











Esquemas de bancos de dados frequentemente evoluem de forma orgânica, em vez de por um design intencional. Com o tempo, ciclos rápidos de desenvolvimento, falta de documentação e mudanças nas exigências do negócio levam a estruturas complexas e difíceis de navegar. Muitas organizações acabam herdando sistemas legados em que os arquitetos originais já não estão disponíveis, e o modelo de dados é obscurecido por anos de correções e ajustes emergenciais. Este processo envolve a análise das camadas de dados existentes e sua reconstrução em um Diagrama de Relacionamento de Entidades (ERD) padronizado. O objetivo é clareza, manutenibilidade e integridade.
A engenharia reversa de um banco de dados não é meramente desenhar linhas entre tabelas; é compreender a lógica de negócios embutida nos dados. Um ERD limpo serve como um plano para o desenvolvimento futuro, uma ferramenta de comunicação para os interessados e uma proteção contra corrupção de dados. Este guia detalha o fluxo técnico para transformar um esquema caótico em um design estruturado e normalizado, sem depender de ferramentas proprietárias específicas.
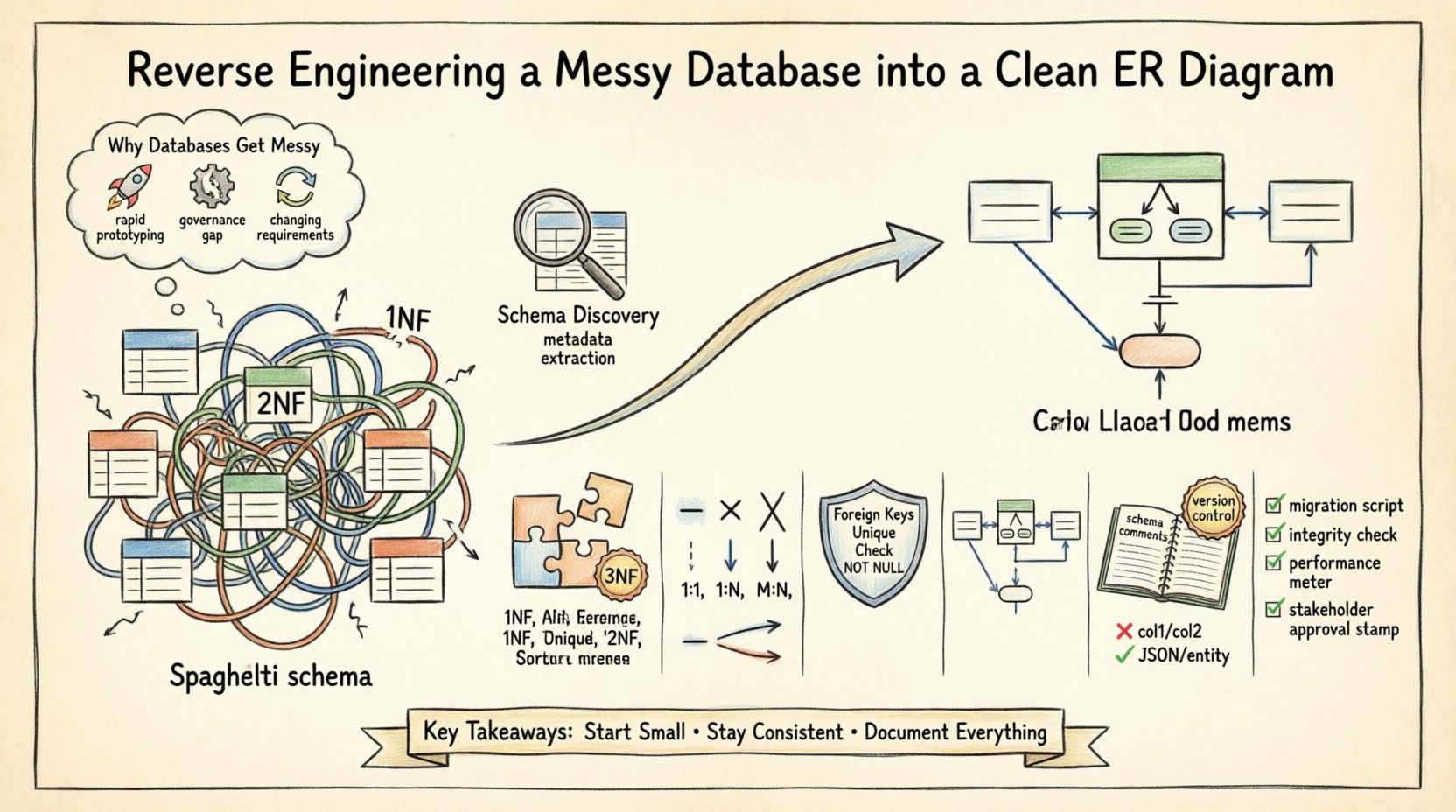
Por que os bancos de dados ficam desorganizados 📉
Compreender a causa raiz da dívida do esquema é o primeiro passo para a correção. Vários fatores contribuem para uma estrutura de banco de dados desorganizada:
- Prototipagem Rápida:O desenvolvimento inicial frequentemente prioriza velocidade em vez de estrutura. As tabelas são criadas de forma espontânea para atender solicitações imediatas de funcionalidades, sem considerar a escalabilidade de longo prazo.
- Falta de Governança:Quando múltiplos desenvolvedores modificam o esquema sem um processo centralizado de revisão, as convenções de nomeação divergem e colunas redundantes aparecem.
- Mudanças na Lógica de Negócio:À medida que os requisitos mudam, as tabelas são alteradas para acomodar novos campos. Chaves estrangeiras às vezes são removidas para contornar restrições, levando a registros órfãos.
- Falhas na Documentação:Comentários e descrições de metadados são frequentemente omitidos durante a implantação inicial, tornando difícil entender a intenção de colunas específicas posteriormente.
Esses problemas resultam no que frequentemente é chamado de “esquema espaguete”. As relações tornam-se implícitas em vez de explícitas, e chaves primárias podem ser perdidas ou duplicadas em várias tabelas. As seções a seguir descrevem a abordagem sistemática para resolver esses problemas.
Fase 1: Descoberta e Perfis do Esquema 🔍
Antes de desenhar qualquer linha, você precisa entender o estado atual do banco de dados. Esta fase foca na extração e análise, e não na modificação.
Extração de Metadados
Todo sistema gerenciador de banco de dados relacional mantém catálogos do sistema ou visualizações de esquema de informações. Esses repositórios contêm detalhes sobre tabelas, colunas, tipos de dados, restrições e índices. Utilize interfaces de consulta para recuperar esses metadados.
- Lista de Tabelas:Recupere todos os nomes de tabelas e suas datas de criação para identificar estruturas legadas.
- Definições de Colunas:Extraia nomes de colunas, tipos de dados, nulidade e valores padrão.
- Restrições:Identifique chaves primárias, restrições únicas e relações de chaves estrangeiras. Observe que algumas relações podem ser impostas apenas no nível da aplicação, e não no banco de dados.
- Índices:Analise os índices existentes para entender os padrões de desempenho de consultas e identificar chaves candidatas potenciais.
Perfilagem de Dados
Os metadados dizem o que o esquema *deveria* ser, mas a perfilagem de dados diz o que ele *é*. A análise dos valores reais dos dados revela inconsistências que as definições de esquema ignoram.
- Distribuição de Valores:Verifique colunas com alta ou baixa cardinalidade que possam indicar a necessidade de normalização.
- Taxas de Nulos:Altas taxas de nulos em campos obrigatórios sugerem a ausência de restrições ou práticas inadequadas de entrada de dados.
- Qualidade dos Dados:Identifique inconsistências de formatação, como números de telefone armazenados como texto com formatos variados.
Fase 2: Identificação e Normalização de Entidades 🧱
Uma vez que os dados brutos forem compreendidos, o próximo passo é a reestruturação lógica. Isso envolve a identificação de entidades e a aplicação de regras de normalização para reduzir a redundância.
Identificação de Entidades
Uma entidade representa um objeto ou conceito distinto dentro do domínio de negócios. Em um banco de dados desorganizado, as entidades muitas vezes estão espalhadas por várias tabelas ou combinadas incorretamente.
- Granularidade:Garanta que cada tabela represente um único conceito. Se uma tabela contém informações de cliente e de pedidos, é provável que viole os princípios de normalização.
- Chaves Primárias:Estabeleça um identificador exclusivo para cada entidade. Evite usar chaves naturais (como endereços de e-mail) se elas forem passíveis de alteração; use chaves de substituição em vez disso.
- Convenções de Nomeação:Padronize os nomes das tabelas para um formato consistente, como substantivos no singular (por exemplo,
clienteem vez declientes).
Aplicação da Normalização
A normalização é o processo de organizar os dados para reduzir a redundância e melhorar a integridade. Embora o objetivo nem sempre seja alcançar o máximo teórico (Forma Normal de Boyce-Codd), buscar a Terceira Forma Normal (3NF) é um padrão sólido para sistemas transacionais.
| Forma | Definição | Objetivo |
|---|---|---|
| Primeira Forma Normal (1NF) | Valores atômicos nas colunas; nenhum grupo repetido. | Garanta que cada célula contenha um único valor. |
| Segunda Forma Normal (2NF) | Atende à 1NF e remove dependências parciais. | Garanta que os atributos não-chave dependam da chave primária inteira. |
| Terceira Forma Normal (3NF) | Atende à 2FN e remove dependências transitivas. | Garanta que os atributos não-chave dependam apenas da chave primária. |
Ao realizar engenharia reversa, procure por colunas que armazenem listas de valores (por exemplo, uma string separada por vírgulas de tags). Essas devem ser divididas em linhas separadas em uma tabela de junção para atender à 1FN. Da mesma forma, atributos que descrevem entidades diferentes (por exemplo, nome_produto e endereço_fornecedor na mesma tabela) devem ser separados em entidades distintas para atender à 2FN e 3FN.
Fase 3: Mapeamento de Relacionamentos 🔗
Relacionamentos definem como as entidades interagem. Em um banco de dados desorganizado, esses são frequentemente implícitos ou ausentes. Esta fase envolve definir a cardinalidade e a opcionalidade dessas conexões.
Tipos de Cardinalidade
- Um para Um (1:1): Um registro na Tabela A está relacionado a exatamente um registro na Tabela B. Isso é raro e geralmente indica uma divisão por motivos de segurança ou desempenho.
- Um para Muitos (1:N): Um registro na Tabela A está relacionado a múltiplos registros na Tabela B. Este é o relacionamento mais comum (por exemplo, Um Cliente faz Muitos Pedidos).
- Muitos para Muitos (M:N): Múltiplos registros na Tabela A estão relacionados a múltiplos registros na Tabela B. Isso exige uma tabela de junção intermediária (por exemplo, Alunos e Cursos).
Resolução de Relacionamentos Muitos para Muitos
Bancos de dados desorganizados frequentemente tentam lidar com relacionamentos muitos para muitos duplicando dados ou criando tabelas largas com múltiplas colunas de chave estrangeira. A abordagem correta é introduzir uma tabela-ponte.
- Identifique as duas entidades pais.
- Crie uma nova tabela contendo as chaves primárias de ambos os pais.
- Adicione quaisquer atributos específicos relacionados à própria relação (por exemplo,
data_matriculaem uma tabela-ponte Aluno-Curso).
Fase 4: Restrições e Integridade de Dados 🔒
Um diagrama é inútil se não impor as regras que ele representa. A implementação física deve refletir o design lógico por meio de restrições.
- Chaves Estrangeiras: Defina explicitamente restrições de chave estrangeira para evitar registros órfãos. Isso garante a integridade referencial automaticamente.
- Restrições Únicas: Aplique restrições únicas às colunas que devem ser distintas (por exemplo, endereços de e-mail, nomes de usuário).
- Restrições de Verificação: Use check constraints to validate data formats or ranges (e.g.,
idade >= 0). - Não Nulo: Marque os campos essenciais como
NÃO NULOpara garantir a integridade dos dados.
Fase 5: Visualização do ERD 🎨
Uma vez que o modelo lógico é estabelecido, ele deve ser visualizado. Embora existam softwares específicos para isso, os princípios de diagramação permanecem consistentes.
Padrões de Diagramação
Escolha um padrão de notação para garantir que o diagrama seja legível por diferentes partes interessadas.
- Notação de Pata de Corvo: Amplamente utilizado na indústria. Usa símbolos específicos para indicar cardinalidade (por exemplo, uma linha simples para “um”, uma pata de corvo para “muitos”).
- Diagramas de Classes UML: Usa caixas e setas, frequentemente preferido por desenvolvedores de software familiarizados com o design orientado a objetos.
- Notação de Chen: Usa losangos para relacionamentos, comum em ambientes acadêmicos, mas menos frequente em ferramentas empresariais modernas.
Melhores Práticas de Layout
- Agrupamento: Agrupe tabelas relacionadas juntas (por exemplo, todas as tabelas de Pedido em uma área) para mostrar domínios lógicos.
- Direção do Fluxo: Organize os diagramas para fluírem logicamente da esquerda para a direita ou de cima para baixo.
- Legibilidade: Garanta que os nomes das tabelas sejam claramente visíveis e que as interseções de linhas sejam minimizadas.
Fase 6: Documentação e Manutenção 📝
Um diagrama estático é uma fotografia. Para garantir valor de longo prazo, a documentação deve ser mantida junto com o código.
Comentários do Esquema
Use comentários de coluna e tabela para explicar a lógica de negócios. Por exemplo, uma coluna chamada status deve ter um comentário explicando quais valores são válidos (por exemplo, “0: Pendente, 1: Aprovado, 2: Rejeitado”).
Controle de Versão
Armazene os arquivos de ERD e definição de esquema em um sistema de controle de versão. Isso permite que você acompanhe as alterações ao longo do tempo e reverta se necessário.
Anti-padrões comuns a evitar 🚫
Durante o processo de limpeza, esteja atento aos armadilhas comuns.
| Anti-padrão | Problema | Solução |
|---|---|---|
| Colunas Genéricas de Dados | Usando colunas como col1, col2 para armazenamento flexível. |
Substitua por uma coluna JSON ou uma nova tabela de entidade. |
| Chaves Compostas | Usar múltiplas colunas como chave primária. | Prefira chaves surrogate (inteiros autoincrementáveis) por simplicidade. |
| Denormalização para Velocidade | Duplicar dados para evitar junções. | Aceite o custo de desempenho das junções, a menos que o perfilamento prove o contrário. |
Fase 7: Validação e Testes ✅
Após a reestruturação, o novo esquema deve ser validado em relação aos dados existentes.
- Scripts de Migração: Escreva scripts para mover dados do esquema antigo para o novo. Certifique-se de que nenhum dado seja perdido durante a transferência.
- Verificações de Integridade Referencial: Execute consultas para garantir que todas as chaves estrangeiras apontem para registros pais válidos.
- Testes de Desempenho: Execute a aplicação contra o novo esquema para verificar se o desempenho das consultas permanece aceitável.
- Revisão por Stakeholders: Apresente o diagrama aos usuários de negócios para confirmar que ele reflete com precisão seus processos.
Considerações Finais 🏁
Engenharia reversa de um banco de dados é uma tarefa significativa que exige paciência e precisão. Não é uma tarefa pontual, mas parte de um ciclo contínuo de governança de dados. Ao seguir uma abordagem estruturada, as organizações podem transformar repositórios de dados caóticos em ativos confiáveis.
Lembre-se de que o diagrama é uma ferramenta de comunicação. Se os stakeholders de negócios não conseguirem entender as relações representadas, o esforço técnico não terá tido sucesso pleno. Revisões regulares do esquema garantem que o desenvolvimento futuro esteja alinhado com a arquitetura estabelecida.
Concentre-se na consistência. Seja nas convenções de nomeação, definições de restrições ou estilos de diagramas, a uniformidade reduz a carga cognitiva de todos que interagem com o sistema. Comece pequeno. Escolha um módulo ou domínio, limpe-o e documente-o detalhadamente. Depois, expanda o processo para outras áreas. Essa abordagem incremental reduz o risco e permite melhorias contínuas.
Em última análise, uma estrutura ERD limpa é a base de uma estratégia de dados sólida. Ela capacita os desenvolvedores a construir funcionalidades mais rapidamente e reduz a probabilidade de perda ou corrupção de dados. Invista tempo agora para colher os benefícios da estabilidade e clareza no futuro.

