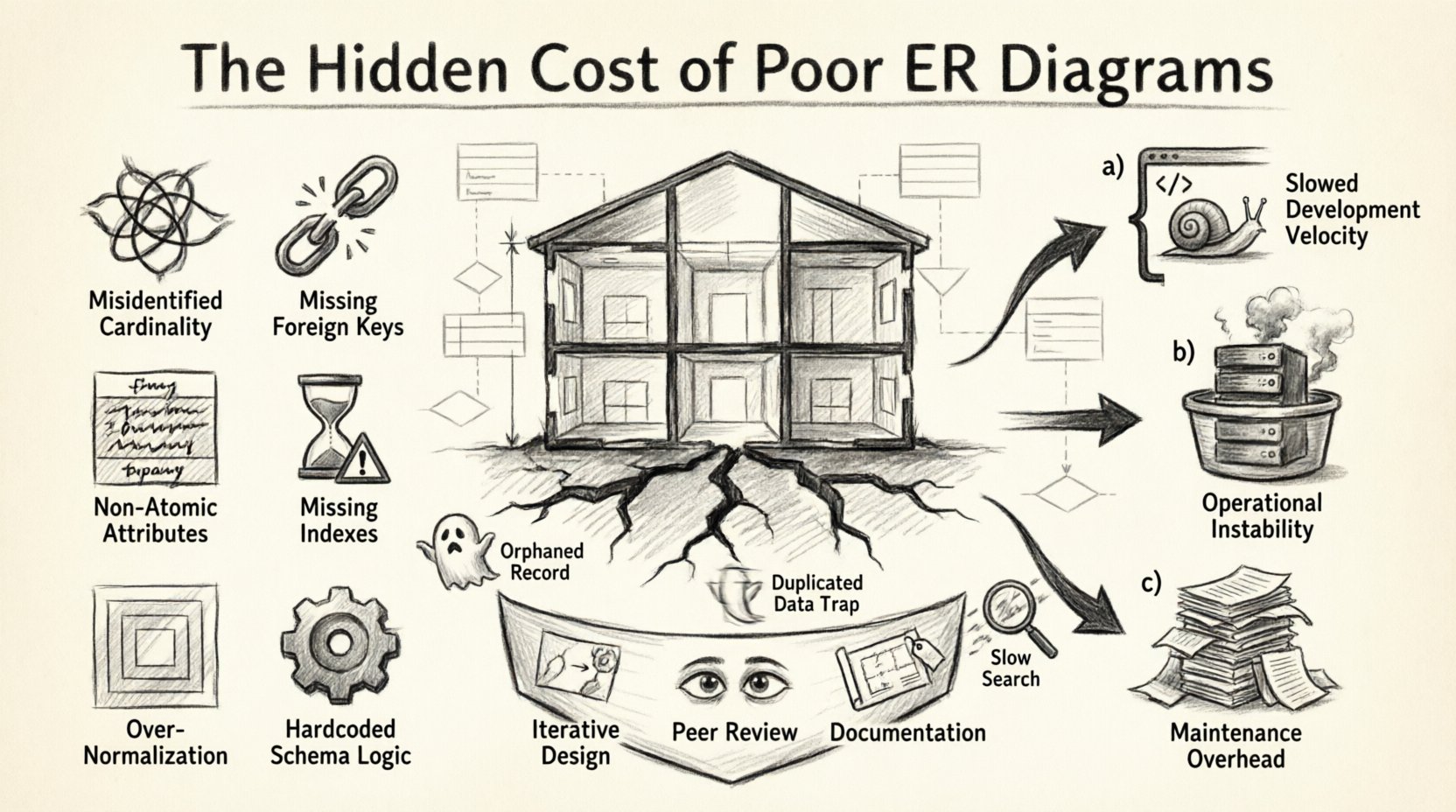
1. Die Bauplan-Analogie: Warum das Schema wichtig ist 🏗️
Stellen Sie sich ein Datenbankschema wie einen architektonischen Bauplan für ein Gebäude vor. Wenn die Tragwände falsch platziert sind oder die Rohrleitungen ineffizient verlegt sind, kann die Struktur zunächst stehen bleiben. Doch im Laufe der Zeit treten Risse auf. Wenn man zusätzliche Funktionen auf eine schwache Grundlage aufbaut, führt dies zu einem strukturellen Zusammenbruch. In der Software zeigt sich dies in langsamen Abfragen, Dateninkonsistenzen und der Unfähigkeit, neue Funktionen hinzuzufügen, ohne bestehende zu beschädigen.
Ein ERD dient als Kommunikationsinstrument zwischen Stakeholdern, Entwicklern und Datenarchitekten. Er definiert Entitäten, deren Attribute und die Beziehungen zwischen ihnen. Wenn dieses Diagramm mehrdeutig oder unvollständig ist, führt dies zu:
- Implementierungsambiguität:Entwickler machen Annahmen über die Datenintegrität, die möglicherweise nicht mit den Geschäftsregeln übereinstimmen.
- Normalisierungsprobleme:Daten sind entweder übermäßig fragmentiert und erfordern übermäßige Joins, oder übermäßig denormalisiert, was zu Aktualisierungsanomalien führt.
- Lücken bei Einschränkungen:Fehlende Fremdschlüssel oder Prüfbedingungen ermöglichen es ungültigen Daten, in das System einzutreten.
Diese Probleme häufen sich. Ein kleiner Fehler in einem Beziehungstyp kann monatelang unbemerkt bleiben, bis er bei der Ausführung eines bestimmten Berichts oder einer Migration zu einem katastrophalen Ausfall führt.
2. Die Anatomie eines fehlerhaften Schemas: Häufige Modellierungsfehler 🔍
Die Identifizierung der spezifischen Fehler in einem ERD ist der erste Schritt, um die damit verbundenen Kosten zu verstehen. Unten finden Sie eine Aufschlüsselung häufiger Modellierungsfallen, die zu erheblichem technischem Schuldenhaufen führen.
| Kategorie | Häufiger Fehler | Auswirkung auf das System |
|---|---|---|
| Beziehungen | Falsch identifizierte Kardinalität (1:1 vs. 1:N) | Ineffiziente Speicherung, komplexe Joins, Daten-Duplikation. |
| Einschränkungen | Fehlende Fremdschlüssel | Verwaiste Datensätze, Verlust der Datenintegrität, manuelle Bereinigung erforderlich. |
| Attribute | Nicht-atomare Spalten | Schwierigkeiten beim Abfragen, Unfähigkeit, bestimmte Teile der Daten zu indizieren. |
| Leistung | Fehlende Indizes auf Fremdschlüsseln | Langsame Joins, Sperrkonflikte bei Schreibvorgängen, hoher CPU-Verbrauch. |
| Design | Tief verschachtelte Normalisierung | Übermäßige Tabellenverknüpfungen für einfache Lesevorgänge, Abfragekomplexität. |
| Skalierbarkeit | Hartkodierter Logik im Schema | Unflexibles Schema, das sich nicht an neue Geschäftszustände anpassen kann. |
Jeder dieser Einträge stellt einen Reibungspunkt dar. Wenn ein Entwickler einen Fehler im Schema trifft, arbeitet er oft mit Logik auf Anwendungsebene darum herum. Dadurch gelangen Geschäftsregeln in den Codebase, was eine Trennung der Verantwortlichkeiten schafft, die schwer zu pflegen ist.
3. Quantifizierung der technischen Schuld 💰
Die Kosten schlechten Designs sind selten sofort spürbar. Es ist ein langsamer Ressourcenverbrauch. Wir können diese Kosten in drei Hauptkategorien einteilen: Entwicklungs-Geschwindigkeit, Betriebssicherheit und Wartungsaufwand.
3.1 Entwicklungs-Geschwindigkeit
Wenn das Schema unklar ist, verbringen Entwickler Zeit damit, das Datenmodell rückwärts zu analysieren, anstatt Funktionen zu entwickeln. Sie müssen:
- Den Datenfluss über mehrere Tabellen verfolgen, um ein einzelnes Feld zu verstehen.
- Komplexe SQL-Abfragen schreiben, um fehlende Beziehungen auszugleichen.
- Datenbereinigungsaufgaben bearbeiten, die bereits an der Quelle verhindert werden sollten.
Dies verlangsamt die Funktionslieferung. Ein Sprint, der drei Tage dauern sollte, kann aufgrund von Daten-Debugging auf fünf oder sechs Tage anwachsen. Dies ist eine direkte Kostenbelastung für die Zeit und das Budget der Organisation.
3.2 Betriebssicherheit
Datenbankprobleme treten oft in der Produktion unter Last auf. Schlechte Indexstrategien oder fehlende Einschränkungen können zu folgendem führen:
- Sperrkonflikte:Wenn mehrere Transaktionen versuchen, die gleichen schlecht strukturierten Tabellen zu aktualisieren, kommt das System zum Stillstand.
- Abfragetimeouts:Unoptimierte Verknüpfungen veranlassen die Datenbank, Millionen von Zeilen unnötigerweise zu scannen.
- Datenkorruption:Ohne angemessene Einschränkungen kann ungültige Daten durch das System propagieren, was es schwierig macht, Berichten zu vertrauen.
3.3 Wartungsaufwand
Jedes Jahr, in dem ein fehlerhaftes Schema existiert, steigen die Kosten, es zu beheben. Dies liegt an der Ansammlung von Abhängigkeiten. Neue Funktionen werden auf der alten, fehlerhaften Struktur aufgebaut. Refactoring wird zu einem wie das Verschieben des Fundaments eines Hauses, während Menschen darin leben.
4. Der Refactoring-Prozess: Komplexität und Risiko 🛠️
Sobald die Entscheidung getroffen ist, die Datenbank zu refaktorisieren, ist der Prozess voller Herausforderungen. Es geht nicht einfach darum, Tabellen zu verändern. Es erfordert eine sorgfältige Abstimmung von Migrationen, Datenkonsistenzprüfungen und minimalem Ausfall.
4.1 Die Migrationsstrategie
Refactoring erfordert Migrations-Skripte. Diese Skripte müssen idempotent und rückgängig machbar sein. Wenn das Schema jedoch schlecht dokumentiert ist, wird das Schreiben dieser Skripte zu einem Ratespiel. Sie müssen sicherstellen, dass:
- Bestehende Daten werden korrekt ohne Verlust transformiert.
- Laufende Anwendungen stürzen während des Übergangs nicht ab.
- Rückgängigmachungspläne sind machbar, falls etwas schief läuft.
In komplexen Systemen könnte dies eine Doppel-Schreibstrategie erfordern, bei der neue Daten in die neue Struktur geschrieben werden, während alte Daten im Hintergrund migriert werden. Dies verdoppelt die Komplexität der Anwendungslogik vorübergehend.
4.2 Ausfallzeiten und Verfügbarkeit
Einige strukturelle Änderungen, wie das Hinzufügen von Spalten mit Standardwerten oder das Neuindizieren großer Tabellen, können die Datenbank sperren. Für Hochverfügbarkeitssysteme ist dies inakzeptabel. Refactoring erfordert oft die Planung von Wartungsfenstern, was die Benutzererfahrung und den Umsatz beeinträchtigt.
4.3 Der menschliche Faktor
Refactoring ist auch ein psychologisches Ereignis für das Team. Wenn das Team ständig mit einer Flut von Datenfehlern konfrontiert ist, die durch das Schema verursacht werden, sinkt die Motivation. Sie fühlen sich ständig mit der Infrastruktur im Kampf, anstatt Wert zu schaffen. Eine saubere, gut modellierte Datenbank stellt das Vertrauen in die Plattform wieder her.
5. Strategische Prävention: Aufbau widerstandsfähiger Modelle 🛡️
Während Refactoring möglich ist, ist Prävention weitaus kosteneffektiver. Die Einführung einer disziplinierten Herangehensweise an die ERD-Erstellung kann die meisten Risiken mindern.
5.1 Iteratives Design
Warten Sie nicht auf die endgültigen Anforderungen, um das Schema zu entwerfen. Beginnen Sie mit den zentralen Entitäten und Beziehungen, die stabil sind. Erlauben Sie dem Modell, sich weiterzuentwickeln. Behandeln Sie das ERD als lebendiges Dokument, das gemeinsam mit Feature-Anfragen aktualisiert wird.
5.2 Peer-Review von Datenmodellen
Genau wie Code wird überprüft, sollten auch Datenbankschemata überprüft werden. Ein frischer Blick kann erkennen:
- Redundante Datenfelder.
- Fehlende Beziehungen zwischen Tabellen.
- Mögliche Namenskonflikte.
- Verletzung der Normalisierungsregeln.
Dieser Überprüfungsprozess stellt sicher, dass das Modell mit dem Geschäftsziel übereinstimmt, bevor eine einzige Zeile Migrationcode geschrieben wird.
5.3 Dokumentation und Namenskonventionen
Konsistenz ist entscheidend. Legen Sie strenge Namenskonventionen für Tabellen und Spalten fest. Vermeiden Sie Abkürzungen, die nicht allgemein verständlich sind. Dokumentieren Sie die Geschäftsregel hinter jedem Fremdschlüssel. Dadurch kann jeder, der dem Team beitritt, die Daten verstehen, ohne Fragen stellen zu müssen.
6. Post-Mortem-Fallstudien: Gelernte Lehren 📝
Betrachten wir hypothetische Szenarien, bei denen eine schlechte ERD-Design zu erheblichen Problemen führte, um Einblicke zu gewinnen, was zu vermeiden ist.
Szenario A: Die Krise der verwaisten Datensätze
Die Situation:Ein Team entwickelte ein System zur Verfolgung von Benutzerbestellungen und Versandadressen. Sie entfernten die Fremdschlüsselbeschränkung, um die Schreibleistung zu verbessern, und gingen davon aus, dass die Anwendungslogik die Validierung übernehmen würde.
Der Ausfall:Im Laufe der Zeit löschten Benutzer ihre Konten, behielten aber ihre Bestellungen. Die Versandadressen wurden verwaist. Als das Team versuchte, eine Steuererklärung zu generieren, schlug der Join fehl, weil die Benutzerdaten verschwunden waren.
Die Kosten:Das Team musste ein Skript schreiben, um historische Daten manuell einem generischen „anonymen“ Benutzerbucket zuzuordnen. Dies dauerte drei Tage Ingenieurarbeit und erforderte einen vollständigen Datenbank-Dump und -Wiederherstellung, um sicher zu testen.
Szenario B: Die Denormalisierungs-Falle
Die Situation:Um die Leseleistung zu beschleunigen, kopierte ein Team Benutzerprofil-Daten in die Bestell-Tabelle. Sie gingen davon aus, dass dies die Anzahl der Join-Operationen reduzieren würde.
Der Fehler:Als ein Benutzer ihren Namen aktualisierte, aktualisierte die Anwendung die Benutzertabelle, aber vergaß, die Tausende von Bestell-Records mit dem alten Namen zu aktualisieren. Berichte zeigten inkonsistente Namen für denselben Benutzer.
Die Kosten:Die Datenkonsistenz ging verloren. Das Team musste entscheiden, ob es die Inkonsistenz akzeptieren oder ein komplexes Trigger-System zur Synchronisierung der Daten implementieren sollte. Sie entschieden sich dafür, das Schema zu refaktorisieren, um die Duplikation zu entfernen, was eine Neuschreibung der Schreiblogik der Anwendung erforderte.
Szenario C: Die Indexierungs-Blindstelle
Die Situation:Eine Suchfunktion wurde auf einer Tabelle mit Millionen von Zeilen aufgebaut. Der Entwickler ging davon aus, dass der Primärschlüssel ausreichen würde.
Der Fehler:Als die Tabelle wuchs, verlangsamten sich die Abfragen auf der Suchspalte bis zum Erliegen. Die Datenbank musste eine vollständige Tabellen-Suche durchführen.
Die Kosten:Das System wurde während der Spitzenzeiten unbrauchbar. Die spätere Hinzufügung eines Indexes erforderte eine lang laufende Operation, die die Tabelle stundenlang sperrte und zu einer Störung des Dienstes führte.
7. Zukunftssicherung Ihrer Datenebene 🔮
Das Ziel jedes Datenmodellierungsprojekts ist es, eine Grundlage zu schaffen, die Veränderungen standhält. Obwohl kein Schema für immer perfekt ist, bietet ein gutes ERD einen klaren Weg für die Entwicklung.
- Versionskontrolle:Behandle deine Schema-Migrationen wie Code. Speichere sie in der Versionskontrolle, um Änderungen im Zeitverlauf nachzuverfolgen.
- Automatisiertes Testen:Integriere Schema-Validierung in deine CI/CD-Pipeline. Stelle sicher, dass Migrationen bestehende Abfragen nicht brechen.
- Überwachung:Überwache die Abfrageleistung, um fehlende Indizes oder ineffiziente Joins frühzeitig zu erkennen.
- Gemeinschaftsstandards:Befolge etablierte Best-Practices für deine spezifische Datenbanktechnologie, um Kompatibilität und Leistung zu gewährleisten.
Die Zeit in der ERD-Phase zu investieren, ist keine Verzögerung; es ist eine Beschleunigung. Sie verringert den Widerstand zukünftiger Entwicklung und stellt sicher, dass die Daten eine zuverlässige Ressource bleiben und keine Last darstellen.
Fazit: Die Kosten der Ignoranz gegenüber dem Wert der Planung ⚖️
Die versteckten Kosten schlechter ER-Diagramme sind oft erst dann sichtbar, wenn es zu spät ist. Sie äußern sich in langsameren Features, instabilen Produktionsumgebungen und frustrierten Entwicklerteams. Die Refaktorisierung einer Datenbank ist eine hochriskante Operation, die Präzision, Planung und oft erhebliche Ausfallzeiten erfordert.
Indem man Datenmodellierung als eine kritische ingenieurtechnische Aufgabe statt als eine administrative Pflicht behandelt, können Organisationen die Fallen der technischen Schuld vermeiden. Ein gut gestaltetes Schema wirkt als Schutzschild und stellt sicher, dass die Anwendung auch beim Wachsen robust bleibt. Die Zeit, die für die Gestaltung eines soliden ERD aufgewendet wird, zahlt sich in jeder später geschriebenen Codezeile, jeder ausgeführten Abfrage und jedem bedienten Benutzer aus.
Warte nicht auf das Nachuntersuchungsprotokoll, um den Wert eines guten Bauplans zu erkennen. Beginne von Tag eins mit Klarheit, Strenge und einem Engagement für Datenintegrität.

