











Quando uma arquitetura de banco de dados projetada em papel funciona perfeitamente em um ambiente de teste, mas colapsa sob tráfego do mundo real, a discrepância geralmente reside entre o modelo visual e a realidade em tempo de execução. Um Diagrama de Relacionamento de Entidades (ERD) é um projeto, não um motor vivo. No entanto, quando desenvolvedores referem-se a um “ERD que falha sob carga”, geralmente estão descrevendo um design de esquema derivado desse diagrama que não consegue suportar as demandas da produção. Este guia aborda os gargalos estruturais, lógicos e de desempenho que fazem modelos relacionais lutarem quando o volume de dados e a concorrência aumentam abruptamente.
Diagnosticar esses problemas exige um profundo entendimento de como os relacionamentos de dados se traduzem em operações de E/S, contenção de bloqueios e uso de memória. Exploraremos os pontos de atrito onde escolhas de design colidem com limitações de hardware e padrões de tráfego. Ao identificar os sintomas específicos de falhas estruturais, você poderá refatorar seu modelo de dados para suportar escalabilidade sem comprometer a integridade dos dados.
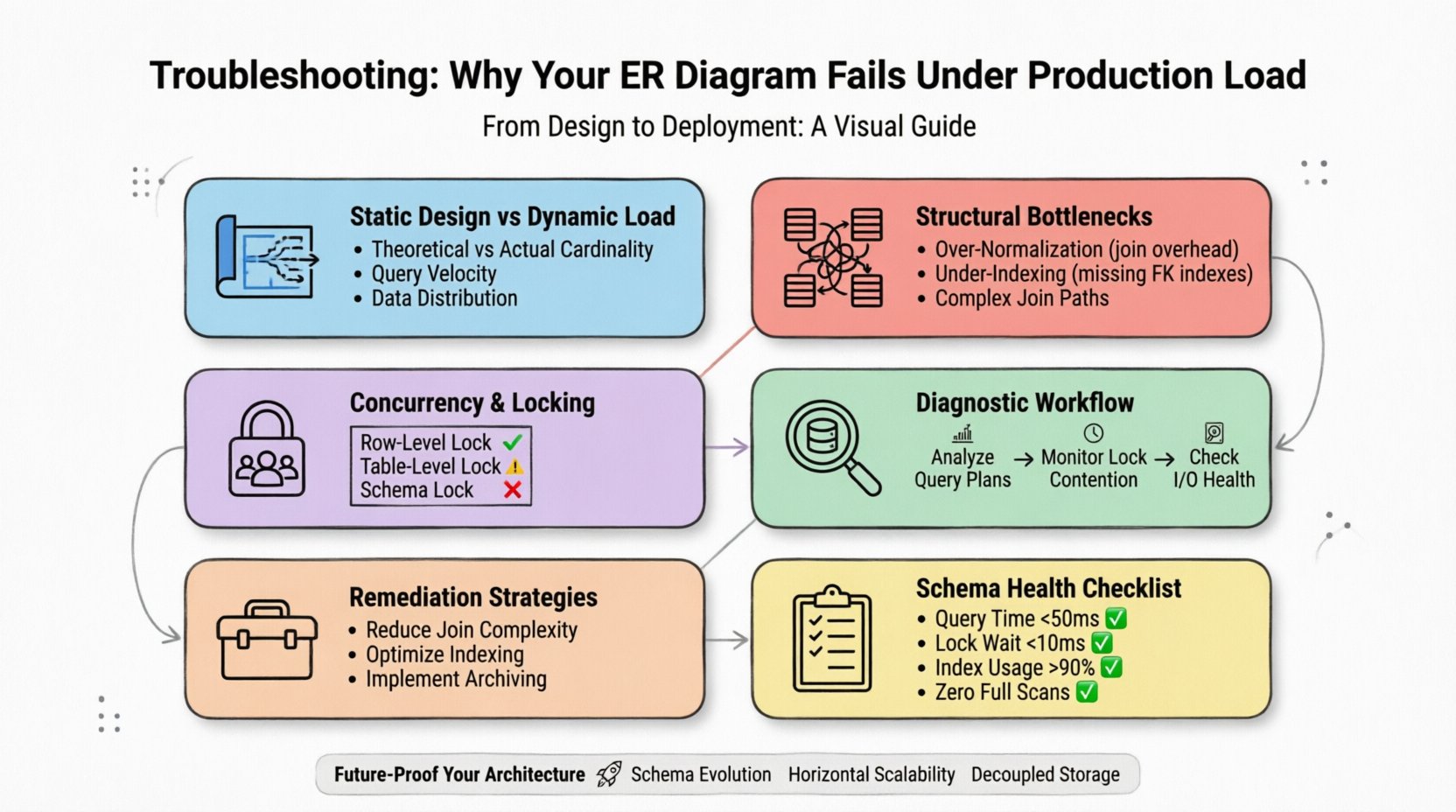
1. A Falha Entre o Design Estático e a Carga Dinâmica ⚡
Um diagrama ER representa relacionamentos potenciais e tipos de dados. Ele não leva em conta a velocidade das gravações, a distribuição das leituras ou as restrições físicas de armazenamento do motor subjacente. Um modelo que parece equilibrado em um quadro geralmente esconde ineficiências que só se manifestam quando milhões de linhas são consultadas simultaneamente.
- Cardinalidade Teórica vs. Real: Diagramas assumem relacionamentos um-para-um ou um-para-muitos. Na produção, esses relacionamentos frequentemente se tornam muitos-para-muitos com caminhos de junção complexos que esgotam os recursos da CPU.
- Velocidade de Consulta: Um esquema pode lidar com alguns milhares de leituras por segundo, mas falhar com milhares por milissegundo devido à granularidade dos bloqueios.
- Distribuição de Dados: Pontos quentes ocorrem quando os dados não são distribuídos uniformemente entre os nós de armazenamento, resultando em balanceamento de carga desigual.
Para diagnosticar com eficácia, você deve parar de tratar o esquema como um artefato estático. É um recurso dinâmico que deve ser monitorado tão de perto quanto o próprio servidor.
2. Gargalos Estruturais Comuns 📉
A causa mais frequente da degradação de desempenho é a própria estrutura de relacionamento. Como as tabelas estão conectadas determina como o motor percorre os dados. Junções complexas são o principal culpado por tempos de execução de consultas lentos.
2.1 Riscos da Sobrenormalização
Embora a normalização reduza a redundância, a normalização excessiva aumenta o número de junções necessárias para recuperar um único conjunto de dados. Em cenários de alta carga, cada junção é um ponto potencial de falha.
- Custo de Junção: Cada operação de junção exige que o banco de dados corresponda linhas de duas tabelas. Se essas tabelas forem grandes e não tiverem indexação adequada, o motor realiza uma varredura completa da tabela.
- Profundidade da Transação:Esquemas profundamente normalizados frequentemente exigem transações de longa duração para buscar dados relacionados, mantendo bloqueios por períodos prolongados.
- Eficiência do Cache:Os dados normalizados são fragmentados em várias páginas, reduzindo a eficácia do cache do pool de buffers.
2.2 Sub-indexação e Caminhos de Acesso
Um ERD bem estruturado implica padrões de acesso. Se o diagrama não estiver alinhado com a carga real de consultas, o motor do banco de dados não conseguirá encontrar o caminho mais rápido para os dados.
- Índices de Chaves Estrangeiras:Chaves estrangeiras frequentemente carecem de índices, causando quedas de desempenho ao excluir ou atualizar registros pais.
- Ordem das Chaves Compostas:A ordem das colunas em um índice composto importa. Se as consultas filtrarem primeiro pela segunda coluna, o índice pode ser ignorado.
- Índices Seletivos Ausentes:Sem índices em colunas de alta cardinalidade, o motor realiza varreduras completas de tabelas para encontrar valores específicos.
3. Concorrência e Mecanismos de Bloqueio 🔒
Quando a carga aumenta, a concorrência torna-se a principal restrição. Múltiplos usuários tentando modificar os mesmos dados criam contenção. Se o design do esquema não levar em conta a granularidade do bloqueio, o sistema entra em deadlock ou excede o tempo limite.
| Tipo de Bloqueio | Impacto na Carga | Sintoma Comum |
|---|---|---|
| Bloqueio por Linha | Impacto mínimo, alta concorrência | Baixa latência, alta taxa de transferência |
| Bloqueio por Tabela | Alto impacto, bloqueia outros usuários | Erros de tempo limite, consultas travadas |
| Bloqueio de Esquema | Bloqueia todo o acesso durante DDL | Interrupção em toda a rede durante manutenção |
3.1 Deadlocks e Condições de Corrida
Deadlocks ocorrem quando duas transações aguardam uma à outra para liberar recursos. Isso é frequentemente causado por ordens de bloqueio inconsistentes na lógica do aplicativo que interage com o esquema.
- Níveis de Isolamento de Transação: Níveis de isolamento mais altos (como Serializable) oferecem segurança, mas reduzem significativamente a concorrência.
- Escalonamento de Bloqueio: Se uma transação bloquear muitas linhas, o motor pode escalonar para um bloqueio de tabela, bloqueando todas as outras operações.
- Transações Longas: Operações que mantêm bloqueios por segundos em vez de milissegundos criam gargalos para toda a fila.
4. Volume de Dados e Estratégias de Particionamento 📊
À medida que os dados crescem, os limites físicos da camada de armazenamento tornam-se evidentes. Um esquema que funciona para 10.000 linhas pode falhar catastroficamente com 100 milhões de linhas. O particionamento é o método usado para dividir tabelas grandes em partes menores e gerenciáveis.
- Particionamento Vertical: Mover colunas raramente acessadas para uma tabela separada reduz o tamanho da tabela principal, melhorando as taxas de acerto do cache para dados quentes.
- Particionamento Horizontal: Dividir linhas em múltiplos segmentos físicos (sharding) distribui a carga entre vários nós de armazenamento.
- Particionamento Baseado em Tempo: Para dados transacionais, o particionamento por data permite que o motor remova partições antigas instantaneamente sem bloquear toda a tabela.
5. Fluxo de diagnóstico para falhas em produção 🔍
Quando o sistema fica lento, você precisa de uma abordagem sistemática para identificar a causa raiz. A otimização aleatória frequentemente desperdiça recursos. Siga este fluxo de trabalho para identificar o problema.
5.1 Analise os planos de execução de consultas
O plano de execução revela como o motor do banco de dados pretende recuperar os dados. Procure indicadores específicos de ineficiência.
- Escaneamentos completos de tabela:Indica um índice ausente ou uma consulta que solicita muitos dados.
- Pesquisas por chave:Sugere que o motor precisa alternar repetidamente entre o índice e os dados da tabela, aumentando a I/O.
- Operações de ordenação:Ordenar conjuntos de resultados grandes consome memória e CPU significativos.
5.2 Monitore a contenção de bloqueios
Use ferramentas do sistema para monitorar eventos de espera. Tempos de espera elevados em bloqueios indicam que o esquema não pode suportar o nível atual de concorrência.
- Métricas de tempo de espera:Monitore a duração em que as transações ficam esperando por recursos.
- Gráficos de deadlocks:Revise dados históricos para ver quais consultas causaram conflitos.
- Fila de espera de bloqueios:Monitore o número de transações esperando pelo mesmo recurso.
5.3 Verifique a saúde do subsistema de E/S
Mesmo com um esquema perfeito, armazenamento lento causará falhas. Certifique-se de que a infraestrutura subjacente corresponda aos padrões de acesso aos dados.
- Limites de throughput:Verifique se o dispositivo de armazenamento está saturado com operações de leitura/escrita.
- Picos de latência:Tempos de resposta inconsistentes da camada de armazenamento frequentemente indicam degradação de hardware.
- Eficiência do pool de buffers:Se o banco de dados gasta mais tempo lendo do disco do que da memória, o esquema ou o volume de dados é muito grande para o cache.
6. Estratégias de remediação para otimização de esquema 🛠️
Uma vez identificado o gargalo, aplique mudanças direcionadas. Refatorar um esquema de produção exige cautela para evitar perda de dados ou tempo de inatividade.
6.1 Redução da complexidade de junções
Simplifique as relações que causam mais atrito. Isso frequentemente envolve a desnormalização de áreas específicas do modelo.
- Visualizações Materializadas: Pré-calcule junções complexas e armazene o resultado em uma tabela separada para recuperação rápida.
- Colunas Computadas: Armazene dados derivados diretamente na tabela para evitar cálculos no momento da consulta.
- Roteamento de Réplicas de Leitura: Envie consultas intensivas de leitura para uma réplica que mantém uma cópia desnormalizada dos dados.
6.2 Otimização da Estratégia de Indexação
Índices são a ferramenta mais eficaz para acelerar pesquisas, mas têm um custo nas operações de escrita.
- Índices Filtrados: Crie índices apenas em subconjuntos de dados que são frequentemente consultados.
- Índices Cobertores: Inclua todas as colunas necessárias para uma consulta no índice para evitar acessar a tabela principal.
- Manutenção de Índices: Reconstitua ou reorganize regularmente os índices para evitar fragmentação causada por atualizações frequentes.
6.3 Implementação de Exclusão Suave e Arquivamento
Dados ativos são mais rápidos para consultar do que dados históricos. Mover dados antigos da tabela principal melhora o desempenho.
- Tabelas de Arquivamento: Mova registros mais antigos que um determinado limite para uma camada de armazenamento separada e mais fria.
- Exclusão Suave: Marque registros como excluídos sem removê-los, mantendo a estrutura da tabela estável enquanto oculta logicamente os dados.
- Políticas de Retenção de Dados: Automatize a limpeza de dados desnecessários para evitar crescimento descontrolado.
7. Lista de Verificação de Avaliação da Saúde do Esquema ✅
Antes de implantar alterações, verifique seu modelo com base neste critérios para garantir que ele possa suportar a pressão da produção.
| Critérios | Condição de Aprovação | Condição de Falha |
|---|---|---|
| Tempo Médio de Consulta | < 50ms | > 500ms |
| Tempo de Espera por Bloqueio | < 10ms | > 100ms |
| Uso de Índices | > 90% | < 50% |
| Escaneamentos Completos de Tabela | Zero | Frequente |
Auditar regularmente seu modelo de dados com base nessas métricas garante que o design evolua junto com suas necessidades comerciais. Um esquema estático acabará se tornando uma desvantagem. A monitorização contínua e os ajustes incrementais são a única maneira de manter a confiabilidade.
8. Compreendendo Padrões de Consulta e Cargas de Trabalho 📈
O desempenho não se limita apenas ao esquema; trata-se de como esse esquema é utilizado. Compreender o perfil da carga de trabalho é essencial para otimizar o modelo.
- OLTP vs. OLAP:Processamento de Transações Online (OLTP) exige gravações rápidas e pequenas. Processamento Analítico Online (OLAP) exige leituras rápidas e grandes. Um esquema otimizado para um frequentemente tem dificuldades com o outro.
- Padrões de Escrita Intensa: Se seu aplicativo escreve com frequência, priorize a eficiência dos índices e minimize o bloqueio durante gravações.
- Padrões de Leitura Intensa: Se seu aplicativo lê com frequência, priorize estratégias de cache e réplicas de leitura.
9. O Papel da Lógica da Aplicação no Desempenho do Banco de Dados 💻
Muitas vezes, o problema não está no banco de dados, mas na forma como a aplicação interage com ele. Problemas de consultas N+1 são um exemplo clássico de ineficiência de nível de aplicação que se manifesta como falha no banco de dados.
- Operações em Lote: Enviar milhares de instruções de inserção individuais é mais lento do que uma única operação em lote.
- Carregamento Precoce: Buscar dados em pequenos pedaços pode gerar excesso de viagens de ida e volta ao banco de dados.
- Pool de Conexões: Uma gestão ineficiente das conexões com o banco de dados pode esgotar os recursos disponíveis durante picos de carga.
Otimizar a camada da aplicação reduz a pressão sobre o esquema, permitindo que o banco de dados funcione dentro de seus parâmetros projetados.
10. Preparando sua Arquitetura de Dados para o Futuro 🚀
Projetar para o futuro exige antecipar o crescimento. Embora você não possa prever números exatos de tráfego, pode projetar para elasticidade.
- Evolução do Esquema: Use estratégias de migração que permitam alterações não disruptivas no modelo de dados.
- Escalabilidade Horizontal: Projete tabelas para suportar o shardings desde o início.
- Armazenamento Desacoplado: Separe a camada de armazenamento da camada de computação para escaloná-las independentemente.
Ao seguir esses princípios, você constrói uma base capaz de resistir às pressões da produção. O objetivo não é apenas corrigir problemas atuais, mas criar um sistema resiliente capaz de se adaptar aos desafios futuros.
11. Resumo das Etapas Chave de Diagnóstico 📝
Para recapitular, diagnosticar falhas de carga em produção envolve uma abordagem multicamadas.
- Revise o ERD: Verifique relações excessivamente complexas e índices ausentes.
- Analise as Consultas: Procure varreduras completas de tabelas e caminhos de junção ineficientes.
- Monitore os Blocos: Identifique pontos de contenção que causam tempo limite.
- Verifique o Hardware: Certifique-se de que armazenamento e memória não sejam gargalos.
- Otimize o Esquema: Aplique estratégias de particionamento e indexação.
- Refatore o Aplicativo: Reduza o número de chamadas ao banco de dados e otimize o tratamento de transações.
Seguir esta abordagem estruturada garante que você aborde a causa raiz e não apenas os sintomas. O ajuste de desempenho é um processo iterativo que exige paciência e precisão.
12. Pensamentos Finais sobre a Resiliência do Esquema 🧠
Um modelo de dados robusto é a base de qualquer aplicação de alto desempenho. Exige atenção constante e disposição para se adaptar conforme os padrões de tráfego mudam. Ao compreender as nuances de relacionamentos, indexação e concorrência, você pode evitar os erros comuns que levam a falhas em produção.
Lembre-se de que o diagrama é uma ferramenta, não o sistema. O verdadeiro teste do seu design acontece no ambiente ao vivo. Mantenha sua monitoração apertada, seus índices limpos e suas transações curtas. Com essas práticas em vigor, sua arquitetura de dados servirá como uma base confiável para o crescimento do seu negócio.
Permaneça vigilante. Monitore suas métricas. Refatore quando necessário. Seu sistema agradecerá.

