











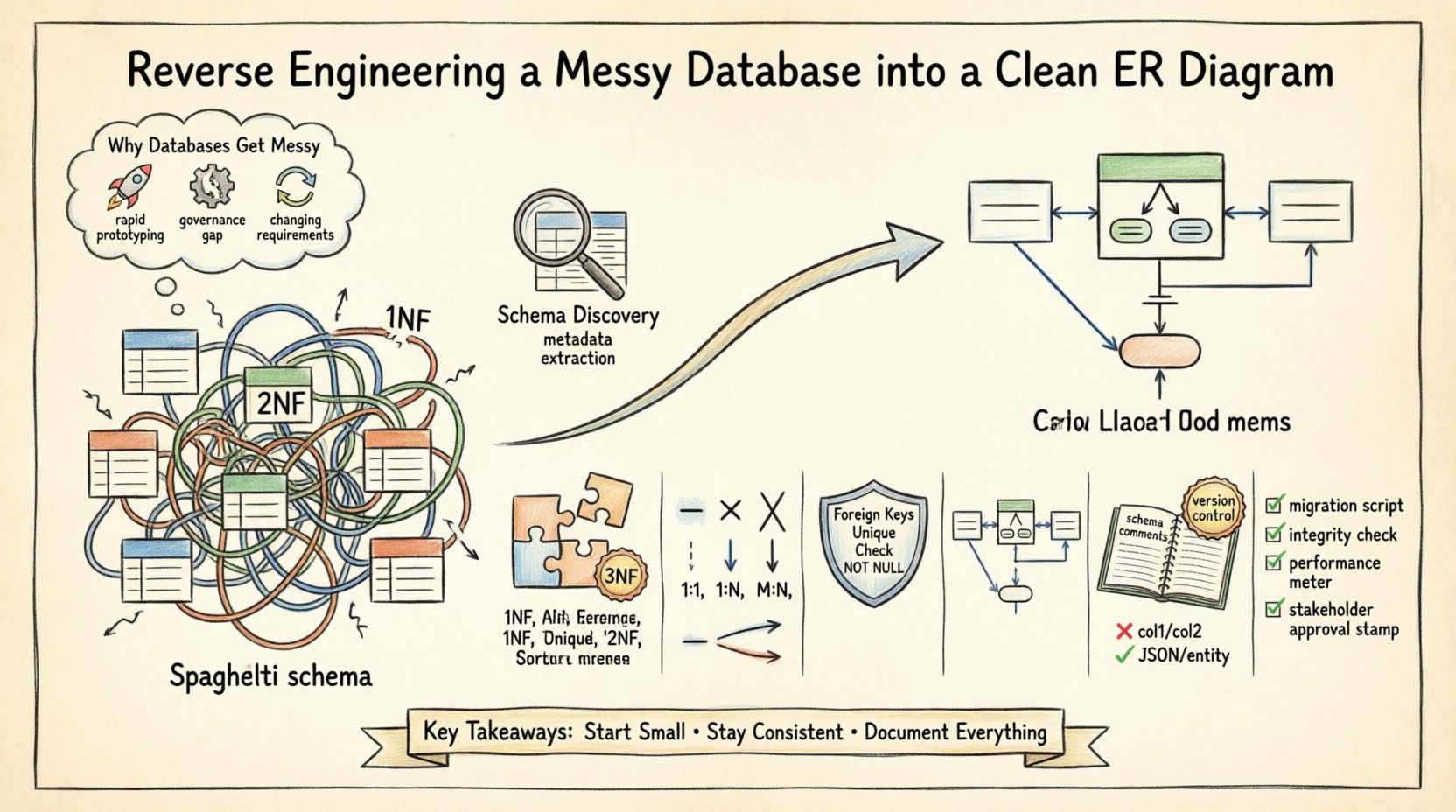
データベーススキーマは、意図的な設計ではなく、自然に進化することが多い。時間の経過とともに、急速な開発サイクル、ドキュメント不足、ビジネス要件の変化が、複雑で使いにくい構造を生み出す。多くの組織は、元の設計者たちがすでに不在で、何年ものパッチや緊急修正によってデータモデルが曖昧になっているレガシーシステムを受け継いでいる。このプロセスでは、既存のデータレイヤーを分析し、標準化されたエンティティ関係図(ERD)に再構築する。目的は明確性、保守性、整合性である。
データベースのリバースエンジニアリングは、テーブルの間に線を引くことだけではない。データの中に埋め込まれたビジネスロジックを理解することにある。クリーンなERDは、将来の開発のための設計図となり、ステークホルダー間のコミュニケーションツールとなり、データ破損から守る防衛策となる。このガイドでは、特定の独自ツールに依存せずに、混沌としたスキーマを構造的で正規化された設計に変換するための技術的ワークフローを詳述する。
なぜデータベースは乱雑になるのか 📉
スキーマデットの根本原因を理解することは、是正への第一歩である。いくつかの要因が、整理されていないデータベース構造を生み出している:
- 素早いプロトタイピング:初期開発では、構造よりもスピードが優先されることが多い。長期的なスケーラビリティを考慮せずに、即時の機能要件を満たすために、急いでテーブルが作成される。
- ガバナンスの欠如:複数の開発者が中央集権的なレビュー体制なしにスキーマを変更すると、命名規則がばらつき、重複するカラムが出現する。
- ビジネスロジックの変更:要件が変化すると、テーブルが新しいフィールドに対応させるために変更される。制約を回避するために、外部キーが時折削除され、孤立したレコードが生じる。
- ドキュメントの穴:コメントやメタデータの説明は、初期デプロイ時にしばしば省略されるため、後で特定のカラムの意図を理解することが難しくなる。
これらの問題は、しばしば「スパゲッティスキーマ」と呼ばれる状態を生み出す。関係性は明示的ではなく、暗黙的になり、主キーが複数のテーブルに失われたり重複したりする。以下のセクションでは、これらの問題を解決する体系的なアプローチを概説する。
フェーズ1:スキーマの発見とプロファイリング 🔍
どんな線も引く前に、データベースの現在の状態を理解しなければならない。このフェーズでは、変更ではなく、抽出と分析に焦点を当てる。
メタデータの抽出
すべてのリレーショナルデータベース管理システムは、システムカタログまたは情報スキーマビューを維持している。これらのリポジトリには、テーブル、カラム、データ型、制約、インデックスに関する詳細が含まれている。クエリインターフェースを利用して、このメタデータを取得する。
- テーブル一覧:すべてのテーブル名と作成日を取得し、レガシーシステムを特定する。
- カラム定義:カラム名、データ型、NULL許容性、デフォルト値を抽出する。
- 制約:主キー、一意制約、外部キー関係を特定する。一部の関係はデータベースではなくアプリケーションレベルでのみ強制されていることに注意する。
- インデックス:既存のインデックスを分析し、クエリのパフォーマンスパターンを理解し、潜在的な候補キーを特定する。
データプロファイリング
メタデータはスキーマが「あるべき姿」を教えてくれるが、データプロファイリングはそれが「実際にどうなっているか」を教えてくれる。実際のデータ値をスキャンすることで、スキーマ定義では見逃される不整合が明らかになる。
- 値の分布:正規化の必要性を示唆する高基数または低基数のカラムを確認する。
- ヌル値の割合:必須フィールドに高い割合のヌル値があることは、制約が欠落しているか、データ入力の品質が低いことを示唆している。
- データ品質:電話番号が異なる形式でテキストとして保存されているなど、フォーマットの不整合を特定する。
フェーズ2:エンティティの識別と正規化 🧱
原始データが理解されたら、次のステップは論理的な再構成である。これはエンティティの特定と、冗長性を減らすための正規化ルールの適用を含む。
エンティティの識別
エンティティとは、ビジネスドメイン内の明確なオブジェクトまたは概念を表す。乱雑なデータベースでは、エンティティが複数のテーブルに散らばっているか、誤って結合されていることが多い。
- 粒度:各テーブルが単一の概念を表していることを確認する。顧客情報と注文情報の両方を保持するテーブルは、正規化の原則に違反している可能性が高い。
- 主キー:各エンティティに一意の識別子を設定する。変更される可能性がある自然キー(例:メールアドレス)は避けて、代わりにサーロゲートキーを使用する。
- 命名規則:テーブル名を一貫した形式に統一する。例えば、単数名詞(例:
顧客ではなく顧客たち).
正規化の適用
正規化とは、冗長性を減らし、整合性を高めるためにデータを整理するプロセスである。理論上の最大値(ボイス・コッド正規形)に到達することを常に目指す必要はないが、トランザクションシステムでは第三正規形(3NF)を目指すことが堅実な基準である。
| 形態 | 定義 | 目的 |
|---|---|---|
| 第一正規形(1NF) | 列に原子値を保持する;繰り返しグループがない。 | 各セルが単一の値を含むことを確認する。 |
| 第二正規形(2NF) | 1NFを満たし、部分的依存関係を排除する。 | 非キー属性が主キー全体に依存していることを確認する。 |
| 第三正規形(3NF) | 2NFを満たし、推移的依存関係を除去する。 | 非キー属性がプライマリキーのみに依存することを確認する。 |
リバースエンジニアリングを行う際には、値のリスト(例:タグをカンマ区切りで格納する文字列)を格納するカラムを探し出す。これらは1NFを満たすために、結合テーブルに別々の行に分割する必要がある。同様に、異なるエンティティを記述する属性(例:product_name および vendor_address 同じテーブル内にあるもの)は、2NFおよび3NFを満たすために別々のエンティティに分離するべきである。
フェーズ3:関係のマッピング 🔗
関係はエンティティ間の相互作用を定義する。乱雑なデータベースでは、これらの関係はしばしば暗黙的であるか、欠落している。このフェーズでは、これらの接続の基数とオプショナリティを定義する。
基数の種類
- 1対1(1:1): テーブルAの1レコードが、テーブルBの正確に1レコードと関連する。これは稀であり、セキュリティまたはパフォーマンスの理由で分割されていることが多い。
- 1対多(1:N): テーブルAの1レコードが、テーブルBの複数のレコードと関連する。これは最も一般的な関係である(例:1人の顧客が複数の注文を出す)。
- 多対多(M:N): テーブルAの複数のレコードが、テーブルBの複数のレコードと関連する。これには中間の結合テーブルが必要となる(例:生徒と授業)。
多対多関係の解決
乱雑なデータベースは、多対多関係を扱うためにデータを複製するか、複数の外部キー列を含む広いテーブルを作成しようとする。正しいアプローチは、ブリッジテーブルを導入することである。
- 2つの親エンティティを特定する。
- 両親のプライマリキーを含む新しいテーブルを作成する。
- 関係自体に関連する特定の属性を追加する(例:
enrollment_date生徒-授業ブリッジテーブルにおけるもの)。
フェーズ4:制約とデータ整合性 🔒
図が示すルールを強制しないならば、無意味である。物理的実装は制約を通じて論理設計を反映しなければならない。
- 外部キー:外部キー制約を明示的に定義して、孤児レコードを防ぐ。これにより参照整合性が自動的に確保される。
- 一意制約:一意でなければならないカラム(例:メールアドレス、ユーザー名)に一意制約を適用する。
- チェック制約: チェック制約を使用して、データ形式や範囲を検証します(例:
age >= 0). - NULL不可:必須フィールドを
NOT NULLとして、データの完全性を確保します。
フェーズ5:ERDの可視化 🎨
論理モデルが確立されると、それを可視化する必要があります。特定のソフトウェアはこれに使用できますが、図示の原則は一貫しています。
図示の標準
異なるステークホルダーが図を読みやすくするために、表記法の標準を選択してください。
- クロウズフット表記:業界で広く使用されています。カーディナリティを示すために特定の記号を使用します(例:「1」には単線、「many」にはクロウズフット)。
- UMLクラス図:ボックスと矢印を使用し、オブジェクト指向設計に精通したソフトウェア開発者に好まれます。
- チェン表記:関係性にはダイヤモンドを使用し、学術的環境で一般的ですが、現代の企業ツールではあまり使用されません。
レイアウトのベストプラクティス
- グループ化:関連するテーブルをまとめて配置します(例:すべてのOrderテーブルを1つの領域に)論理的なドメインを示します。
- 流れの方向:図を左から右、または上から下へと論理的に流れが生じるように配置します。
- 可読性:テーブル名が明確に見えるようにし、線の交差を最小限に抑えてください。
フェーズ6:ドキュメント作成と保守 📝
静的な図はスナップショットです。長期的な価値を確保するためには、コードと並行してドキュメントを維持する必要があります。
スキーマコメント
カラムおよびテーブルのコメントを使用して、ビジネスロジックを説明します。たとえば、statusという名前のカラムには、有効な値について説明するコメントを付けるべきです(例:「0: 保留中、1: 承認済み、2: 拒否」)。
バージョン管理
ERDおよびスキーマ定義ファイルをバージョン管理システムに保存してください。これにより、時間の経過とともに変更を追跡でき、必要に応じて元に戻すことができます。
避けるべき一般的な悪習慣 🚫
整理作業中に、一般的な落とし穴に注意を払ってください。
| 悪習慣 | 問題点 | 解決策 |
|---|---|---|
| 汎用データカラム | 次のようなカラムを使用する:col1, col2柔軟なストレージのために。 |
JSONカラムまたは新しいエンティティテーブルに置き換える。 |
| 複合キー | 複数のカラムをプライマリキーとして使用する。 | シンプルさを重視して、サロゲートキー(自動増分整数)を優先する。 |
| 高速化のための非正規化 | 結合を避けるためにデータを複製する。 | プロファイリングによってそれ以外が証明されない限り、結合のパフォーマンスコストを受け入れる。 |
フェーズ7:検証とテスト ✅
再構築後、新しいスキーマは既存のデータに対して検証されなければなりません。
- マイグレーションスクリプト:古いスキーマから新しいスキーマへデータを移動するスクリプトを書く。移行中にデータが失われないことを確認する。
- 参照整合性の確認:すべての外部キーが有効な親レコードを指していることを確認するためのクエリを実行する。
- パフォーマンステスト:新しいスキーマに対してアプリケーションを実行し、クエリのパフォーマンスが許容範囲内であることを確認する。
- ステークホルダーのレビュー:ビジネスユーザーに図を提示し、それが彼らのプロセスを正確に反映していることを確認する。
最終的な考察 🏁
データベースの逆工程は、忍耐と正確さを要する大きな作業です。一度きりの作業ではなく、データガバナンスの継続的なサイクルの一部です。構造的なアプローチに従うことで、組織は混乱したデータリポジトリを信頼できる資産へと変革できます。
図はコミュニケーションツールであることを忘れないでください。ビジネス関係者が図示された関係性を理解できない場合、技術的な努力は完全に成功したとは言えません。スキーマの定期的なレビューにより、将来の開発が確立されたアーキテクチャと整合するように保証できます。
一貫性に注目してください。命名規則、制約の定義、図のスタイルに関わらず、一貫性があることで、システムとやり取りするすべての人々の認知的負荷が軽減されます。小さなステップから始めましょう。一つのモジュールやドメインを選んで整理し、徹底的に文書化してください。その後、そのプロセスを他の領域へと拡大します。この段階的なアプローチによりリスクが軽減され、継続的な改善が可能になります。
結局のところ、明確なERD構造は強固なデータ戦略の基盤です。開発者が機能をより迅速に構築できるようにし、データの損失や破損の可能性を低減します。今、時間を投資することで、将来の安定性と明確性の恩恵を享受できます。

