











Schematy baz danych często ewoluują organicznie, a nie poprzez celowe projektowanie. Z czasem szybkie cykle rozwoju, brak dokumentacji i zmieniające się wymagania biznesowe prowadzą do skomplikowanych, trudnych do przewijania struktur. Wiele organizacji znajduje się w sytuacji dziedziczenia systemów dziedziczonych, gdzie pierwotni architekci nie są już dostępni, a model danych jest zasłonięty przez lata poprawek i szybkich napraw. Ten proces obejmuje analizę istniejących warstw danych i ich ponowne konstruowanie w standardowej strukturze diagramu relacji encji (ERD). Celem jest przejrzystość, utrzymywalność i integralność.
Odwracanie inżynierii bazy danych nie polega jedynie na rysowaniu linii między tabelami; polega na zrozumieniu logiki biznesowej ukrytej w danych. Czysty diagram ERD służy jako projekt dla przyszłego rozwoju, narzędziem komunikacji dla stakeholderów oraz ochroną przed uszkodzeniem danych. Niniejszy poradnik szczegółowo opisuje przepływ techniczny przekształcania chaotycznego schematu w strukturalny, znormalizowany projekt bez użycia konkretnych narzędzi własnościowych.
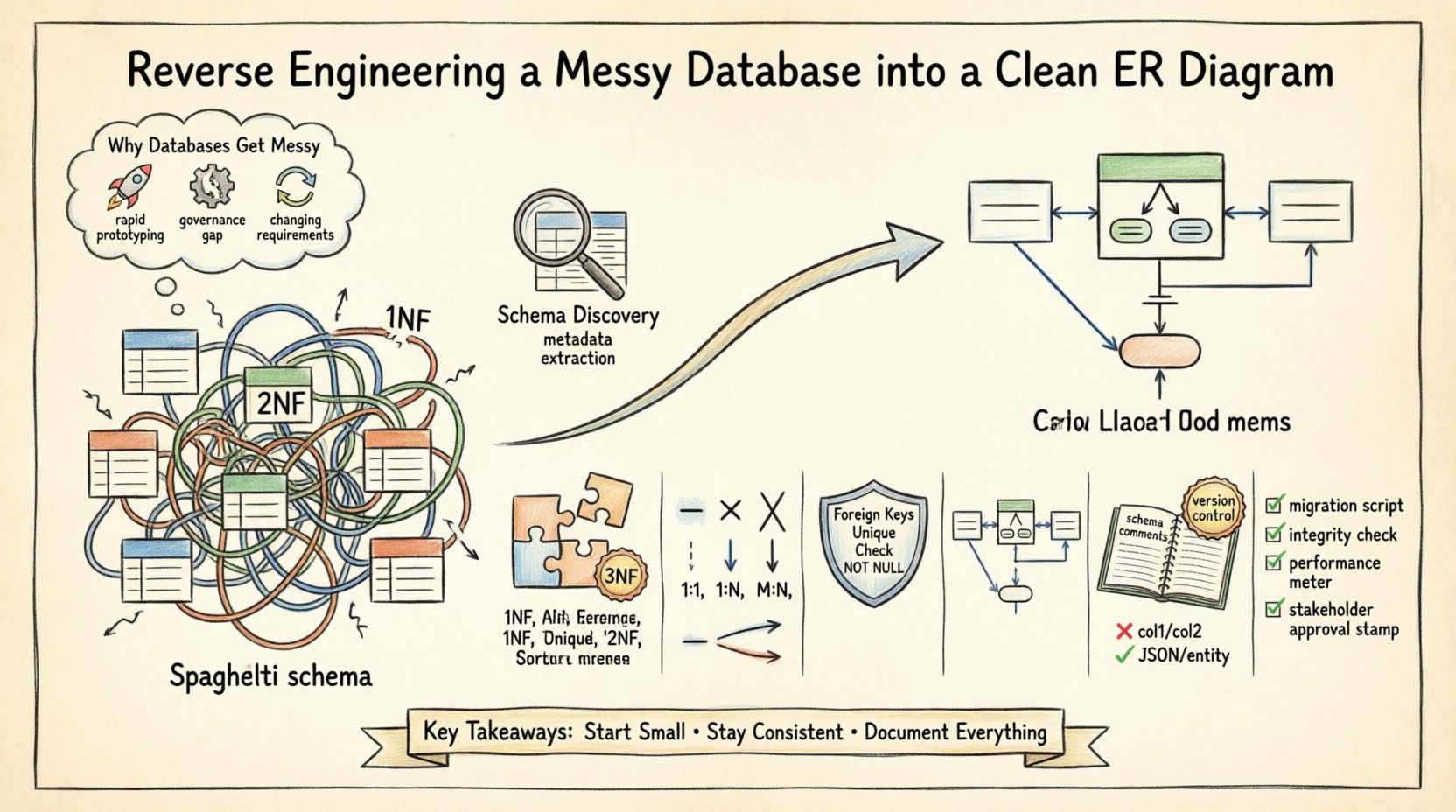
Dlaczego bazy danych stają się chaotyczne 📉
Zrozumienie przyczyny pierwotnej długu schematu jest pierwszym krokiem ku jego usunięciu. Kilka czynników przyczynia się do nieuporządkowanej struktury bazy danych:
- Szybkie prototypowanie:Początkowy rozwój często stawia nacisk na szybkość zamiast na strukturę. Tabele są tworzone na bieżąco, aby spełnić natychmiastowe żądania funkcjonalne, bez rozważania skalowalności długoterminowej.
- Brak zarządzania:Gdy wiele deweloperów modyfikuje schemat bez centralnego procesu przeglądu, konwencje nazewnictwa się różnią, a pojawiają się nadmiarowe kolumny.
- Zmiany logiki biznesowej:W miarę zmiany wymagań tabele są modyfikowane, aby dopasować nowe pola. Klucze obce czasem są usuwane, aby obejść ograniczenia, co prowadzi do pozostawionych rekordów bez rodzica.
- Luki w dokumentacji:Komentarze i opisy metadanych są często pomijane podczas początkowego wdrażania, co utrudnia zrozumienie intencji określonych kolumn w przyszłości.
Te problemy prowadzą do tego, co często nazywa się „schematem makaronowym”. Relacje stają się niejawne zamiast jawnych, a klucze główne mogą zostać utracone lub powielone w wielu tabelach. Poniższe sekcje przedstawiają systematyczny podejście do rozwiązywania tych problemów.
Faza 1: Odkrywanie i profilowanie schematu 🔍
Zanim narysujesz jakiekolwiek linie, musisz zrozumieć aktualny stan bazy danych. Ta faza skupia się na wyodrębnieniu i analizie, a nie na modyfikacji.
Wyodrębnianie metadanych
Każdy system zarządzania bazami danych relacyjnymi utrzymuje katalogi systemowe lub widoki schematu informacji. Te repozytoria zawierają szczegółowe informacje o tabelach, kolumnach, typach danych, ograniczeniach i indeksach. Wykorzystaj interfejsy zapytań, aby pobrać te metadane.
- Lista tabel: Pobierz wszystkie nazwy tabel oraz ich daty utworzenia, aby zidentyfikować struktury dziedziczne.
- Definicje kolumn: Wyodrębnij nazwy kolumn, typy danych, możliwość wartości null oraz wartości domyślne.
- Ograniczenia: Zidentyfikuj klucze główne, ograniczenia unikalności i relacje kluczy obcych. Zwróć uwagę, że niektóre relacje mogą być wymuszane tylko na poziomie aplikacji, a nie w bazie danych.
- Indeksy: Przeanalizuj istniejące indeksy, aby zrozumieć wzorce wydajności zapytań i zidentyfikować potencjalne klucze kandydujące.
Profilowanie danych
Metadane mówią Ci, jak schemat *powinien* wyglądać, ale profilowanie danych mówi Ci, jak wygląda *w rzeczywistości*. Skanowanie rzeczywistych wartości danych ujawnia niezgodności, które definicje schematu pomijają.
- Rozkład wartości: Sprawdź kolumny o wysokiej lub niskiej kardynalności, które mogą wskazywać na potrzebę normalizacji.
- Stawki nulli:Wysokie stawki nulli w wymaganych polach wskazują na brakujące ograniczenia lub słabe praktyki wprowadzania danych.
- Jakość danych:Zidentyfikuj niezgodności w formacie, takie jak numery telefonów przechowywane jako tekst w różnych formatach.
Faza 2: Identyfikacja encji i normalizacja 🧱
Po zrozumieniu danych surowych następny krok to logiczne przebudowanie. Obejmuje to identyfikację encji i stosowanie reguł normalizacji w celu zmniejszenia nadmiarowości.
Identyfikacja encji
Encja reprezentuje odrębny obiekt lub pojęcie w zakresie działalności biznesowej. W nieuporządkowanej bazie danych encje często są rozproszone na wielu tabelach lub niepoprawnie połączone.
- Zużycie:Upewnij się, że każda tabela reprezentuje pojedynczy koncept. Jeśli tabela zawiera zarówno informacje o kliencie, jak i o zamówieniu, najprawdopodobniej narusza zasady normalizacji.
- Klucze podstawowe:Ustanów unikalny identyfikator dla każdej encji. Unikaj używania kluczy naturalnych (np. adresów e-mail), jeśli mogą ulec zmianie; zamiast tego używaj kluczy zastępczych.
- Zasady nazewnictwa:Ujednolit nazwy tabel w spójnym formacie, np. rzeczowniki liczby pojedynczej (np.
klientzamiastklienci).
Stosowanie normalizacji
Normalizacja to proces organizowania danych w celu zmniejszenia nadmiarowości i poprawy integralności. Choć celem nie zawsze jest osiągnięcie maksymalnej teoretycznej wartości (Postać Normalna Boyce’a-Codda), dążenie do Trzeciej Postaci Normalnej (3NF) jest solidnym standardem dla systemów transakcyjnych.
| Postać | Definicja | Cel |
|---|---|---|
| Pierwsza Postać Normalna (1NF) | Wartości atomowe w kolumnach; brak powtarzających się grup. | Upewnij się, że każda komórka zawiera jedną wartość. |
| Druga Postać Normalna (2NF) | Spełnia 1NF i usuwa zależności częściowe. | Upewnij się, że atrybuty niekluczowe zależą od całego klucza podstawowego. |
| Trzecia Postać Normalna (3NF) | Spełnia 2NF i usuwa zależności przekazywane. | Upewnij się, że atrybuty niekluczowe zależą wyłącznie od klucza podstawowego. |
Podczas inżynierii wstecznej szukaj kolumn przechowujących listy wartości (np. ciąg rozdzielony przecinkami z etykietami). Muszą one zostać podzielone na osobne wiersze w tabeli pośredniej, aby spełnić 1NF. Podobnie atrybuty opisujące różne encje (np. nazwa_produktu i adres_dostawcy w tej samej tabeli) powinny zostać rozdzielone na osobne encje, aby spełnić 2NF i 3NF.
Faza 3: Mapowanie relacji 🔗
Relacje definiują sposób działania encji. W nieporządnym zbiorze danych są one często niejawne lub brakują. Ta faza obejmuje definiowanie liczności i opcjonalności tych połączeń.
Typy liczności
- Jeden do jednego (1:1): Jeden rekord w Tabeli A jest powiązany dokładnie z jednym rekordem w Tabeli B. Jest to rzadkie zjawisko i często wskazuje na podział z powodów bezpieczeństwa lub wydajności.
- Jeden do wielu (1:N): Jeden rekord w Tabeli A jest powiązany z wieloma rekordami w Tabeli B. Jest to najbardziej powszechna relacja (np. Jeden Klient składa Wiele Zamówień).
- Wiele do wielu (M:N): Wiele rekordów w Tabeli A jest powiązanych z wieloma rekordami w Tabeli B. Wymaga to pośredniej tabeli połączeniowej (np. Studenci i Kursy).
Rozwiązywanie relacji wiele do wielu
Nieporządne bazy danych często próbują obsłużyć relacje wiele do wielu poprzez powielanie danych lub tworzenie szerokich tabel z wieloma kolumnami kluczy obcych. Poprawnym podejściem jest wprowadzenie tabeli połączeniowej.
- Zidentyfikuj dwie rodzicielskie encje.
- Utwórz nową tabelę zawierającą klucze podstawowe obu rodziców.
- Dodaj dowolne specyficzne atrybuty związane z samą relacją (np.
data_zapisuw tabeli połączeniowej Student-Kurs).
Faza 4: Ograniczenia i integralność danych 🔒
Diagram jest bezużyteczny, jeśli nie wymusza zasad, które przedstawia. Wdrożenie fizyczne musi odzwierciedlać projekt logiczny poprzez ograniczenia.
- Klucze obce:Jawnie zdefiniuj ograniczenia kluczy obcych, aby zapobiec istnieniu zaniedbanych rekordów. Zapewnia to automatycznie integralność referencyjną.
- Ograniczenia unikalności:Zastosuj ograniczenia unikalności do kolumn, które muszą być różne (np. adresy e-mail, nazwy użytkowników).
- Ograniczenia sprawdzające: Użyj ograniczeń sprawdzających, aby zweryfikować formaty danych lub zakresy (np.
wiek >= 0). - Nie null: Zaznacz istotne pola jako
NOT NULLaby zapewnić kompletność danych.
Faza 5: Wizualizacja modelu ERD 🎨
Po ustaleniu modelu logicznego musi zostać wizualizowany. Choć istnieją specjalistyczne oprogramowanie do tego celu, zasady tworzenia diagramów pozostają stałe.
Standardy tworzenia diagramów
Wybierz standard notacji, aby zapewnić czytelność diagramu dla różnych stakeholderów.
- Notacja „Klucza kruka”: Szeroko stosowana w przemyśle. Używa określonych symboli do oznaczania liczności (np. pojedyncza linia dla „jeden”, klucz kruka dla „wiele”).
- Diagramy klas UML: Używa prostokątów i strzałek, często preferowana przez programistów znaną z projektowania obiektowego.
- Notacja Chen: Używa rombów do oznaczania relacji, powszechna w środowiskach akademickich, ale rzadsza w nowoczesnych narzędziach przedsiębiorstw.
Najlepsze praktyki układu
- Grupowanie: Grupuj powiązane tabele razem (np. wszystkie tabele Order w jednym obszarze), aby pokazać domeny logiczne.
- Kierunek przepływu: Ułóż diagramy tak, aby przepływ był logiczny od lewej do prawej lub od góry do dołu.
- Czytelność: Upewnij się, że nazwy tabel są jasno widoczne, a przecięcia linii są minimalizowane.
Faza 6: Dokumentacja i utrzymanie 📝
Statyczny diagram to zdjęcie. Aby zapewnić wartość długoterminową, dokumentacja musi być utrzymywana razem z kodem.
Komentarze schematu
Używaj komentarzy kolumn i tabel, aby wyjaśnić logikę biznesową. Na przykład kolumna o nazwie status powinna mieć komentarz wyjaśniający, jakie wartości są dozwolone (np. „0: Oczekujące, 1: Zatwierdzone, 2: Odrzucone”).
Kontrola wersji
Przechowuj pliki ERD i definicji schematu w systemie kontroli wersji. Dzięki temu możesz śledzić zmiany w czasie i cofnąć je, jeśli to konieczne.
Powszechne wzorce do unikania 🚫
W trakcie procesu oczyszczania bądź ostrożny podczas unikania typowych pułapek.
| Wzorzec do unikania | Problem | Rozwiązanie |
|---|---|---|
| Ogólne kolumny danych | Używanie kolumn takich jakcol1, col2 do elastycznego przechowywania danych. |
Zamień na kolumnę JSON lub nową tabelę encji. |
| Klucze złożone | Używanie wielu kolumn jako klucza podstawowego. | Zaleca się używanie kluczy zastępczych (liczby całkowite z automatycznym zwiększaniem) dla uproszczenia. |
| Denormalizacja dla prędkości | Dwukrotne zapisywanie danych w celu uniknięcia łączeń. | Zaakceptuj koszt wydajności łączeń, chyba że profilowanie dowiedzie inaczej. |
Faza 7: Weryfikacja i testowanie ✅
Po przebudowie nowy schemat musi zostać zweryfikowany wobec istniejących danych.
- Skrypty migracji: Napisz skrypty do przenoszenia danych z starego schematu do nowego. Upewnij się, że podczas transferu nie stracisz żadnych danych.
- Sprawdzenia integralności referencyjnej: Uruchom zapytania, aby upewnić się, że wszystkie klucze obce wskazują na poprawne rekordy nadrzędne.
- Testy wydajności: Uruchom aplikację wobec nowego schematu, aby zweryfikować, czy wydajność zapytań nadal jest akceptowalna.
- Recenzja zainteresowanych stron: Przedstaw diagram użytkownikom biznesowym, aby potwierdzili, że dokładnie odzwierciedla ich procesy.
Ostateczne rozważania 🏁
Odwrócone inżynieria bazy danych to znaczące przedsięwzięcie wymagające cierpliwości i precyzji. Nie jest to zadanie jednorazowe, lecz część ciągłego cyklu zarządzania danymi. Przestrzegając strukturalnego podejścia, organizacje mogą przekształcić chaotyczne repozytoria danych w wiarygodne aktywa.
Pamiętaj, że schemat to narzędzie komunikacji. Jeśli stakeholderzy biznesowi nie rozumieją przedstawionych relacji, wysiłek techniczny nie został w pełni skuteczny. Regularne przeglądy schematu zapewniają, że przyszłe rozwijanie będzie zgodne z zainstalowaną architekturą.
Skup się na spójności. Niezależnie czy chodzi o zasady nazewnictwa, definicje ograniczeń czy style schematów, jednolitość zmniejsza obciążenie poznawcze dla wszystkich, którzy współpracują z systemem. Zacznij od małego. Wybierz jeden moduł lub dziedzinę, uporządkuj ją i dokładnie z dokumentuj. Następnie rozszerz proces na inne obszary. Ta stopniowa metoda zmniejsza ryzyko i pozwala na ciągłe doskonalenie.
Na końcu, czysta struktura ERD jest fundamentem solidnej strategii danych. Pozwala programistom szybciej tworzyć funkcje i zmniejsza ryzyko utraty danych lub ich uszkodzenia. Inwestuj czas teraz, aby później skorzystać z korzyści z stabilności i przejrzystości.

