











数据库模式通常会自然演进,而非通过有意识的设计。随着时间推移,快速的开发周期、缺乏文档以及不断变化的业务需求,导致结构变得复杂且难以导航。许多组织发现自己继承了遗留系统,原始架构师已不再可用,而数据模型则因多年来的修补和紧急修复而变得模糊不清。这一过程包括分析现有的数据层,并将其重构为标准化的实体关系图(ERD)。目标是实现清晰性、可维护性和完整性。
逆向工程数据库不仅仅是简单地在表之间画线;更重要的是理解数据中嵌入的业务逻辑。一个清晰的ERD可作为未来开发的蓝图、利益相关者之间的沟通工具,以及防止数据损坏的保障。本指南详细介绍了将混乱的模式转换为结构化、规范化的设计的技术流程,且不依赖于特定的专有工具。
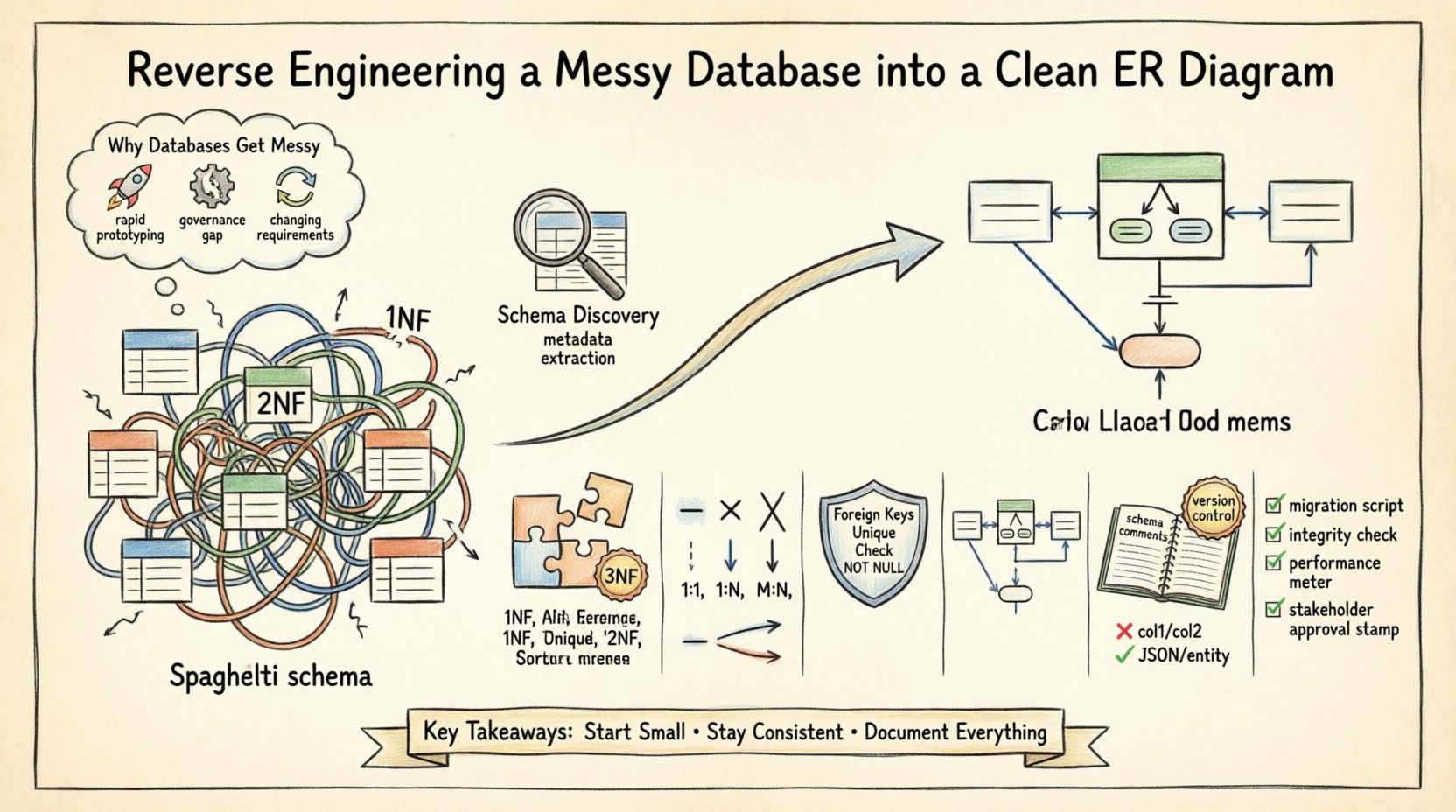
为什么数据库会变得杂乱 📉
理解模式债务的根本原因,是解决问题的第一步。以下几种因素导致了数据库结构的混乱:
- 快速原型设计:初期开发往往更注重速度而非结构。表被临时创建以满足即时的功能需求,而未考虑长期的可扩展性。
- 缺乏治理:当多名开发人员在缺乏集中审查流程的情况下修改模式时,命名规范会变得不一致,冗余的列也会出现。
- 业务逻辑变更:随着需求的变化,表会被修改以容纳新字段。有时会删除外键以绕过约束,从而导致孤立记录的产生。
- 文档缺失:在初始部署过程中,注释和元数据描述常常被忽略,导致后期难以理解特定列的意图。
这些问题导致了所谓的“意大利面式模式”(spaghetti schema)。关系变得隐式而非显式,主键可能在多个表中丢失或重复。接下来的章节将概述解决这些问题的系统性方法。
第一阶段:模式发现与分析 🔍
在绘制任何连线之前,你必须了解数据库的当前状态。本阶段的重点是提取和分析,而非修改。
提取元数据
每个关系型数据库管理系统都维护着系统目录或信息模式视图。这些存储库包含有关表、列、数据类型、约束和索引的详细信息。使用查询接口来获取这些元数据。
- 表列表:获取所有表名及其创建日期,以识别遗留结构。
- 列定义:提取列名、数据类型、可空性以及默认值。
- 约束:识别主键、唯一约束以及外键关系。请注意,某些关系可能仅在应用层强制执行,而非在数据库中。
- 索引:分析现有索引,以理解查询性能模式,并识别潜在的候选键。
数据剖析
元数据告诉你模式*应该*是什么,而数据剖析则告诉你它*实际是什么*。扫描实际的数据值可以揭示出模式定义所遗漏的不一致之处。
- 值分布:检查高基数或低基数的列,这些可能表明需要进行规范化。
- 空值率:在必填字段中出现高比例的空值,表明可能存在缺失的约束条件或数据录入质量较差。
- 数据质量:识别格式不一致的问题,例如电话号码以不同格式的文本形式存储。
第二阶段:实体识别与规范化 🧱
在理解原始数据后,下一步是进行逻辑重构。这包括识别实体,并应用规范化规则以减少冗余。
识别实体
实体代表业务领域中的一个独立对象或概念。在混乱的数据库中,实体通常分散在多个表中,或被错误地合并在一起。
- 粒度:确保每张表只代表一个单一概念。如果一张表同时包含客户信息和订单信息,很可能违反了规范化原则。
- 主键:为每个实体建立唯一的标识符。如果自然键(如电子邮件地址)可能发生变化,应避免使用,而应改用代理键。
- 命名规范:将表名标准化为一致的格式,例如使用单数名词(例如,
客户而不是客户们).
应用规范化
规范化是组织数据以减少冗余并提高完整性的过程。虽然目标不一定是达到理论上的最高标准(博伊斯-科德范式),但将第三范式(3NF)作为目标,是事务系统中一个稳健的标准。
| 范式 | 定义 | 目标 |
|---|---|---|
| 第一范式(1NF) | 列中为原子值;无重复组。 | 确保每个单元格只包含一个值。 |
| 第二范式(2NF) | 满足1NF,并消除部分依赖。 | 确保非主键属性依赖于整个主键。 |
| 第三范式(3NF) | 满足第二范式并消除了传递依赖。 | 确保非主键属性仅依赖于主键。 |
在逆向工程时,寻找存储值列表的列(例如,用逗号分隔的标签字符串)。这些必须拆分为连接表中的单独行以满足第一范式。同样,描述不同实体的属性(例如,product_name 和 vendor_address在同一张表中)应被拆分为不同的实体以满足第二范式和第三范式。
第三阶段:映射关系 🔗
关系定义了实体之间的交互方式。在混乱的数据库中,这些关系往往是隐式的或缺失的。此阶段涉及定义这些连接的基数和可选性。
基数类型
- 一对一(1:1):表A中的一个记录恰好与表B中的一个记录相关联。这种情况很少见,通常表明出于安全或性能原因进行了拆分。
- 一对多(1:N):表A中的一个记录与表B中的多个记录相关联。这是最常见的关系(例如,一个客户下多个订单)。
- 多对多(M:N):表A中的多个记录与表B中的多个记录相关联。这需要一个中间的连接表(例如,学生和课程)。
解决多对多关系
混乱的数据库通常试图通过复制数据或创建包含多个外键列的宽表来处理多对多关系。正确的做法是引入一个桥接表。
- 识别两个父实体。
- 创建一个包含两个父实体主键的新表。
- 添加与关系本身相关的任何特定属性(例如,
enrollment_date在学生-课程桥接表中)。
第四阶段:约束与数据完整性 🔒
如果图示不能强制执行其所描述的规则,则毫无用处。物理实现必须通过约束来反映逻辑设计。
- 外键:显式定义外键约束以防止出现孤立记录。这可自动确保引用完整性。
- 唯一性约束:对必须保持唯一的列应用唯一性约束(例如,电子邮件地址、用户名)。
- 检查约束: 使用检查约束来验证数据格式或范围(例如,
age >= 0). - 非空:将关键字段标记为
NOT NULL以确保数据完整性。
第五阶段:可视化ERD 🎨
逻辑模型建立后,必须进行可视化。尽管存在专门的软件用于此目的,但绘图的基本原则保持一致。
绘图标准
选择一种符号标准,以确保不同利益相关者都能读懂该图。
- 乌鸦足符号:在行业中广泛使用。使用特定符号表示基数(例如,单线表示“一”,乌鸦足表示“多”)。
- UML类图:使用方框和箭头,通常被熟悉面向对象设计的软件开发人员所青睐。
- 陈氏符号:使用菱形表示关系,在学术环境中常见,但在现代企业工具中较少使用。
布局最佳实践
- 分组:将相关表放在一起(例如,将所有订单表放在一个区域)以展示逻辑域。
- 流向:将图表按逻辑方向从左到右或从上到下排列。
- 可读性:确保表名清晰可见,并尽量减少线条交叉。
第六阶段:文档编写与维护 📝
静态图表只是一个快照。为了确保长期价值,文档必须与代码同步维护。
模式注释
使用列和表注释来解释业务逻辑。例如,名为status的列应有注释说明哪些值是有效的(例如,“0:待处理,1:已批准,2:已拒绝”)。
版本控制
将ERD和模式定义文件存储在版本控制系统中。这使您能够跟踪随时间的变化,并在必要时进行回滚。
应避免的常见反模式 🚫
在清理过程中,要警惕常见的陷阱。
| 反模式 | 问题 | 解决方案 |
|---|---|---|
| 通用数据列 | 使用类似这样的列col1, col2以实现灵活存储。 |
替换为JSON列或新的实体表。 |
| 复合键 | 使用多个列作为主键。 | 为简化起见,优先使用代理键(自增整数)。 |
| 为提升速度而进行反规范化 | 复制数据以避免连接操作。 | 除非性能分析证明相反,否则应接受连接操作的性能开销。 |
阶段7:验证与测试 ✅
重构后,新模式必须与现有数据进行验证。
- 迁移脚本:编写脚本,将数据从旧模式迁移到新模式。确保迁移过程中不会丢失任何数据。
- 参照完整性检查:运行查询,确保所有外键都指向有效的父记录。
- 性能测试:在新模式上运行应用程序,以验证查询性能仍可接受。
- 利益相关方评审:向业务用户展示图表,确认其准确反映了他们的流程。
最终思考 🏁
逆向工程数据库是一项需要耐心和精确性的重大任务。它不是一次性的任务,而是持续数据治理循环的一部分。通过采用结构化的方法,组织可以将混乱的数据存储库转变为可靠的资产。
请记住,图表是一种沟通工具。如果业务利益相关者无法理解图中所展示的关系,那么技术努力就没有完全成功。定期审查模式可以确保未来开发与既定架构保持一致。
注重一致性。无论是命名规范、约束定义还是图表风格,统一性都能降低所有与系统交互人员的认知负担。从小处着手。选择一个模块或领域,将其清理并彻底文档化,然后将这一过程扩展到其他区域。这种渐进式方法可以降低风险,并实现持续改进。
最终,清晰的ERD结构是强大数据战略的基础。它使开发人员能够更快地构建功能,并降低数据丢失或损坏的可能性。现在投入时间,将来才能收获稳定性和清晰度带来的好处。

